こんにちは、こちらはTreasure Data Advent Calendar 9日目の記事です。
今回は、TDを利用する際に行っている簡単な監視について紹介いたします。
背景
SQLに慣れているエンジニア以外の人たちにもTDの利用を解放すると、どうしても効率的でないクエリが投げられてしまうことがあります。そうしたクエリがたくさん投げられてしまうと、計算リソースを消費してしまいTDとはいえジョブの実行が滞ってしまうことがあります。そうなるとログを集計したいと考えている人たちの作業が滞ってしまいます。そのため、TD上で現在実行中のジョブの監視をしています。
以下では、具体的な監視内容を紹介いたします。
全体的なジョブ数の監視
どのくらいジョブが実行されているかざっくりと知るために、10分置きに現在実行中のジョブ数を表示しています。スクリプトで実行して集計はしていますが意味合い的には
td job:list -R NUM
を行っています。
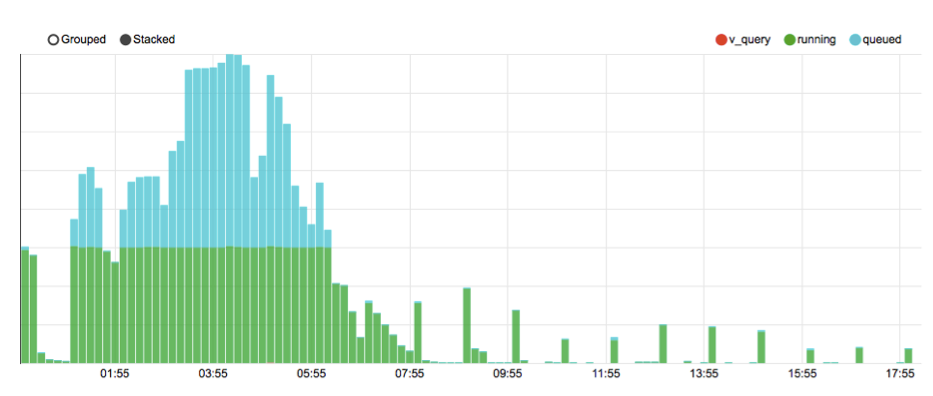
td job:list -R NUMは、running(実行中)状態のジョブ以外に、queued(実行待ち)状態のジョブ数も取得できます。上のグラフでは緑色の部分が実行中のジョブ数、水色の部分がqueued状態のジョブ数を表しています。
他にも、取得したジョブの情報からクエリをパースして、v['hoge']というフレーズを使っているクエリ数も表示するようにしています。v['hoge']に関しては、こちらにあるようにスキーマを貼っていない要素に対してアクセスするために利用するものですが、vを利用した場合とてもクエリが重くなってしまいます。こうしたクエリが投げられているのを見つけ、スキーマを利用したクエリに書きかえるようにアナウンスし注意を促しています。
また、深夜に大量に走っているバッチが朝のうちににあらかた終わっているのを確認するのにも利用しています。
queued状態なジョブ数の監視
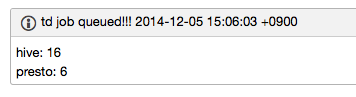
深夜のバッチのジョブがqueued状態になってしまうのは仕方ありませんが、日中に詰まってしまうとサービスのチームがログの集計をすることができなくなってしまうので、日中にqueued状態なジョブが無いかも監視しています。日中はhourlyで動いているバッチ以外では、アドホックなクエリが多く投げられる時間です。アドホックなクエリは扱うデータ量も少なく、日中にジョブがqueued状態になることはほとんどないのですが、
- 誤ってアクセスログを全て舐めてしまうようなクエリを投げてしまった
- スクリプトなどでクエリを誤って大量投入してしまった
- 反応がすぐ返ってこなかったので同じクエリを何度も投げてしまった
などが原因で詰まってしまうことがあり、prestoが利用できるようになってからはprestoのジョブが3.が原因で詰まることが増えました。「presto = 速い」という印象からでしょうか。(実際とても早く助かっております :))
もし、queued状態なジョブがいくつか見つかった場合にはチャットに連絡が入るようにしています。
長時間running状態なジョブの監視
誤ってテーブルを全て舐めるクエリや、それをJOINするクエリを投げてしまい、1日以上走っているジョブがいたことがあったので監視するようにしました。深夜のバッチは数時間は当たり前なので、こちらも日中のみ監視するようにしています。
こちらも設定した時間以上running状態なジョブが見つかった場合にはチャットに連絡が入るようにしています。
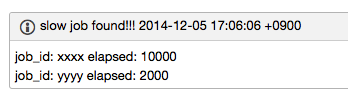
長時間running状態なジョブの監視については、日中以外にも情報を収集し実行時間が長いジョブをリストアップしています。多くの場合、time indexが効いていないことや巨大なテーブルのJOINなどが原因ですので、修正方法のアナウンス等をしています。
まとめ
TD上で実行中のジョブ数や、ジョブの実行時間の監視について紹介しました。アドホックなクエリの異常は、実際に異常なのか意図して長いクエリを投げているのかは利用者側が確認しないとわからないものなので、非常に簡単な項目ではありますが監視をしています。私達のチームとしては、サービスのチームより先に異常を検出しこちらから問い合わせられるようにしています。
多くの場合投げたクエリが原因なので、検出後はクエリの改善方法を添えて連絡しています。ちょっとした工夫として、TDへクエリを投げるとコメントとしてユーザ名がクエリの先頭につくようにしてあり、誰が投げたのか追いやすくしています。また、スクリプトや他のツールから投げている場合も同様にツール名などをコメントとしてつけるように依頼しています。
以上、9日目の記事でした!