なぜ記事にしたか
2年前に勉強会を開催させていただいたのですが、もう古くなってしまったので、備忘録の意味で公開します。
やってみたこと
胸部レントゲン画像と腹部レントゲン画像とを自動で判別できるアプリケーションを開発する。
モチベーション
何かを二値に分類することは重要なことです。
どんなに複雑な課題も、体系的にまとめることができれば課題を部分ごとに分解できます。分解した課題をさらに細かく分解していくと、最終的にはYes or Noの選択になります。部分を細分化して答えを出していけば、Yes or Noの選択の繰り返しのみで難しい課題も解ける(のではないか)ということです。
テーマは何でも良かったのですが、メディカルで画像の二値分類の体験をするためのトレーニング題材を探していたら、ちょうど良いのがこのテーマでした。
元はこの論文です。Hello World Deep Learning in Medical Imaging
使ったもの
- ノートパソコン(一般のもの)
- Optional: NVIDIA-GPU(今回は1050Ti)
環境
- ubuntu 18.04 (javaなのでOSは細かく問わない)
- maven + dl4j関連
- eclipse (2018)
- JDK8 or higher
- (もう、こういうテーマに興味ある人はpythonでやってますよね)
データ
以下のGitHubリンクで公開されています。
https://github.com/paras42/Hello_World_Deep_Learning/tree/9921a12c905c00a88898121d5dc538e3b524e520
画像は「Open_I_abd_vs_CXRs.zip」です。
abdはAbdomen、CXRsはChest-X-raysの略です。たぶん。
ダウンロード後、解凍して使います。
全75枚の画像になっており、38枚のchest X-rays、37枚のabdominal X-raysになっています。
フォルダ階層はこのようになっています。TEST、TRAIN、VAL(Validationの略)のフォルダに分かれており、TRAINとVALフォルダにはそれぞれで胸部と腹部の画像フォルダが作られています。

TESTフォルダには胸部と腹部の画像が一枚ずつ入っており、これらはフォルダに振り分けられていません。
作業
データは解凍したら適当な場所に保存します。
私の場合は、Mavenプロジェクトの直下に置きました。

コードと解説
POM.xmlはこのページの末尾に記載しています。
最終的なコードは、この節の最後にまとめています。
バージョンによっては、見ているパッケージが違うことがあるので注意して下さい。
(頻繁に変わる印象、、)
セットアップ
まず、学習の基本的なパラメータや設定を準備します。
学習時には重みの計算や、トレーニングデータの自動割り振りなど、いろんなところでランダム変数が利用されます。
これはとても便利ですが、毎回結果がかわってしまうと厄介です。
毎回同じランダム変数を設定するために、シードを定義しておきます。
long seed = 42;
final Random RAND_NUM_GEN = new Random(seed);
今回は画像を対象にしていますので、画像の入力が必要になります。
どのような画像でも入力する!としていると、たまたまフォルダ内に紛れていた変なデータが吸い込まれてしまうことがあります。
これを防ぐために、入力可能な画像フォーマットを設定します。ここではデフォルトで汎用の画像フォーマットを入力できるようにしています。
final String[] ALLOWED_FORMATS = BaseImageLoader.ALLOWED_FORMATS;
機械学習(教師あり)では、教師ラベルデータを自作することが多いのですが、以下のように設定すると、フォルダ名をクラス名として自動で認識して、自動でラベルを振り分けてくれます。
(今回の場合は、例えば、胸部画像1.png : [0,1](左側が腹部、右側が胸部)のように、ラベルの並び順に沿って、インデックスを着けていきます。インデックスは何でも良いのですが、一般的には「1」が使われます。)
ParentPathLabelGenerator LABEL_GENERATOR_MAKER = new ParentPathLabelGenerator();
次に、学習にデータを流す際に、データをランダムに選択しながら、同じ数だけ入力するようにする設定をします。
BalancedPathFilter PATH_FILTER = new BalancedPathFilter(RAND_NUM_GEN, ALLOWED_FORMATS, LABEL_GENERATOR_MAKER);
モデルの学習に必要な基本的な設定を行います。
コメントにあるとおりですが、
numLabelsは、ラベルの数です。今回は胸部と腹部の分類ですので、ラベルは2つ、ということになります。
height、width、channelsは、モデルに入力する画像(予測したい画像)の縦横のマトリックスと、カラーチャンネルを設定します。
inputShapeは、これらを組み合わた配列で、モデルの入力層の設定値になります。
batchSizeは一回の学習で利用するデータの量で、これらのデータが処理されてからネットワークの重みが更新されます。
epochsは学習回数です。一回の学習でbatchSize分のデータを学習し、ネットワークの重みを更新します。
int numLabels = 2;// chest or abd
int height = 64;// image size for train
int width = 64;// image size for train
int channels = 3;// image channels(in this case, image type is RGB, so 3 channels)
int[] inputShape = new int[] {channels, height, width};
int batchSize = 32;// train data size in 1 epoch
int epochs = 50;
画像データ入力のパイプライン
基本的な設定が完了したので、画像を入力する方法を設定します。
入力したい学習データフォルダまでのパスを指定して、FileSplitとInputSplitのオブジェクトを構築します。
本来、これらは自動でトレーニング用/検証用/テスト用の画像を振り分けたりするために使うのですが、今回はフォルダで振り分けが完了しているので、データをコードで分けることはせず、トレーニング、バリデーション(検証)、テストのそれぞれで入力のパイプラインを構築しています。
System.out.println("Preparing data....");
// Prepare train
File trainDir = new File("./Open_I_abd_vs_CXRs/TRAIN/");
FileSplit trainSplit = new FileSplit(trainDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN);
InputSplit train = trainSplit.sample(PATH_FILTER, 1.0)[0];//すべてを訓練へ
// Prepare val
File valDir = new File("./Open_I_abd_vs_CXRs/VAL/");
FileSplit valSplit = new FileSplit(valDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN);
InputSplit val = valSplit.sample(PATH_FILTER, 1.0)[0];//すべてを検証へ
// Prepare test
File testDir = new File("./Open_I_abd_vs_CXRs/TEST/");
FileSplit testSplit = new FileSplit(testDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN);
InputSplit test = testSplit.sample(PATH_FILTER, 1.0)[0];//すべてをテストへ
System.out.println("train data total sample size " + train.length());
System.out.println("validation total data sample size " + val.length());
System.out.println("test data total sample size " + test.length());
オーグメンテーション(疑似データの増幅処理)
今回のデータセットではデータ量がとても少ない(深層学習では各クラスで数百単位のデータが必要)ので、擬似的にデータを増やしてモデルの精度を検討します。
これでうまく行けば、データを増やしても結構いい線いくモデルが開発できそうだ!とわかるためです。
画像の増幅の方法には、フリップ、回転、クロップ、位置のスライド、アフィン変換による変形など、いろいろなことが出来ます。注意点は、ありえない画像を増幅させないようにすることです。例えば、超音波画像で、後方エコーがあるにも関わらず、180°回転させて疑似画像を作るなどが失敗例です。
ここでは、そこまで厳密には考えず、ImageTransformを使って、ランダムなフリップと位置の並行移動を設定しました。
いくつかのImageTransformを作り、最終的にこれらをListにまとめて、PipelineImageTransformとして構築してパイプラインが出来上がります。
PipelineImageTransformのshuffleがTrueの場合、パイプラインの順序がランダムに選ばれます。Falseの場合はシーケンシャルにList順に処理されます。
System.out.println("Prepare augumentation....");
ImageTransform flipTransform1 = new FlipImageTransform(new Random(seed));
ImageTransform flipTransform2 = new FlipImageTransform(new Random(seed));
ImageTransform warpTransform = new WarpImageTransform(new Random(seed), inputShape[1]/10);
boolean shuffle = false;
List<Pair<ImageTransform, Double>> pipeline = Arrays.asList(new Pair<>(flipTransform1, 0.9),
new Pair<>(flipTransform2, 0.8), new Pair<>(warpTransform, 0.9));
ImageTransform transform = new PipelineImageTransform(pipeline, shuffle);
画像の入力とデータ増幅の紐付け
ここまでで画像の入力部分と、データの増強処理の設定が出来ました。
あとはこれらを紐付けます。
一般的に、トレーニングデータに対してのみデータの増強を行います。
以下のコードのように、その画像の入力に対して増強するかを指定します。
この画像入力と増強処理の管理はImageRecordReaderが担ってくれます。
// data reader setup
ImageRecordReader recordReaderTrain = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER);
ImageRecordReader recordReaderVal = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER);
/*
* 今回は配布元のデータ構造に合わせるので、
* テストデータは階層のラベルを自動計算させない。
* (利用する際は、データのフォルダ階層を他と同じにして利用する。)
*/
// ImageRecordReader recordReaderTest = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER);
ImageRecordReader recordReaderTest = new ImageRecordReader(height, width, channels);
try {
// recordReaderTrain.initialize(train);// Train without transformations
recordReaderTrain.initialize(train,transform);// Train with transformations
recordReaderVal.initialize(val);//検証データにはオーグメンテーションをしない
recordReaderTest.initialize(test);
} catch (IOException e) {
e.printStackTrace();
}
モデルの構築
ちょっと簡単にしたいと思ったのですが、せっかくなので、SimpleCNNというModelZooシリーズのネットワークを借りてやってみます。
ここに示す例は、完全なSimpleCNNではなく、最後の出力層をこの検討のために調整して追加しています。
難しいことはやっておらず、SimpleCNN.javaコードからコピペして、出力層をマルチクラス分類用にしたのみです(2クラスなので、バイナリ分類も出来ますが、ここではSoftMaxを使う例でいきます)。
ここは説明を省略しますが、DL4Jは、ここで使っているMultiLayerNetworkが基本的かつシンプルなCNNの概念になります。
深層学習に興味のある人がよく知っているモデルは、もっと複雑で巨大なものもありますが、このような複雑・巨大なモデルはこのMultiLayerNetworkを組み合わせて構成されます。
System.out.println("Start construct SimpleCNN model...");
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder().trainingWorkspaceMode(WorkspaceMode.ENABLED)
.inferenceWorkspaceMode(WorkspaceMode.ENABLED).seed(seed).activation(Activation.IDENTITY)
.weightInit(WeightInit.RELU).optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(new AdaDelta()).convolutionMode(ConvolutionMode.Same).list()
// block 1
.layer(0,
new ConvolutionLayer.Builder(new int[] { 7, 7 }).name("image_array").nIn(inputShape[0]).nOut(16)
.build())
.layer(1, new BatchNormalization.Builder().build())
.layer(2, new ConvolutionLayer.Builder(new int[] { 7, 7 }).nIn(16).nOut(16).build())
.layer(3, new BatchNormalization.Builder().build())
.layer(4, new ActivationLayer.Builder().activation(Activation.RELU).build())
.layer(5, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build())
.layer(6, new DropoutLayer.Builder(0.5).build())
// block 2
.layer(7, new ConvolutionLayer.Builder(new int[] { 5, 5 }).nOut(32).build())
.layer(8, new BatchNormalization.Builder().build())
.layer(9, new ConvolutionLayer.Builder(new int[] { 5, 5 }).nOut(32).build())
.layer(10, new BatchNormalization.Builder().build())
.layer(11, new ActivationLayer.Builder().activation(Activation.RELU).build())
.layer(12, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build())
.layer(13, new DropoutLayer.Builder(0.5).build())
// block 3
.layer(14, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(64).build())
.layer(15, new BatchNormalization.Builder().build())
.layer(16, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(64).build())
.layer(17, new BatchNormalization.Builder().build())
.layer(18, new ActivationLayer.Builder().activation(Activation.RELU).build())
.layer(19, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build())
.layer(20, new DropoutLayer.Builder(0.5).build())
// block 4
.layer(21, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(128).build())
.layer(22, new BatchNormalization.Builder().build())
.layer(23, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(128).build())
.layer(24, new BatchNormalization.Builder().build())
.layer(25, new ActivationLayer.Builder().activation(Activation.RELU).build())
.layer(26, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build())
.layer(27, new DropoutLayer.Builder(0.5).build())
// block 5
.layer(28, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(256).build())
.layer(29, new BatchNormalization.Builder().build())
.layer(30, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(256).build())
.layer(31, new GlobalPoolingLayer.Builder(PoolingType.AVG).build())
//output
.layer(32, new OutputLayer.Builder().nIn(256).nOut(2)
.lossFunction(LossFunctions.LossFunction.MCXENT)
.weightInit(WeightInit.XAVIER)
.activation(Activation.SOFTMAX)
.build())
.setInputType(InputType.convolutional(inputShape[2], inputShape[1], inputShape[0]))
.backpropType(BackpropType.Standard)
.build();
MultiLayerNetwork network = new MultiLayerNetwork(conf);
network.init();
System.out.println(network.summary());
学習の過程を可視化する
学習がどのように各エポックで進むのかを確認するために、DL4Jに組み込まれている機能を使います。
この記事のコードを最後まで繋ぎ合わせ、実行した後、学習が進んでいきますが、このときに、自分のウェブブラウザを立ち上げて、http://localhost:9000をURLに入力してページに移動してみて下さい。
自分のPCで学習の進捗をグラフィカルに確認できます。
// visualize train process
// URL:http://localhost:9000/train/overview
UIServer uiServer = UIServer.getInstance();
StatsStorage statsStorage = new InMemoryStatsStorage();
uiServer.attach(statsStorage);
学習の過程をどのようにモニタリングするかも設定することが出来ます。
モデルの汎用情報を集めてくれるStatsListenerと、指定した間隔でモデル精度(ロスが主です)を計算してくれるScoreIterationListenerがよく利用されます。
// set Stats Listener, to check confusion matrix for each epoch
network.setListeners(new StatsListener(statsStorage), new ScoreIterationListener(1));
画像の入力をモデルの入力へ
学習までもう一息です。
ここまでですでに画像データ入力のパイプラインは作成しましたが、これをモデルの入力用に変換してくれる設定を追加します。
DataSetIteratorです。
DataSetIteratorは、繰り返し学習を行う度に、必要なデータを学習用に準備してくれる役割を担っています。
今回は、TRAIN、VAL(検証)、TESTの3つのDataSetIteratorを作ります。
このうち、TESTの画像データに関しては、元のデータフォルダを見て分かるように、他のデータと違って、クラスフォルダごとに画像データが割り振られておらず、TESTフォルダの中に直接画像が入っています。
他のデータと同じようにフォルダを作って、コピーしてもよいのですが、よい機会なので、フォルダ分けせずに入力する方法も併せて示します。
//Label index : Always value 1 when using ImageRecordReader. For CSV etc: use index of the column
DataSetIterator traindataIter = new RecordReaderDataSetIterator(recordReaderTrain, batchSize, 1, numLabels);
DataSetIterator valdataIter = new RecordReaderDataSetIterator(recordReaderVal, batchSize, 1, numLabels);
DataSetIterator testdataIter = new RecordReaderDataSetIterator(recordReaderTest, batchSize, 1, numLabels);
正規化
学習を始める最終段階として、モデルに入力するデータを正規化します。
正規化とはよく統計学で利用される手法で、外れ値や、データごとの最大値・最小値のズレなど、モデルが学習する上で混乱をさせるようなものを省くための処理です。
ここでは、画像のピクセル値を0から1の間の数値に変換するスケーラを設定しています。
スケーラにはいろいろな種類がありますが、一般に、訓練用に調整されたスケーラを、検証やテストのデータにも適用します。
(とはいえ、ここで利用しているのは0-1範囲変換なので、調整の必要がない単純なものですが、お作法的に。)
// Normalization
DataNormalization scaler = new ImagePreProcessingScaler(0, 1);
scaler.fit(traindataIter);
traindataIter.setPreProcessor(scaler);
valdataIter.setPreProcessor(scaler);
testdataIter.setPreProcessor(scaler);
モデルのトレーニングと検証
モデルの訓練をepochs回繰り返します。
準備したDatasetIteraterをモデルのfit()という関数に渡すのみです。
あとは自動的に繰り返しでデータ取得→学習データリセットをやってくれます。
(モデルによっては、1epoch内でさらにiteraterの繰り返しが必要なことがあるので、DL4JのExampleなどを注意して見てください。)
訓練ごとに、同時に検証も行っていきます。
network.evaluate(valdataIter);でよく知られている評価指標と混合行列が計算されます。
System.out.println("Start training model....");
int i = 0;
while (i < epochs) {
while (traindataIter.hasNext()) {
DataSet trained = traindataIter.next();
// System.out.println(trained.numExamples());//same as batch size
network.fit(trained);
}
System.out.println("Evaluate model at iteration " + i + " ....");
Evaluation eval = network.evaluate(valdataIter);//use nd4j's Evaluation
System.out.println(eval.stats());
valdataIter.reset();//Iteraterを最初に戻す
traindataIter.reset();//Iteraterを最初に戻す
i++;
}
モデルのテスト
最後に、トレーニングにもテストにも用いていないデータでテストしてみます。
ここでは、画像を単体で入力して、Evaluationを使わずに、自分で確認する方法を示します。
/*
* 元画像があるフォルダ階層をトレーニングデータのフォルダ階層と同じにした場合、
* 上記のように評価できます。
* フォルダが整理されていなくても、
* 以下のように画像ごとに評価できます。
*/
System.out.println("Test model....");
while(testdataIter.hasNext()) {
DataSet testData = testdataIter.next();
System.out.println("testing... :"+testData.id());
INDArray input = testData.getFeatures();
INDArray pred = network.output(input);
System.out.println(pred);
int predLabel = Nd4j.argMax(pred).getInt(0);//labelある場合
if(predLabel == 0) {
System.out.println("ABDOMEN"+" with praba "+pred.getDouble(predLabel));
}else {
System.out.println("CHEST"+" with praba "+pred.getDouble(predLabel));
}
}
System.out.println("Finish....");
実行
途中の計算過程はこのように可視化出来ます。
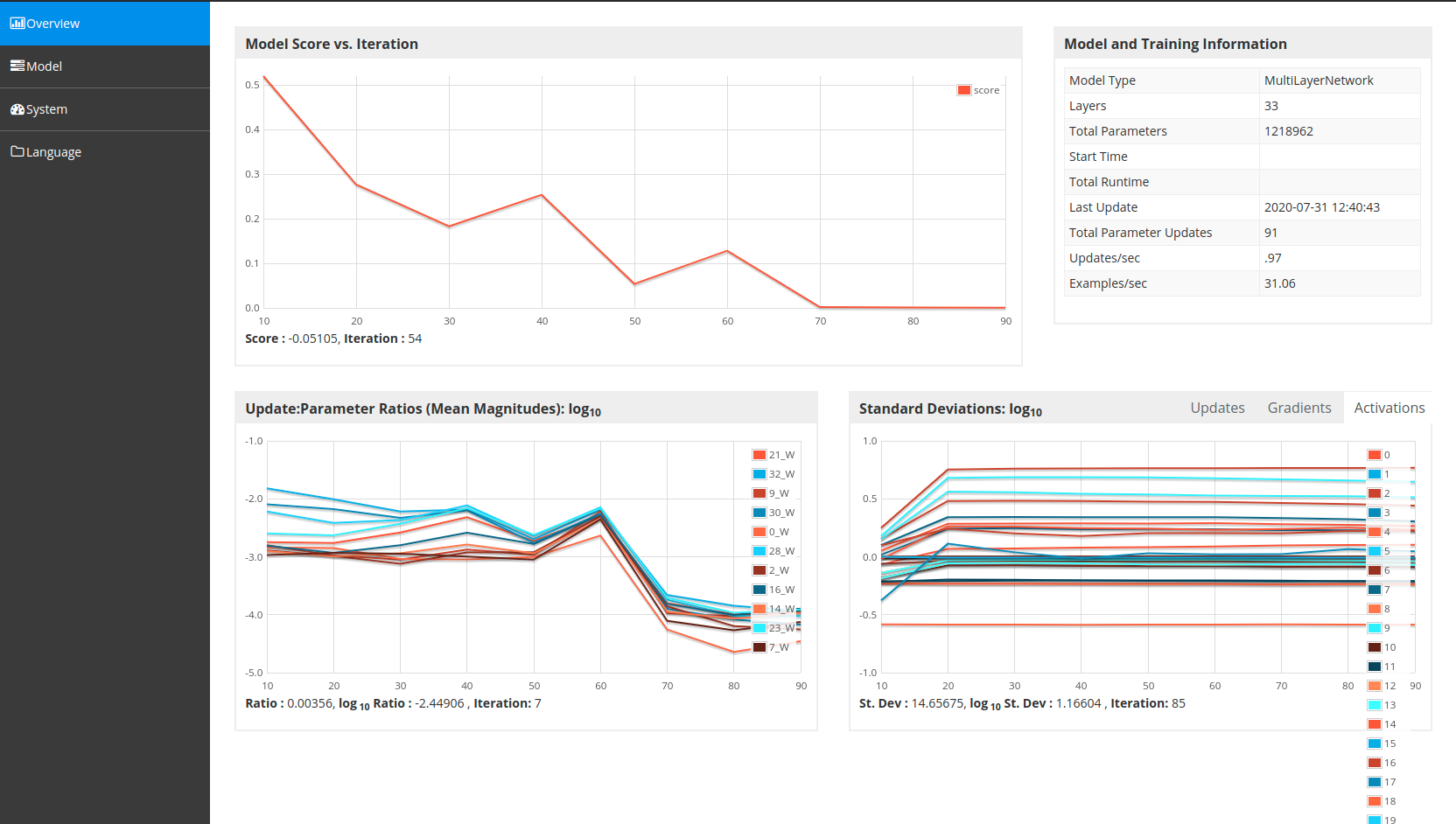
途中の評価は、以下のとおりです。epoch16で結構良い成績になっています。
一部省略。
Evaluate model at iteration 15 ....
of classes: 2
Accuracy: 0.9000
Precision: 0.9167
Recall: 0.9000
F1 Score: 0.8889
最後のテストの出力は、以下のとおりです。
Test model....
testing... :
[[ 5.7758e-5, 0.9999]]
CHEST with praba 0.9999421834945679
testing... :
[[ 0.5547, 0.4453]]
ABDOMEN with praba 0.5546808838844299
Finish....
お腹はギリギリ判定できたようです。まだまだ怪しいモデルですね。
コードの外観
以下のようになります。
import java.io.File;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
import org.datavec.api.io.filters.BalancedPathFilter;
import org.datavec.api.io.labels.ParentPathLabelGenerator;
import org.datavec.api.split.FileSplit;
import org.datavec.api.split.InputSplit;
import org.datavec.image.loader.BaseImageLoader;
import org.datavec.image.loader.NativeImageLoader;
import org.datavec.image.recordreader.ImageRecordReader;
import org.datavec.image.transform.FlipImageTransform;
import org.datavec.image.transform.ImageTransform;
import org.datavec.image.transform.PipelineImageTransform;
import org.datavec.image.transform.WarpImageTransform;
import org.deeplearning4j.api.storage.StatsStorage;
import org.deeplearning4j.datasets.datavec.RecordReaderDataSetIterator;
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.BackpropType;
import org.deeplearning4j.nn.conf.ConvolutionMode;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.WorkspaceMode;
import org.deeplearning4j.nn.conf.inputs.InputType;
import org.deeplearning4j.nn.conf.layers.ActivationLayer;
import org.deeplearning4j.nn.conf.layers.BatchNormalization;
import org.deeplearning4j.nn.conf.layers.ConvolutionLayer;
import org.deeplearning4j.nn.conf.layers.DropoutLayer;
import org.deeplearning4j.nn.conf.layers.GlobalPoolingLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.conf.layers.PoolingType;
import org.deeplearning4j.nn.conf.layers.SubsamplingLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.deeplearning4j.ui.api.UIServer;
import org.deeplearning4j.ui.stats.StatsListener;
import org.deeplearning4j.ui.storage.InMemoryStatsStorage;
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.dataset.api.preprocessor.ImagePreProcessingScaler;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.learning.config.AdaDelta;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import org.nd4j.linalg.primitives.Pair;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class ChestOrAbd {
protected static final Logger log = LoggerFactory.getLogger(ChestOrABd.class);
public static void main(String[] args) {
long seed = 42;
final Random RAND_NUM_GEN = new Random(seed);
final String[] ALLOWED_FORMATS = BaseImageLoader.ALLOWED_FORMATS;
ParentPathLabelGenerator LABEL_GENERATOR_MAKER = new ParentPathLabelGenerator();
BalancedPathFilter PATH_FILTER = new BalancedPathFilter(RAND_NUM_GEN, ALLOWED_FORMATS, LABEL_GENERATOR_MAKER);
int numLabels = 2;// chest or abd
int height = 64;// image size for train
int width = 64;// image size for train
int channels = 3;// image channels(in this case, image type is RGB, so 3 channels)
int[] inputShape = new int[] {channels, height, width};
int batchSize = 32;// train data size in 1 epoch
int epochs = 50;
System.out.println("Preparing data....");
// Prepare train
File trainDir = new File("./Open_I_abd_vs_CXRs/TRAIN/");
FileSplit trainSplit = new FileSplit(trainDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN);
InputSplit train = trainSplit.sample(PATH_FILTER, 1.0)[0];
// Prepare val
File valDir = new File("./Open_I_abd_vs_CXRs/VAL/");
FileSplit valSplit = new FileSplit(valDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN);
InputSplit val = valSplit.sample(PATH_FILTER, 1.0)[0];
// Prepare test
File testDir = new File("./Open_I_abd_vs_CXRs/TEST/");
FileSplit testSplit = new FileSplit(testDir, NativeImageLoader.ALLOWED_FORMATS, RAND_NUM_GEN);
InputSplit test = testSplit.sample(PATH_FILTER, 1.0)[0];
System.out.println("train data total sample size " + train.length());
System.out.println("validation total data sample size " + val.length());
System.out.println("test data total sample size " + test.length());
System.out.println("Prepare augumentation....");
ImageTransform flipTransform1 = new FlipImageTransform(new Random(seed));
ImageTransform flipTransform2 = new FlipImageTransform(new Random(seed));
ImageTransform warpTransform = new WarpImageTransform(new Random(seed), inputShape[1]/10);
boolean shuffle = false;
List<Pair<ImageTransform, Double>> pipeline = Arrays.asList(new Pair<>(flipTransform1, 0.9),
new Pair<>(flipTransform2, 0.8), new Pair<>(warpTransform, 0.9));
ImageTransform transform = new PipelineImageTransform(pipeline, shuffle);
// data reader setup
ImageRecordReader recordReaderTrain = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER);
ImageRecordReader recordReaderVal = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER);
/*
* 今回は配布元のデータ構造に合わせるので、
* テストデータは階層のラベルを自動計算させない。
* (利用する際は、データのフォルダ階層を他と同じにして利用する。)
*/
// ImageRecordReader recordReaderTest = new ImageRecordReader(height, width, channels, LABEL_GENERATOR_MAKER);
ImageRecordReader recordReaderTest = new ImageRecordReader(height, width, channels);
try {
// recordReaderTrain.initialize(train);// Train without transformations
recordReaderTrain.initialize(train,transform);// Train with transformations
recordReaderVal.initialize(val);//検証データにはオーグメンテーションをしない
recordReaderTest.initialize(test);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("Start construct SimpleCNN model...");
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder().trainingWorkspaceMode(WorkspaceMode.ENABLED)
.inferenceWorkspaceMode(WorkspaceMode.ENABLED).seed(seed).activation(Activation.IDENTITY)
.weightInit(WeightInit.RELU).optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(new AdaDelta()).convolutionMode(ConvolutionMode.Same).list()
// block 1
.layer(0,
new ConvolutionLayer.Builder(new int[] { 7, 7 }).name("image_array").nIn(inputShape[0]).nOut(16)
.build())
.layer(1, new BatchNormalization.Builder().build())
.layer(2, new ConvolutionLayer.Builder(new int[] { 7, 7 }).nIn(16).nOut(16).build())
.layer(3, new BatchNormalization.Builder().build())
.layer(4, new ActivationLayer.Builder().activation(Activation.RELU).build())
.layer(5, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build())
.layer(6, new DropoutLayer.Builder(0.5).build())
// block 2
.layer(7, new ConvolutionLayer.Builder(new int[] { 5, 5 }).nOut(32).build())
.layer(8, new BatchNormalization.Builder().build())
.layer(9, new ConvolutionLayer.Builder(new int[] { 5, 5 }).nOut(32).build())
.layer(10, new BatchNormalization.Builder().build())
.layer(11, new ActivationLayer.Builder().activation(Activation.RELU).build())
.layer(12, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build())
.layer(13, new DropoutLayer.Builder(0.5).build())
// block 3
.layer(14, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(64).build())
.layer(15, new BatchNormalization.Builder().build())
.layer(16, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(64).build())
.layer(17, new BatchNormalization.Builder().build())
.layer(18, new ActivationLayer.Builder().activation(Activation.RELU).build())
.layer(19, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build())
.layer(20, new DropoutLayer.Builder(0.5).build())
// block 4
.layer(21, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(128).build())
.layer(22, new BatchNormalization.Builder().build())
.layer(23, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(128).build())
.layer(24, new BatchNormalization.Builder().build())
.layer(25, new ActivationLayer.Builder().activation(Activation.RELU).build())
.layer(26, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.AVG, new int[] { 2, 2 }).build())
.layer(27, new DropoutLayer.Builder(0.5).build())
// block 5
.layer(28, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(256).build())
.layer(29, new BatchNormalization.Builder().build())
.layer(30, new ConvolutionLayer.Builder(new int[] { 3, 3 }).nOut(256).build())
.layer(31, new GlobalPoolingLayer.Builder(PoolingType.AVG).build())
//output
.layer(32, new OutputLayer.Builder().nIn(256).nOut(2)
.lossFunction(LossFunctions.LossFunction.MCXENT)
.weightInit(WeightInit.XAVIER)
.activation(Activation.SOFTMAX)
.build())
.setInputType(InputType.convolutional(inputShape[2], inputShape[1], inputShape[0]))
.backpropType(BackpropType.Standard)
.build();
MultiLayerNetwork network = new MultiLayerNetwork(conf);
network.init();
System.out.println(network.summary());
// visualize train process
// URL:http://localhost:9000/train/overview
UIServer uiServer = UIServer.getInstance();
StatsStorage statsStorage = new InMemoryStatsStorage();
uiServer.attach(statsStorage);
// set Stats Listener, to check confusion matrix for each epoch
network.setListeners(new StatsListener(statsStorage), new ScoreIterationListener(1));
/*
* 今回は2クラスしか無いのですが、
* 教師ラベルには、画像の種類(フォルダごと)によって画像に教師ラベルが付きます。
* 例えば、画像1(答えは腹部):(胸部:0, 腹部:1)です。
* このように、対応する方に「1」がつきます。
* この「1」という数字がラベルインデックスです。
* DataSetIteratorは4つの引数がセットできます。
* recordReaderTrain, batchSize, 1, numLabelsです。
* このうち、1の部分がラベルインデックスです。
*/
DataSetIterator traindataIter = new RecordReaderDataSetIterator(recordReaderTrain, batchSize, 1, numLabels);
DataSetIterator valdataIter = new RecordReaderDataSetIterator(recordReaderVal, batchSize, 1, numLabels);
DataSetIterator testdataIter = new RecordReaderDataSetIterator(recordReaderTest, batchSize, 1, numLabels);//1 is a label ind
// Normalization
DataNormalization scaler = new ImagePreProcessingScaler(0, 1);
scaler.fit(traindataIter);
traindataIter.setPreProcessor(scaler);
valdataIter.setPreProcessor(scaler);
testdataIter.setPreProcessor(scaler);
System.out.println("Start training model....");
int i = 0;
while (i < epochs) {
while (traindataIter.hasNext()) {
DataSet trained = traindataIter.next();
// System.out.println(trained.numExamples());//same as batch size
network.fit(trained);
}
System.out.println("Evaluate model at iteration " + i + " ....");
Evaluation eval = network.evaluate(valdataIter);//use nd4j's Evaluation
System.out.println(eval.stats());
valdataIter.reset();//Iteraterを最初に戻す
traindataIter.reset();//Iteraterを最初に戻す
i++;
}
/*
* テストデータのフォルダ階層を他と同じにした場合は、
* 上記のように評価できます。
* フォルダが整理されていなくても、
* 以下のように画像ごとに評価できます。
*/
System.out.println("Test model....");
while(testdataIter.hasNext()) {
DataSet testData = testdataIter.next();
System.out.println("testing... :"+testData.id());
INDArray input = testData.getFeatures();
INDArray pred = network.output(input);
System.out.println(pred);
int predLabel = Nd4j.argMax(pred).getInt(0);//labelある場合
if(predLabel == 0) {
System.out.println("ABDOMEN"+" with praba "+pred.getDouble(predLabel));
}else {
System.out.println("CHEST"+" with praba "+pred.getDouble(predLabel));
}
}
System.out.println("Finish....");
}
}
感想
私の場合は、ここまでできたら、あれはどうだ、こうやったらどうだなど、いろんなことを妄想し始めることが出来ました。
次のステップには、転移学習や、今回うまく活用できていないレイヤーの組み込み方法、複雑なモデル(ComputationGraph)へのレベルアップ(あるいは簡素化のための試行錯誤)、RNNやLSTMの活用、分類問題以外の課題への挑戦、などがあります。
時代の流れに乗って、こういう話題にもついていけるように頑張りたいものです。
Reference
- Hello World Deep Learning in Medical Imaging
- QiitaのDL4J関連の記事を書いてくれた先人たちの知恵
参考POM
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.vis</groupId>
<artifactId>ChestOrAbd</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<nd4j.version>1.0.0-beta4</nd4j.version>
<dl4j.version>1.0.0-beta4</dl4j.version>
<datavec.version>1.0.0-beta4</datavec.version>
<arbiter.version>1.0.0-beta4</arbiter.version>
<logback.version>1.2.3</logback.version>
<dl4j.spark.version>1.0.0-beta4_spark_2</dl4j.spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native</artifactId>
<version>${nd4j.version}</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-cuda-10.0-platform</artifactId>
<version>${nd4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>dl4j-spark_2.11</artifactId>
<version>${dl4j.spark.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-nlp</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-zoo</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>arbiter-deeplearning4j</artifactId>
<version>${arbiter.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>arbiter-ui_2.11</artifactId>
<version>${arbiter.version}</version>
</dependency>
<dependency>
<groupId>org.datavec</groupId>
<artifactId>datavec-data-codec</artifactId>
<version>${datavec.version}</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.3.5</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.11.0</version>
</dependency>
</dependencies>
</project>