はじめに
入門監視、読みました。最近、監視項目を整理していたところだったので、まさにアンチパターンをふんでしまっていた私にとって、ものすごく有用なものでありました。
自分、監視の考え全然整理できていないと思い、今筆をとっているところでございます。
ちょっと回りくどいかもしれませんが、入門監視を読んで、ゼロベースで監視について自分の頭を整理したものをここに記します。
まずはじめに - 監視とは
監視とは、あるシステムやそのシステムのコンポーネントの振る舞いや出力を観察しチェックし続ける行為である
ふむふむなるほど。当たり前といえば、当たり前ですが、心に留めておきましょう。
Monitorama PDX 2016 - Greg Poirier - Monitoring is Dead. Long Live Monitoring

次に、監視の要素は以下のように定義されていました。
- データ収集
- データストレージ (蓄積)
- 可視化
- 分析とレポート
- 通知 (アラート)
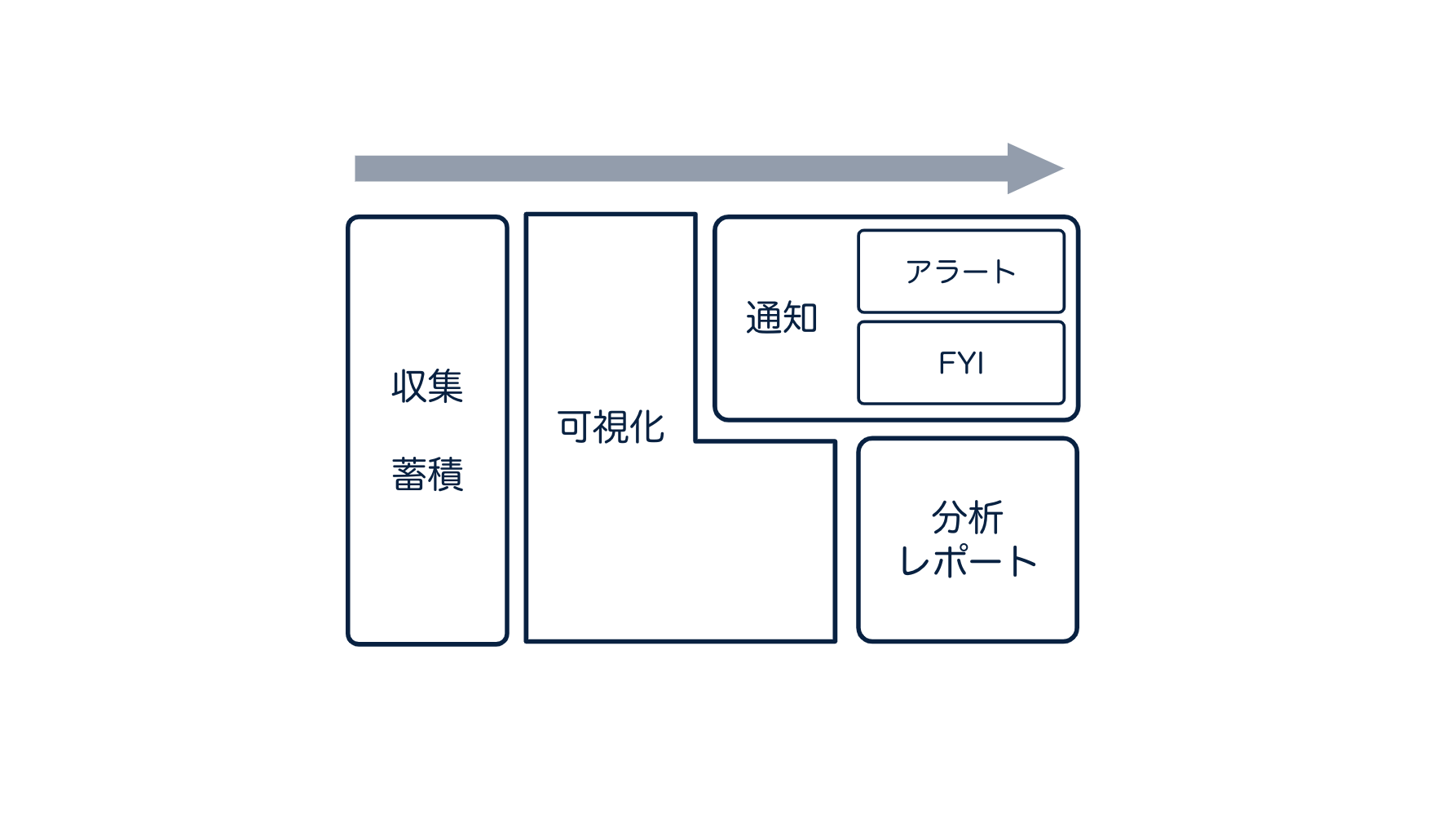
監視 とはなにか、なんとなく定義ができてきました。
監視ってなんのためにあるの?
「監視項目はこんな感じで」、ザーッと思いつく項目を (一応各レイヤでもれなく) 洗い出して、これを監視しておけば大丈夫。
という気になってしまっていた私です。ただ、先述した監視の定義から、やっていることは間違いないです。
ただ、確かにCPU使用率が90%を5min継続したときにslack飛んでくるけど、これでちゃんと"監視"できているんだっけ? ということですよね。入門監視のアンチパターンにガッツリハマってしまいました。
今回を機に、改めて監視について考え直したいと思います。
システム管理者としてのキャリアを始めた頃、私はリードエンジニアのところへ行きました。あるサーバのCPU使用率が高いことを伝え、どうしたらよいか聞きました。彼の答えは私を驚かせるものでした。「そのサーバはやるべき処理はしてるんだろう?」そうだと私は答えました。「それなら、何も問題はないじゃないか」
動かすサービスによっては、元々リソースをたくさん使うものもありますが、それで問題ないのです。MySQLが継続的にCPUを全部使っていたとしても、レスポンスタイムが許容範囲に収まっていれば何も問題はありません。これかこそが、CPUやメモリ使用率のような低レベルなメトリクスではなく、「動いているか」を基準にアラートを送ることが有益である理由です。
(1.3.2 アラートに関しては、OSのメトリクスはあまり意味がない より)
そもそも、なんのために監視があるんだっけ。それは、"なんらかのアクションをとるため" です。
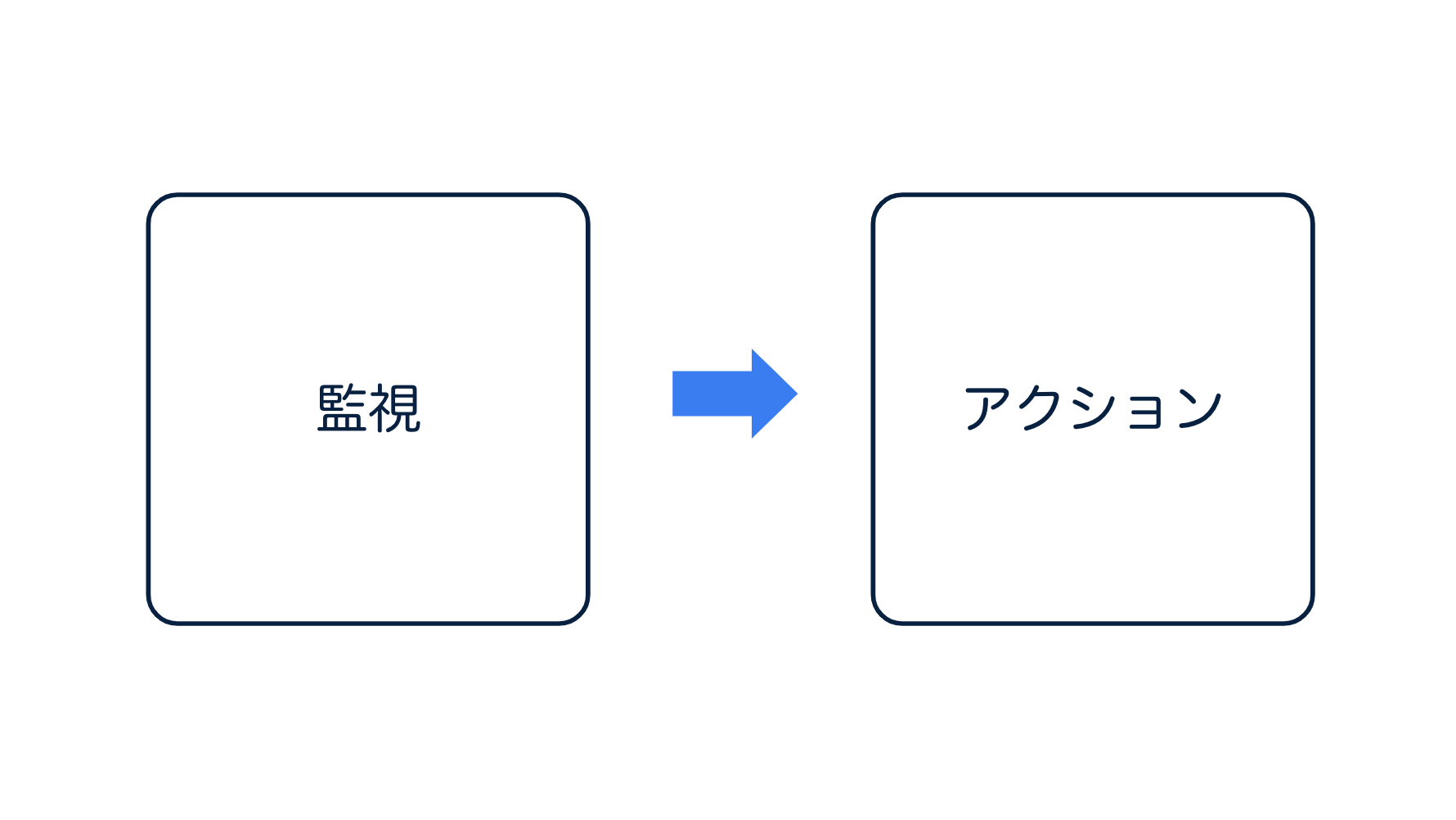
slackでCPU使用率90%超過のアラート飛んできているけど、私なんにもアクション取っていません。だからダメ🙅なんですよね。
アクションとは?
ここでいう"アクション"とは何でしょう。ここで登場人物をせいりしたいと思います。
- 登場人物
- システム
- ユーザ
- 運用者
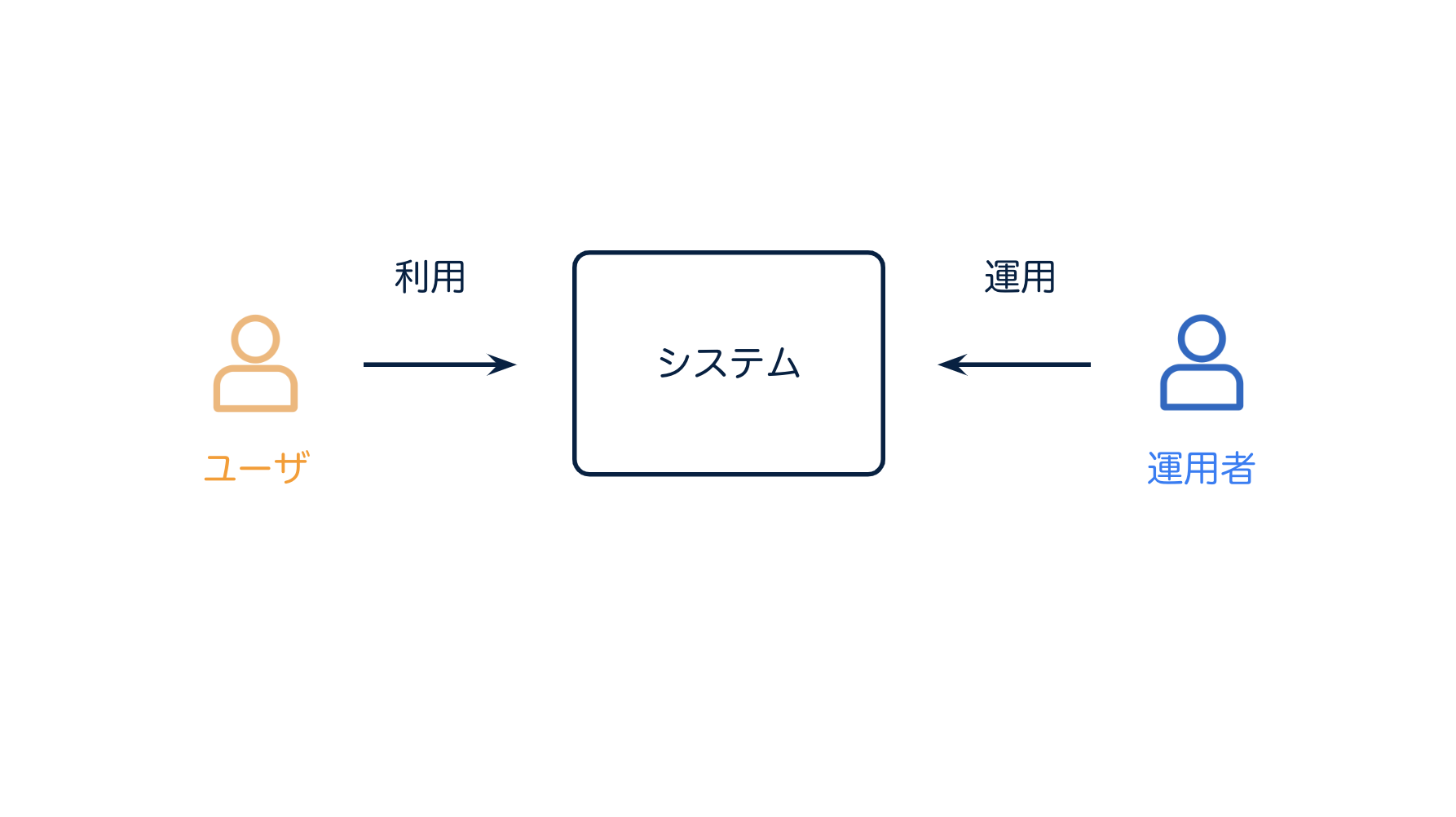
まず "システム" があって、それを利用する "ユーザ" がいます。
このシステムを 運用 するのが運用者
話を戻すと、アクション とは、運用者が システムに対して 行うものと定義します。
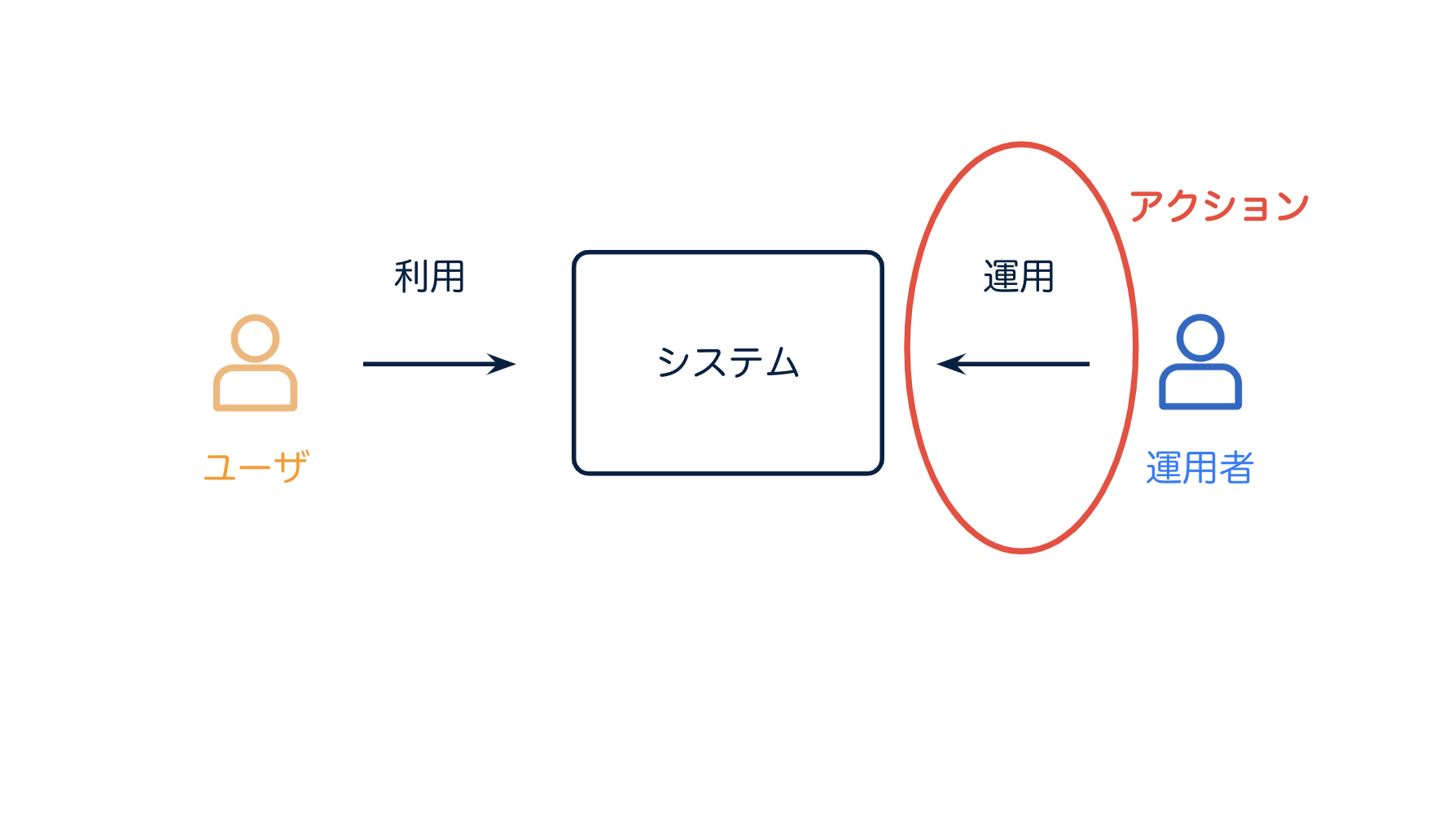
そして、このアクションを取るための、"監視" ですね。最初の目的のところです。
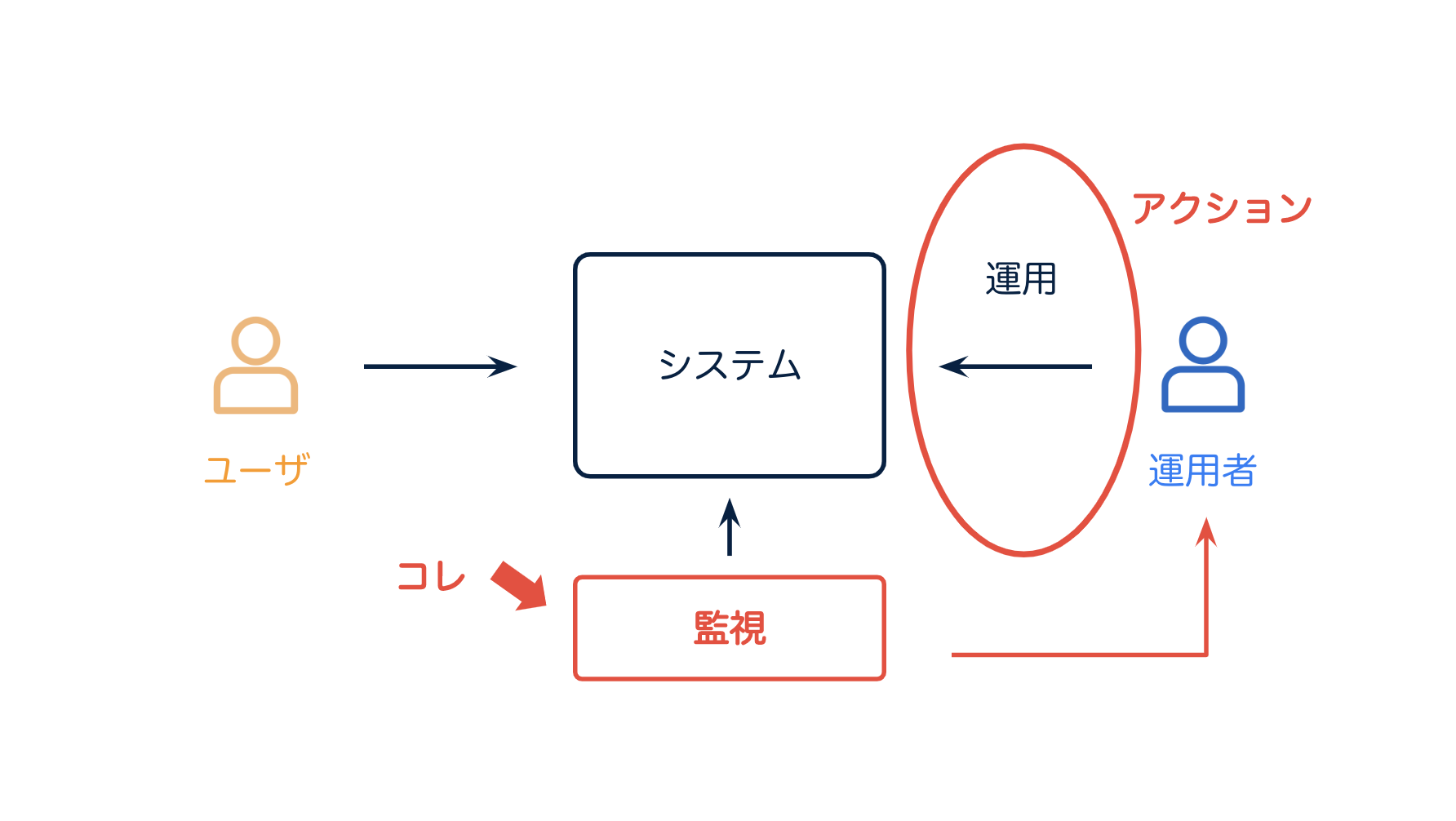
アクションとは
では、次にここでいう アクション とは何を指すのでしょう。それはまず、システム運用者の責務を整理する必要があります。
システムの運用ってなにするのでしょう。これは SRE本から引用
ソフトウェアの価値をユーザーに届け続ける役割
一つ、明確なのは、システムが利用不可の状態になっていたら
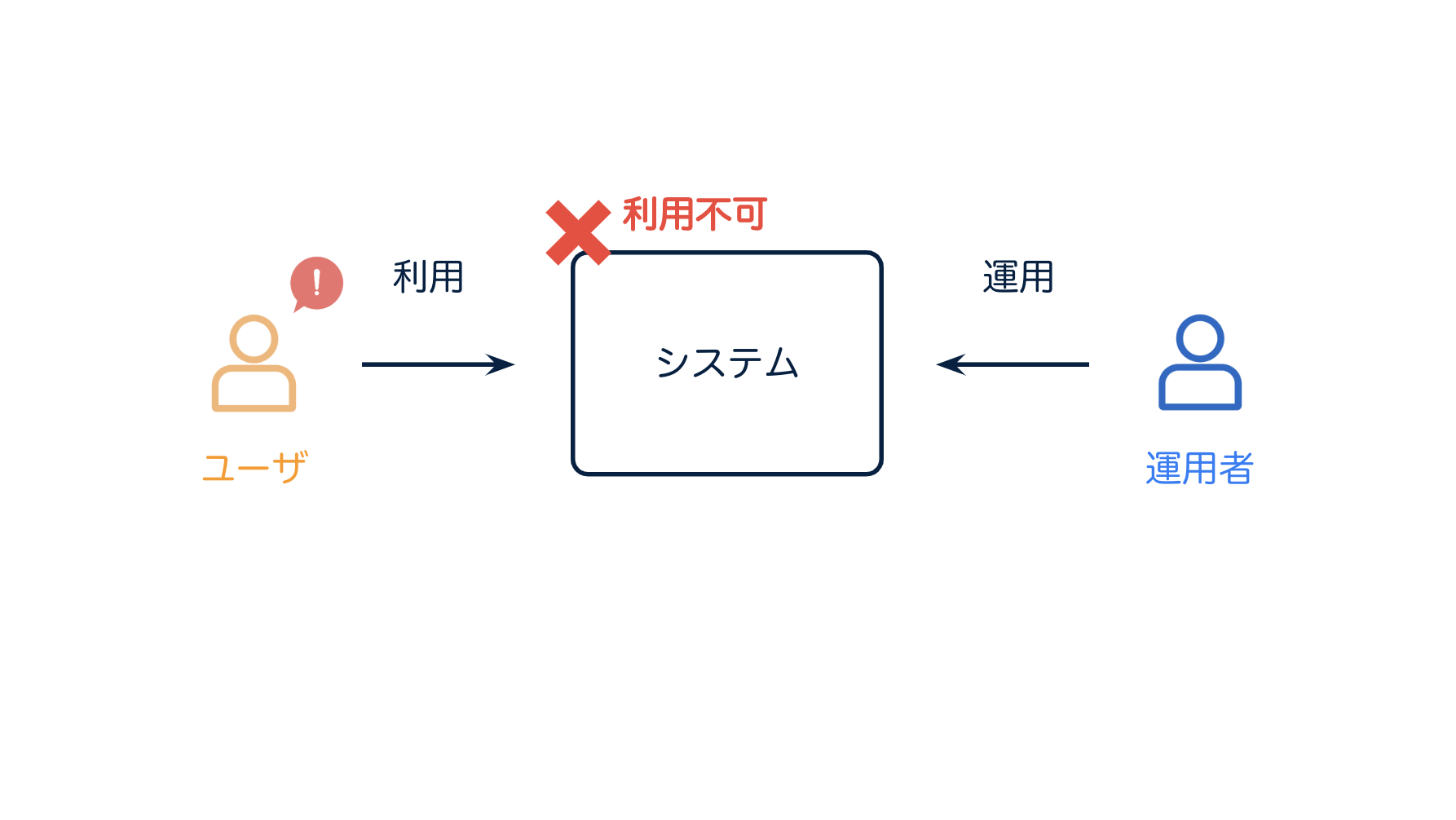
利用可能な状態に戻す、というのがわかりやすい責務ですね
もちろんこれだけではないと思います。例えば、システム(インフラ)を最適化してより良い体験をユーザにしてもらうことはもちろん、コスト削減も運用者の責務であると考えます。システムに対してアクションを取るのは、なにか変化が必要だからです。そのBEFOREとAFTERを整理してみました。大きく2つに分類できると思います。
-
Bad -> Good
- システムが正常でない状態から、正常に戻すアクション
-
NOT Great -> Great
- システムは正常に稼働している状態だが、さらに良い状態にするアクション
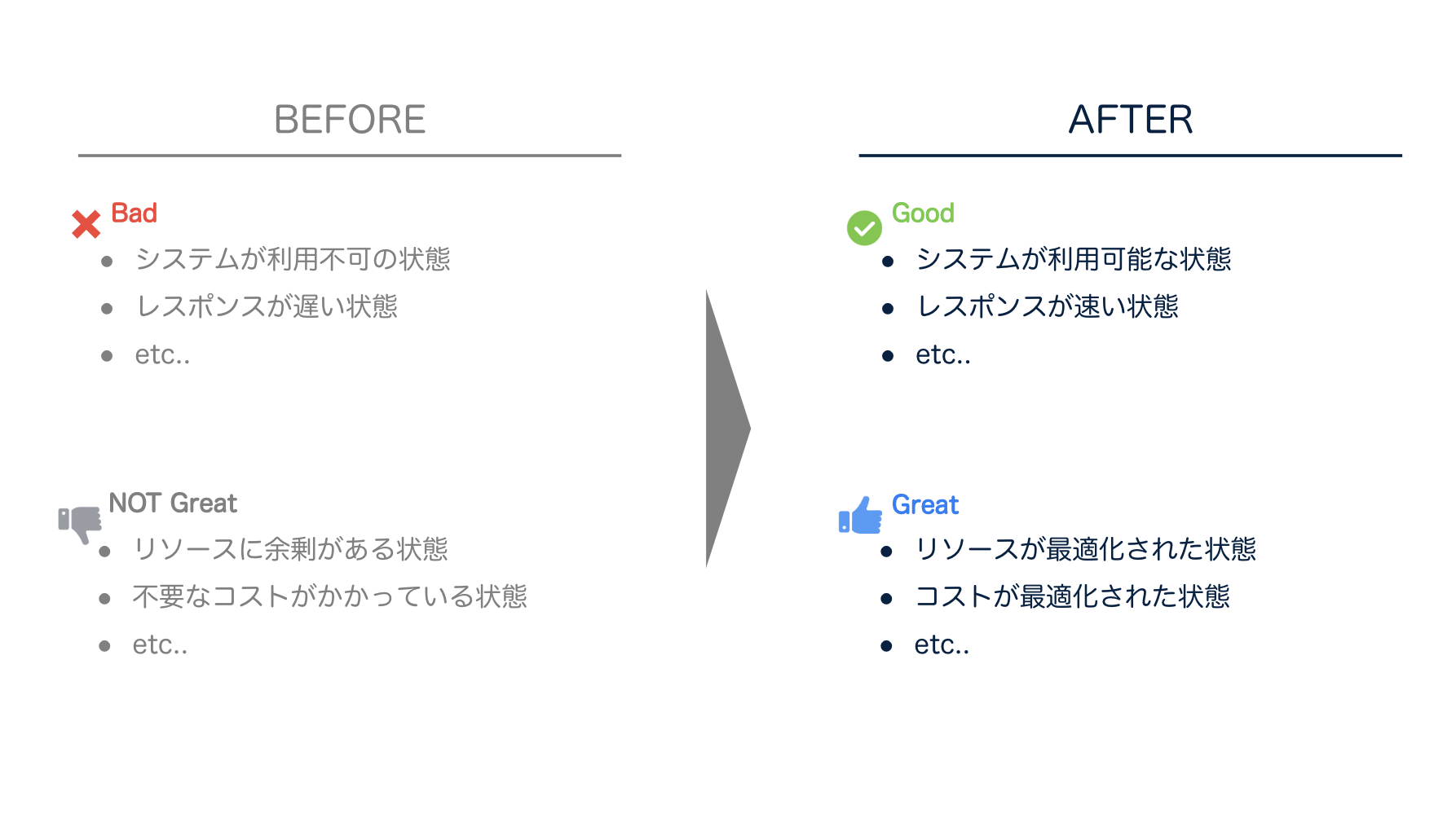
アクションの分類
これらのアクションを取るのが、運用者の責務であると整理しまいたが、もう少しこれらのアクションを整理したいと思います。
上図のように、"Bad -> Good" とするためのアクションと、"NOT Great -> Great" とするアクションに分かれますが、さらに重要なファクターは**"緊急度"** だと考えます。
緊急度を加えて、分解すると以下のようになりました。 "NOT Great -> Great" は 緊急はないですよね。
※ ここで書いている緊急とは、"夜中に叩き起こされる" 必要があるレベルをイメージしてもらえば良いです。
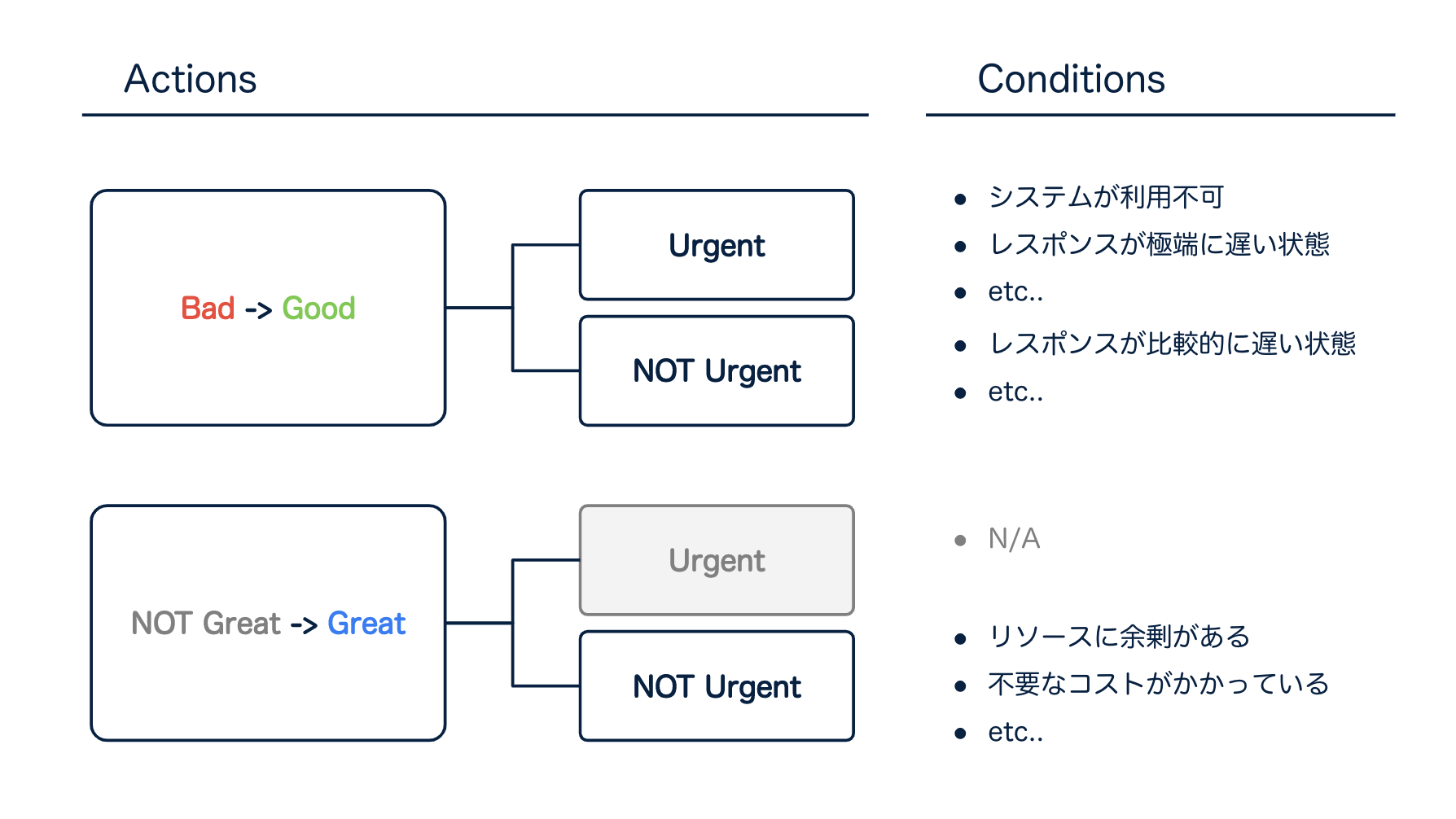
緊急度の高いアクション、例えば
- システムが利用不可
- レスポンスが極端に遅い状態
つまり、システムが正常でない状態の場合、
運用者は早急にアクションを打って、システムを正常な状態 しなくてはなりません。
そのために運用者は、監視のダッシュボードを一日中眺めていないといけないのでしょうか。
いえ、そんなことはしません。そのためにアラートがあるのです。
監視のあり方
ここで本題の監視のあり方について考えてみましょう。冒頭にも述べたように、CPU 90%超過 のイベントはアラートするべきでしょうか。
先述した通りアラートは不要であると考えます。ただ、もちろんデータ収集は行い、パフォーマンス分析には活かすべきです。
パフォーマンスに影響を与える可能性のある負荷の急変化やトレンドを確認できるので、OSのメトリクスは診断やパフォーマンス分析にとって重要です。しかし、99%の場合、これらのメトリクスは誰かを叩き起こすには値しません。OSのメトリクスをアラートに使う明確な理由がないなら、止めてしまいましょう。
(1.3.2 アラートに関しては、OSのメトリクスはあまり意味がない より)
また、アラートには2種類あります。
・誰かを叩き起こすためのアラート
緊急の対応が求められ、でなければシステムがダウンしてしまう (ダウンしたままになってしまう) ものです。電話、テキストメッセージ、アラームなどの方法で送られます。例えば、全Webサーバがダウンした、メインサイトへの疎通が取れないなどのケースです
・参考情報(FYI)としてのアラート
すぐに対応する必要はありませんが、アラートが来たことは誰かが確認すべきものです。例えば、夜間バックアップジョブが失敗したというケースです
これらを念頭に置きながら、
どのような監視をして そして、どのようなアクションを取るべきなのか をまとめます。
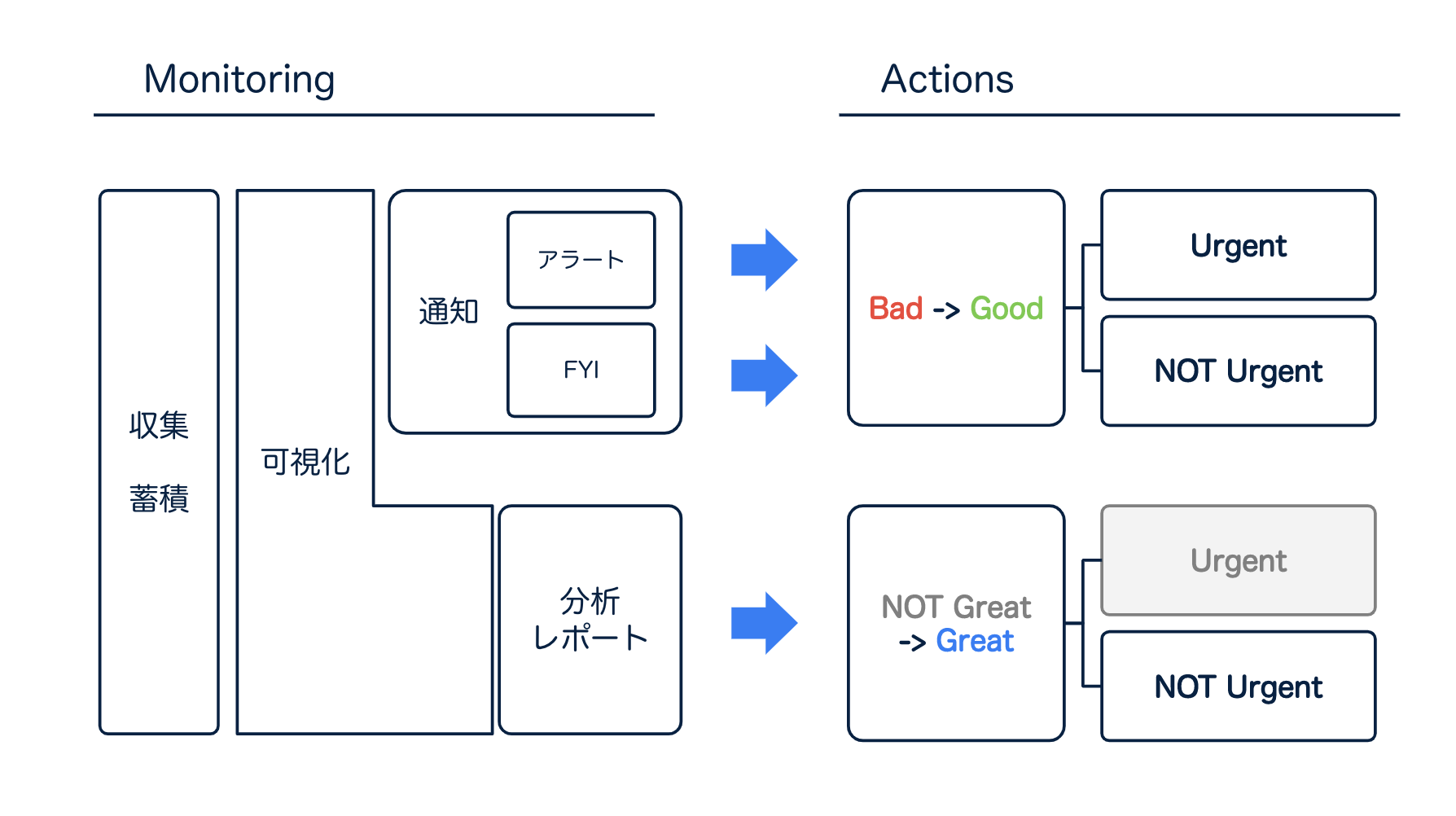
このようにすれば、アラートは本当に必要なときだけ、私達を叩き起こすようになるのではないでしょうか。
- サービスが正常に稼働していないとき、アラートが飛んでくる
- システムが良くない状態(Bad)のとき、FYIの通知が飛んでくる
- システムを最適化するための情報を分析し、レポートする
ここまで、入門監視を読んで私の考えをまとめてきました。入門監視の表現とは異なる部分も多々ありますが、今回自分の言葉で、改めて "監視" について考え直すことができました。
さいごに
次のステップは、"サービスが正常に稼働していない" 状態を定義することだと思います。これが結構難しいのではないかと思っています。
- キャッシュサーバがダウンして、クエリのキャッシュが機能しなくなっている、しかしユーザにはレスポンスを返せている、これは正常か?
- レスポンスが以前よりも増幅しているが、ユーザにとっては気になるものではない、 これは正常か?
- コンテナが起動後にすぐダウンして、自動復旧を繰り返している、しかしユーザは問題なくサービスを利用できている、これは正常か?
- CPU利用量に応じて、コンテナが有象無象にスケールアウトしている、これは正常か?
それぞれのシステムの要件によって、正常の定義は大きく異なるものになると思います。この要件を明確にした上で、"監視" を設定することが、難しいところでもあり、面白いところでもあるのかもしれません。