概要
今回は、中野区の賃貸物件の価格予測を行ってみました!利用したデータは、SUUMOのサイトです(他サイトと比較して物件の数が多かったので)。全体の流れは、スクレイピング->前処理->EDA->特徴量選択->モデル訓練というように進めていきました。
スクレイピング
まずは、SUUMOのサイトからスクレイピングをしました。サイトとディベロッパーツールを確認し、取得したい情報のDOM要素を確認します。そして、BeautifulSoupを利用して HTMLを解析し必要な情報のみを抽出します。また、連続的にサーバーにアクセスすることになるので、負荷を掛けないように1秒間隔を空けました。
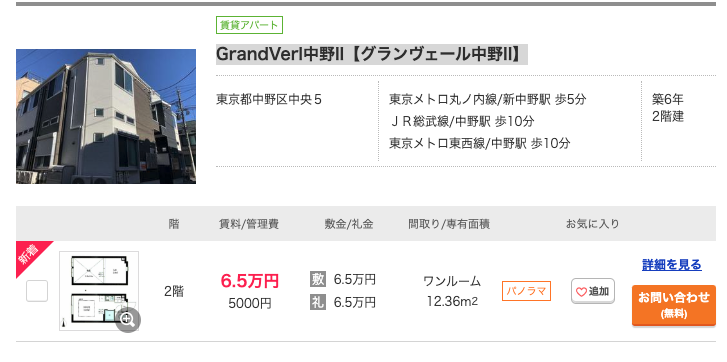
# 中野区賃貸スクレイピング
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# 中野区
base_url = "https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=13&sc=13114&sngz=&po1=25&pc=50&page={}"
def get_html(url):
r = requests.get(url)
time.sleep(1)
soup = BeautifulSoup(r.content, "html.parser")
return soup
all_data = []
max_page = {最大のページ数を入力}
for page in range(1, max_page+1):
#ページのURL取得
url = base_url.format(page)
# htmlを取得
soup = get_html(url)
#ページに表示される全ての物件を取得
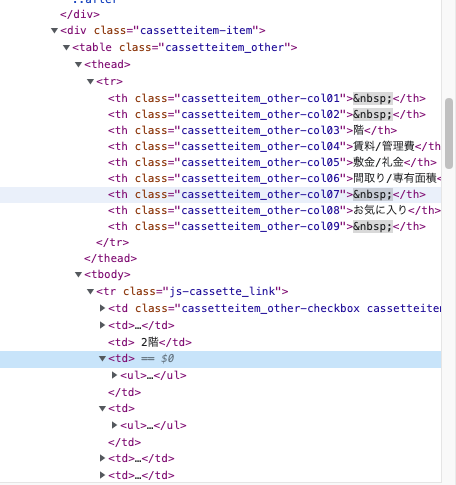
items = soup.find_all("div", {"class" : "cassetteitem"})
print("page", page, "items", len(items))
for item in items:
#最寄り駅から徒歩何分
stations = item.find_all("div", {"class" : "cassetteitem_detail-text"})
stations = [station.get_text() for station in stations]
base_data = {}
base_data["最寄り駅"] = stations[0]
base_data["名称"] = item.find("div", {"class" : "cassetteitem_content-title"}).get_text()
base_data["カテゴリー"] = item.find("div", {"class": "cassetteitem_content-label"}).get_text()
base_data["アドレス"] = item.find("li", {"class": "cassetteitem_detail-col1"}).get_text()
base_data["築年数"] = item.find("li", {"class": "cassetteitem_detail-col3"}).find_all("div")[0].get_text().strip()
base_data["構造"] = item.find("li", {"class": "cassetteitem_detail-col3"}).find_all("div")[1].get_text().strip()
tbodys = item.find("table", {"class" : "cassetteitem_other"}).find_all('tbody')
for tbody in tbodys:
data = base_data.copy()
data["階数"] = tbody.findAll("td")[2].get_text().strip()
data["家賃"] = tbody.findAll("td")[3].find_all("li")[0].get_text().strip()
data["管理費"] = tbody.findAll("td")[3].find_all("li")[1].get_text().strip()
data["敷金"] = tbody.findAll("td")[4].find_all("li")[0].get_text().strip()
data["礼金"] = tbody.findAll("td")[4].find_all("li")[1].get_text().strip()
data["間取り"] = tbody.findAll("td")[5].find_all("li")[0].get_text().strip()
data["専有面積"] = tbody.findAll("td")[5].find_all("li")[1].get_text().strip()
data["URL"] = "https://suumo.jp" + tbody.findAll("td")[8].find("a").get("href")
all_data.append(data)
df = pd.DataFrame(all_data)
df.to_csv('nakano_rent_house_'+ str(max_page)+'.csv', index=False)
実際のデータがこちらです。
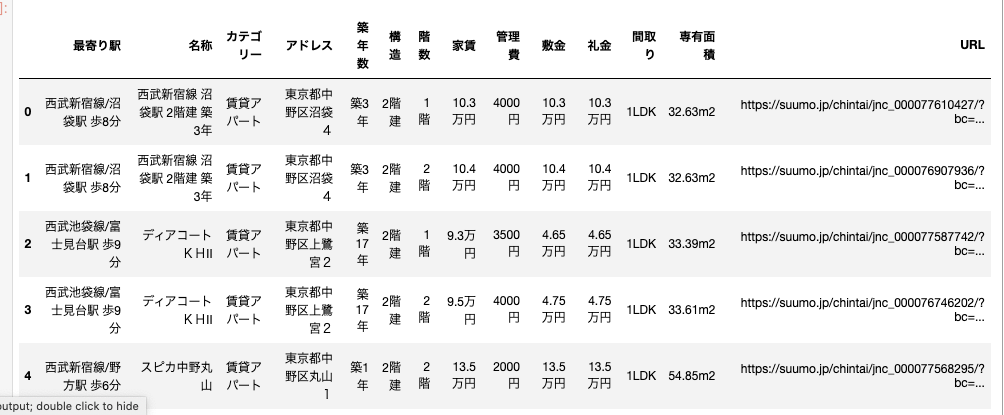
物件のデータは更新頻度が高いので、適度に収集し直してもいいかもしれないです。このようなDataFrameを作成した。そして、このデータをモデルで学習できるように前処理を行います。
データの前処理
ライブラリのインポート
# ライブラリのインポート&データ確認
%matplotlib inline
#データ解析用ライブラリ
import pandas as pd
import numpy as np
import japanize_matplotlib
import re
# データ可視化用ライブラリ
import matplotlib.pyplot as plt
from glob import glob
# Scikit-learn
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
from sklearn.model_selection import KFold, StratifiedKFold
from sklearn import linear_model
from sklearn.ensemble import RandomForestRegressor
# LightGBM
import lightgbm as lgb
データの確認・変換
まず、各データの型を確認します。
df.dtypes

全てobject型のデータになっています。なので、それぞれのデータを確認していきながら、適宜データの変換を実施していきたいと思います。
礼金
# 礼金
df["礼金"].value_counts()

敷金
# 敷金
df["敷金"].value_counts()

敷金・礼金に関してはない物件に関して、「-」が記載されているため、0で補完します。家賃も含め変換していこうと思います。
# 価格データの統一(家賃、敷金、礼金)
df["家賃"] = df["家賃"].apply(lambda x: re.sub("(万円)", '', x)).astype(float)
df["敷金"] = df["敷金"].apply(lambda x: re.sub("(万円)", '', x))
df["礼金"] = df["礼金"].apply(lambda x: re.sub("(万円)", '', x))
df["敷金"] = df["敷金"].apply(lambda x: 0 if x == '-' else float(x))
df["礼金"] = df["礼金"].apply(lambda x: 0 if x == '-' else float(x))
df[["敷金", "礼金", "家賃"]] = df[["敷金", "礼金", "家賃"]].apply(lambda x : x*10000)
df.dtypes

このように、float型に変換できました。この調子で他のデータも変換を実施していきます!
管理費
管理費は以下のようになっていました。

単位を消して、「-」に関しては0で補完します。
# 管理費の変換
df["管理費"] = df["管理費"].apply(lambda x: re.search('\d*', x).group())
df["管理費"] = df["管理費"].apply(lambda x: x if x != '' else 0)
df["管理費"] = df["管理費"].astype(float)
df.dtypes

このように変換することができました。
月額賃料
一般的に賃貸を借りた場合、毎月家賃だけでなく管理費も払う必要があるので、今回は目的変数を家賃と管理費を合計した値に設定しました。
# 月額賃料
df["月額賃料"] = df["家賃"] + df["管理費"]
また、名称と月額賃料が同じデータに関しては重複データであるため、あらかじめ削除削除しておきます。
# 重複データの削除(名称と月額賃料)
df = df.drop_duplicates(subset=['名称', '月額賃料'])
階数
# 階数
df["階数"].value_counts()

結果を見ると、少し処理が難しそうです。まずは、「階」を削除し、B1を含む値を0としました。また、階を「-」で複数表現されているものは、最高階だけを抽出できるようにしました。最後に、「-」に関しては1で補完しました。
df["階数(変換)"] = df["階数"]
df["階数(変換)"] = df["階数(変換)"].apply(lambda x: re.sub('階', "", x))
df["階数(変換)"] = df["階数(変換)"].apply(lambda x: '0' if 'B1' in x else x)
df["階数(変換)"] = df["階数(変換)"].apply(lambda x: x[-1] if re.match('(.-.)', x) else x)
df["階数(変換)"] = df["階数(変換)"].apply(lambda x: '1' if x == '-' else x)
df["階数(変換)"] = df["階数(変換)"].astype(int)
df["階数(変換)"].value_counts()

築年数
築年数を確認していきます。

データを見る限り、「築,年」を消す必要がありそうです。また、新築に関しては、0で補完していきます。
#築年数の変換
df["築年数"] = df["築年数"].apply(lambda x: re.sub('[(築)(年)]', '', x))
df["築年数"] = df["築年数"].apply(lambda x: 0 if x == '新' else int(x) )
df.dtypes

int型に変換することができました。
専有面積
続いて、専有面積を確認していこうと思います。

専有面積も単位を削除する必要がありそうなので、削除していきます。
# 専有面積
df["専有面積"] = df["専有面積"].apply(lambda x: re.search('\d*', x).group()).astype(float)
構造
構造を確認していきます。

このデータも複雑ですが、平屋を1階建として数字に変換しつつ、地下を含む物件は地下分を加算できるようにします。
# 構造
df["構造(変換)"] = df["構造"]
df["構造(変換)"] = df["構造(変換)"].apply(lambda x: re.sub("[(階建),(地下)]", "", x))
df["構造(変換)"] = df["構造(変換)"].apply(lambda x: re.sub("平屋", "1", x))
df["構造(変換)"] = df["構造(変換)"].apply(lambda x: int(x[:1])+ int(x[2:]) if '上' in x else int(x))
df["構造(変換)"].value_counts()

最寄駅
最寄駅をみていきましょう。あらかじめ、最も近いデータ以外は取り除いてあります。

データを確認すると、最寄駅と最寄り駅からかかる時間が記載してあるので、それぞれ分けてデータを作成することにしました。
# 最寄駅変換
df["最寄駅 距離(分)"] = df["最寄り駅"].apply(lambda x: re.search('\d+', x).group()).astype(int)
df["最寄駅"] = df["最寄り駅"].apply(lambda x: re.search('/.*駅', x).group())
df["最寄駅"] = df["最寄駅"].apply(lambda x: re.sub('/', '', x))
ここで、データの一部を再度確認してみます。
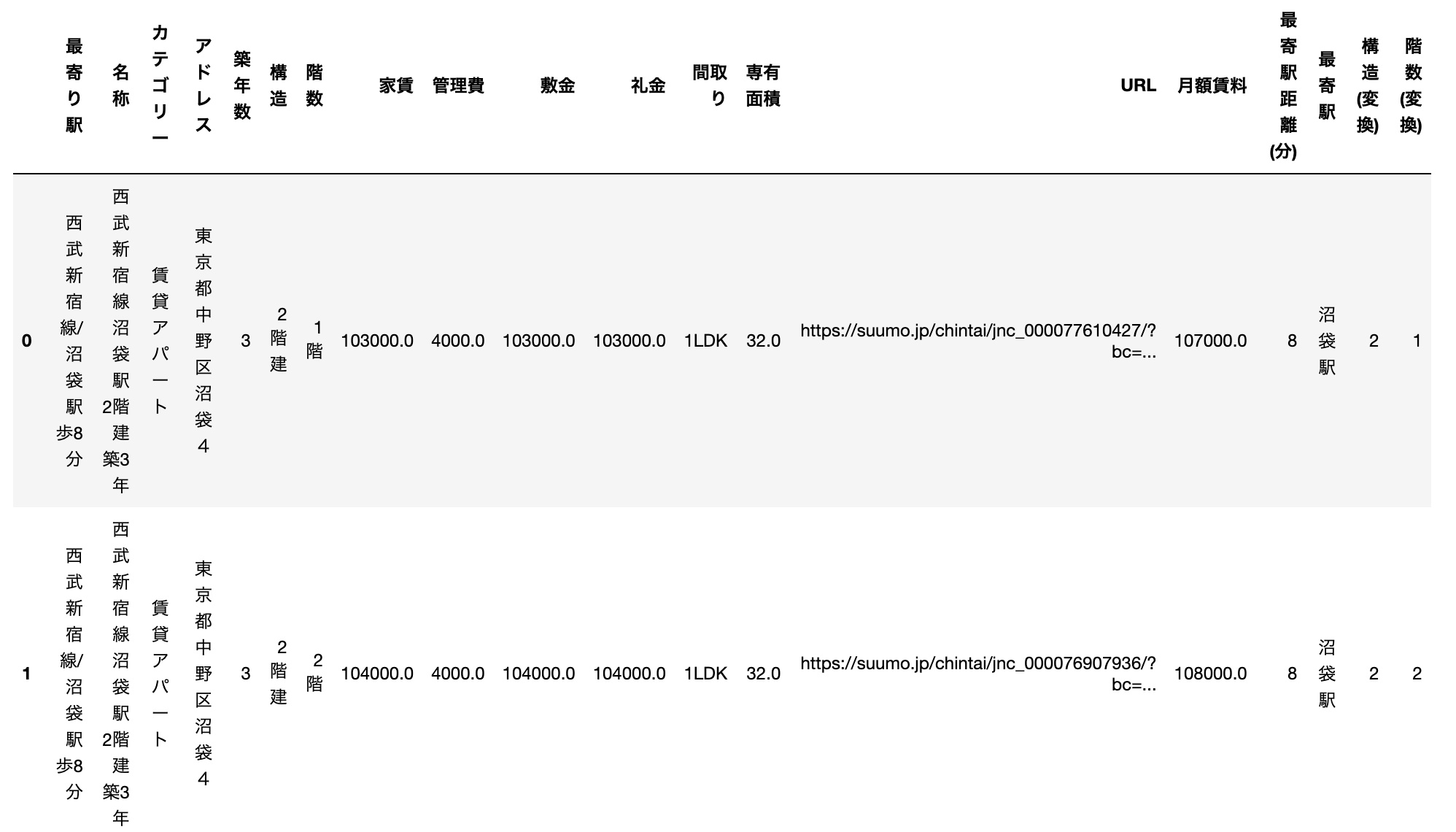
だいたい、細かいデータ変換は一通りできた感じなので、特徴量分析に入っていきます。
EDA
基本統計量
変換後の基本統計量をみていきます。
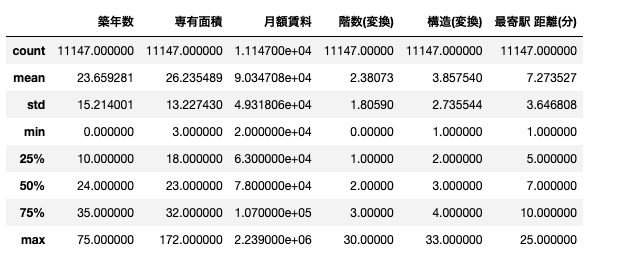
見ていくと、月額賃料の最大値がとてつもない値だったのですが、調べてみると誤植で一桁多く書かれているようでした(同じ物件の他の部屋の価格が22万円だったため)。したがって、値を一桁もとに戻しておきました。その他、中野区の物件はそこまで高層階の建物が多いわけでもなく、駅から10分以内の物件が多いことも分かりました。
目的変数のヒストグラム
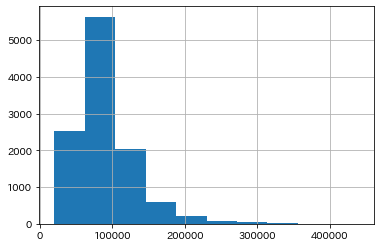
ポアソン分布のように右裾が長い分布になっています。なので、これを対数変換して正規分布に近似するデータに変換しておきます。
# 目的変数の対数変換
df["月額賃料log"] = df["月額賃料"].apply(lambda x: np.log(x))
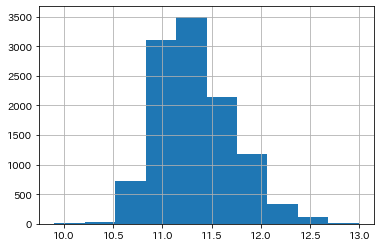
いい感じに変換できたのではないでしょうか?笑
相関係数
続いて相関係数を見ていきたいと思います。seabornのヒートマップを利用して可視化してみました。
import seaborn as sns
plt.figure(figsize=(20, 20))
sns.heatmap(df.corr(), square=True, annot=True)
plt.show()
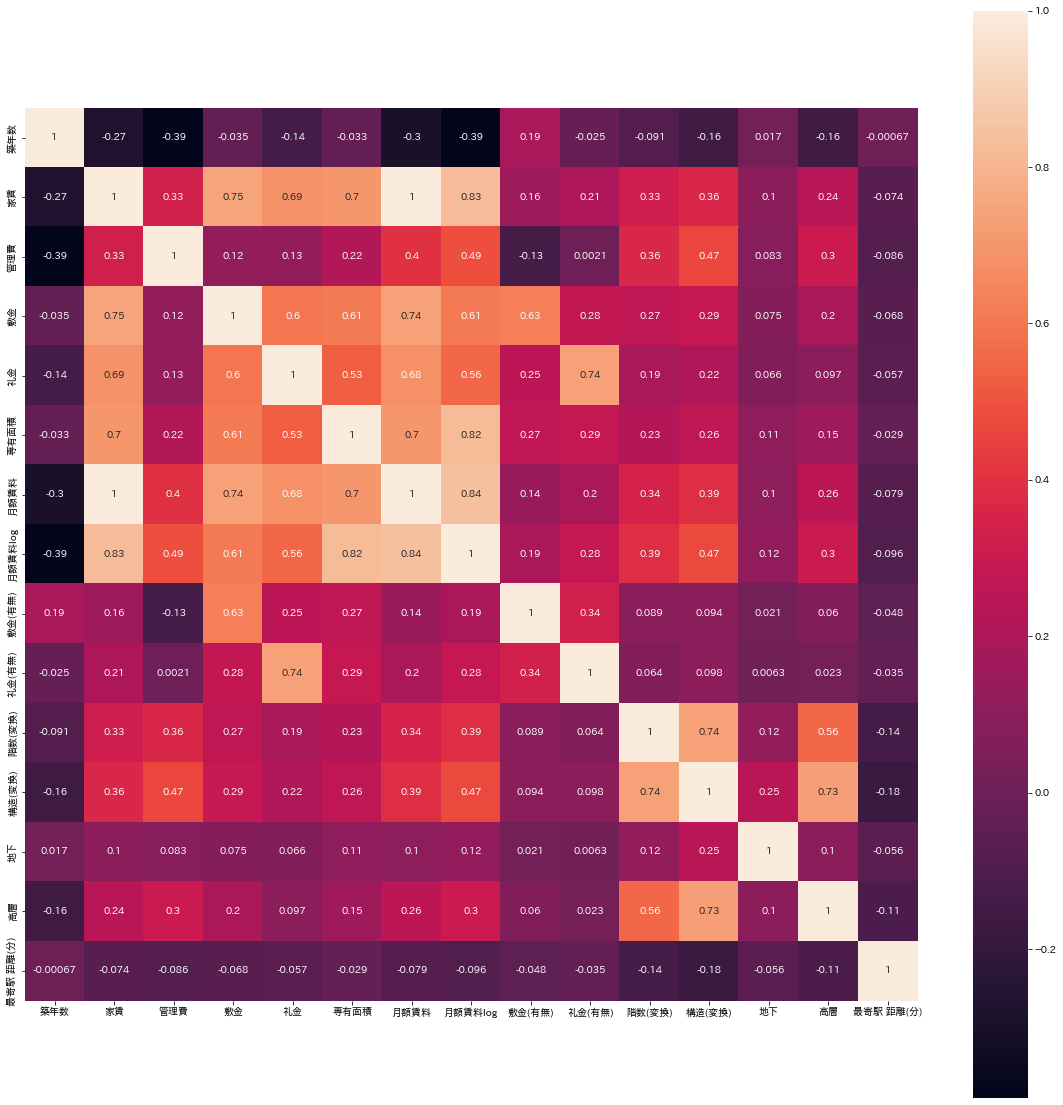
小さくて見にくいのですが、専有面積と月額賃料の相関がかなり強いことが分かりました。 散布図も出しておきます。
plt.scatter(df["専有面積"], df["月額賃料log"])
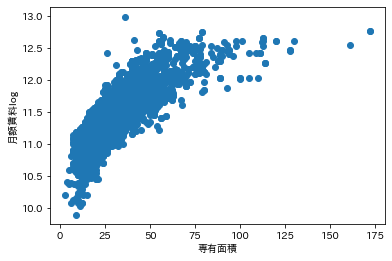
散布図を確認してもかなり正の相関が強いことが分かります。
それでは、実際にモデル訓練を行っていきたいと思います。
モデル訓練
モデル訓練を実施していきますが、今回はlightGBMモデルを利用していきます。lightGBMは精度・計算速度・使いやすさともに優れているモデルであるため採用しました。
説明変数と目的変数
features = ['カテゴリー', '築年数', '構造(変換)', '階数(変換)', '間取り', '専有面積','最寄駅 距離(分)', '最寄駅']
X = df[features]
y = df["月額賃料log"]
今回は、名称やアドレスやURL、最寄り駅,敷金、礼金は今回の推定には利用せず、それ以外のデータを利用し、家賃+管理費を対数化した「月額賃料log」を目的変数として予測していこうと思います。
カテゴリデータの変換
続いて、まだ前処理が完了していないデータの処理を行なっていきます。数値データは一通り変換しているので、カテゴリデータの変換を実施していきます。今回はlightGBMモデルという決定木をベースにしたモデルを利用するため、各数値の大きさがモデルに影響されないためLabelEncodingを適用します。
from sklearn.preprocessing import LabelEncoder
categories = X.columns[X.dtypes == "object"]
for category in categories:
le = LabelEncoder()
X[category] = le.fit_transform(X[category])
X[category] = X[category].astype("category")
X.dtypes
これで、データの前処理は完了しました!!実際にモデルで学習していきます。
データの分割
まずは、利用するデータを学習用とテスト用に分割していきます。また、k-分割交差検証を実施するためfold数を5に設定しておきます。
from sklearn.model_selection import train_test_split, KFold
folds = 5
kf = KFold(n_splits=folds)
train_X, X_test, train_Y, y_test = train_test_split(X, y, test_size=0.2, random_state=100)
パラメータ調整
最終的な学習を実施する前にoptunaでパラメータ調整していきます。optunaは最適化と計算コストのバランスがよく、広範囲でパラメータを探索できます。
# optunaによるパラメータ調整
import optuna
def objective(trial):
params = {
"objective": "regression",
"random_seed": 1234,
"learning_rate": 0.05,
"n_estimators": 1000,
"num_leaves": trial.suggest_int("num_leaves", 4, 64),
"max_bin": trial.suggest_int("max_bin", 50, 200),
"bagging_fraction": trial.suggest_uniform("bagging_fraction", 0.4, 0.9),
"bagging_freq": trial.suggest_int("bagging_freq", 1, 10),
"feature_fraction": trial.suggest_uniform("feature_fraction", 0.4, 0.9),
"min_data_in_leaf": trial.suggest_int("min_data_in_leaf", 2, 16),
"min_sum_hessian_in_leaf": trial.suggest_int("min_sum_hessian_in_leaf", 1, 10)
}
scores = []
for train_index, val_index in kf.split(train_X):
X_train = train_X.iloc[train_index]
X_valid = train_X.iloc[val_index]
y_train = train_Y.iloc[train_index]
y_valid = train_Y.iloc[val_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train)
model_lgb = lgb.train(params, lgb_train,
valid_sets=lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval=10)
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
score = np.sqrt(mean_squared_error(y_valid, y_pred))
scores.append(score)
scores = np.mean(scores)
return scores
study = optuna.create_study(sampler=optuna.samplers.RandomSampler(seed=0))
study.optimize(objective, n_trials=50)
study.best_params
今回は、earlyStoppingを20回に設定しましたが、コンペとかで精度をあげることを第一の目標にしつつデータが多い場合は、earlystoppingを増やしてもいいかもしれません(力業ですけど、、、)。
最適パラメータでモデル訓練
optunaで得た最適パラメータでモデル訓練を実施していきます。最適なパラメータはstudy.best_paramsに格納してあります。
lgbm_params = {
"objective": "regression",
"random_seed": 1234,
"learning_rate": 0.05,
"n_estimators": 1000,
"num_leaves": study.best_params["num_leaves"],
"max_bin": study.best_params["max_bin"] ,
"bagging_fraction": study.best_params["bagging_fraction"] ,
"bagging_freq": study.best_params["bagging_freq"] ,
"feature_fraction": study.best_params["feature_fraction"] ,
"min_data_in_leaf": study.best_params["min_data_in_leaf"] ,
"min_sum_hessian_in_leaf": study.best_params["min_sum_hessian_in_leaf"]
}
models = []
rmses = []
oof = np.zeros(len(train_X))
for train_index, val_index in kf.split(train_X):
X_train = train_X.iloc[train_index]
X_valid = train_X.iloc[val_index]
y_train = train_Y.iloc[train_index]
y_valid = train_Y.iloc[val_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=True)
model_lgb = lgb.train(lgbm_params, lgb_train,
valid_sets=lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval=10)
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
tmp_rmse = np.sqrt(mean_squared_error(y_valid, y_pred))
print(tmp_rmse)
models.append(model_lgb)
rmses.append(tmp_rmse)
oof[val_index] = y_pred
モデル評価
実際の賃料と予測値の比較
それでは、学習後のテストデータの予測値と実際の賃料を比較していきます。
y_pred = model_lgb.predict(X_test)
actual_pred_df_test = pd.DataFrame({"actual": np.exp(y_test), "pred": np.exp(y_pred)})
actual_pred_df_test["差額"] = actual_pred_df_test["pred"] - actual_pred_df_test["actual"]
actual_pred_df_test.sort_values('差額')
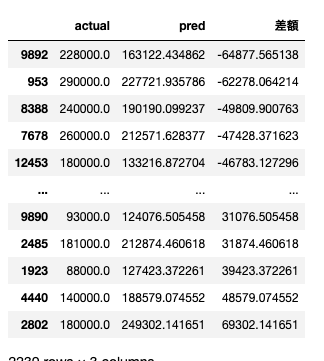
実際の賃料と予測値のズレは最大で7万円弱でした。もう少し詳しく見ていこうと思います。
テストデータの決定係数とRMSE
まずは、決定係数とRMSEを見ていこうと思います。決定係数は説明変数が目的変数をどれくらい説明しているかを表す指標です。RMSEは二乗平均平方根誤差を表していています。平均の価格誤差の範囲がどのくらいかをより視覚的にわかりやすくするために対数から真数に戻してます。
R2 = r2_score(actual_pred_df_test['actual'], actual_pred_df_test['pred'])
RMSE = np.sqrt(mean_squared_error(actual_pred_df_test['actual'], actual_pred_df_test['pred']))
R2, RMSE
===出力結果===
(0.9624915381069755, 7615.596157832987)
決定係数は0.96, RMSEは7615とかなりいい感じになりました。(パラメータ調整や前処理実施前は決定係数0.89, RMSE10000を超えてました.....)
予測値と実際の賃料を散布図にプロットしていきます。
z = sns.jointplot(x=actual_pred_df_test["actual"], y=actual_pred_df_test["pred"], color="b", kind='reg')
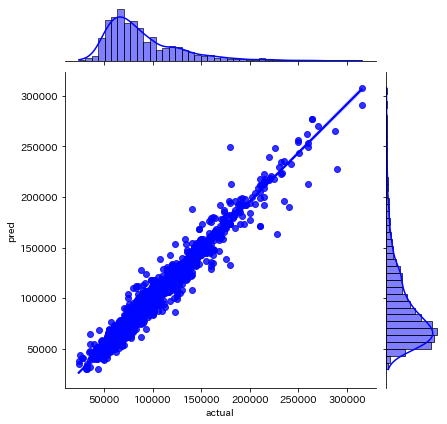
全体で見ると予測値とのズレが少なくなっているように感じました。
それでは、誤差が大きい物件に関して詳しく見ていこうと思います。
予測値と実際の賃料の差が多い物件について
actual_pred_df_test.sort_values('差額')
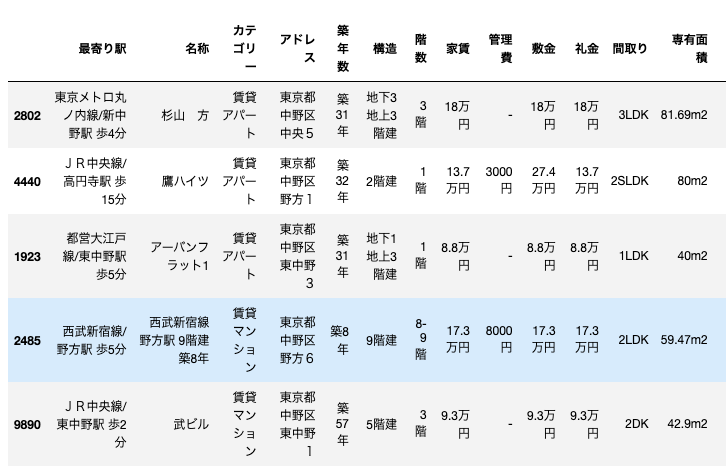
実際の賃料よりも高く予測した物件と低く予測した物件ベスト5のインデックスをリストにしておきます。
top_list = [9892, 953, 8388, 7678, 12453]
bottom_list = [2802, 4440, 1923, 2485, 9890]
元のデータを読み込んでどのような物件か見ていきます。
origin_df = pd.read_csv('nakano_rent_house_159.csv')
Topリストの表示
それでは、実際の値よりやすく予測した物件(過小評価してしまった物件)を見ていきます。
a_df = origin_df.iloc[top_list, :]
a_df
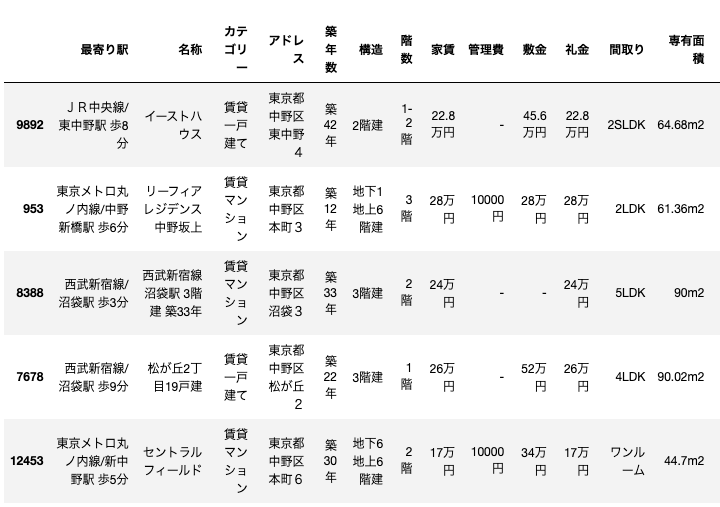
見ていくと、一戸建てや地下があるマンション、さらに5LDKの物件など直感的に考えると高くなりそうな物件が多い印象を受けました。それでは、いくつかどのような物件なのかを見ていきます。
リーフィアレジデンス中野坂上(予測:22.7万円, 実際:29万円)
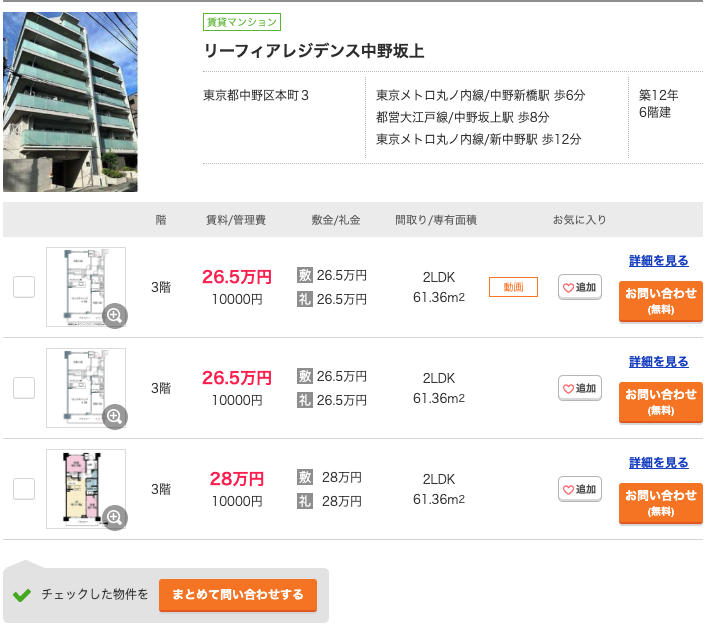
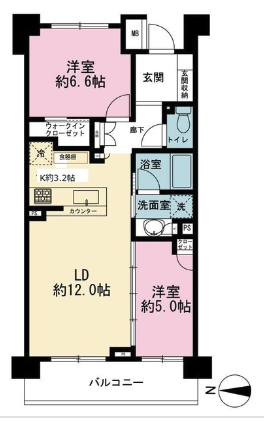





一見した感じだと月額賃料29万円と言われても納得するような物件なので、モデルの予測がなぜ安くなってしまったのか気になるところです。そこで、SHAPという手法を利用してモデルがどの特徴量の影響を受けているのかを見ていきましょう。
# SHAP
import shap
# X_test = X_test.reset_index(drop=True)
exp = shap.TreeExplainer(model_lgb)
sv_test = exp.shap_values(X_test)
shap.decision_plot(exp.expected_value, sv_test[2192], X_test.iloc[2192])
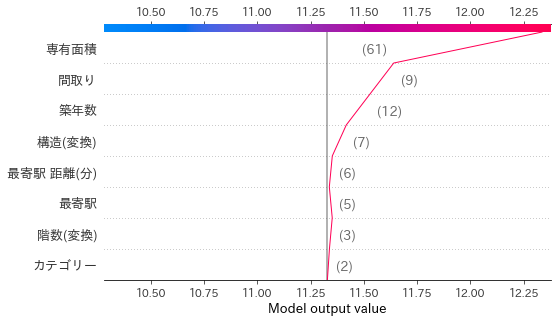
かなり、専有面積や間取りがプラスの方向に影響を与えているようですが、これでも足りないみたいです。画像では、システムキッチンや洗面化粧台、ウォークインクローゼットなどの特徴も見られるので、今回利用した特徴量だけでは限界があるのかもしれないですね....
セントラルフィールド(予測:13.3万円, 実際:18万円)
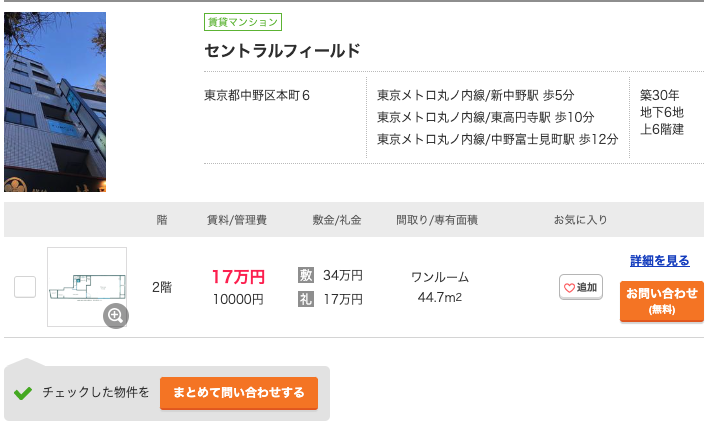


写真を見ると、部屋は広そうですが...という感じですね笑。キッチンもなさそうなのでどうやって住むのだろうって思います。でも、広さと東京都内駅近ってことを考えると18万も妥当なのかもしれません。。。
shap.decision_plot(exp.expected_value, sv_test[672], X_test.iloc[672])
こちらは、明らかにプラスに専有面積が効いていてそれ以外はそこまで効いていなそうですね。二つの例を見ただけでも専有面積が結果を左右しているのが伺えます。
bottomリスト表示
今度は、実際の値より高く予測した物件を見ていきます。
b_df = origin_df.iloc[bottom_list, :]
b_df
こちらは築年数30年以上の物件が4件と古めの物件が多い印象です。ただ、専有面積が広い物件が多いので、この辺モデル予測に影響したのかなあという印象です。では、実際の物件を見ていきましょう!
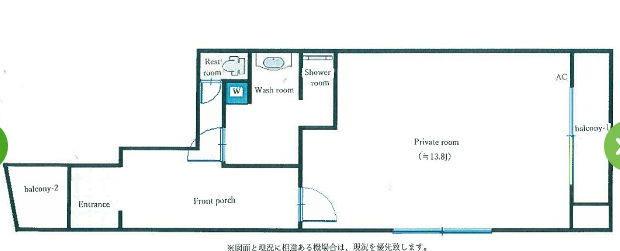
アーバンフラット1(予測:12.7万円, 実際:8.8万円)
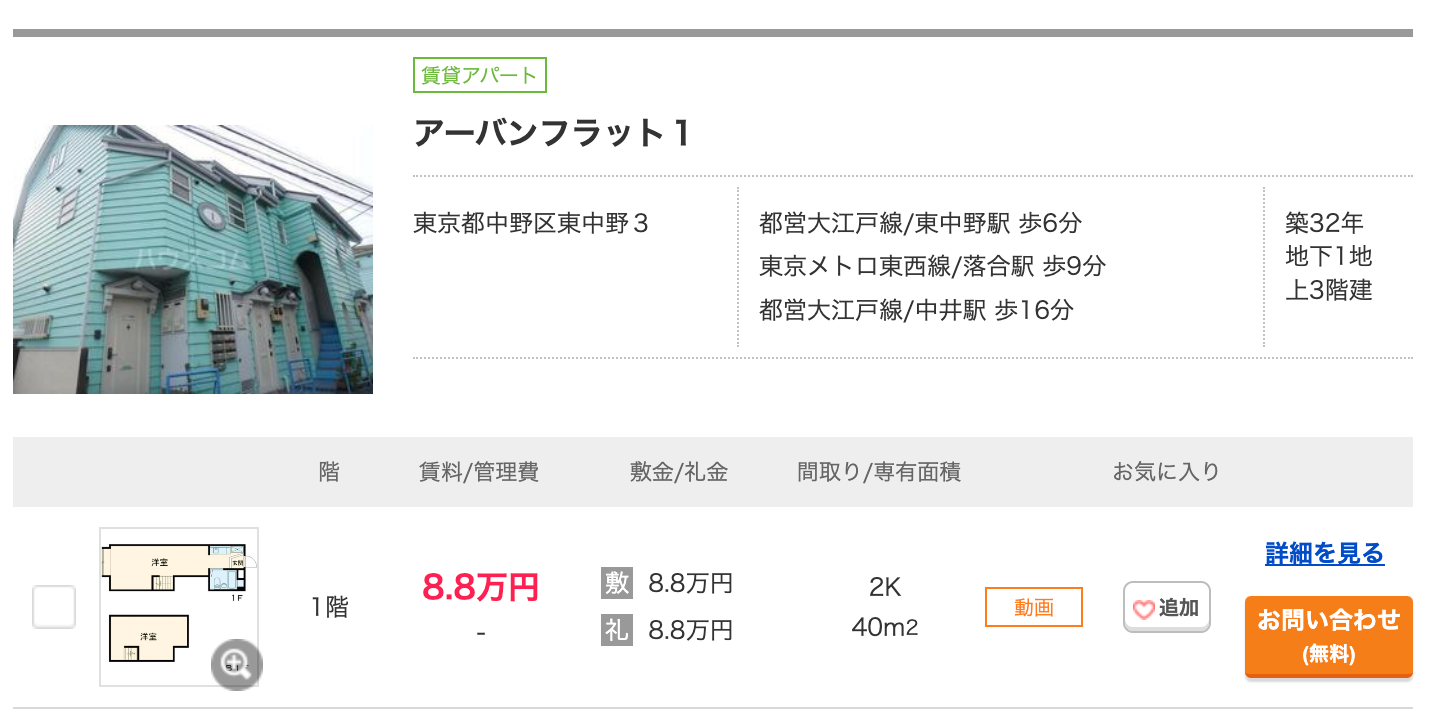
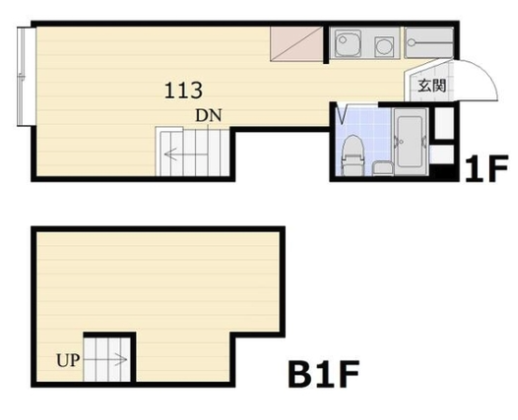

間取りを見ると、ユニットバスになっているみたいです。一般的にユニットバスの物件は安くなりやすいと言われているので、この辺りが予測値と実際の賃料の差の原因になっているかもしれません。また、地下にもフロアがあり専有面積が多くなっている点も影響しているかもしれません。個人的には、2部屋あるよりバス・トイレ別の方が嬉しいので惜しいなと思ってしまいます(何様)。
こちらもSHAPでモデルの予測に対する特徴量の影響を見ていきましょう!
shap.decision_plot(exp.expected_value, sv_test[1551], X_test.iloc[1551])
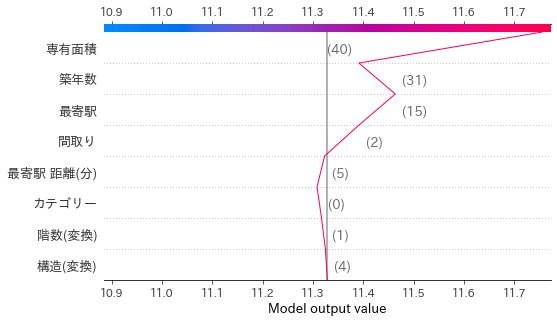
やはりというべきか、面積がかなりプラス側に効いていますね。モデルにとってはもう少し特徴量が必要なのかもしれません。最後にデータ全体に対する特徴量の影響を見ていきましょう。
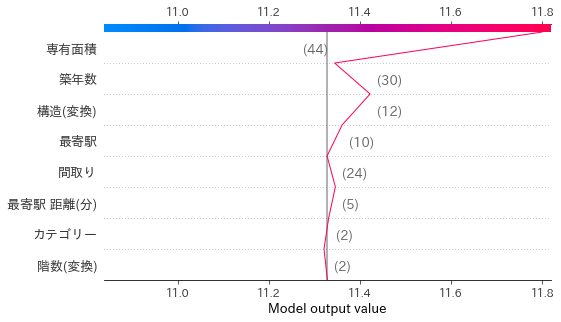
shap.summary_plot(sv_test, X_test)
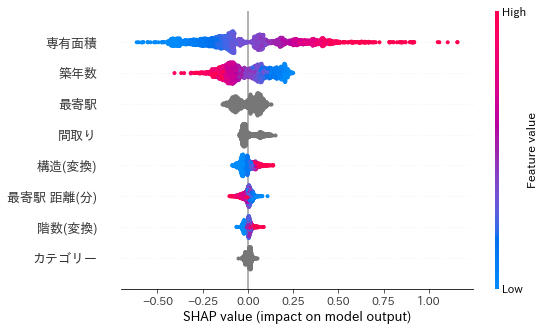
この図は各予測に対する影響の絶対値の平均値の順に特徴量を並んでいて、それぞれの特徴量についてSHAP値の散布図になっています。線の太さでデータの件数がわかる。
専有面積は面積が広いとプラス方向に効き、狭いとマイナス方向に効くことやプラス方向への効き方の方が大きいことがわかる。
築年数などは多いほどマイナスの方向に効いていますが、多くのデータで効き方の絶対値が小さく、一部のデータに対して大きく効いていることがわかります。
考察・まとめ
- 専有面積について
専有面積についてはかなり大きな影響が出ているようですが、データの分布を確認してみます。
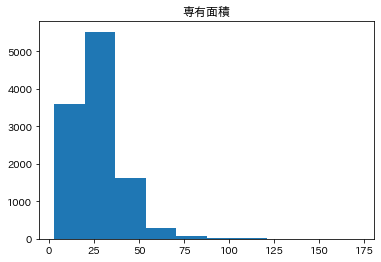
このようにポアソン分布のようになっていたので、あらかじめ対数変換等を行っておいた方がよかったかもしれないなと思いました。また、今回はそこまで関係ありませんが、専有面積には部屋の面積しか含まれていない可能性が高く (引用:専有面積とは)、バルコニーや庭があるなどについても考慮する必要があるかもしれません。 - その他特徴量について
構造などは高層階であるほど予測に影響が効いていましたが、中野区のみの物件ということもあり、そこまでデータ数が多くなかったので他の区の物件情報もあるとなお良いと思いました。また、他の区の物件情報を集めれば区ごとの違いも出てくるので予測に影響が出てきそうですね(良いか悪いかは分かりませんが...)。
また、ユニットバスありなしやオートロックなどの詳細情報もあると面白いなと思いました(スクレイピングがきついですが)。
まとめると、今回の価格予測では推定精度に関してはかなり良かったのですが、特徴量作成をはじめ、改善点も見つかったので今後に生かしていけたらなあと思います。