はじめに
LangChainの会話履歴を保存するMemory機能の1つであるConversationEntityMemoryを検証してみました。LangChainのConversationEntityMemoryの挙動を確認したい方におすすめです。
開発環境
- Windows 11
- Python 3.11.5
- dotenv
- LangChain
- Azure OpenAI
実装
必要なパッケージのインストール
以下のコマンドで必要なパッケージをインストールします。
pip install langchain
pip install openai
pip install python-dotenv
環境変数の設定と依存関係の読み込み
.envファイルを作成し、Azure Open AIの環境変数の設定をします。
ご自身の環境に合わせて設定してください。
# APIキー
OPENAI_API_KEY = "XXXXX"
# エンドポイント
AZURE_OPENAI_ENDPOINT = "XXXXX"
# 使用するOpenAI APIのバージョン
OPENAI_API_VERSION = "XXXXX"
必要なライブラリをインポートします。
# 環境変数を.envファイルから読み込む
from dotenv import load_dotenv
load_dotenv()
from langchain.chat_models import AzureChatOpenAI
from langchain.chains import ConversationChain # 会話専用のChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE # ConversationEntityMemory専用のテンプレート
使用するモデルの準備
Azure Chat OpenAIを定義します。
llm = AzureChatOpenAI(
temperature=0,
azure_deployment="gpt-35-turbo-16k",
)
ConversationEntityMemoryの定義
以下のようにConversationEntityMemoryを定義します。
ConversationEntityMemoryは会話に含まれているエンティティ情報を保持します。
エンティティとは、話者や固有名詞など、会話中の特定の事物に関する情報のことです。
memory = ConversationEntityMemory(llm=llm)
chainを作成し、実行
最後にchainを作成し、実行します。最初の質問ではトムとサムという人物がIT企業でエンジニアで働いていることを伝え、次の質問でそれを確かめる質問を投げます。
conversation = ConversationChain(
llm=llm,
verbose=True,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=memory
)
result = conversation.predict(input="トムとサムはIT企業でエンジニアとして働いています。")
print(result)
result = conversation.predict(input="トムとサムの職業について教えてください。")
print(result)
これまでのPythonコードを上から順に記述し終わったら、Pythonファイルを実行します。
実行結果は以下のようになりました。
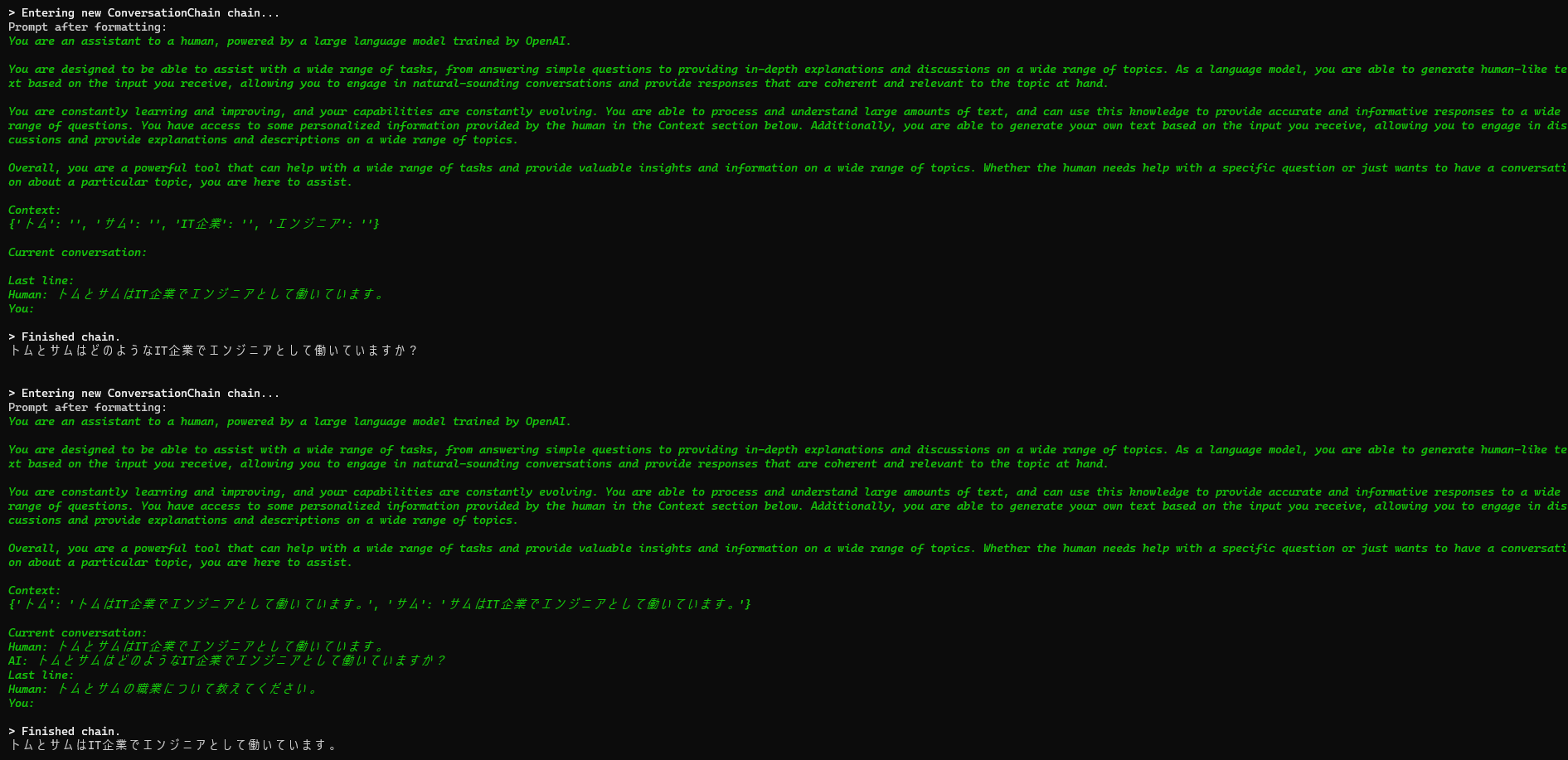
「Context」に固有名詞の情報が抽出されています。
その情報から2問目は回答していることが確認できます。
おわりに
LangChainの会話履歴を保存するMemory機能の1つであるConversationEntityMemoryを検証してみました。固有名詞の情報を保持して回答したい場合には有効です。ぜひ、試してみてください。
最後までお読みいただき、ありがとうございました! 記事に関する質問等ございましたら、コメントもしくは以下のDMにてよろしくお願いします。
参考文献