はじめに
初めまして!東大学部4年(機械工学科ベンチャー研)の上條と申します.OMRON SINIC Xインターン生で,TRAILにもよく顔を出させてもらっています.ロボットと環境の物理的な接触の多い,contact-richマニピュレーションを解くことに興味があります.
本記事は基盤モデル×Robotics Advent Calendar 2023の23日目の記事です!
Google X, DeepMindの研究者による論文"Robust Multi-Modal Policies for Industrial Assembly via Reinforcement Learning and Demonstrations: A Large-Scale Study" を紹介します.少し古い(?)ですが,RSS2021に採択された論文です.
この論文は,高い精度を要求される物体挿入タスクを遂行するための模倣学習の手法SHIELD(Super-Human InsErtion using Learning from Demonstration)を提案したものです.基盤モデルのトピックとは少し離れていますが,LLMやVLMのような大規模モデルはハイレベルなreasoningでは強力な一方で,マニピュレーションに着目すると多くがPick and Placeレベルに留まり,環境との接触を伴うようなタスクには大きな課題が残ります.そこで今回は,そのようなcontact-richマニピュレーションタスクの代表である挿入タスクを学習で解いた論文を紹介します.
目次
背景
産業用ロボットの応用は現在,完全に整理された環境下での反復的な動作が多くを占めています.外乱へのロバスト性が期待される学習ベースの手法は多く提案されてきていますが,産業レベルのクリアランス(挿入物体と対象の穴の隙間)での挿入は難しく,未だ実際に広く応用されるには至っていません.この論文は,産業レベルの精密な挿入作業を実現する実応用にフォーカスし,その実現のための強化学習・模倣学習の"a collection of design choices"であるSHEILDを提案し,複数のconnectorや動いているターゲットへの挿入タスクで評価しています.
SHIELDの何がすごい
まずは動画を見ていただくと,SHIELDのロバスト性の高さがわかると思います.1'20"の動くソケットに対するHDMI挿入タスクでは,人間より早く挿入に成功しています(ちょっとスタートずれていて怪しいですが).名前のSuper-Human Insertionも納得できます.
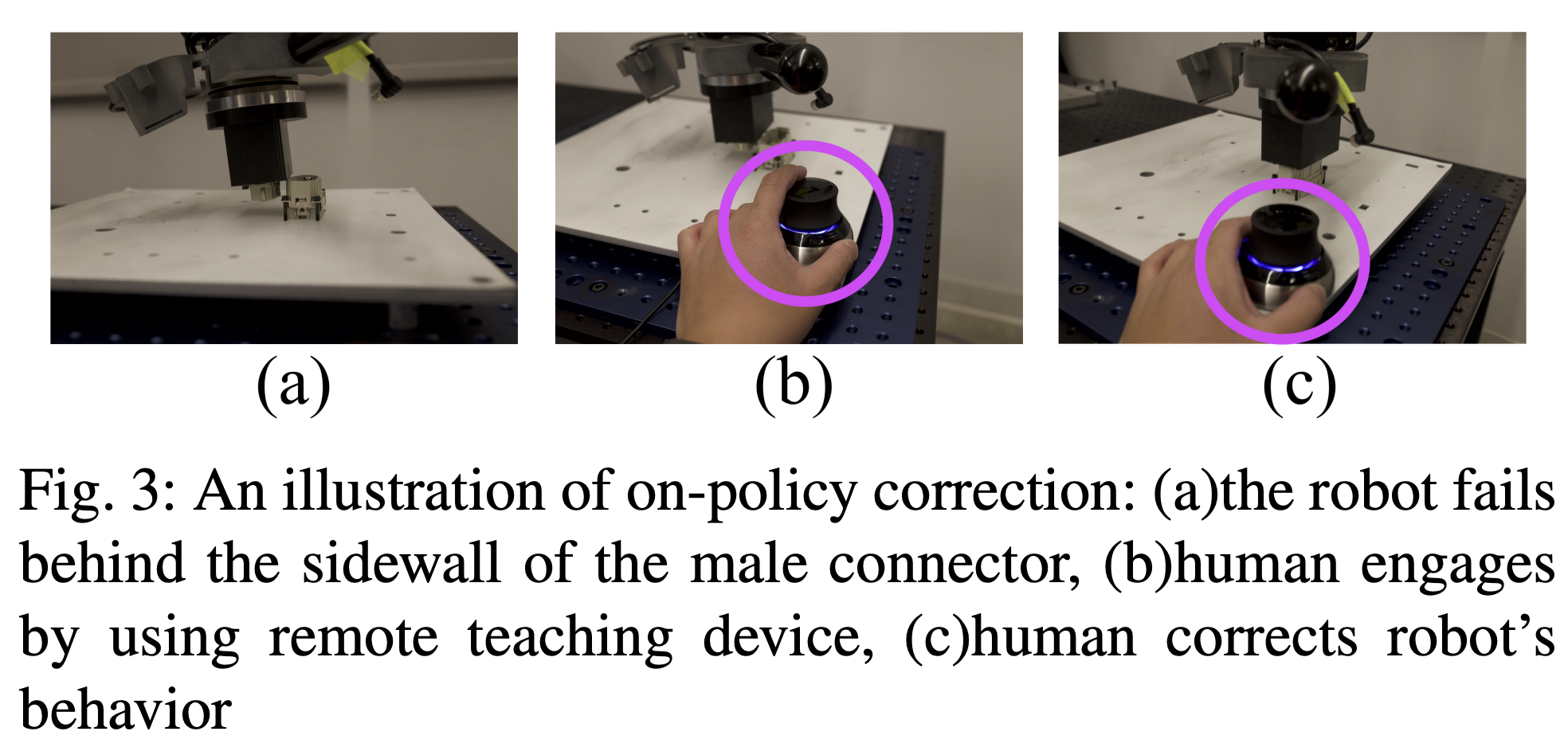
これを実現した大きなポイントとしては,ロボットのタスク失敗時に人間がデバイスを使って介入し,on-policy correctionを行うことで効率的な学習を可能にしたことがあります.単純な強化学習では長時間の探索によって,挿入失敗から復活する動きを学習しなければならないのに対し,人間の介入によってこの探索を省いたことになります.Expert方策と学習中の方策の乖離を防ぐ点でDAgger的なアプローチといえます.
論文概要
ここでは,まず学習の流れを簡単に述べ,Deep Deterministic Policy Gradient from Demonstration (DDPGfD)に基づいているSHIELDの,DDPGfDからの変更点をまとめます.
模倣学習の流れ
- 人間によるデモンストレーションを集め,replay bufferに保存
- 現在の方策をroll outし,さらにデータを集める
- 必要であれば人間が助ける(これはロボットが取った行動としてreplay bufferに保存される)
- アクター・クリティックのネットワークを上記データ収集と非同期で学習
DDPGfDからの変更点
そもそもDDPGとはDeep Q learningを連続的な行動空間に拡張したoff-policyの強化学習アルゴリズムです.ここで,最初から学習するのは大変なので,人間によるデモンストレーションが良い初期方策として使えます.DDPGにデモンストレーションを組み込むために改良されたのがDDPGfDです.以下が,SHIELDにおける変更点です.
-
アクターネットワークへのガウシアンノイズの除去
オリジナルのアルゴリズムでは方策からサンプリングした行動にガウシアンノイズを加えることで探索を促進していますが,ここではデモンストレーションが探索を担っていること,精密な挿入タスクではこの探索が邪魔なことからノイズを除去しています. -
Replay bufferでの優先度付けなし
Replay bufferの中で,予測された報酬と実際の報酬の差分を表すTD-errorの大きいもの(重要な情報を含む経験)を優先的に学習に使うような優先度付けはRLでよく行われますが,今回の設定ではパフォーマンスが低下したため,人間のon-policy correctionを含む全てのデータから均一サンプリングをしたと論文中で述べられています.RLfDの設定では,TD-errorを用いることで,現在の方策とは大きく異なる初期の経験を不適切に優先させてしまい,学習が誤った方向に進んでしまったのではないかというのが著者らの考察です. -
人間によるon-policy correction
SHIELDの何がすごいでも述べましたが,現在の方策をroll outして経験を集めている際に,挿入が失敗する可能性があります.ここで,人間がデバイスを用いて行動を修正し,ロボットの行動としてreplay bufferに保存します.アルゴリズムがoff-policyなため,この人間による修正を含む一連の行動はきちんと方策の学習に利用されます(on-policyの場合,現在の方策と人間による修正が違いすぎるため,うまく学習に利用されない).
実験
NIST board insertion tasksというAssemblyタスクに取り組んだ論文でよく見るベンチマーク,動くターゲットにHDMIを挿入するタスク,ドアの鍵を挿入するタスクを用い,挿入の成功率/遂行時間で評価を行っています.
エージェントの観測は,以下のFig. 4(a)~(d)の4通りです.
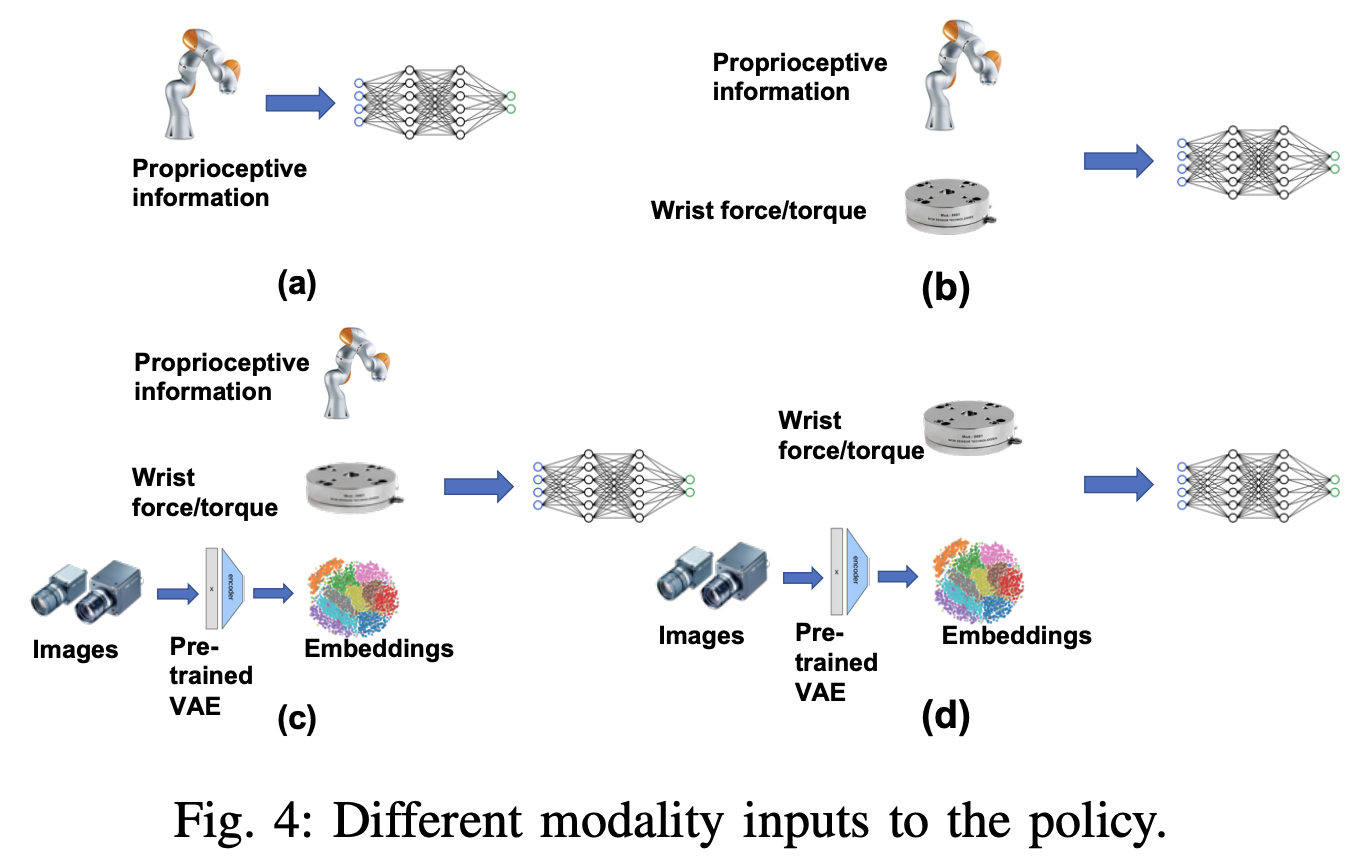
このうち,各タスクのモダリティは
| タスク | 対応する図 |
|---|---|
| NIST board insertion tasks | (a), (b), (c) |
| Moving target HDMI | (d) |
| ドアの鍵挿入 | (b) |
で実験・比較が行われています.
詳細な実験結果・実験の様子は論文と,論文のWebsiteに譲ります.Websiteの方にたくさん動画が載っているので見てみると面白いです.
まとめ
本記事では,産業レベルの挿入タスクに模倣学習で取り組んだ論文"Robust Multi-Modal Policies for Industrial Assembly via Reinforcement Learning and Demonstrations: A Large-Scale Study"を紹介しました.SHIELDの手法自体は比較的シンプルで,誤解を恐れずに言うと「論文っぽくない」ですが,実応用性に強いフォーカスを置いて実ロボットで実際の挿入タスクをきちんと解いているのが好きで,紹介させていただきました.
これだけうまくいっている動画を見せられると,学習ベースの手法の産業応用はますます加速するだろうなと感じます.
現状基盤モデルとロボティクスの結び付きでは,visionベースのハイレベルなプランニングは得意ですが最終的に手元で行っているのはpick and placeなど手先のフィードバックが必要ないタスクが多いと思います.しかし,今回取り上げられた挿入作業のような接触が多く発生するタスクをロボットが行う際には,力や触覚のデータが重要です.視覚データと力覚・触覚データを組み合わせた大規模なデータセットが得られた場合に,モデルが各タスクに適切な力加減の調整を学習できるかというところは気になっています.
今回は以上になります.ありがとうございました!