やりたいこと
参考書やGithubを見ながら、見様見真似でまずDCGANを試してみたい。
今回は簡易的なDCGANで、胸部X線画像を入力して、似たような画像が生成できるか試す。
環境
- Ubuntu 18.04
- Anaconda 1.9.6
- Tensorflow-gpu 1.12.0
- Keras-gpu 2.2.4
- GeForce GTX 1050 Ti(totalMemory: 3.95GiB freeMemory: 3.89GiB) + AkiTiONODE
必要なもの
日本放射線技術学会「標準ディジタル画像データベース[胸部腫瘤陰影像]」SuperResolution01
http://imgcom.jsrt.or.jp/minijsrtdb/
画像サイズ 256*256、色深度 Gray 8 bitのデータ(一番上段のもの)を選択してダウンロード。
ダウンロードしたら解凍。ここではわかりやすくデスクトップへ。
SuperResolution01.zipをデスクトップに移動して、右クリックから「ここで展開」を実行。
画像の前処理
- デスクトップに新しく「DCGAN01」フォルダを作成する。
- さらに、この「DCGAN01」フォルダの中に「org」フォルダを作成する。
- SuperResolution01内にある「train/org」内のすべての画像と、SuperResolution01内にある「test/org」内のすべての画像とを「DCGAN01/org」にコピー&ペーストする。おそらく、画像は全部で247枚になるはず。
- その後、「DCGAN01/org」内のすべての画像をリネームする。リネームは、画像を全選択して、右クリックなどで名前の変更を行う。この際、ベースになるファイル名は同じになるようにして、末尾に番号が振られるようにすると後の作業がやりやすい。例えば、small_1.png small_2.png small_3.png ...など。
- そして、「DCGAN01/org」内の画像数を「32」で割れる数に合わせる。ここでは例として「224」枚の画像を残すようにする。つまり、225〰247枚目の画像は削除してしまう。
- 次に、新しく「DCGAN01」内に「small_org」フォルダを作る。(この時点で、「DCGAN01」フォルダの直下には、「org」と「small_org」の2つのフォルダができた。)
- 続けて、「DCGAN01/small_org」のフォルダに、「train」フォルダを作成する。ここは重要なので注意(ImageDataGenerater(class_mode=None)への対応)。
- ここまでできたら、このままでは画像のマトリクスが256256となっており、練習には重いので、マトリクスを3232まで落とす。方法はいくつかある。
方法1:ImageJ
ImageJで224枚の画像を一遍にスタックとして開き、リサイズ(補間法は任意でいい)して、任意の一般画像フォーマットで保存する。(おそらく、スクリプトを書かないとマンパワーが、、。)
方法2:コードを書く
'''
Created on 2019/05/05
@author: tatsunidas
'''
import glob, os
import numpy as np
from skimage.io import imread
from scipy.misc import imresize
from PIL import Image
# ここは自分の環境に合わせて下さい
org_dir = '/home/tatsunidas/デスクトップ/DCGAN01/org/'
small_dir = '/home/tatsunidas/デスクトップ/DCGAN01/small_org/'
datasets = glob.glob(org_dir+'*.png')
for data in datasets:
img = imread(data,as_gray=True)
#array to PIL
img = Image.fromarray(np.uint8(img))
# img = imresize(img,(32, 32), interp='bicubic')# return as ndarray
img = img.resize((32,32), Image.BICUBIC)
img.save(small_dir+'train/'+os.path.basename(data))
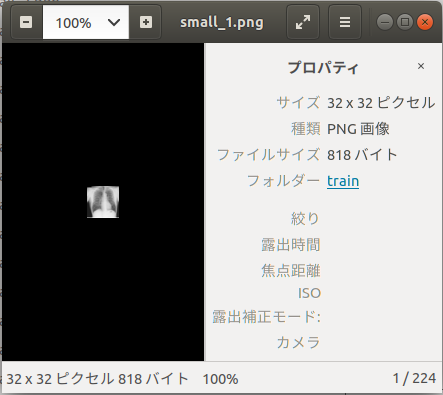
ここまでで、このような状態になる。
画像はすべて32*32マトリクスになっている。
コード
今回はほぼすべて参考URLを参考にさせていただき、組んでみた。DCGANの中でも比較的シンプルでわかりやすい。
'''
Created on 2019/05/05
設定
モデル構築(GAN)
モデルトレーニング
モデル保存
@author: tatsunidas
'''
import os
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
import keras
from keras import layers
import numpy as np
# トレーニングデータの場所
TRAIN_DIR = '/home/tatsunidas/デスクトップ/DCGAN01/small_org/' #trainまで指定しないことに注意
# 生成画像の保存先:任意の場所へ(コードを実行する前にフォルダを作っておいて下さい。)
save_dir = '/home/tatsunidas/デスクトップ/DCGAN01/dcgan_sampling/'
latent_dim = 32 # 殆どの場合、height,widthと同じ値に。
height = 32
width = 32
channels = 1
batch_size=16#とりあえず
# 贋作生成(ジェネレータ)モデルを構築
generator_input = keras.Input(shape=(latent_dim,))
# 入力を16*16,128 channelの特徴マップへ
x = layers.Dense(128*16*16)(generator_input)
x = layers.LeakyReLU()(x)
x = layers.Reshape((16,16,128))(x)
# 畳み込み層を追加
x = layers.Conv2D(256,5,padding='same')(x)
x = layers.LeakyReLU()(x)
# 32,32へアップサンプリング
x = layers.Conv2DTranspose(256,4,strides=2,padding='same')(x)
x = layers.LeakyReLU()(x)
# さらに畳み込み層を追加
x = layers.Conv2D(256,5,padding='same')(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(256,5,padding='same')(x)
x = layers.LeakyReLU()(x)
# 32.32.1の特徴マップへ
x = layers.Conv2D(channels,7,activation='tanh',padding='same')(x)
generator = keras.models.Model(generator_input,x)
generator.summary()
'''
discriminator(贋作判別器)
'''
discriminator_input = layers.Input(shape=(height,width,channels))
x = layers.Conv2D(128,3)(discriminator_input)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128,4,strides=2)(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128,4,strides=2)(x)
x = layers.LeakyReLU()(x)
x = layers.Conv2D(128,4,strides=2)(x)
x = layers.LeakyReLU()(x)
x = layers.Flatten()(x)
# ドロップアウトを追加。重要
x = layers.Dropout(0.4)(x)
# 判別分類
x = layers.Dense(1,activation='sigmoid')(x)
# discriminatorモデルをインスタンス化
discriminator = keras.models.Model(discriminator_input,x)
discriminator.summary()
# オプティマイザで勾配刈り込み(clipvalue)
discriminator_optimizer = keras.optimizers.RMSprop(lr=0.0008,clipvalue=1.0,decay=1e-8)
discriminator.compile(optimizer=discriminator_optimizer,loss='binary_crossentropy')
# 生成と判別をつなぎ合わせる(つまり、GANを構築する)
# discriminatorの重みを凍結
discriminator.trainable = False
gan_input = keras.Input(shape=(latent_dim,))
gan_output = discriminator(generator(gan_input))
gan = keras.models.Model(gan_input,gan_output)
gan_optimizer = keras.optimizers.RMSprop(lr=0.0004,clipvalue=1.0,decay = 1e-8)
gan.compile(optimizer=gan_optimizer,loss='binary_crossentropy')
# training dataの作成
data_gen = ImageDataGenerator(rescale=1./255)
data_gen = data_gen.flow_from_directory(TRAIN_DIR,
target_size=(32,32),
batch_size=batch_size,
class_mode=None,
color_mode= "grayscale")
# GANのトレーニング開始
iterations = 10000 #エポックと同意。とりあえず10000
for step in range(iterations):
#贋作を作るために、無作為にベクトルを作成
random_latent_vectors = np.random.normal(size=(batch_size,latent_dim))
#偽物画像にデコーディング
generated_images = generator.predict(random_latent_vectors)
#本物の画像を取得
real_images = data_gen.next()
combined_images = np.concatenate([generated_images,real_images])
#本物の画像と偽物の画像を区別するラベルを組み立て
labels = np.concatenate([np.ones((batch_size,1)),np.zeros((batch_size,1))])
#ラベルにランダムノイズを追加,重要なトリック
labels += 0.05 * np.random.random(labels.shape)
#discriminator(判別器)を訓練
d_loss = discriminator.train_on_batch(combined_images, labels)
#潜在空間から点をランダムに抽出
random_latent_vectors = np.random.normal(size=(batch_size,latent_dim))
#これらは全て本物というラベルを作成
misleading_targets = np.zeros((batch_size,1))
#ganモデルを通じて、generatorを訓練
a_loss = gan.train_on_batch(random_latent_vectors, misleading_targets)
#訓練過程でモデルと結果を保存
if step % 1000 == 0 or step == iterations-1:
gan.save_weights('gan-discloss_%s_advloss_%s.h5' %(d_loss,a_loss))
#成果を出力
print('discriminator loss at step %s: %s' %(step,d_loss))
print('adversarial loss at step %s: %s'%(step,a_loss))
#生成画像を保存
img = image.array_to_img(generated_images[0]*255.,scale=False)
img.save(os.path.join(save_dir,'generated_chest_'+str(step)+'.png'))
#比較のために本物も保存
img = image.array_to_img(real_images[0]*255.,scale=False)
img.save(os.path.join(save_dir,'real_chest_'+str(step)+'.png'))
if step == iterations-1 :
print('finish iterations')
else:
print('now training gan ..., last step is %s'%(step))
結果


上段は生成画像、下段はオリジナル画像。
左からエポック0,1000,2000,3000,4000,5000,6000,7000,8000,9000
この記事を書いたモチベーション
勉強のために。
その他
誤記などありましたらご指摘下さい。