はじめに
本記事はC#用ライブラリの「ExcelDataReader」を使い方をサンプルを交えて述べる記事です。
ExcelDataReaderとは
C#でExcelファイル(xls,xlsxファイル)を読み込むためのライブラリです。読み取り専用であるため、軽量であることが特徴です。
詳細はこちらを参照ください。
ExcelDataReaderを使ってみる
やりたいこと
以下のようなウェブページの閲覧ログデータにおいて、ページごとのユニークユーザー数を算出するプログラムをC#で作成していきます。
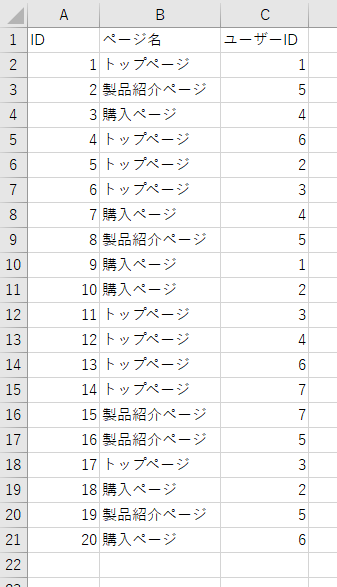
以降で必要な手順を記載していきます。
必要なNuGetパッケージのインストール
まずは、NuGetパッケージ「ExcelDataReader」と読み取った情報を扱いやすいDataSet型で扱うための拡張パッケージ「ExcelDataReader.DataSet」の2つをインストールします。
VisualStudioでプロジェクト作成後に作成したプロジェクトをソリューションエクスプローラー上で右クリックし、[NuGetパッケージの管理]メニューを実行します。
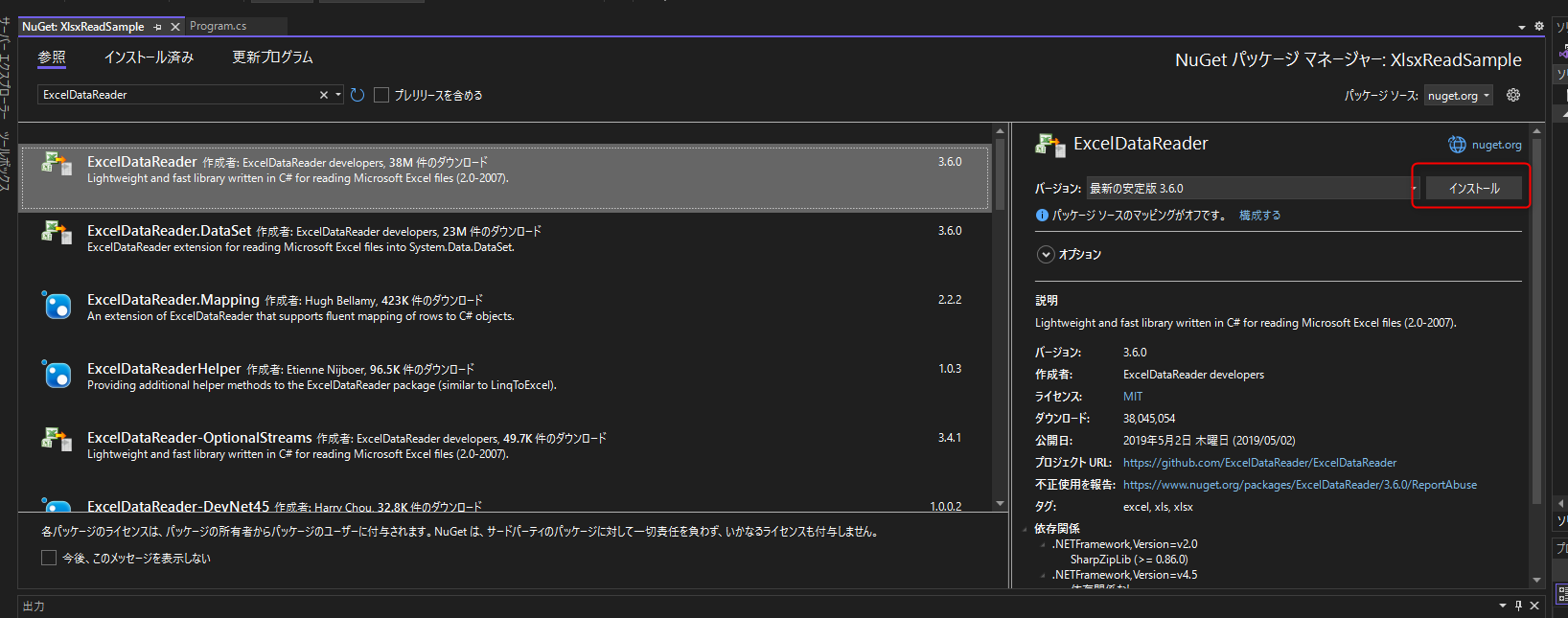
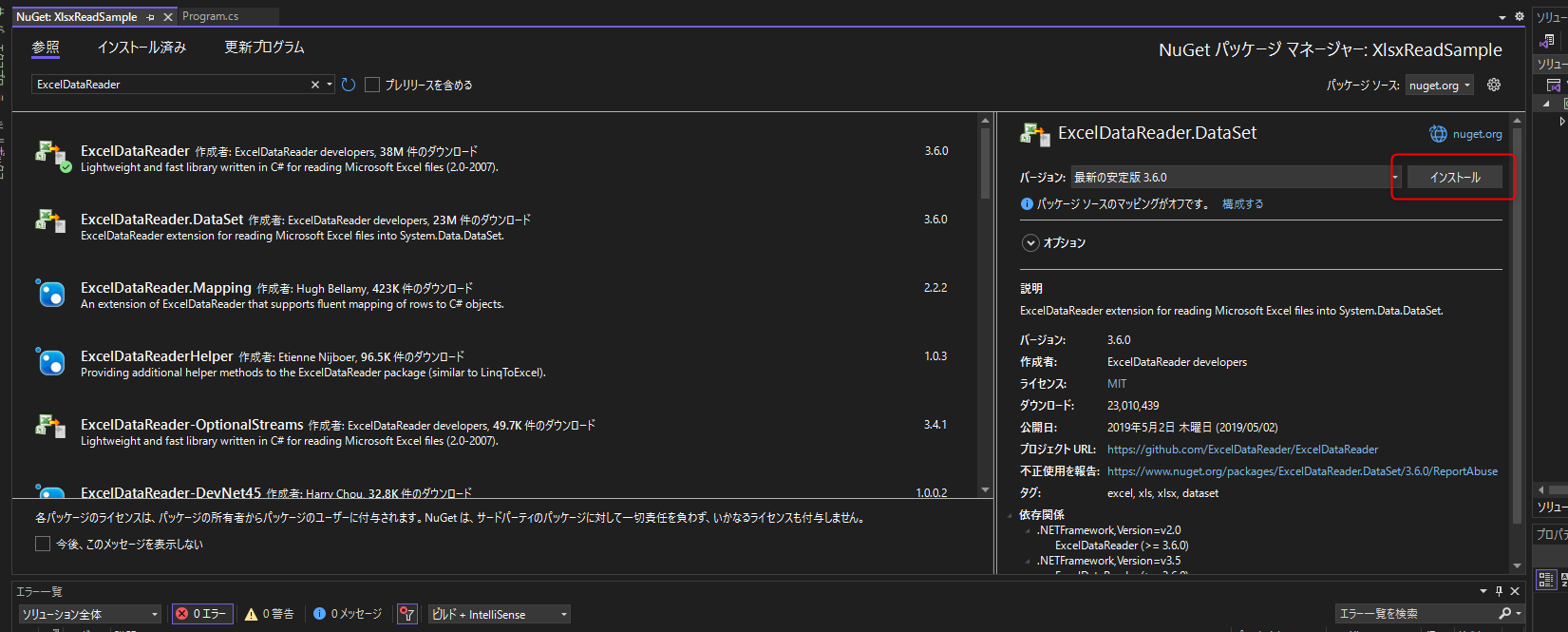
表示されたNuGetパッケージマネージャーウィンドウから「ExcelDataReader」、「ExcelDataReader.DataSet」をインストールします。
-
ExcelDataReader
-
ExcelDataReader.DataSet
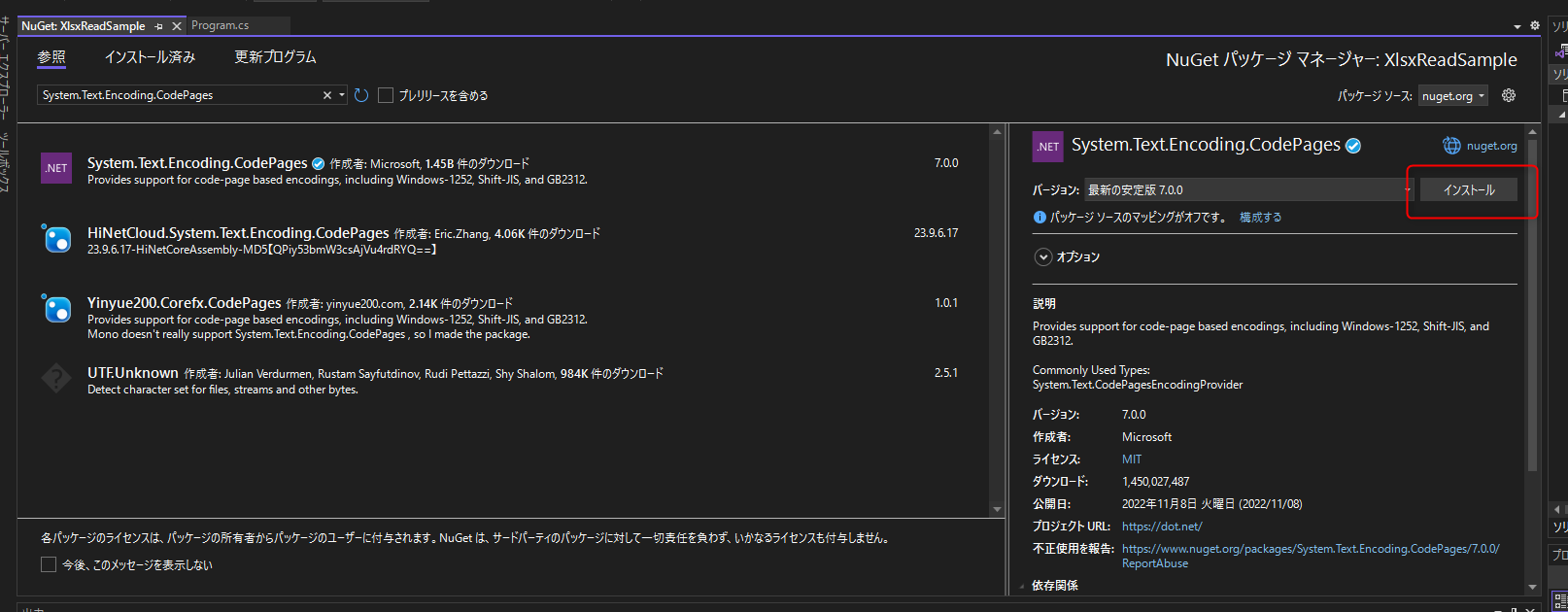
また、こちらに記載があるようにdotNetCoreおよびdotNet5以降の環境では、ExcelDataReaderを利用するためにエンコーディングのプロバイダーの登録処理が必要です。そのため、登録処理のためにパッケージ「System.Text.Encoding.CodePages」もインストールします。
プログラム作成
これで準備ができたので、プログラムを作成していきます。
以下がコードです。
using System.Data;
using System.Text;
using ExcelDataReader;
// dotNetCoreおよびdotNet5以降の場合は以下のコードでエンコーディングプロバイダーの登録が必要
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
var filePath = "読み取りたいxlsxファイルのパス";
// 読み取り専用でxlsxファイルを開く
using (var stream = File.Open(filePath, FileMode.Open, FileAccess.Read))
{
// xlsxファイルを読み取るためのリーダーオブジェクトを作成する
using (var reader = ExcelReaderFactory.CreateReader(stream))
{
// DataSet型でxlsxファイルの情報を取得
var result = reader.AsDataSet();
// 最初のDataTableを取り出し、行をコレクションで取得
var firstTable = result.Tables[0];
var rows = firstTable.AsEnumerable();
// [ページ名]、[ユーザーID]列を取得
// 最初の行を取り出し、セルの値で列を特定し、のちの処理で使うために記憶する
var firstRow = rows.First();
DataColumn? pageNameColumn = null;
DataColumn? userIdColumn = null;
foreach (DataColumn column in firstTable.Columns)
{
var cellValue = firstRow[column] as string;
if (cellValue == "ページ名")
{
pageNameColumn = column;
}
else if(cellValue == "ユーザーID")
{
userIdColumn = column;
}
}
// ページごとにユニークユーザーID一覧を集計するためのディクショナリ
var uniqueUserIdsPerPage = new Dictionary<string, HashSet<double?>>();
// 2行目から最後の行まで反復処理して、ページ名ごとにユニークユーザーIDの数を集計
foreach (DataRow row in rows.Skip(1))
{
var pageName = row[pageNameColumn] as string;
var userId = row[userIdColumn] as double?;
if (!uniqueUserIdsPerPage.ContainsKey(pageName))
{
// 該当のページに対応するユーザーIDが一件も追加されていない場合はユーザーIDリストを初期化
uniqueUserIdsPerPage.Add(pageName, new HashSet<double?>() { userId });
}
else
{
// 該当のページに対応するユーザーIDを追加
// HashSetへの追加なので重複追加はされない
uniqueUserIdsPerPage[pageName].Add(userId);
}
}
// ページごとのユニークユーザー数を出力
foreach (var (pageName, users) in uniqueUserIdsPerPage)
{
Console.WriteLine($"{pageName}:{users.Count}");
}
}
}
コードの説明をしていきます。
前章でも記載しましたが、dotNetCoreおよびdotNet5以降の環境でExcelDataReaderを利用するために初期化処理としてエンコーディングのプロバイダーの登録をします。以下がそのコードになります。
using System.Data;
using System.Text;
using ExcelDataReader;
// dotNetCoreおよびdotNet5以降の場合は以下のコードでエンコーディングプロバイダーの登録が必要
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
読み取り専用で読み取り対象のxlsxファイルを開き、ExcelDataReaderのExcelReaderFactoryクラスを使ってxlsxファイルを読み取るためのリーダーオブジェクトを作成します。
// 読み取り専用でxlsxファイルを開く
using (var stream = File.Open(filePath, FileMode.Open, FileAccess.Read))
{
// xlsxファイルを読み取るためのリーダーオブジェクトを作成する
using (var reader = ExcelReaderFactory.CreateReader(stream))
{
リーダーオブジェクト作成時のusingスコープの中で処理を続けていきます。
リーダーオブジェクトのAsDataSetメソッドでxlsxの情報をDataSet型として取得します。
DataSet型で情報を取得すると読み取り対象のxlsxファイル内のすべてのシートについて、シートごとに列*行の情報がDataTable型で表現されます。
// DataSet型でxlsxファイルの情報を取得
var result = reader.AsDataSet();
今回は読み取り対象のxlsxファイルの構造を知っている状態を前提としており、シートは一つしかないため、先頭のシート情報(DataTable)を取り出します。
やりたいことである「ページごとのユニークユーザー数を算出する」ためには、[ページ名]と[ユーザーID]列の情報(DataCoumn型で表現される)が必要になります。
そのため、先頭のシートから最初の行(列ヘッダ名を記載している行)のみを取り出して、[ページ名]と[ユーザーID]列の情報を特定し、後から利用するために記録しておきます。
// 最初のTableを取り出し、行をコレクションで取得
var firstTable = result.Tables[0];
var rows = firstTable.AsEnumerable();
// [ページ名]、[ユーザーID]列を取得
// 最初の行を取り出し、セルの値で列を特定し、のちの処理で使うために記憶する
var firstRow = rows.First();
DataColumn? pageNameColumn = null;
DataColumn? userIdColumn = null;
foreach (DataColumn column in firstTable.Columns)
{
var cellValue = firstRow[column] as string;
if (cellValue == "ページ名")
{
pageNameColumn = column;
}
else if(cellValue == "ユーザーID")
{
userIdColumn = column;
}
}
上記で処理した先頭行を除いた行について、上記コードで記録した[ページ名]と[ユーザーID]列の情報を利用してセル情報を取得し、ページ名ごとのユーザーIDの一覧をディクショナリに記録することで、最終的にページ名ごとのユニークなユーザー数(重複しないユーザーIDの数)を出力します。
// ページ(ページ名)ごとにユニークユーザーID一覧を集計するためのディクショナリ
var uniqueUserIdsPerPage = new Dictionary<string, HashSet<double?>>();
// 2行目から最後の行まで反復処理して、ページ名ごとにユニークユーザーIDの数を集計
foreach (DataRow row in rows.Skip(1))
{
var pageName = row[pageNameColumn] as string;
var userId = row[userIdColumn] as double?;
if (!uniqueUserIdsPerPage.ContainsKey(pageName))
{
// 該当のページに対応するユーザーIDが一件も追加されていない場合はユーザーIDリストを初期化
uniqueUserIdsPerPage.Add(pageName, new HashSet<double?>() { userId });
}
else
{
// 該当のページに対応するユーザーIDを追加
// HashSetへの追加なので重複追加はされない
uniqueUserIdsPerPage[pageName].Add(userId);
}
}
// ページごとのユニークユーザー数を出力
foreach (var (pageName, users) in uniqueUserIdsPerPage)
{
Console.WriteLine($"{pageName}:{users.Count}");
}
出力結果は以下のようになります。

DataSet型で値が取得できるため、集計などがしやすい形で情報を扱える点が良いと感じました。
DataSet型になれば、ExcelDataReader独自のメソッドなどを利用せずに情報を扱えるため、利用するハードルは低いように感じました。
まとめ
本記事ではC#用ライブラリの「ExcelDataReader」を使い方をサンプルを交えて述べました。
筆者が以前記事にしたCSVデータをプログラムで操作するときと大差ないプログラムで操作ができるため、ぜひ活用したいと思いました。(以前の記事はこちら。)