はじめに
NEUTRINO の歌声, 素晴しいですよね. 私もあの少し舌足らずな歌声にすっかり魅了されてしまい NEUTRINO を使用した楽曲を聴き漁っていましたが, そのうち趣味が高じて深層学習を利用した統計的音声合成をやってみたいと考えるようになりました. 残念ながら 2020 年 6 月現在 NEUTRINO はオープンソースではありませんが, 同様に深層学習を利用した歌声合成のフレームワークとして NNSVS が存在します. 結果の再現性が重視されていて レシピという形で歌声合成に必要な全行程を実行できるスクリプトが提供されているのが特徴です. 本稿では Google Colaboratory 上で NNSVS で遊ぶための簡単な HOWTO を提供します. 想定している読者は次の通りです.
- Linux の簡単なコマンドがわかる, またはコマンドラインインターフェイスに抵抗感がない
- 簡単なシェルスクリプトや python プログラムを読み書きできる
なぜ Google Colaboratory なのか
NNSVS は python で書かれています. Windows 上で python を使うには python 公式ページ で配布されているもの以外にも Anaconda (Miniconda), Cygwin, MSYS2, Windows subsystem for Linux (WSL), Docker を利用するなど様々な方法があります. 深層学習を効率良く行うために GPU を使うのが一般的ですが, Windows 上で python から GPU を扱うためには 2020 年 6 月現在 Windows のネイティブアプリケーションとして動作する Python が必要です (この時点で WSL と Docker は除外. 将来 WSL2 で GPU が使用できるようになれば有力な候補になるでしょう). また, Cygwin, MSYS2 の python では 予期せぬエラーが起きたり一部の python ライブラリのインストールに失敗する という報告もあり, Windows 上で python から GPU を扱うには Anaconda (Miniconda) を利用するのが簡便です. しかし Anaconda (Miniconda) だけでは NNSVS の 東北きりたん歌唱データベース 用のレシピに必要な Pysinsy をビルドできないという問題もあります.
これに対し Google Colaboratory では深層学習に必要な python ライブラリや GPU がいつでも使用できる状態で用意されています. また内部では Ubuntu Linux 18.04.3 LTS が動作しており Linux 由来の豊富かつ強力な開発環境が使用できます. 連続使用は最長 12 時間という制約はあるものの深層学習を試すにあたっては非常に強力なツールとなります.
基本的な環境構築
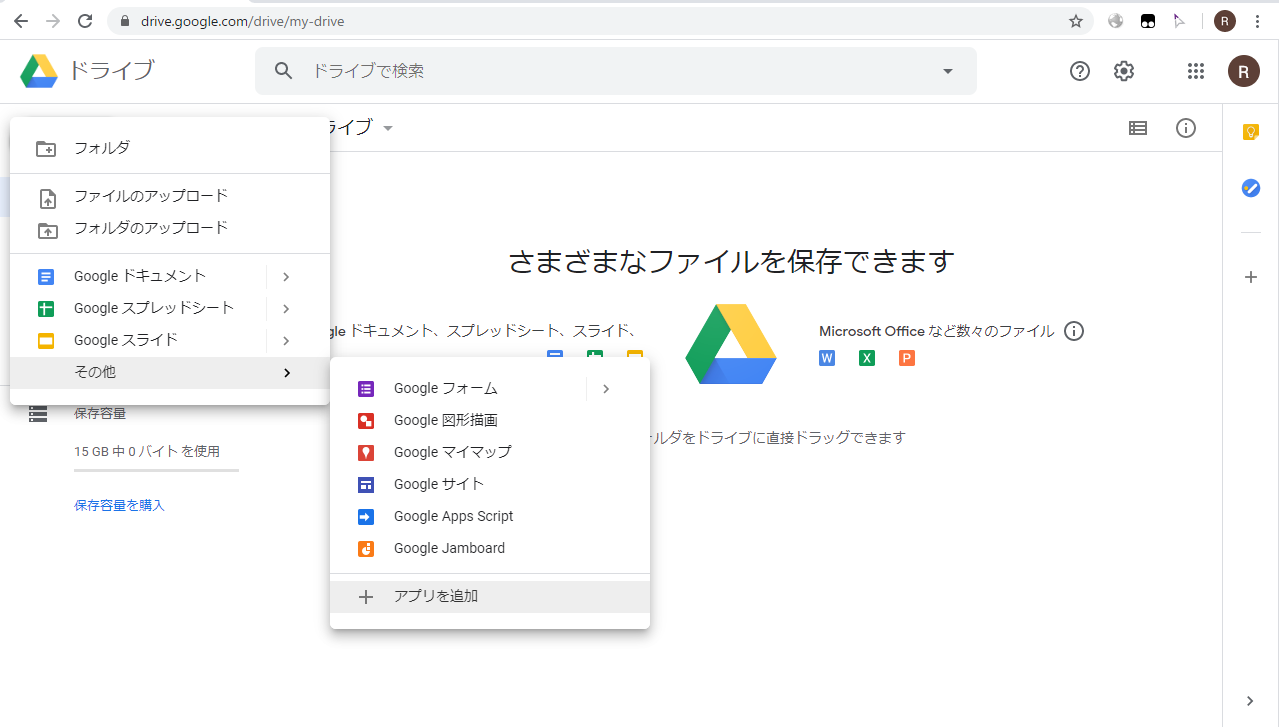
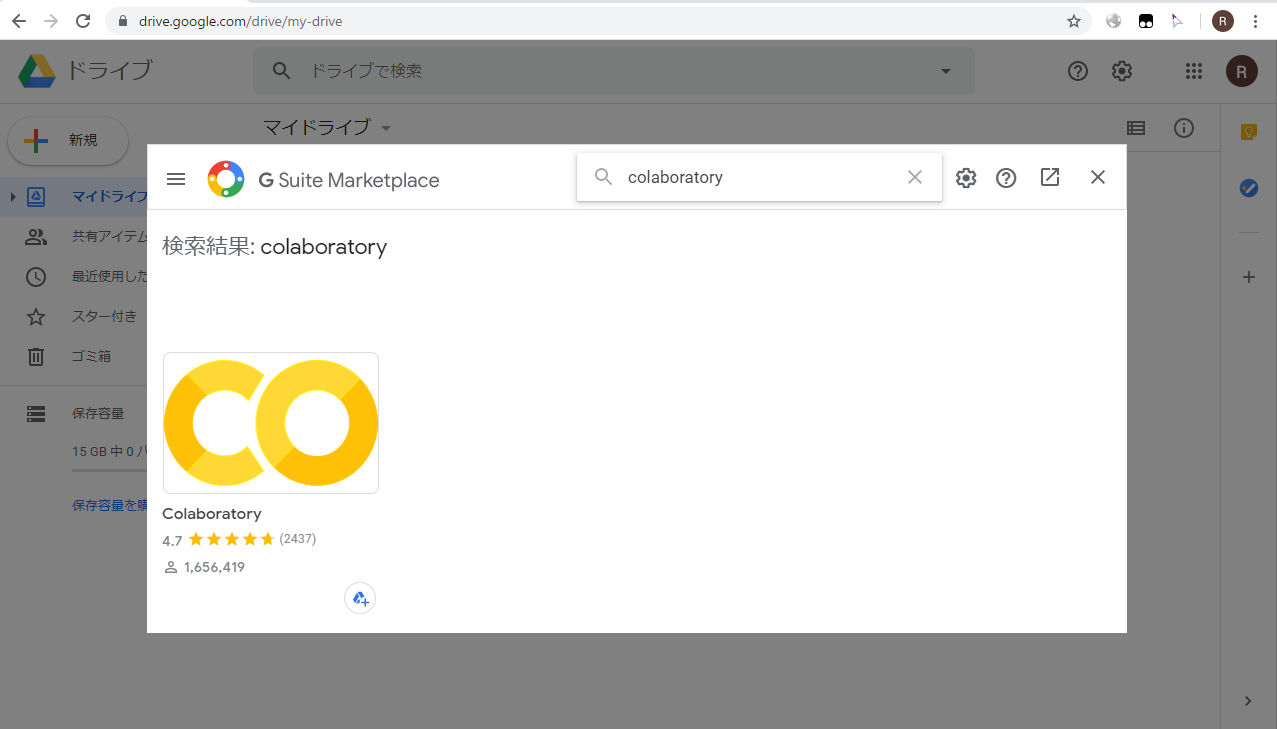
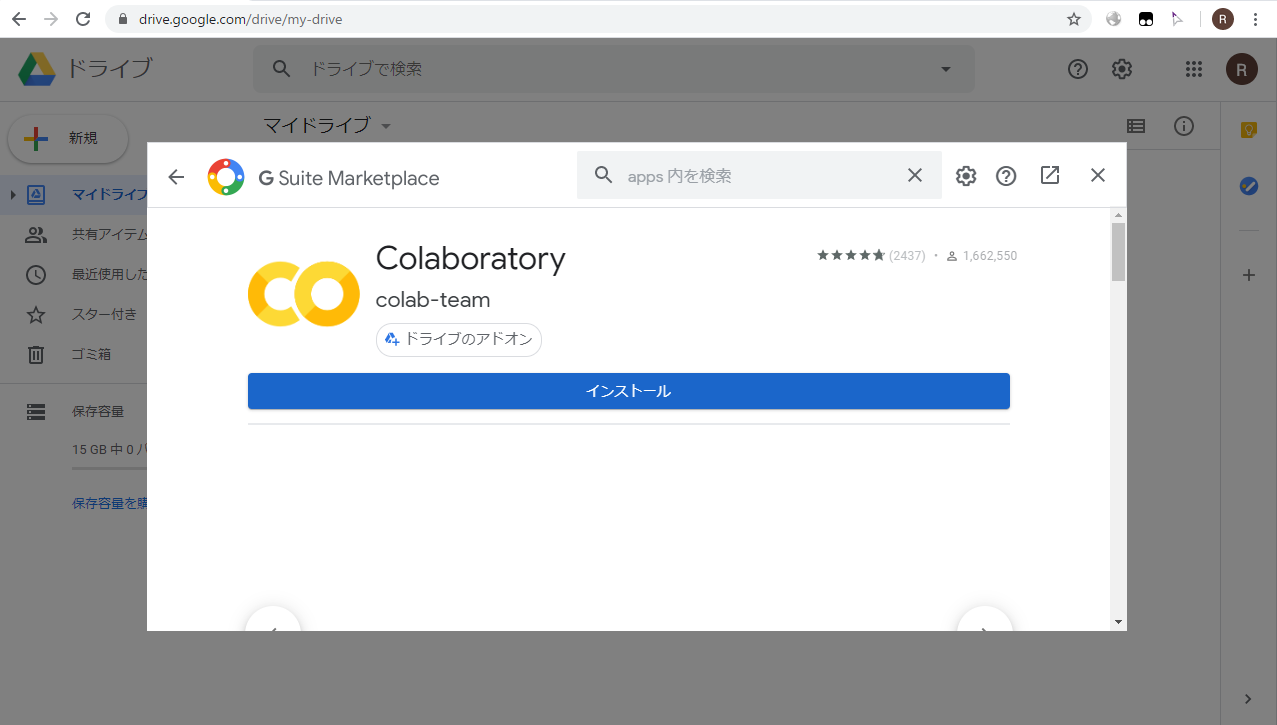
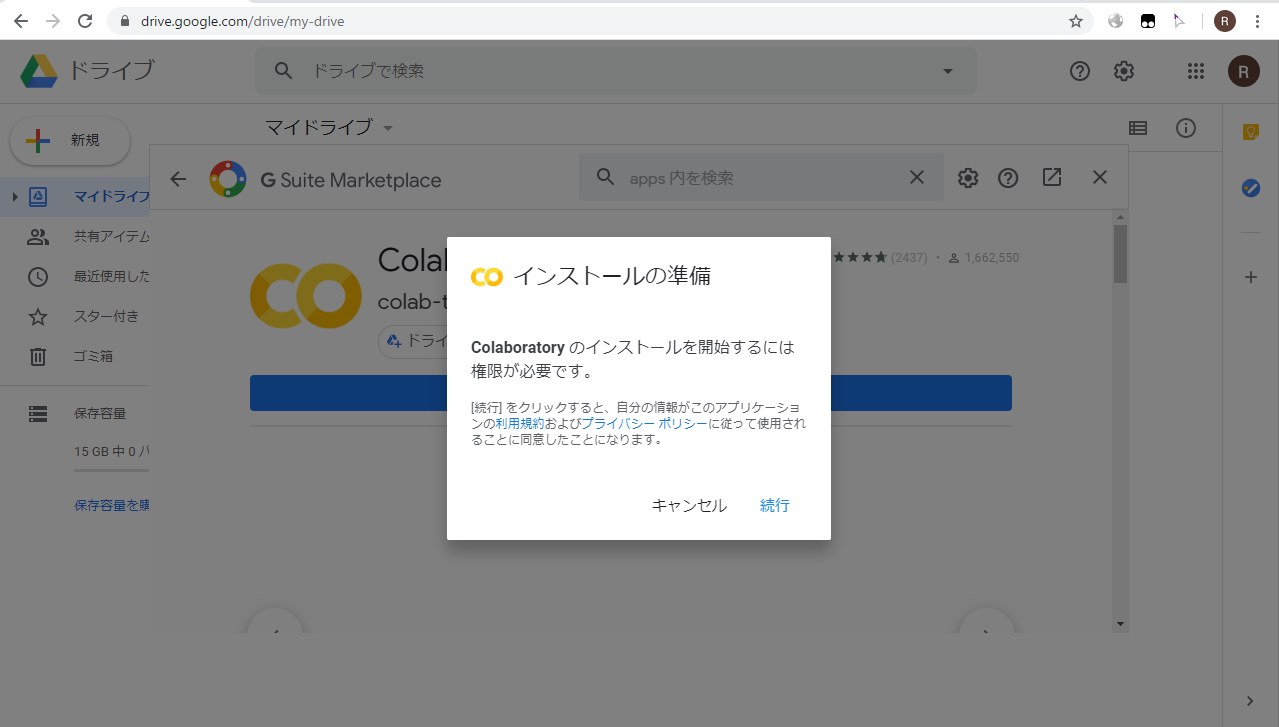
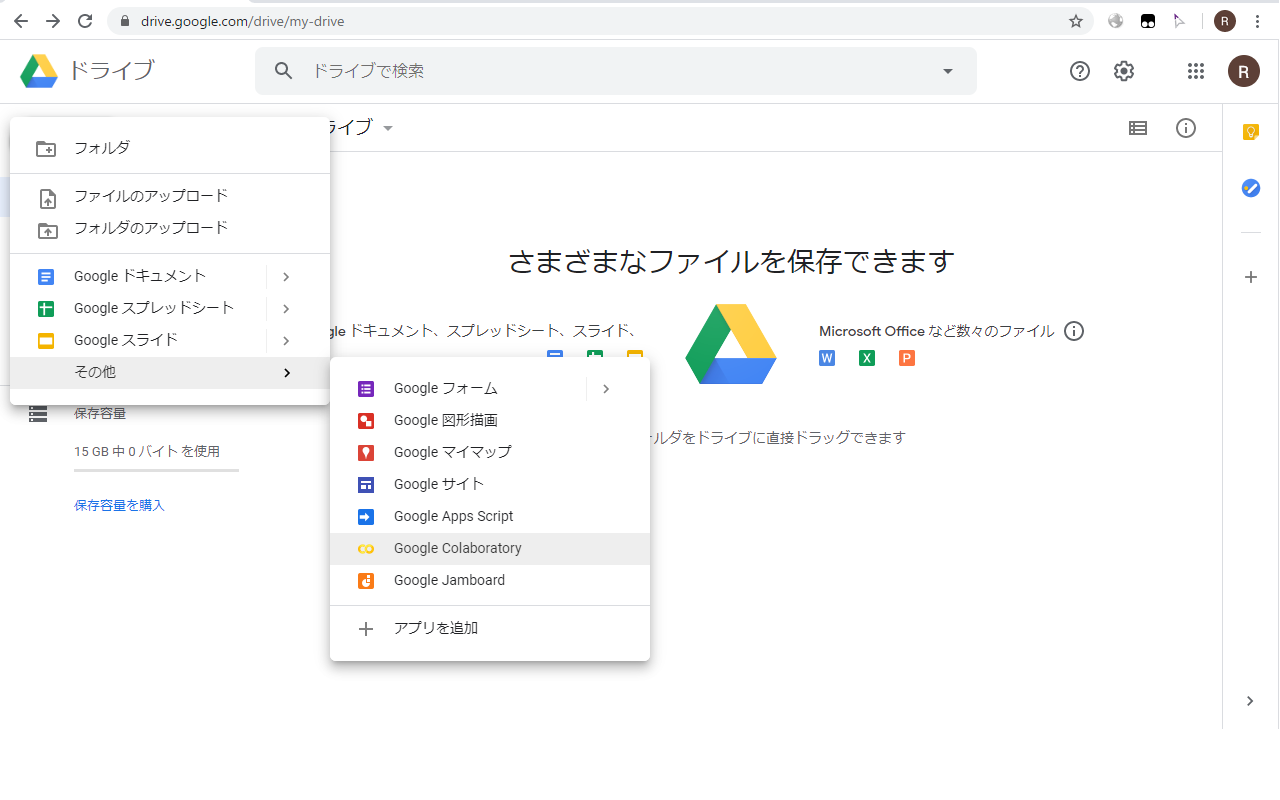
Google Colaboratory の基本的な使い方に関しては割愛します. Google アカウントにログインして Google Drive から [新規]->[その他] で [Colaboratory] を選択, または Colaboratory が選択肢にない場合は [アプリを追加] から Colaboratory を検索してインストールすると使用可能になります. Colaboratoryを新規作成したらメニューから [編集]-[ノートブックの設定] を選びハードウェアアクセラレータを None から GPU に変更します.
NumPy, Cythonのアップグレード
NumPy, Cythonは最初からColaboratoryにインストールされていますが, 最新版にアップグレードするためにセルに以下のように入力して実行してください.
! pip install -U numpy cython
hts_engine_API, sinsy のビルド
NNSVS は楽譜 (musicxml ファイル) から歌声合成に必要な情報が書かれたラベルファイル (lab ファイル) に変換するために Sinsy の python wrapper である Pysinsy を使います. Pysinsy のインストールに必要な hts_engine_API, Sinsy をビルドしますが, それぞれ公式からのリリースではなく NNSVS の作者である Ryuichi Yamamoto 氏の fork を使います.
! git clone -q https://github.com/r9y9/hts_engine_API
! cd hts_engine_API/src && mkdir -p build && cd build && cmake -DCMAKE_BUILD_TYPE=Release -DBUILD_SHARED_LIBS=ON -DCMAKE_INSTALL_PREFIX=/usr/ .. && make -j > hts_engine_API_build.log 2>&1 && make install
! git clone -q https://github.com/r9y9/sinsy
! cd sinsy/src/ && mkdir -p build && cd build && cmake -DCMAKE_BUILD_TYPE=Release -DBUILD_SHARED_LIBS=ON -DCMAKE_INSTALL_PREFIX=/usr/ .. && make -j > sinsy_build.log 2>&1 && make install
Pysinsy, nnmnkwii, NNSVS のインストール
NNSVS は音声合成システムを作るためのライブラリである nnmnkwii 上に構築されています. Pysinsy, nnmnkwii, NNSVS をインストールするためにセルに以下のように入力して実行してください.
! git clone -q https://github.com/r9y9/pysinsy
! cd pysinsy && export SINSY_INSTALL_PREFIX=/usr/ && pip install -q .
! git clone -q https://github.com/r9y9/nnmnkwii
! cd nnmnkwii && pip install -q .
! git clone -q https://github.com/r9y9/nnsvs
! cd nnsvs && pip install -q .
これで NNSVS を使用する準備が整いました.
NNSVS で 東北きりたん歌唱データベースを使用してみる
さきほど NNSVS をインストールする過程でダウンロードされたファイルは /content/nnsvs 以下にあります. そのうち egs ディレクトリ以下にあるものが既に用意された再現可能な歌声合成のレシピになります. 2020 年 11 月現在 7 つのレシピが提供されています.
まずは東北きりたん歌唱データベースを使用したレシピを試してみましょう.
(2020.11.21追記) NNSVS のレシピの構造が 2020年11月に大きく変更され, 設定ファイルが config.yaml という形で分離されました. 古いバージョンの NNSVS をお使いの方は適宜読み替えてお使いください.
東北きりたん歌唱データベースのダウンロード
研究者向け東北きりたん歌唱データベース ログインページ から kiritan_singing.zip をダウンロードします (要 facebook アカウント). ダウンロードされたファイルを Google Drive 上にアップロードします.
Google Driveのマウント
Google Drive にアップロードしたファイルを Colaboratory から使うためには Google Drive を Colaboratory にマウントする必要があります. セルに以下のように入力して実行してください.
from google.colab import drive
drive.mount('/content/drive')
リンクが表示されますので, それをクリックして Google アカウントへのアクセスを許可してください. 表示されたコードをコピーして Colaboratory 上に戻って "Enter your authorization code:"の下の欄にペーストします.



一部のシェルスクリプトはファイル名にスペースが含まれていると上手く動作しないことがあります. /content/gdrive から Google Drive 上のファイルにアクセスできるようシンボリックリンクを貼ります.
! ln -s "/content/drive/My Drive" /content/gdrive
これでさきほどアップロードした kiritan_singing.zip に /content/gdrive/kiritan_singing.zip からアクセスできるようになりました.
kiritan_singing.zip の解凍と/content/nnsvs/egs/kiritan_singing/svs-world-mdn/config.yaml の編集
セルに以下のように入力して kiritan_singing.zip を解凍します.
! cd /content/gdrive && unzip kiritan_singing.zip
東北きりたん歌唱データベース用のレシピがあるディレクトリに RECIPE_ROOT でアクセスできるようセルに以下のように入力します.
RECIPE_ROOT="/content/nnsvs/egs/kiritan_singing/svs-world-conv/"
東北きりたん歌唱データベース用のレシピは実際には /content/nnsvs/egs/kiritan_singing/svs-world-conv/run.sh というシェルスクリプトの形で提供されます. レシピに展開した kiritan_singing の場所を設定します.
Colaboratory の画面の右端にある [ファイル] から /content/nnsvs/egs/kiritan_singing/svs-world-conv/config.yaml を開き, 12 行目の wav_root を以下のように書き換えます
:/content/nnsvs/egs/kiritan_singing/svs-world-conv/config.yaml 7-13行目
###########################################################
# DATA PREPARATION SETTING #
###########################################################
# **CHANGE** this to your database path
wav_root: "/content/gdrive/kiritan_singing/wav"
もしくはセルから以下のように入力しても良いです.
! sed -i 's#\/home\/ryuichi\/data#\/content\/gdrive#g' RECIPE_ROOT/config.yaml
ステージ-1(データのダウンロード) の実行
ここからは基本的にレシピの提供するステージに沿って実行していきます. 歌声合成に必要なラベルファイルや python スクリプトをダウンロードします. セルに以下のように入力してください.
! cd $RECIPE_ROOT && bash run.sh --stage -1 --stop-stage -1
:出力結果
stage -1: Downloading data
Cloning into 'downloads/kiritan_singing'...
remote: Enumerating objects: 114, done.[K
remote: Counting objects: 100% (114/114), done.[K
remote: Compressing objects: 100% (82/82), done.[K
remote: Total 301 (delta 57), reused 73 (delta 30), pack-reused 187[K
Receiving objects: 100% (301/301), 572.87 KiB | 12.73 MiB/s, done.
Resolving deltas: 100% (119/119), done.
/content/nnsvs/egs/kiritan_singing/svs-world-conv/downloads/kiritan_singing 以下にラベルファイルや python スクリプトがダウンロードされます.
ステージ0(データの準備)の実行
東北きりたん歌唱データベース用のラベルファイルをNNSVSで扱いやすい形に整えます. 本来であれば githubに ssh keyを登録しておけば
! cd $RECIPE_ROOT && bash run.sh --stage 0 --stop-stage 0
で自動的にデータの準備が行われますが, Colabolatory からだと $RECIPE_ROOT/downloads/kiritan_singing/run.sh から呼ばれる git submodule update –init に失敗するので, 少々細工します.
$RECIPE_ROOT/downloads/kiritan_singing/kiritan_singing_extra を一旦削除して github から手動でダウンロードし直します.
! cd $RECIPE_ROOT && rm -rf downloads/kiritan_singing/kiritan_singing_extra
! cd $RECIPE_ROOT/downloads/kiritan_singing && git clone -q https://github.com/r9y9/kiritan_singing_extra
kiritan_singing に含まれる python スクリプトが jaconv を必要とするのでインストールします (これはレシピ側に含まれていても良いかもしれません).
! pip install -q jaconv
$RECIPE_ROOT/downloads/kiritan_singing/gen_lab.py で Sinsy の辞書ファイルの場所を /usr/local/lib/sinsy/dic 以下に決め打ちしている場所があるのでシンボリックリンクを張ります.
! mkdir -p /usr/local/lib/sinsy
! ln -s /usr/lib/sinsy/dic /usr/local/lib/sinsy/dic
ステージ 0 を実行します. Colaboratory の CPU はそれほど高速ではないので時間がかかります.
! cd $RECIPE_ROOT && bash run.sh --stage 0 --stop-stage 0
:出力結果
stage 0: Data preparation
Submodule 'kiritan_singing_extra' (git@github.com:r9y9/kiritan_singing_extra.git) registered for path 'kiritan_singing_extra'
musicxml/01.xml
musicxml/02.xml
[WARN] The last note is not rest
(中略)
100% 50/50 [00:00<00:00, 365.73it/s]
Prepare data for acoustic models
100% 50/50 [17:48<00:00, 21.37s/it]
/content/nnsvs/egs/kiritan_singing/00-svs-world
train/dev/eval split
ステージ 1 (タイムラグ, 継続長, 言語特徴量, 音響特徴量の抽出) の実行
歌声合成に必要なタイムラグ, 継続長, 言語特徴量, 音響特徴量を抽出します. この処理もかなりの時間がかかるので, 何度も歌声合成の実験を行う場合はレシピを Google Drive 以下に移動して Colaboratory のインスタンスが初期化されてもデータが残るようにすると良いかもしれません.
! cd $RECIPE_ROOT && bash run.sh --stage 1 --stop-stage 1
:出力結果
stage 1: Feature generation
[2020-06-18 01:39:12,942][nnsvs][INFO] - acoustic:
enabled: true
f0_ceil: 700
f0_floor: 150
(中略)
out_dir: dump/kiritan/norm/eval/out_acoustic/
scaler_path: dump/kiritan/org/out_acoustic_scaler.joblib
verbose: 100
100% 7/7 [00:00<00:00, 99.71it/s]
ステージ 2-4 (タイムラグモデル, 継続長モデル, 音響モデルの学習) の実行
ここまでは特に GPU を必要としない処理でしたが, ここからは GPU が使えると処理が高速になります. ステージ 2 がタイムラグモデル, ステージ 3 が継続長モデル, ステージ 4 が音響モデルの学習になります.
! cd $RECIPE_ROOT && bash run.sh --stage 2 --stop-stage 4
:出力結果
stage 2: Training time-lag model
+ nnsvs-train data.train_no_dev.in_dir=dump/kiritan/norm/train_no_dev/in_timelag/ data.train_no_dev.out_dir=dump/kiritan/norm/train_no_dev/out_timelag/ data.dev.in_dir=dump/kiritan/norm/dev/in_timelag/ data.dev.out_dir=dump/kiritan/norm/dev/out_timelag/ model=timelag train.out_dir=exp/kiritan/timelag data.batch_size=8 resume.checkpoint=
[2020-06-18 02:03:30,986][nnsvs][INFO] - cudnn:
benchmark: false
deterministic: false
(中略)
[2020-06-18 02:19:49,388][nnsvs][INFO] - [Best loss 0.8945809304714203: checkpoint is saved at /content/nnsvs/egs/kiritan_singing/00-svs-world/exp/kiritan/acoustic/best_loss.pth
100% 50/50 [13:34<00:00, 16.29s/it]
[2020-06-18 02:19:49,417][nnsvs][INFO] - Checkpoint is saved at /content/nnsvs/egs/kiritan_singing/00-svs-world/exp/kiritan/acoustic/checkpoint_epoch0050.pth
[2020-06-18 02:19:49,436][nnsvs][INFO] - The best loss was 0.8945809304714203
+ set +x
ステージ 5-6 (歌声合成) の実行
ステージ 5 は学習したモデルの出力, ステージ 6 がモデルを使った歌声合成になります.
! cd $RECIPE_ROOT && bash run.sh --stage 5 --stop-stage 6
:出力結果
stage 5: Generation features from timelag/duration/acoustic models
+ nnsvs-generate model.checkpoint=exp/kiritan/timelag/latest.pth model.model_yaml=exp/kiritan/timelag/model.yaml out_scaler_path=dump/kiritan/norm/out_timelag_scaler.joblib in_dir=dump/kiritan/norm/dev/in_timelag/ out_dir=exp/kiritan/timelag/predicted/dev/latest/
[2020-06-18 02:19:56,324][nnsvs][INFO] - in_dir: dump/kiritan/norm/dev/in_timelag/
model:
checkpoint: exp/kiritan/timelag/latest.pth
(中略)
verbose: 100
[2020-06-18 02:22:50,753][nnsvs][INFO] - Processes 7 utterances...
100% 7/7 [00:42<00:00, 6.14s/it]
+ set +x
合成された歌声は $RECIPE_ROOT/exp/kiritan/synthesis 以下に出力されます. Colaboratory からインタラクティブに視聴するにはセルに以下のように入力します(これは大変重い処理で Colaboratory のランタイムが落ちることがあります. ローカルに保存してからの視聴をお勧めします).
import IPython
from IPython.display import Audio
from glob import glob
from os.path import join
sample_rate=48000
synthesized_wav_paths = sorted(glob(join(RECIPE_ROOT, "exp/kiritan/synthesis/**/label_phone_score/*.wav"), recursive=True))
for wav_path in synthesized_wav_paths:
print(wav_path)
IPython.display.display(Audio(wav_path, rate=sample_rate))

どうでしょうか? NEUTRINO と比較すると音程や発声のタイミングが若干不安定に感じるかもしれませんが, NNSVS はまだ発展途上で現在進行形で改良が進められています. 逆に NEUTRINO が随所に工夫を凝らしていることを実感できるかもしれません. 音程に関してはデフォルトの音響モデルはかなりの頻度で基本周波数の推定に失敗しますが、音響モデルを混合密度ネットワークや別のものに差し替えるとあるていど改善します.
NNSVS で オリジナルレシピを作成する (未完成)
NNSVS で歌声合成を行うには以下の 3 つが必要です.
- 音声データ
- 楽譜 (musicxml), または musicxml から変換されたラベルファイル (HTS フルコンテキストラベルファイル)
- 音声データに含まれる各音素の開始時間, 終了時間が設定されたラベルファイル
2 に関して, 東北きりたん歌唱データベースや PJS corpus は楽譜 (musicxml) を提供しており, HMM/DNN-based Speech Synthesis System (HTS) でデモとして提供されている HTS-demo_NIT-SONG070-F001 は HTS フルコンテキストラベルファイルを提供しています. 自分が使いたい音源の構成に合わせて既存のレシピをを参考にすると良いでしょう.
ここでは夏目悠李氏の男声歌声データベースを使用してオリジナルレシピの作成に挑戦します.
(2020.11.21追記) 夏目悠李/男声歌声データベースは2020年11月4日にNNSVS公式リポジトリにマージされました. 以下の内容は時代遅れとなりますが, 自作の歌声データベースを作成したい方のために残してあります.
夏目悠李/男声歌声データベースのダウンロード
夏目悠李/ 男声歌声データベース配布, 始めました! 【 2020/5/2_13:25 更新】 から利用規約に同意して Natsume_Singing_DB.zip をダウンロードします. ダウンロードされたファイルを Google Drive 上にアップロードします.
Natsume_Singing_DB.zip の解凍と レシピの移植
セルに以下のように入力して Natsume_Singing_DB.zip を解凍します.
! cd /content/gdrive && unzip Natsume_Singing_DB.zip
解凍した夏目悠李/男声歌声データベースの構成は以下のようになっています.
/content/gdrive/Natsume_Singing_DB
├── list.xlsx
├── midi
│ ├── 10.mid
│ ├── 11.mid
│ ├── 12.mid
(中略)
├── mono_label
│ ├── 10.lab
│ ├── 11.lab
│ ├── 12.lab
(中略)
├── README.md
├── readme.txt
├── wav
│ ├── 10.wav
│ ├── 11.wav
│ ├── 12.wav
(中略)
└── xml
├── 10.xml
├── 11.xml
├── 12.xml
(後略)
音声データ, 楽譜, ラベルファイルの組合せで提供されており, 東北きりたん歌唱データベースのレシピか PJS corpus のレシピが流用できそうです. ここでは PJS corpus のレシピを流用してみます. 以下をセルに入力しレシピをコピーします.
! cp -r /content/nnsvs/egs/pjs /content/nnsvs/egs/natsume_singing
/content/nnsvs/egs/natsume_singing/svs-world/run.sh を開いて編集していきます.
6 行目の spk を natsumeyuuri に変更します. また 15 行目の pretrained_expdir を設定しておくと他のレシピで事前に学習したモデルを使用してファインチューニングできますが, 今回は使用しないので空欄にします. ステージ-1 直前までの run.sh は以下のようになります.
:/content/nnsvs/egs/natsume_singing/00-svs-wrold/run.sh 1-59行目
(省略)
script_dir=$(cd $(dirname ${BASH_SOURCE:-$0}); pwd)
NNSVS_ROOT=$script_dir/../../../
spk="natsumeyuuri"
dumpdir=dump
(省略)
pretrained_expdir=
batch_size=8
(省略)
レシピのステージ-1 はデータのダウンロードでした. 夏目悠李/男声歌声データベースでは東北きりたん歌唱データベースのように追加で必要なファイルがないのでここで特にすることはありません. natsume_singing_db_root にデータベースのディレクトリを設定するようにし, ディレクトリが存在しない場合はダウンロードを促すメッセージを表示するように変更しました.
:/content/nnsvs/egs/natsume_singing/00-svs-wrold/run.sh 55-62行目
natsume_singing_db_root=/content/gdrive/Natsume_Singing_DB
if [ ${stage} -le -1 ] && [ ${stop_stage} -ge -1 ]; then
if [ ! -d $natsume_singing_db_root ]; then
echo "stage -1: Downloading"
echo "Please download Natsume_Singing_DB.zip from https://amanokei.hatenablog.com/entry/2020/04/30/230003"
exit
fi
fi
夏目悠李/男声歌声データベース用のレシピがあるディレクトリに NATSUME_SINGING_00_SVS_WORLD_ROOT でアクセスできるようセルに以下のように入力します.
NATSUME_SINGING_00_SVS_WORLD_ROOT="/content/nnsvs/egs/natsume_singing/00-svs-world/"
! cd $NATSUME_SINGING_00_SVS_WORLD_ROOT && bash run.sh --stage -1 --stop-stage -1
ステージ 0 (データの準備) の編集と実行
ステージ 0 はデータの準備でした. /content/nnsvs/egs/natsume_singing/00-svs-wrold/utils/data_prep.py の第一引数を PJS corpus から夏目悠李/男声歌声データベースのディレクトリに変更します. その後の find や grep は学習用のデータと評価用のデータを分けています. 夏目悠李/男声歌声データベースは 51 曲のデータがありそのどれを評価用に選んでも構いませんが, ここでは 50.wav, 51.wav を評価用に選んでみます.
:/content/nnsvs/egs/natsume_singing/00-svs-wrold/run.sh 63-75行目
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
echo "stage 0: Data preparation"
python utils/data_prep.py $natsume_singing_db_root data --gain-normalize
echo "train/dev/eval split"
mkdir -p data/list
# exclude utts that are not strictly aligned
find data/acoustic/ -type f -name "*.wav" -exec basename {} .wav \; \
| sort > data/list/utt_list.txt
grep 50 data/list/utt_list.txt > data/list/$eval_set.list
grep 51 data/list/utt_list.txt > data/list/$dev_set.list
grep -v 50 data/list/utt_list.txt | grep -v 51 > data/list/$train_set.list
fi
セルに以下のように入力します.
! cd $NATSUME_SINGING_00_SVS_WORLD_ROOT && bash run.sh --stage 0 --stop-stage 0
:出力結果
stage 0: Data preparation
Traceback (most recent call last):
File "utils/data_prep.py", line 70, in <module>
assert len(mono_lab_files) == len(muxicxml_files)
AssertionError
エラーになってしまいました. /content/nnsvs/egs/natsume_singing_/00-svs-wrold/utils/data_prep.py を見ると 69 行目で musicxml の拡張子のあるファイルを探しています. 夏目悠李/男声歌声データベースは musicxml ファイルの拡張子が xml になっているので修正します. 今度はどうでしょうか?
:出力結果
stage 0: Data preparation
Traceback (most recent call last):
File "utils/data_prep.py", line 72, in <module>
align_mono_lab = hts.load(mono_path)
File "/usr/local/lib/python3.6/dist-packages/nnmnkwii/io/hts.py", line 325, in load
return labels.load(path, lines)
File "/usr/local/lib/python3.6/dist-packages/nnmnkwii/io/hts.py", line 211, in load
end_time = int(end_time)
ValueError: invalid literal for int() with base 10: '1.86758'
またエラーになってしまいました. "'1.86758'は 10 進数の整数ではない"と表示されています. NNSVS で扱うことのできるラベルファイルの時間の最小単位(100ナノ秒)と夏目悠李/男声歌声データベースのラベルファイルの時間の最小単位(秒)が異なるのが原因です. kiritan_singing にこれを扱うためのコードが含まれている ので拝借します. /content/nnsvs/egs/natsume_singing/00-svs-wrold/utils/data_prep.py を以下のように修正します.
:/content/nnsvs/egs/natsume_singing/00-svs-wrold/utils/data_prep.py 68-85行目
files = sorted(glob(join(args.pjs_root, "**/*.lab")))
# Prepare mono label with 100ns unit.
dst_dir = join(out_dir, "natsume_mono")
os.makedirs(dst_dir, exist_ok=True)
for m in files:
h = hts.HTSLabelFile()
with open(m) as f:
for l in f:
s,e,l = l.strip().split()
s,e = int(float(s) * 1e7), int(float(e) * 1e7)
h.append((s,e,l))
with open(join(dst_dir, basename(m)), "w") as of:
of.write(str(h))
mono_lab_files = sorted(glob(join(out_dir, "natsume_mono", "*.lab")))
muxicxml_files = sorted(glob(join(args.pjs_root, "**/*.xml")))
assert len(mono_lab_files) == len(muxicxml_files)
for mono_path, xml_path in zip(mono_lab_files, muxicxml_files):
:出力結果
stage 0: Data preparation
Traceback (most recent call last):
File "utils/data_prep.py", line 96, in <module>
assert len(align_mono_lab) == len(sinsy_mono_lab)
AssertionError
またエラーになってしまいました. 夏目悠李/男声歌声データベースで提供されているラベルファイルと楽譜から変換されたラベルファイルの長さが合わないようです. これにはいくつか原因があって, 一つは Sinsy が musicxml からラベルファイルを生成するときに, 休符のあとのブレスを無視する (出力しない) ことが原因です. これは Sinsy に簡単なパッチを当てることで改善しますが, 長母音の音素の数の違いや表記のゆれなどは手作業で修正する必要があります. ここを乗り越えるとステージ 1 以降は使用する音源に特異的な処理はなくなり, 手作業で修正が必要な箇所は減ります.
品質改善のために
Github の issues#1 にこれまで実装された機能や今後実装されるかもしれないアイデアがまとめられています. また参考文献として挙げられている Y. Hono et al, "Recent Development of the DNN-based Singing Voice Synthesis System - Sinsy," Proc. of APSIPA, 2017 にも Sinsy で使用されているテクニックが紹介されています. これらのなかからなんとなく hack できそうな気がする (できるとは言ってない) ものを列挙してみます. なお筆者は音声合成も深層学習も全くの門外漢なので, 多分に誤りを含んでいるであろうことを予めご了承ください.
自己回帰 (Autoregressive) モデルの導入
現在 NNSVS の音響モデルは Conv1dResnet (時間軸方向の畳み込み層を積み重ねて残差を学習するようにしたもの) です. 歌唱の発声は各瞬間ごとに独立した存在ではなく時間の流れにそった展開があり, 合成したい時間より前の時間の合成結果も利用すると歌声合成の品質が上がる可能性があります. 時系列データの深層学習では再帰型ニューラルネットワーク (Recurrent Neural Network:RNN) や Long-short term memory (LSTM) が良く利用されるようですが,NEUTRINO のように AR 付きの FFNN に変更しても改善するのではないかと思います. nnsvs/data/data_source.py で各特徴量を抽出するときに細工をして, 学習時に Data Loader に言語特徴量だけでなく前の時間の音響特徴量も渡すようにすれば良いのでしょうか?
ビブラートモデルの導入
先ほど挙げた Sinsy の論文で紹介されていますが, ビブラートを sin で近似された f0 の振動と解釈することで歌声合成にビブラートを追加できるようです. ビブラートの周波数は 5Hz から 7Hz だとすると, 音声特徴量の抽出時に f0 の変動を周波数解析してローパスフィルターをかけて, 振幅と周期の 2 次元を音響特徴量に足せば良いでしょうか?
タイムラグモデルを混合密度ネットワーク (Mixture density network:MDN) に変更する
これも Sinsy の論文で紹介されていますが, 各音素の継続時間は音素の種類 (母音, 子音, 休符) によって異なり, 継続時間の変化も考慮したタイムラグモデルを構築するには MDN を使うと良いようです. MDN は Pattern Recognition and Machine Learningl (PRML book) の p. 272 で取り上げられていますが, 1 つの入力に複数の出力が対応するような逆問題のモデル化に良いようです. github 上には pytorch による MDN の実装もいくつかありますが, 私が数学的背景を良く分かっていないのでそれをどのように NNSVSで使えば良いかわかりません.
NN-vocoderの導入
現在 NNSVS では歌声合成に World (正確にはその Python wrapper である PyWorldVocoder) が使用されていますが, これも深層学習を利用した方法に変更することで品質が改善する可能性があります. おりしも 2020 年 6 月に NEUTRINO で使用されている NN-vocoder である NSF の PyTorch 版 がリリースされました. NNSVS は学習の過程で音響特徴量と音声データを npy の形で出力する ので, それらをもとに NSF を学習させれば NN-vocoder の導入は容易だと思います. ただ NSF の学習はかなり時間のかかる工程であり, 筆者の PC (GPU は NVIDIA Quadro M4000) で添付された 00_demo.sh を走らせるのに hn-nsf だと 1 日半, NEUTRINO でも使用されている hn-sinc-nsf だと 5 日, cyc-noise-nsf に至ってはおそらく GPU のメモリ不足で未だに結果を確認できていません. 12 時間制限のある Colaboratory で学習させるには途中経過を Google Drive に保存してあとからレジュームできるようにするなど工夫が必要そうです.
おわりに
Google Colaboratory 上で NNSVS で遊ぶための方法を簡単に解説しました. 歌声合成は信号処理や機械学習など必要とされる知識が多く敷居が高く感じられますが, このmini-HOWTOが最初の一歩を踏み出す一助になれば幸いです. 素晴らしいライブラリを作成してくださった Ryuichi Yamamoto 氏をはじめオープンソースコミュニティの皆様方に感謝します.
関連記事
- Windows で可搬性のある NNSVS 環境を作る mini-HOWTO (2020/09/11)
- Windows で可搬性のある NNSVS 環境で遊ぶ mini-HOWTO (2020/09/16)