はじめに
本記事では交互作用特徴量について解説しています。本記事は主に「機械学習のための特徴量エンジニアリング」を参考とさせて頂いておりますので、気になる方は是非チェックしてみてください。
※本記事で解説するプログラムは全てこちらにあります。
交互作用特徴量とは
複数の特徴量を掛け合わせて新たな特徴量を作るという手法です。この中でで特に2つの特徴量を組み合わせるものをペアワイズ交互作用特徴量と呼びます。また、特徴量が二値である場合は論理積となります。
例えば特徴量として地域と年齢層がある場合に、地域と年齢層を掛け合わせることで「20代」と「東京住み」の情報から「東京住みの20代」という目的変数をより表現できる情報を作成することができるのです。
しかしデメリットとして、学習コストが増大することと、不要な特徴量を作成してしまうことが考えられます。この学習コストの増大と不要な特徴量の問題は特徴量選択を行うことで解決することができます。
例えば以下のような特徴量データがあったとします。

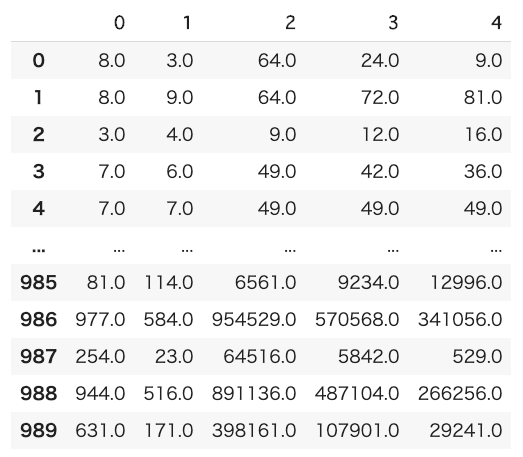
このデータに対して交互作用特徴量を作成すると以下のようなデータセットが作成されました。
以下では実際に交互作用特徴量を実装するサンプルコードを示します。
import numpy as np
import pandas as pd
import sklearn.preprocessing as preproc
## 乱数固定
np.random.seed(100)
data_array1 = []
for i in range(1, 100):
s = np.random.randint(0, i * 10, 10)
data_array1.extend(s)
## 乱数固定
np.random.seed(20)
data_array2 = []
for i in range(1, 100):
s = np.random.randint(0, i * 10, 10)
data_array2.extend(s)
data = pd.DataFrame({'A': data_array1, 'B': data_array2})
## 交互作用特徴量
data2 = pd.DataFrame(preproc.PolynomialFeatures(include_bias=False).fit_transform(data))
## interaction_only=Trueとすることで自身の値の二乗を除くことができます
# data2 = preproc.PolynomialFeatures(include_bias=False, interaction_only=True).fit_transform(data)
最後に
YouTubeでITに関する動画を上げていこうと思っています。
YoutubeとQiita更新のモチベーションに繋がるため、いいね、チャンネル登録、高評価をよろしくお願い致します。
YouTube: https://www.youtube.com/channel/UCywlrxt0nEdJGYtDBPW-peg
Twitter: https://twitter.com/tatelabo