はじめに
Amazon Bedrockで文書検索をやってみました。ベクトル化にはamazon.titan-embed-text-v1モデル、回答生成にはanthropic.claude-v2モデルを使用しました。
環境
- Windows11
- Python 3.11.5
- LangChain
- OpenAI
- FAISS
- AWS CLI
実装
必要なライブラリのインストール
pip install langchain openai python-dotenv faiss-cpu pypdf PyPDF2 tiktoken boto3
AWS CLIの設定
AWS IAMの「ユーザー」タブに移動して、任意のユーザーを選択または作成します。
「セキュリティ認証情報」タブから、「アクセスキーを作成」を選択します。
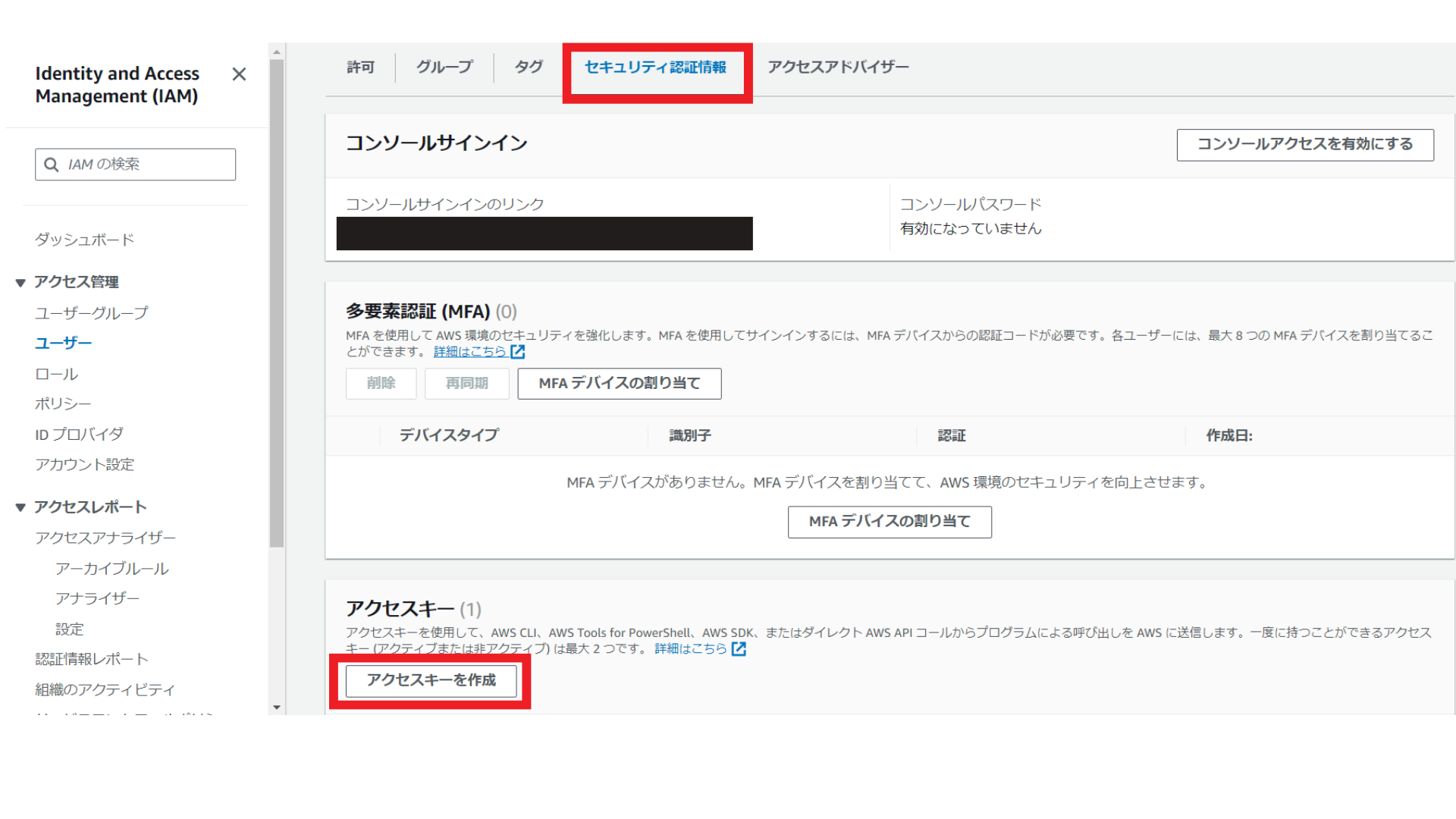
ユースケースは「コマンドラインインターフェイス(CLI)を選択し、「次へ」を選択します。
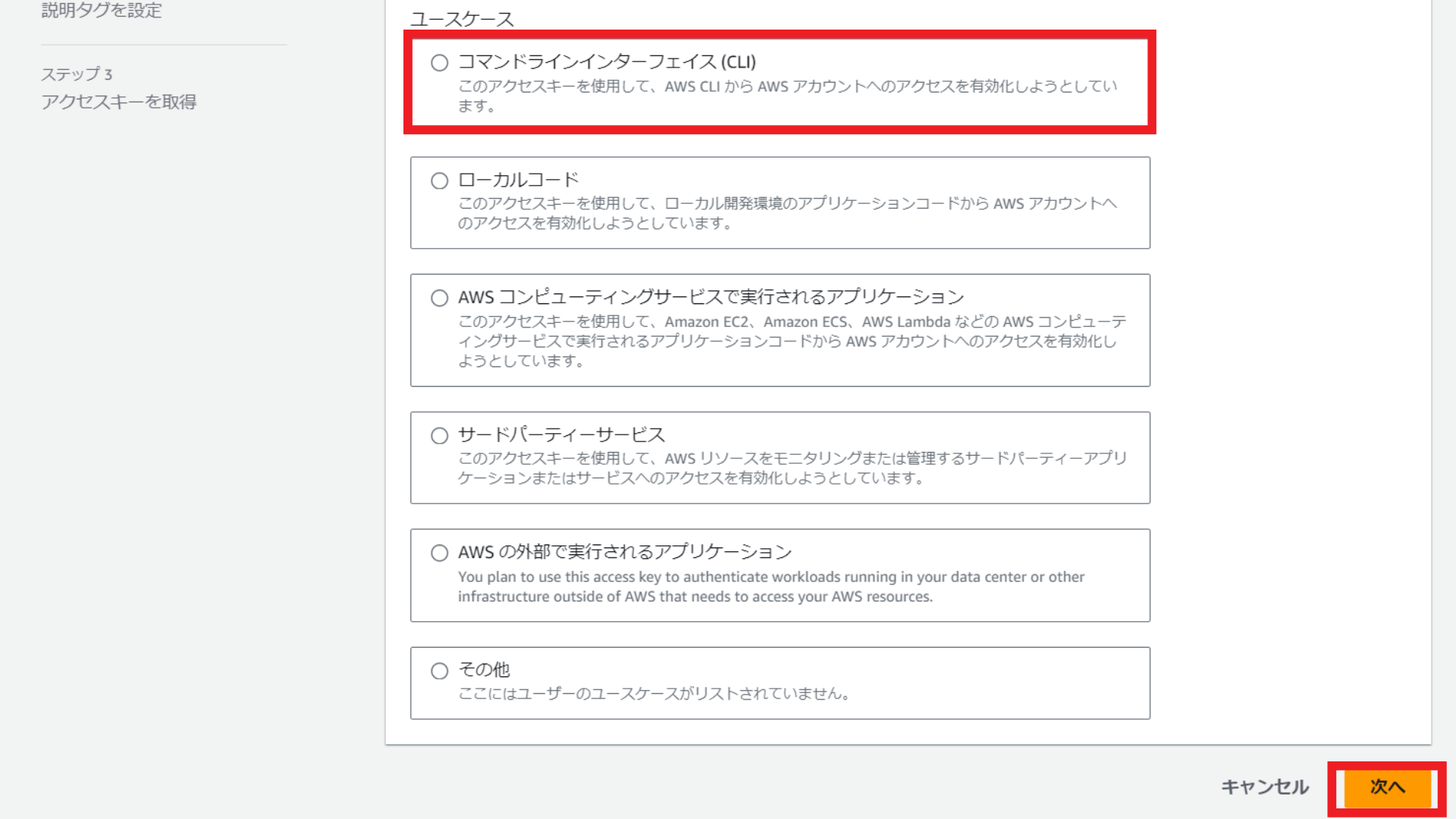
説明タグ値の入力は任意となるため、入力せずに「アクセスキーを作成」を選択します。
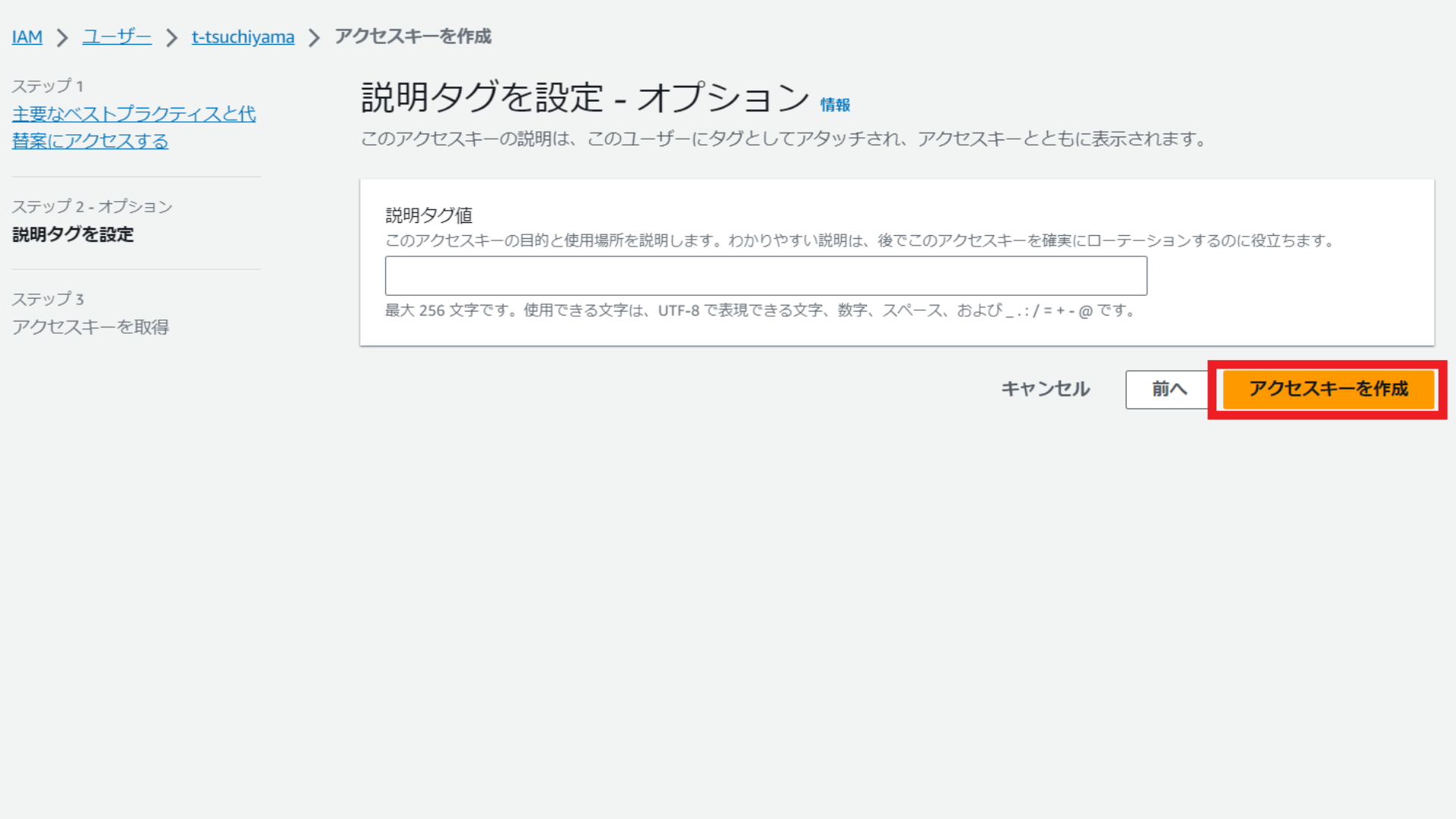
アクセスキーとシークレットキーをメモして「完了」を選択します。
続いて、AWS CLIをインストールしていない場合は、インストールします。
以下の記事を参考にして、インストールしてください。
今回のチャットボットを実行するディレクトリに移動し、AWS CLIがインストールされたかを以下のコマンドで確認します。
aws --version
aws-cli/2.13.29 Python/3.11.6 Windows/10 exe/AMD64 prompt/off
結果が表示されれば、インストールされています。
以下のコマンドで、アクセスキーとシークレットキーを設定します。
最初は空の状態なので、ご自身のアクセスキーやシークレットキーを入力し、エンターキーを押してください。region nameは「us-east-1」、output formatは「json」にしてください。
aws configure
AWS Access Key ID [****************YK63]:
AWS Secret Access Key [****************2DbP]:
Default region name [us-east-1]:
Default output format [json]:
ベクトルストアの作成
まず、PDFをベクトル化してベクトルストアを作成します。
私は以下のAmazon KendraのPDFをベクトル化しました。
vectorstore.py
import os
from langchain.embeddings import BedrockEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1")
dummy_text, dummy_id = "1", 1
vectorstore = FAISS.from_texts([dummy_text], embeddings, ids=[dummy_id])
vectorstore.delete([dummy_id])
dirname = "datasets"
files = []
for filename in os.listdir(dirname):
full_path = os.path.join(dirname, filename)
if os.path.isfile(full_path):
files.append({"name": filename, "path": full_path})
dirname = "datasets"
files = []
for filename in os.listdir(dirname):
full_path = os.path.join(dirname, filename)
if os.path.isfile(full_path):
files.append({"name": filename, "path": full_path})
for file in files:
if file["path"].endswith(".pdf"):
loader = PyPDFLoader(file["path"])
else:
raise ValueError(f"Unsupported file format: {file['path']}")
pages = loader.load_and_split()
for page in pages:
page.metadata["source"] = file["path"]
page.metadata["name"] = file["name"]
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(pages)
vectorstore.merge_from(FAISS.from_documents(docs, embeddings))
vectorstore.save_local("./vectorstore")
コードの解説は以下のとおりです。
- BedrockEmbeddings(langchain.embeddings)
Amazonのamazon.titan-embed-text-v1モデルを使ってテキストの埋め込み(ベクトル表現)を生成します。これにより、テキストの意味的内容を数値ベクトルとして表現できます。
- FAISS(langchain.vectorstores)
Facebook AI Similarity Search(FAISS)を使用して、生成されたテキストのベクトルを効率的に保存し、検索できるようにします。FAISSは、大量のベクトルを高速に検索するためのライブラリです。
- PyPDFLoader(langchain.document_loaders)
PDFファイルを読み込み、処理するためのツールです。PDFの各ページを読み込み、テキストを抽出します。
- CharacterTextSplitter(langchain.text_splitter)
文書を指定されたサイズのチャンクに分割するために使用されます。これにより、大きな文書も効率的に処理できるようになります。
文書検索を実行する
qa.py
from langchain.llms import Bedrock
from langchain.embeddings import BedrockEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
llm = Bedrock(
model_id="anthropic.claude-v2",
model_kwargs={"max_tokens_to_sample": 16000},
)
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1")
vectorstore = FAISS.load_local("./vectorstore", embeddings)
retriever = vectorstore.as_retriever()
chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
results = chain("Amazon Kendraの仕組みについて教えてください。")
print(results["result"])
コードの解説は以下のとおりです。
- LangChainとBedrockのインポート
-
from langchain.llms import Bedrock: LangChainライブラリからBedrockモジュールをインポートします。BedrockはAnthropic社のAIモデル、ClaudeのためのAPIラッパーです。 -
from langchain.embeddings import BedrockEmbeddings: 埋め込み(embeddings)の取り扱いに特化したBedrockEmbeddingsモジュールをインポートします。
-
- FAISSとRetrievalQAのインポート
-
from langchain.vectorstores import FAISS: FAISSはFacebook AI Similarity Searchの略で、大規模なデータセットから効率的に類似アイテムを検索するためのライブラリです。 -
from langchain.chains import RetrievalQA: 質問応答のための複合型チェーンを提供するRetrievalQAモジュールをインポートします。
-
- LangChainモデルの設定
-
llm = Bedrock(...): Claudeモデルの設定を行います。ここで、モデルIDと最大トークン数を指定します。
-
- 埋め込みモデルの設定
-
embeddings = BedrockEmbeddings(...): Amazon Titanのテキスト埋め込みモデルを設定します。
-
- ベクターストアのロードとリトリバーの設定
-
vectorstore = FAISS.load_local(...): ローカルに保存されているFAISSベクターストアをロードします。 -
retriever = vectorstore.as_retriever(): ロードしたベクターストアをリトリバー(検索エンジン)として設定します。
-
- RetrievalQAチェーンの構築
-
chain = RetrievalQA.from_chain_type(...): LangChainモデルとリトリバーを使用して、質問応答チェーンを構築します。
-
- 質問応答の実行と結果の出力
-
results = chain("..."): 指定した質問(ここでは「Amazon Kendraの仕組みについて教えてください。」)に対する応答を取得します。 -
print(results["result"]): 取得した応答を出力します。
上記のPythonファイルを実行すると以下のような結果が返ってきました。
-
Amazon Kendraは、機械学習と自然言語処理を利用したクラウドベースのインテリジェント検索サー
ビスです。
主な特徴は以下の通りです。
- ドキュメントのインデックス作成と検索: Kendraは様々なデータソースからドキュメントを収集し、内容を解析してインデックスを作成します。
ユーザーは自然言語でクエリを行い、関連性の高いドキュメントが検索結果として表示されます。
- インテリジェントなランキング: 検索結果は、ドキュメントの内容とユーザーのクエリの意図に基づいてランク付けされます。Kendraは機械学習を使って、クエリとの関連性が高いドキュメントを上位にランク付けします。
- カスタマイズ可能な検索エクスペリエンス: 検索結果ページのレイアウトや表示方法をカスタマイズできます。また、シソーラスや同義語検索などの機能で検索精度を高めることもできます。
- 多様なデータソースのサポート: S3、SharePoint、Salesforceなど、様々なデータソースからドキュメントを取得できます。
- セキュリティと拡張性: KendraはIAMを使ったアクセスコントロールやVPCエンドポイントによるセキュリティをサポートしています。また、インデックスの容量を拡張することもできます。
このようにKendraは、大量の非構造化データからユーザーが必要とする情報を見つけ出すことを可能にする、インテリジェントなエンタープライズ検索サービスです。機械学習を活用した高度な検索機能と拡張性の高さが特徴です。
おわりに
お疲れ様でした!
参考文献は以下のとおりです。