pandasのgroupbyがなかなか便利だったのでチートシートっぽいものを作っておく。
ほぼ自分用のメモ。
参考にさせていただいたサイトなど
詳しいことは下記のリンクを参照
pandasのドキュメント
https://pandas.pydata.org/pandas-docs/stable/reference/groupby.html
nkmk.meさんのサイト
https://note.nkmk.me/python-pandas-groupby-statistics/
Takashi Yamamiyaさんの記事
https://qiita.com/propella/items/a9a32b878c77222630ae
環境とか
python 3.7.2
pandas 0.23.4
データとかの準備
データはseabornのirisを使ってみる。
qiit.rb
import pandas as pd
import seaboan as sns
df = sns.load_dataset('iris')
どんなグループ分けができるのか未知のデータとかをざっくり調べるときに使えるかも。
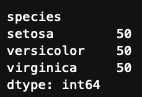
species別にどれだけデータが入っているか?
qiit.rb
df.groupby('species').size()
.indexでグループのリストも取得できる。
qiit.rb
GroupList = df.groupby('species').size().index

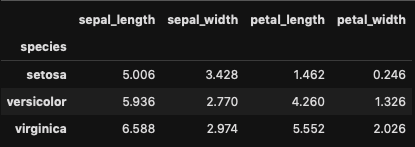
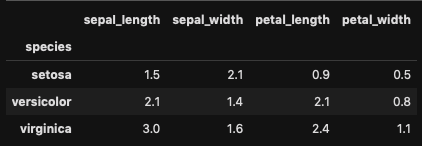
各グループの平均とか
データフレームに対してだとデータフレームの各列の平均とかのデータフレームが返ってくる。
qiit.rb
df.groupby('species').mean()
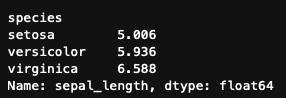
データフレームのある列(シリーズ)に対してなら下記
qiit.rb
df.groupby('species').mean()['sepal_length']
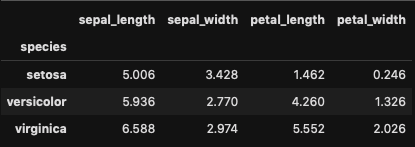
numpyの関数とか使うなら
.aggを使う。
qiit.rb
df.groupby('species').agg(np.nanmean)
df.groupby('species').agg(np.nanmean)['sepal_length']
.aggは自作関数もOKみたい。
qiit.rb
def TEST_DEF(DF):
DF_MAX = DF.max()
DF_MIN = DF.min()
return DF_MAX - DF_MIN
df.groupby('species').agg(TEST_DEF)
他にも気が向いたら更新していく予定。