ゴール
amazon-kendra-langchain-extensionsを参考に、Amazon KendraとOpenAIを使って文書検索をPythonで実行することができます。日本語化にも対応しています。
スタートライン
- AWSアカウントを持っていること
- AWS CLIの設定が完了していること
環境
- Windows 11
- Python 3.11.5
- AWS CLI
ステップ1:IAMユーザーにAmazonKendraFullAccessをアタッチする
任意のIAMユーザーを選択し、「許可を追加」を選択します。
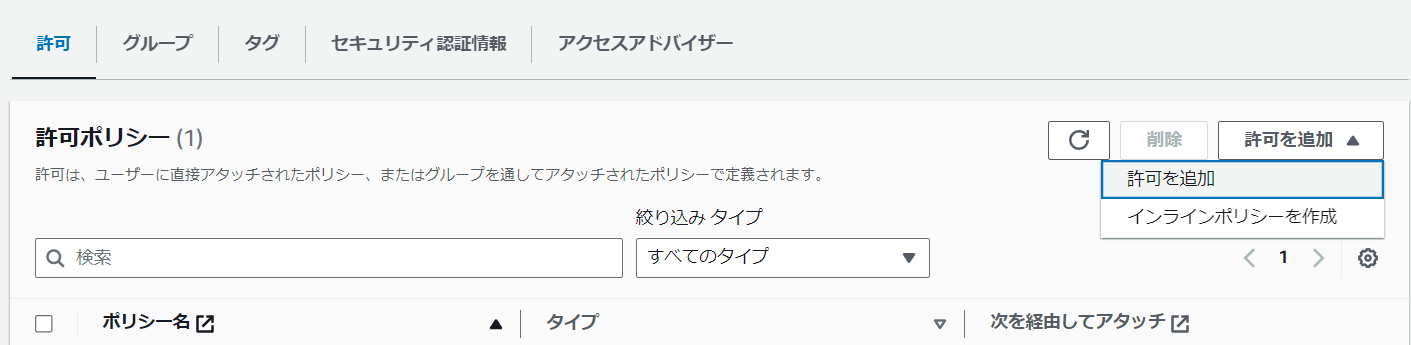
「AmazonKendraFullAccess」と検索し、「次へ」を選択します。
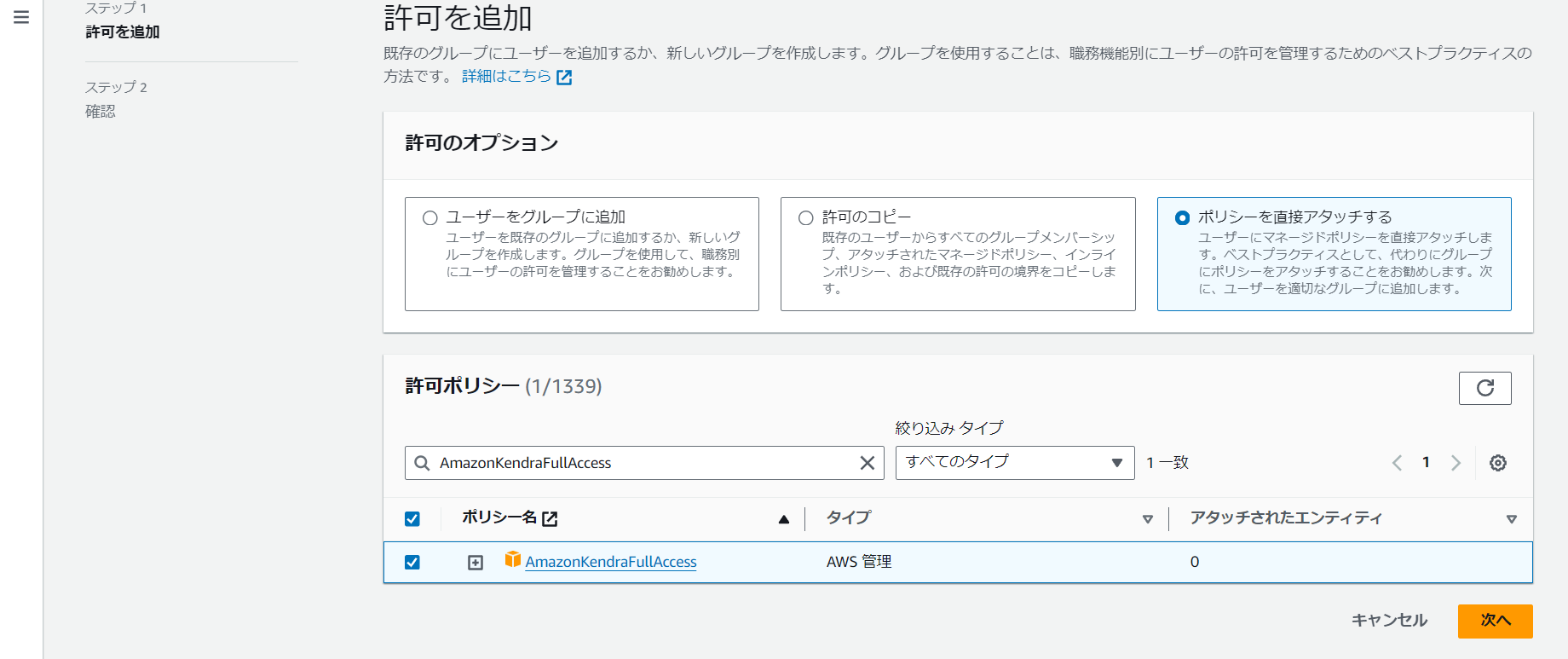
「許可を追加」を選択します。
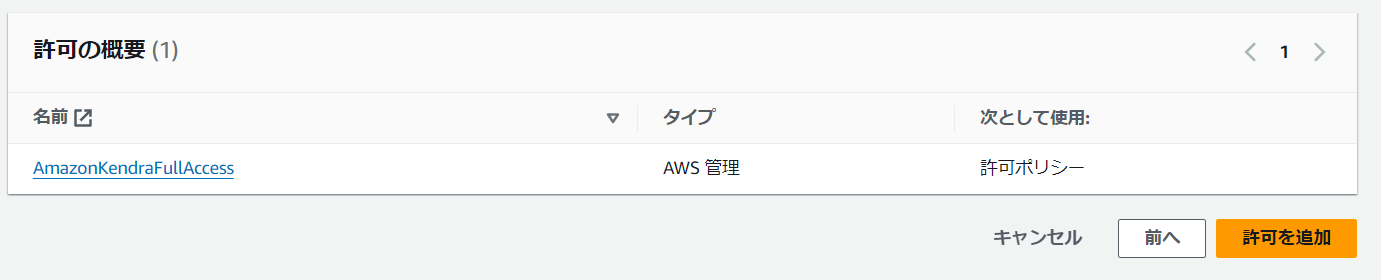
これで任意のIAMユーザーにAmazonKendraFullAccessがアタッチされました。
ステップ2:Amazon Kendra インデックスを設定する
Amazon Kendra consoleにアクセスし、「Create an Index」を選択します。
以下のように、Index nameとIAM role、Role nameを入力します。各項目名はご自身で
決めてください。入力したら「Next」を選択します。
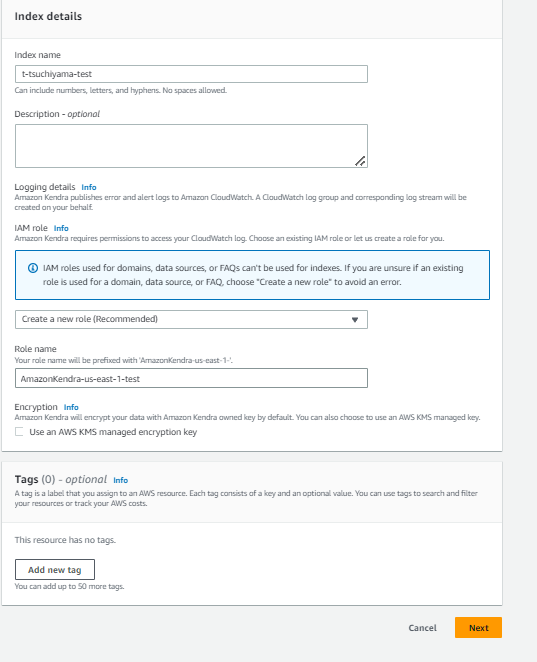
次の画面では、何も変更せずに「Next」を選択します。
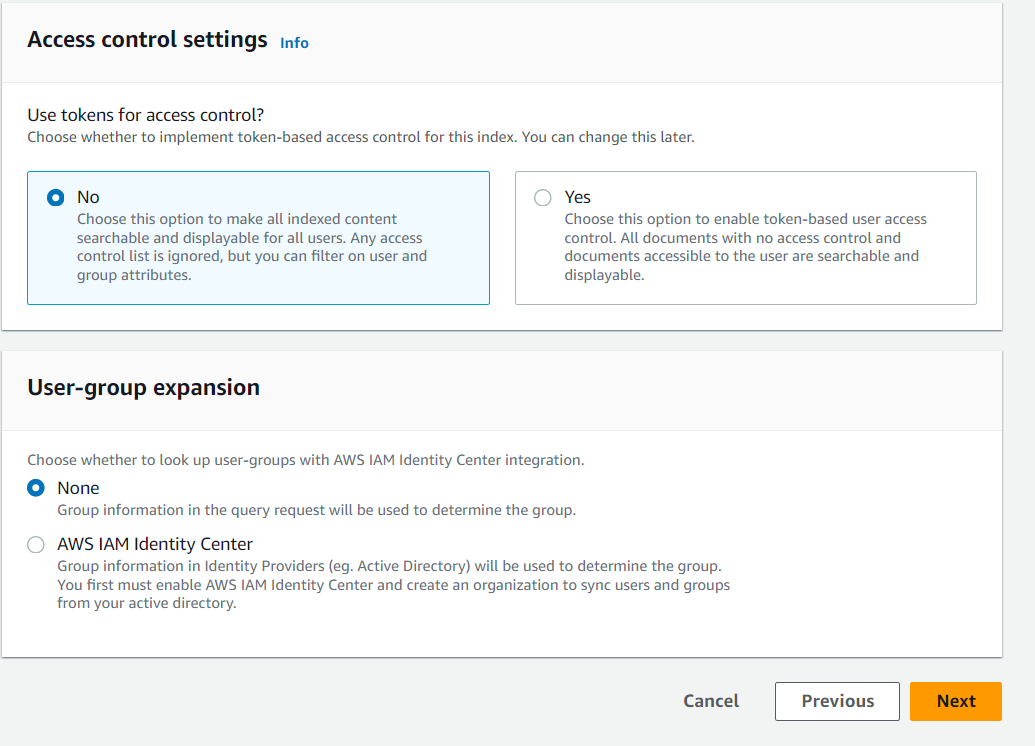
「Developer editions」を選択し、「Next」を選択します。
「Create」を選択します。
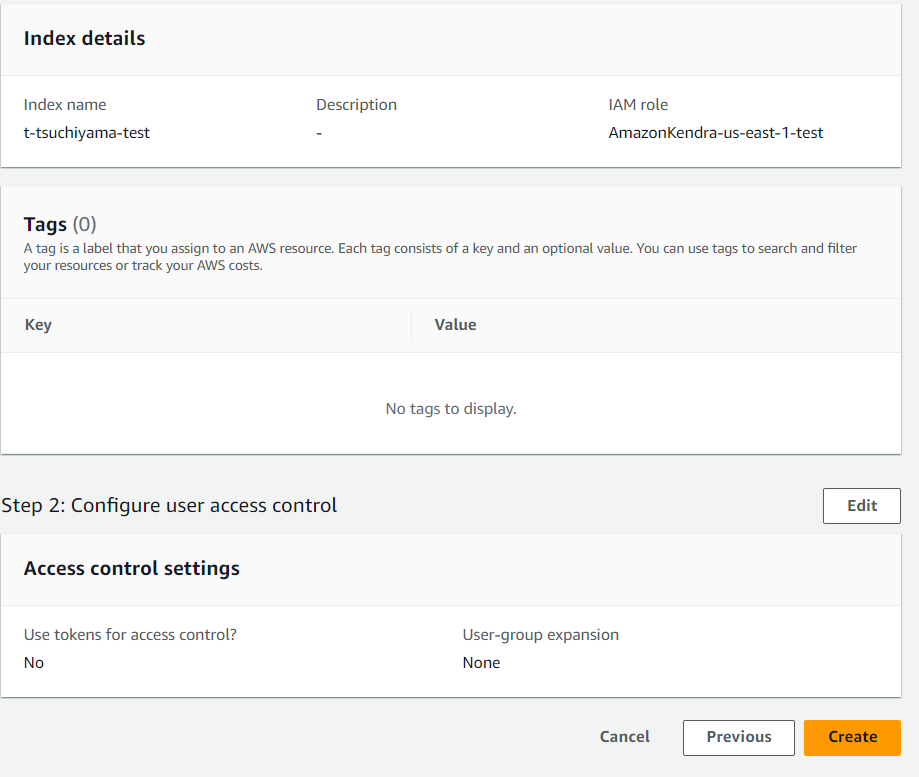
Statusが「Active」になったら、作成完了です。

ステップ3:IAMロールを更新する
IAM consoleで先ほど作成したRoleを選択し、「ポリシーをアタッチ」を選択します。

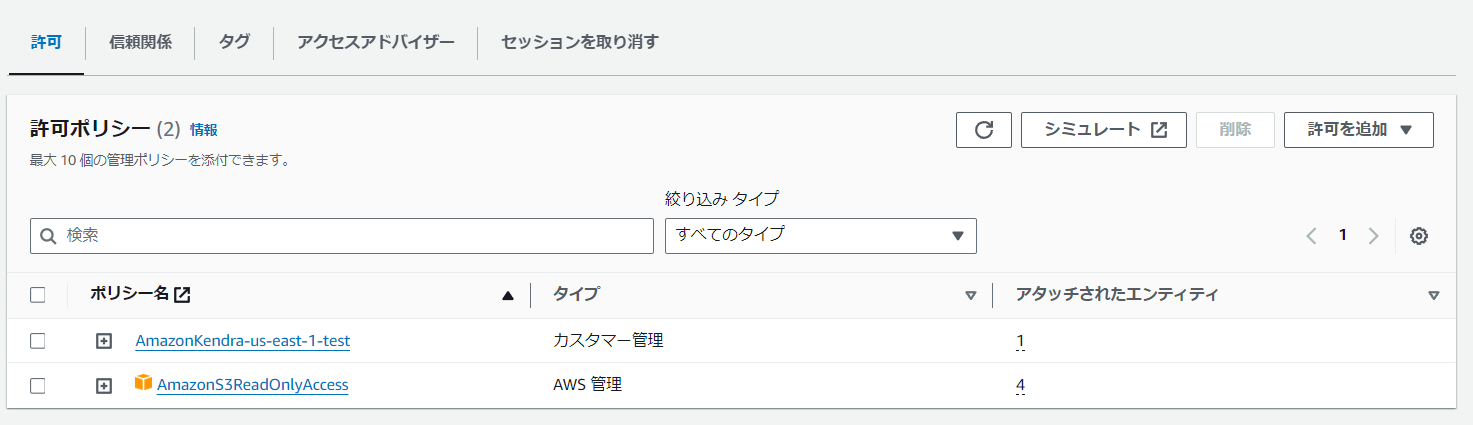
今回はS3を使うため、「AmazonS3ReadOnlyAccess」と検索し、ヒットしたポリシーにチェックを入れた状態で、「許可を追加」を選択します。

許可ポリシーに追加されました。
ステップ4:データソースへのS3コネクタを構成する
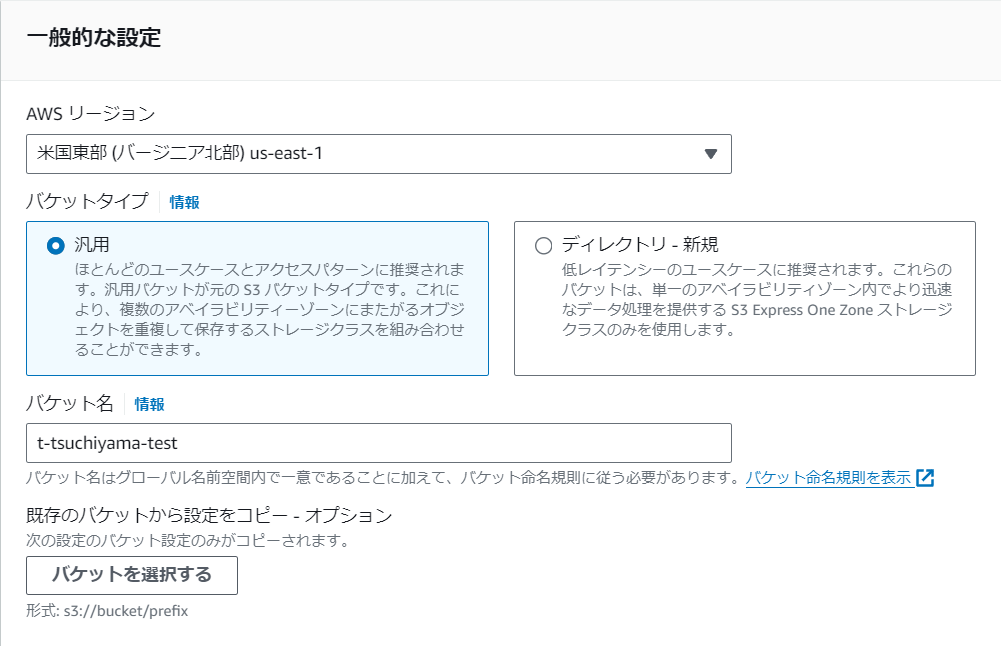
S3のページに移動し、「バケットを作成」を選択します。

AWSリージョンは「米国東部(バージニア北部)us-east-1、バケットタイプは「汎用」を選択し、バケット名を入力してバケットを作成します。
作成したバケットに移動し、「アップロード」を選択します。
今回は以下のAmazon Kendraのデベロッパーガイドをアップロードします。
次に、データソースを作成します。作成したインデックスの画面に移動し、「Data management」の「Data sources」タブを選択すると以下のような画面が表示されるので、「Add data sources」を選択します。
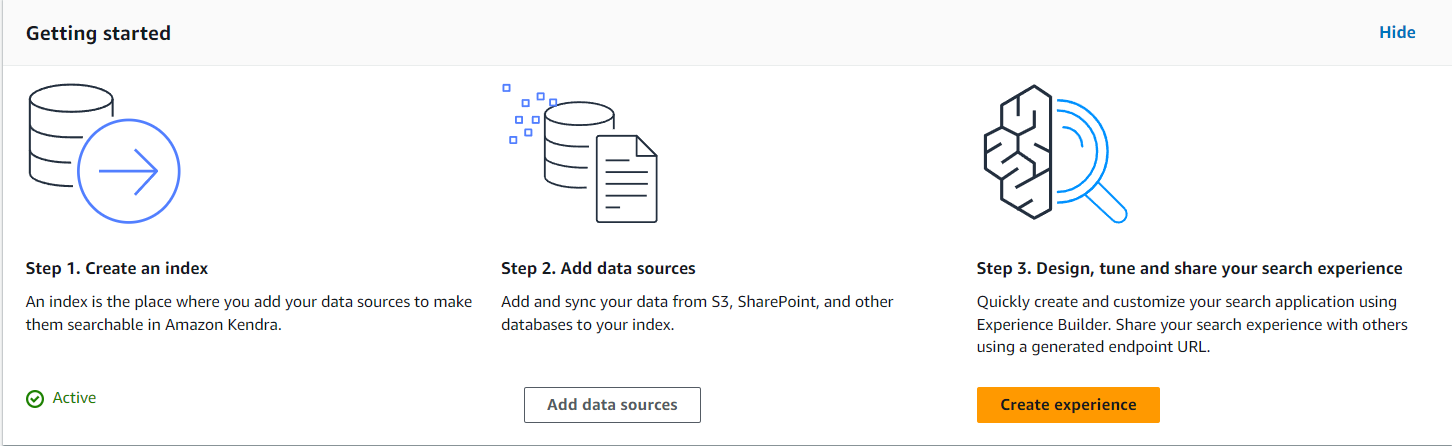
Amazon S3 connecterの「Add connecter」を選択します。
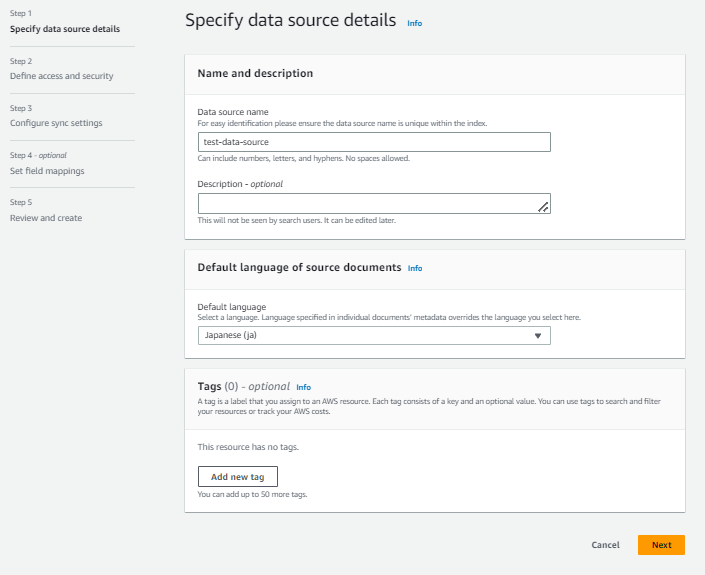
Data sourse nameを入力し、Default Languageは「Japanese(ja)」を選択し、「Next」で移動します。
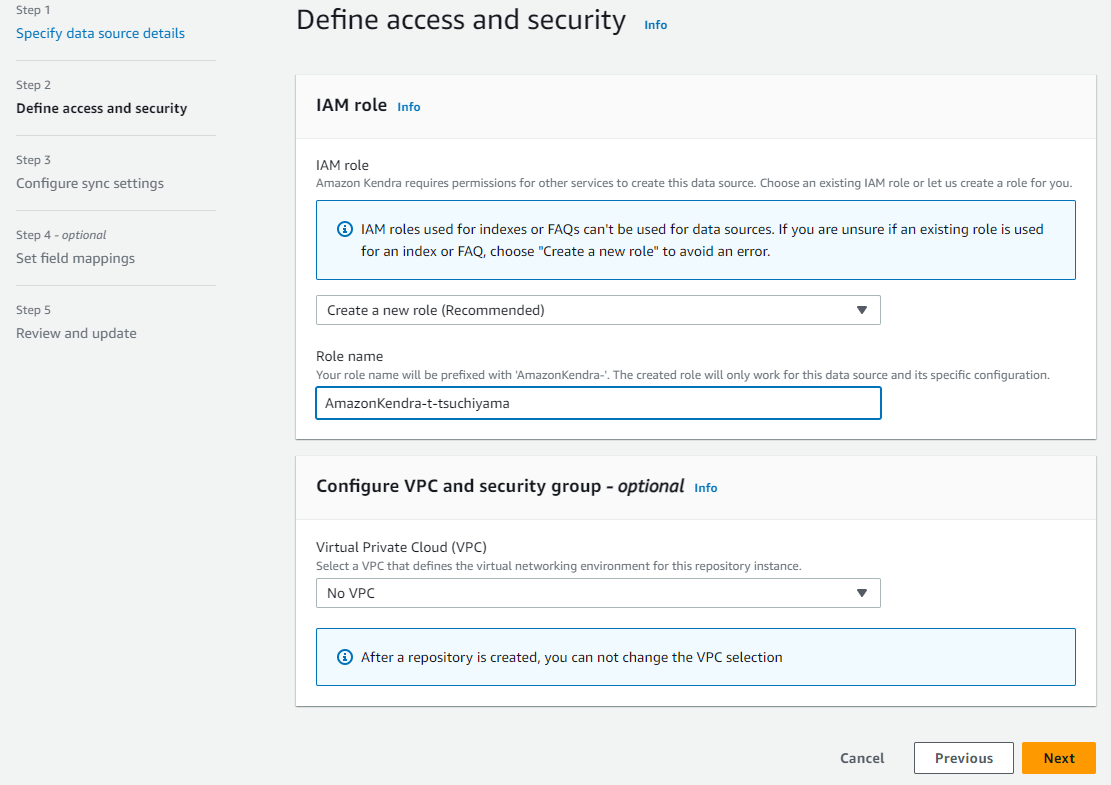
「Create a new Role(Recommended)」を選択し、任意のRole nameを入力して「Next」で移動します。
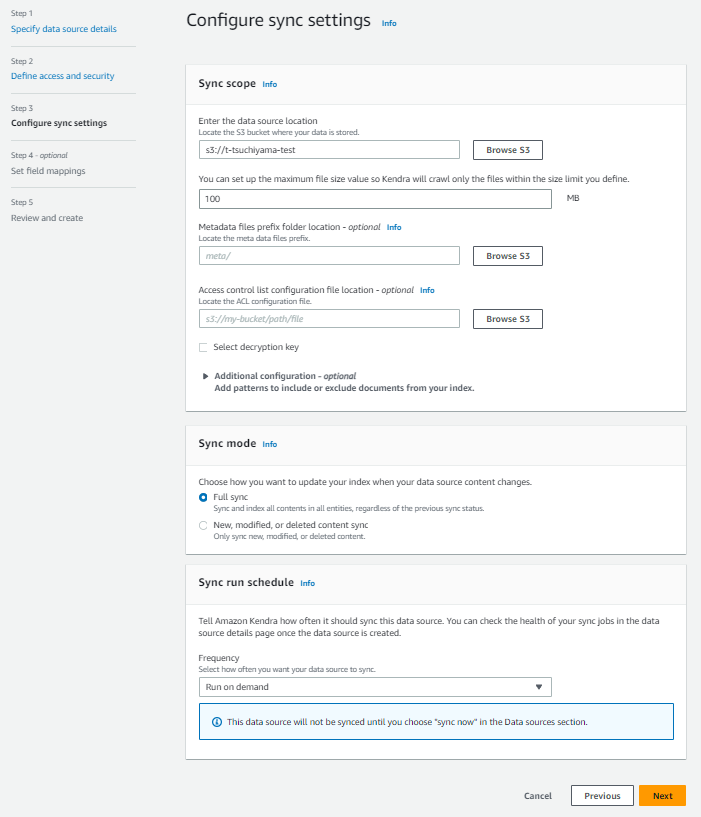
Enter the data source locationには先ほど作成したs3へのパスを通し、Sync modeは「Full sync」、Sync run scheduleは「Run on demand」を選択して「Next」で移動します。
そのまま「Next」で移動します。
確認画面では「Add data source」を選択してください。データソースが作成されます。
データソースの作成が完了したら、以下の「Sync now」を選択してください。
StatusがCompletedになったら完了です。

ステップ5:Search console上で実行する
「Data management」の「Search indexed content」タブに移動し、右側のSettingsのDefault language of sourse documentsから「Japanese(ja)」を選択して、「Kendraの料金」というクエリを実行すると、以下のように結果が返ってきます。

ステップ6:Pythonから実行する
ライブラリのインストール
以下のコマンドで必要なライブラリをインストールします。
pip install langchain openai python-dotenv boto3
環境変数の設定
.envファイルを作成して、以下の変数をご自身の環境に合わせて設定します。
OPENAI_API_KEY = "Azure OpenAIのキー"
OPENAI_API_BASE = "Azure OpenAIのエンドポイント"
OPENAI_API_VERSION = "Azure OpenAIのバージョン"
AWS_REGION = "インデックスを作成したリージョン"
KENDRA_INDEX_ID = "インデックスのID"
コードの追加
https://github.com/aws-samples/amazon-kendra-langchain-extensions/blob/main/kendra_retriever_samples/kendra_chat_open_ai.py を参考に、いくつか変更点を加えた以下のコードを追加します。
from langchain.retrievers import AmazonKendraRetriever
from langchain.chains import ConversationalRetrievalChain
from langchain.prompts import PromptTemplate
from langchain.chat_models import AzureChatOpenAI
import sys
import os
from dotenv import load_dotenv
load_dotenv()
MAX_HISTORY_LENGTH = 5
def build_chain():
region = os.environ["AWS_REGION"]
kendra_index_id = os.environ["KENDRA_INDEX_ID"]
llm = AzureChatOpenAI(
temperature=0,
openai_api_version=os.environ["OPENAI_API_VERSION"],
)
attribute_filter = {"EqualsTo": {"Key": "_language_code", "Value": {"StringValue": "ja"}}}
retriever = AmazonKendraRetriever(
index_id=kendra_index_id, attribute_filter=attribute_filter, region_name=region
)
prompt_template = """
<documents>タグには参考文書が書かれています。
<documents>{context}</documents>
\n\nHuman: 上記参考文書を元に、<question>に対して説明してください。言語の指定が無い場合は日本語で答えてください。
もし<question>の内容が参考文書に無かった場合は「文書にありません」と答えてください。
<question>{question}</question>
\n\nAssistant:
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
condense_qa_template = """
Given the following conversation and a follow up question, rephrase the follow up question
to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
standalone_question_prompt = PromptTemplate.from_template(condense_qa_template)
qa = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
condense_question_prompt=standalone_question_prompt,
return_source_documents=True,
combine_docs_chain_kwargs={"prompt":PROMPT})
return qa
def run_chain(chain, prompt: str, history=[]):
return chain({"question": prompt, "chat_history": history})
if __name__ == "__main__":
class bcolors:
HEADER = '\033[95m'
OKBLUE = '\033[94m'
OKCYAN = '\033[96m'
OKGREEN = '\033[92m'
WARNING = '\033[93m'
FAIL = '\033[91m'
ENDC = '\033[0m'
BOLD = '\033[1m'
UNDERLINE = '\033[4m'
qa = build_chain()
chat_history = []
print(bcolors.OKBLUE + "Hello! How can I help you?" + bcolors.ENDC)
print(bcolors.OKCYAN + "Ask a question, start a New search: or CTRL-D to exit." + bcolors.ENDC)
print(">", end=" ", flush=True)
for query in sys.stdin:
if (query.strip().lower().startswith("new search:")):
query = query.strip().lower().replace("new search:","")
chat_history = []
elif (len(chat_history) == MAX_HISTORY_LENGTH):
chat_history.pop(0)
result = run_chain(qa, query, chat_history)
chat_history.append((query, result["answer"]))
print(bcolors.OKGREEN + result['answer'] + bcolors.ENDC)
if 'source_documents' in result:
print(bcolors.OKGREEN + 'Sources:')
for d in result['source_documents']:
print(d.metadata['source'])
print(bcolors.ENDC)
print(bcolors.OKCYAN + "Ask a question, start a New search: or CTRL-D to exit." + bcolors.ENDC)
print(">", end=" ", flush=True)
print(bcolors.OKBLUE + "Bye" + bcolors.ENDC)
変更点
- dotenvで.envファイルにある環境変数を読み込む
- OpenAIではなくAzureChatOpenAIを使用
- attribute_filterで日本語のドキュメントに対応
- こちらの記事 を参考にしたprompt_templateに
実行
Hello! How can I help you?
Ask a question, start a New search: or CTRL-D to exit.
> Kendraの料金
Amazon Kendraの料金については、参考文書に詳細な情報が記載されています。料金は、Amazon Kendraの使用状況に応じて請求されます。最初の30日間は、最大750時間のAmazon Kendraの使用が無料で利用できるデベロッパーエディションがあります。ただし、試用期間が終了すると、プロビジョニングされたインデックスが空でクエリが実行されていない場合でも、Amazon Kendraプロビジョニングされたすべてのインデックスに対して料金が請求されます。また、試用期間が終 了すると、Amazon Kendraデータソースを使用してドキュメントをスキャンおよび同期するための追加料金がかかります。詳細な料金と価格については、Amazon Kendra料金表をご覧ください。
Sources:
https://t-tsuchiyama-test.s3.amazonaws.com/kendra-dg.pdf
https://t-tsuchiyama-test.s3.amazonaws.com/kendra-dg.pdf
https://t-tsuchiyama-test.s3.amazonaws.com/kendra-dg.pdf
回答結果が日本語で取得できました。
フィニッシュ
お疲れ様でした。
値段が高いので、継続的に使用しない場合は今回作成したリソースは削除しましょう。
以下のXでも情報発信してます!
参考文献