あらためて読み返すと、中身が無い上に長すぎたので、ぼちぼち別記事に分けていくことにします。
・自前テンプレートの件
5行で書ける、JSONを表示するjQueryテンプレートプラグイン
その辺のマンガが好きなら、この辺のマンガも好きなんじゃない?
という、よくあるやり取りをサービス化してみた。
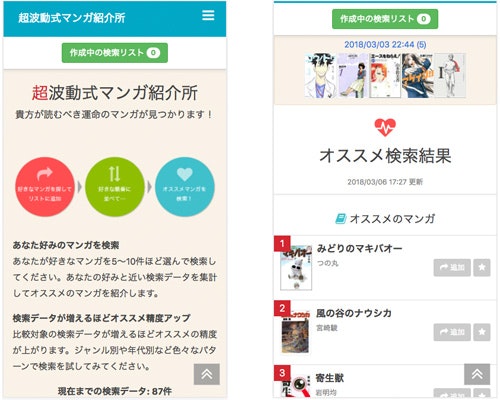
レコメンドの流れ
- 好きなマンガを好きな順に並べて検索
- 過去の検索データの中から、好みが似ている人の検索リストを集計
- 類似度が高い検索データから、オススメのマンガを紹介
最初は「最新のWebトレンドを押さえて、意識高いQiita書くぞー!」なんて意気込んでいたのだが、実際やってみると時間と性格の都合で、意識低い感じに仕上がった。
意識低いところ
nginx + php-fpm + MySQL
「やっぱ、node.js + redis でしょ!」 と意気込んでいたものの、ちゃちゃっと PHP, MySQL で仕様を捏ねながらプロトタイプを作ってるうちに、面倒くさくなって、もうコレでいいや、ってなった。
IDCFの500円クラウド
「当然、AWS に Docker でしょ!」 と手を付けたものの、AWSをガチャガチャと構成してるうちに面倒くさくなって、気がついたらIDCFの500円クラウドをポチっていた。
見積りが甘い
仕事のスキマ時間を使って**「1週間ぐらいでできるっしょ!」**と思って作り始めたが、終わってみたら4週間ぐらいかかった。
想定以上に手間がかかった上に、だんだん忙しくなってきてスキマ時間が無くなり、どんどん遅れた。
レコメンド性能がポンコツ (今のところ)
過去の検索データと比較してオススメマンガを探す、という仕組みなので、比較対象となる検索データが少ないうちは、オススメ性能がまったくアテにならない。
今のところ、「四月は君の嘘」と「恋は雨上がりのように」が好きな人に「エアマスター」をオススメするレベル。
jQuery
**「さて、Reactか、Vueか」**と迷っているうちに、プロトタイプ作ってた jQuery で充分な気がしてきて、そのまま仕上げた。
まあ、JSON受け取って表示するだけなので。
Bootstrap3
4ではなく3。
4で作るつもりで、8割方まで4で作ってみたものの、どうしても「ないわーコレ」と思ったので、まるっとBootstrap3で書き直した。
知人がいま Bootstrap4 の本を書いているらしいのでディスるのは止めとく。
FontAwesome4
ちょうど、作ってる最中に FontAwesome がバージョンアップしたけど、作り変えるのも面倒なのでそのまま。
アクセシビリティ系の属性 (WAI-ARIA)
roleとかaria-***とか、全部取っ払った。スッキリ。
これが無くて困ってる事例を見たことも聞いたことも無ければ、あって助かったという話も聞いたことがない。
FontAwesomeも新しくなってから付けるの止めたっぽいね。
レコメン度の計算式を丸パクりで理解できていない
https://qiita.com/hik0107/items/96c483afd6fb2f077985
こちらの式をそのまま使わせていただきました。
ユークリッド距離というのかな? けど、まったく原理を理解できていない。
サービスの仕様的にこの式だけでは難しかったので、予備的に使用している。
自前サジェスト
マンガタイトルを検索する際のサジェスト機能は、jQuery UI の Autocomplete を使うつもりだったんだけど、どうも使い方が分からない。
例えば、「進撃の巨人」を検索する時は、入力が「進」でも「しん」でもサジェスト候補が出て欲しいんだけど、複数パターンの入力候補から1つのデータを拾う方法が分からなくて、コードを読むのも面倒なので、ちゃちゃっと自前で作った。
突貫で作ったので、現状では 十字キー + Enter選択 という一般的なサジェスト操作が効かないなどの弱点が。
次に時間ができたらちゃんとしよう。
前方一致しばり
MySQLのインデックス効かないのがイヤなので、サジェスト機能は前方一致しばり。
すると「みどりのマキバオー」を「マキバオー」で検索してもサジェストが出てこない。
そこでテーブルに予備の検索候補を持たせるという超原始的な対策をしている。
Elasticsearch とか使えばいいのかな? 今のところ考えてないけど。
自前HTMLビルドツール
プロトタイプを作ってテストするたびに変更が入るので、HTMLはヘッダ、フッタ等の共通部品をモジュール化したいし、多少の変数や分岐も使いたい。
手元の環境にはGulpがあるけど、今一番流行してるツールはどれなんだろう?とか調べてるとよく分からないし、PHPのAPI側と設定も共有するには?とか諸々調べるのが面倒くさくなったので簡単なビルドツールを3分で作ったら、これで充分だった。
テンプレートつなぎ合わせて、変数展開するだけだし。
ob_start();
include('template/header.html');
include('template/ranking.html');
include('template/footer.html');
$dump = ob_get_clean();
file_put_contents($output, $dump);
自前HTMLテンプレート
※ 別記事にしました。
5行で書ける、JSONを表示するjQueryテンプレートプラグイン
ぜんぶ cookie に保存
気軽に使ってもらうためには、ユーザー登録やログインをさせたくなかった。
当初の予定ではゴテゴテと機能が多かったので、昔ながらの削除キーとか機能を用意していたけど、結局ぜんぶCookieに覚えさせておくことにした。
最終的には機能もダイエットされたので、特に問題なさそう。
手間をかけたところ
スコア評価ではなく、並び替え
仕組み上、レコメン精度を上げるためには、なるべく多くの検索データが必要になる。なので、とにかく気軽にたくさん検索してもらいたい。
そして、レコメン度を計算するためには、ユーザーには作品ごとにスコアを付けてもらう必要があるんだけど、「好きな作品それぞれのスコアを考える」という作業を課すのはちょっと負荷が高い。
この負荷を避けて、より気軽に使ってもらえる方法を考えた結果、スコアを付ける作業を「好きな順に並べる」という作業に変えた。ランキングの順位を内部的にスコア変換すれば、ユーザーは作品ごとにスコアを考えるという負荷を意識せずに済む。
レコメン度の計算
前述のレコメン度計算式を使うつもりだったんだけど、「ランキングを内部的にスコア化する」という仕様上、そのままでは上手く使えなかった。
たとえば、以下のような検索データがあった場合、
1. SLAM DUNK
2. よつばと!
3. キングダム
4. 波よ聞いてくれ
5. GIANT KILLING
1. アオアシ
2. ワンピース
3. SLAM DUNK <-- ユーザーの1位
4. HUNTERxHUNTER
5. よつばと! <-- ユーザーの2位
1. 鋼の錬金術師
2. 寄生獣
3. ダンジョン飯
4. 波よ聞いてくれ <-- ユーザーの4位
5. GIANT KILLING <-- ユーザーの5位
色々とテストしている過程で、ユーザーがランキングを決める時は、上位のタイトルほど悩んで順位を付けるが、下位になるほど順位付けが適当になるらしいと分かった。
なので、ユーザーが上位に選んだマンガを含んでいる比較データ1の方を類似度高と判定してほしいところだが、元の式の通りだとデータ2の方を類似度高と判定する。
レコメン度の計算時には、順位データを主として判定し、類似度の式は補足的に使うようにした。
内部スコア
先に書いた通り、ユーザーが好きなマンガに順位を付けるとき、上位ほど悩み、下位ほど適当になるっぽい。
すると、ランキングをスコア化する際に、1位と2位の差と、9位と10位の差が同じだと、ユーザー選択の重要度が反映されていないことになる。
そこで、ランキングをスコア化する際には、上位と下位で重みを変えてみた。
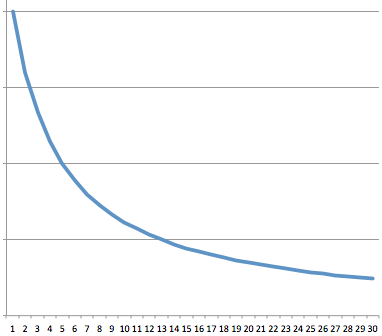
下位になるほど、スコア間に差が小さくなる。
この重みは、様子を見ておいおい調整していく予定。
データ集め・整形
様々な情報を集めて5000件ほどのマンガタイトルを収集したものの、ネックになったのはフリガナで、形態素解析とWikipediaのおかげでなんとか揃えた。
さらに、途中からサムネイルを表示することになったので、慌ててASIN番号を集める必要があったり、各マンガの話題度を集めたりと、何だかんだデータを集めるだけで1週間以上かかった。
プロトタイプ + ユーザーテスト
初期プロトタイプを3日で作り、以降、最終版までにプロトタイプを数十バージョン作って身内に公開していた。その間にユーザビリティテストをやってもらったのが5人。その都度、不便なところやコンセプトのブレなどを潰していった。
以下、プロトタイプ&テストの結果、大きめの仕様変更が入ったところ。
サムネイルを表示、順位表示を縮小
当初、マンガタイトルに対してサムネイルを表示しておらず、ランキング順位を大きく表示していた。

しかし、実際に使ってみてもらうと、タイトルの文字列だけではマンガをイメージしずらい上に、なにより使っていてつまらなかった。
また、大きめに表示している「順位」は、ユーザーにとってさほど重要度ではないことが分かった。
サムネイルを表示し、順位の表示を縮小し、現在の形に落ち着いた。

タグ機能を削除
少年マンガ、少女マンガ、SF、ホラーなどのタグを作品ごとに設定できるようにしていたが、UIがごちゃごちゃしてきたので、タグ専用の機能を削除して、タイトル毎のコメント欄にハッシュタグを記述できるようにした。
タイトル毎のコメント投稿機能を削除
はてなブックマークのイメージで、好きなマンガを選んだ時、タイトル毎にコメントを付けられるようにしていた。
また、前述通りタグ機能を廃止した際に、ハッシュタグ機能が付いた。
しかし、「コメントを記述できる」という機能があると、「コメントを記述しないといけない」という無駄なプレッシャーに繋がるという理由で削除。
ランキングタイトル、メモの入力機能を削除
当初、ランキングページという概念があった。
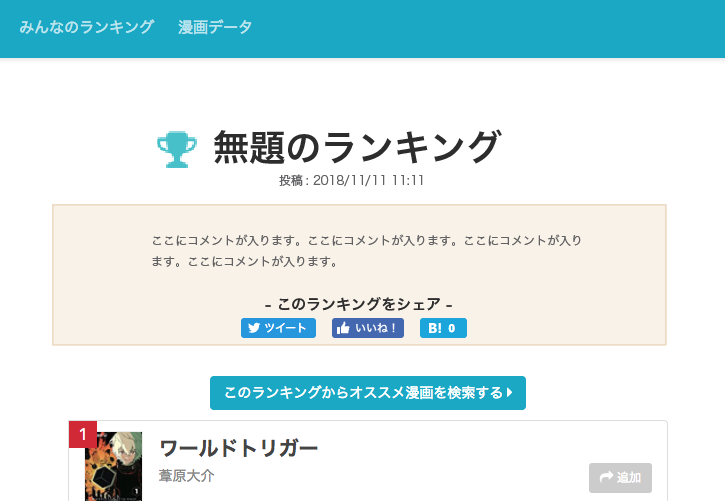
ランキングページは、現在の検索リストと機能的には同じだが、タイトルとメモを記述できるようになっていた。
ユーザーに入力の負荷をかけないために、タイトル・メモともに入力は任意で、タイトルが未入力の場合は「無題のランキング」となるように作っていた。
ところが、テストを始めてみるとタイトルを入力する方が稀で、ほぼすべて「無題のランキング」となり、無意味だということに気づいた。
ランキングページという考え方を廃止した
ランキングページは、ブログ等でよくある「面白いマンガ 30選!」のようなページを生成する機能だった。
オススメマンガを検索する過程でついでに生まれる副産物なのだが、これを活かそうと考えた結果、サービスのコンセプトがブレてしまっていた。
**「好きなマンガを選んで、オススメマンガを検索する」**というサービスのはずが、「好きなマンガを選んで投稿すると、手軽にランキングページを作ることができ、さらにオススメのマンガも教えてくれる」という感じにボワボワしていた。
ランキングページという考え方を止めて、検索リストという考え方とし、サービス内での重要度を落とした結果、ずいぶんスッキリとした。
検索後、すぐにレコメンド結果を表示
ランキングページの概念があった影響で、レコメンドまで次のような手順になっていた。
- 好きなマンガを選ぶ
- 面白い順に並べて投稿
- 投稿された内容が、検索リストとして表示される
- リストからオススメマンガを検索する
- オススメマンガを表示
このうち、3と4を省いた結果、
- 好きなマンガを選ぶ
- 面白い順に並べて投稿
- オススメマンガを表示
となって、手順がスッキリした。
「お気に入り」と「検索履歴」を追加
テストしてもらったユーザーを見ていると、興味を持ったマンガが、今すぐオススメ検索したい好きなマンガとは限らなかった。未読だけど読んでみたいと思ったマンガをメモっておきたいとか、後でオススメ検索したいマンガがあったけど覚えていない、といった場面が何度も見られたため、「お気に入り機能」を追加した。
また、サイトの構造上、「オススメ検索結果」→「好みが近い検索データ」→「オススメ検索結果」→… といった具合にユーザーの動線が循環しやすいので、前に見ていたページに戻りたいけどドコだったか分からない、という場面が発生していたため、ユーザー自身の「検索履歴機能」を追加した。
【教訓】 余計な機能はコンセプトを濁らせちゃうね
ついつい「こんな機能もあると便利だよね」と機能を作ってしまうが、コンセプトを濁らせているなと思ったものはゴリゴリ削っていった。
【教訓】 ユーザビリティテストなしでコンテンツを作るのは無謀
無謀っすよ。
今後の課題
- 現在の意識低い構成でどこまでアクセスが捌けるのか
- 捌き切れない場合は、クラウドをスケールアップすれば足りるのか。 node + Redis で組み直すのか
- そもそも、捌ききれなくなるほどユーザーに使ってもらえるのか
- 中途半端なサジェスト機能をちゃんと作る
- 作者用のサジェストも作る
- データ数が溜まってきたら、レコメンド性能を検証する
オススメマンガを探してみて!
検索データが溜まらないことには、ポンコツ性能のまま!
使ってもらうほど賢くなるはず。使ってみて!!!