概要
前回、声優の出演数をグラフ化する遊びをやってみましたが、今回も同じ要領で週刊少年ジャンプにおける最も多く表紙を飾った/カラーを飾った作品が何だったのかをプログラミング言語であるRを使って調べてみたいなと思います。
結果だけ見たいマンは基本ルールをさーっと呼んでリンクから「表紙を飾った作品Best100」、「カラーを飾った作品Best100」を見てネ!
基本ルール
・文化庁メディア芸術データベースに登録されている情報からデータを抽出
・期間は1969/11/03~2017/07/31までを対象とする(以降は未登録であり、データの抽出ができないため)
・最も多く表紙を飾った作品、カラーを飾った作品のベスト100を突き止める
データクレンジングの難点(文字化け対策)
前回も苦しめられたこともあって今回は反省点を活かせればスムーズにいくかなー、と楽観していたのですが、実際にやってみてそんなことはありませんでした。
中でも特に文字化けが発生したときが苦しかったなと。
Rを使用する全てのプログラマーは文字化けという妖怪との果てしないバトルを繰り広げるのが日課だというのがぼくの認識なのですが、ほんとうにどうにかなりませんかね、この問題。
rvestパッケージを使用中でも文字化けが発生し、一時的にロケールを変更することで事なきを得ました。
実装ソースコード
では実装ソースコードを晒していきます。
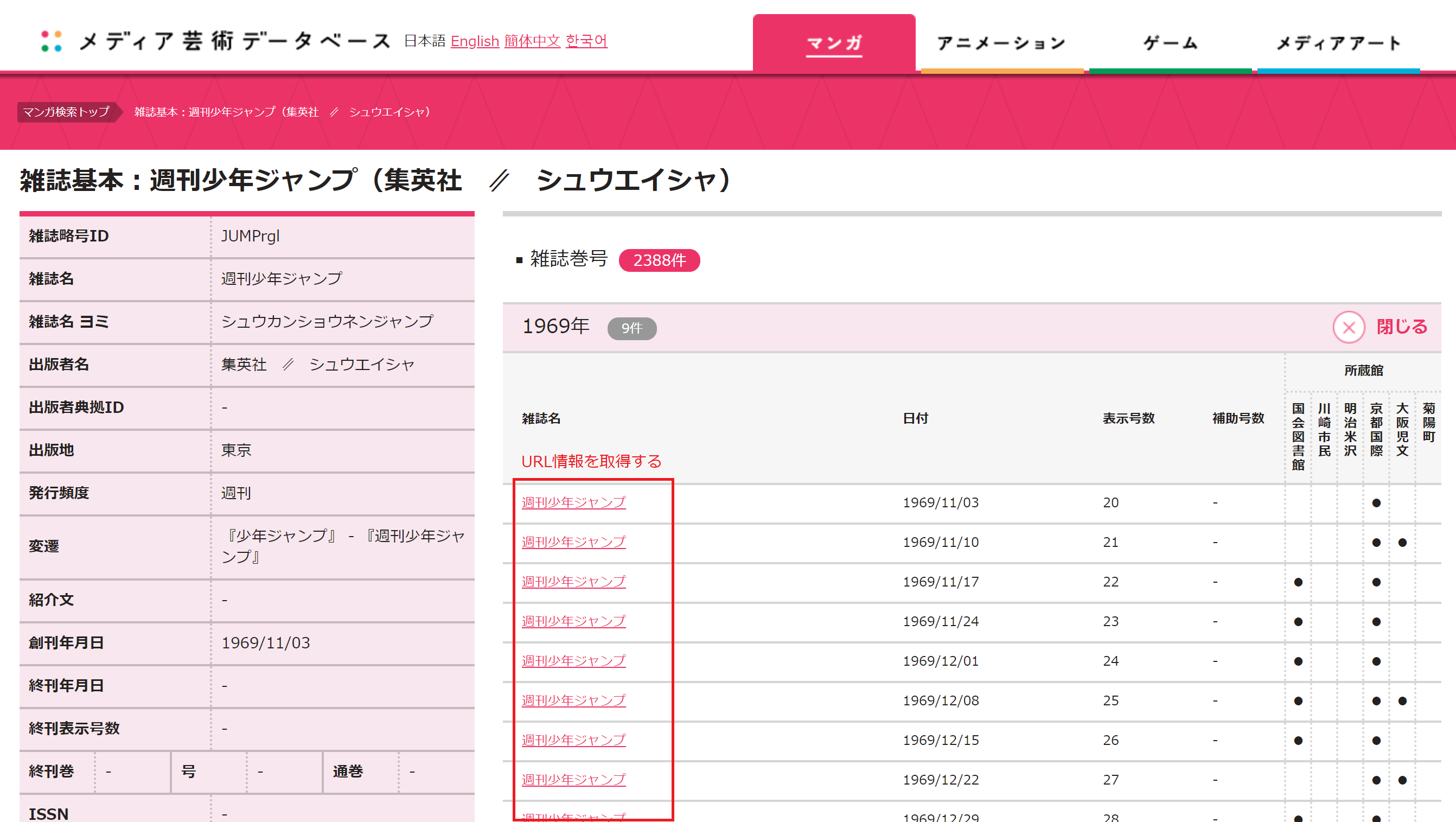
まずは少年ジャンプの詳細情報ページへ行きます。
各号ごとにリンクが貼られていますのでこのURL情報を取得します。
# ライブラリ -------------------------------------------------------------------
pacman::p_load(tidyverse,pipeR,rvest,DataExplorer)
# ソース本文 -------------------------------------------------------------------
# 各週刊少年ジャンプのURL情報を取得する
url_txt <- "https://mediaarts-db.bunka.go.jp/mg/magazine_titles/11470?display_view=pc&locale=ja"
data <- read_html(url_txt)
# 対象のURL情報を取得
url_path <-data %>>%
#aタグのノード情報を取得
html_nodes(xpath = "//a") %>>%
#属性を取得
html_attr("href") %>>%
#データフレーム化
as.data.frame() %>>%
#リンク先の情報だけ取得できるようフィルタする
filter(grepl("/mg/magazines/", .))
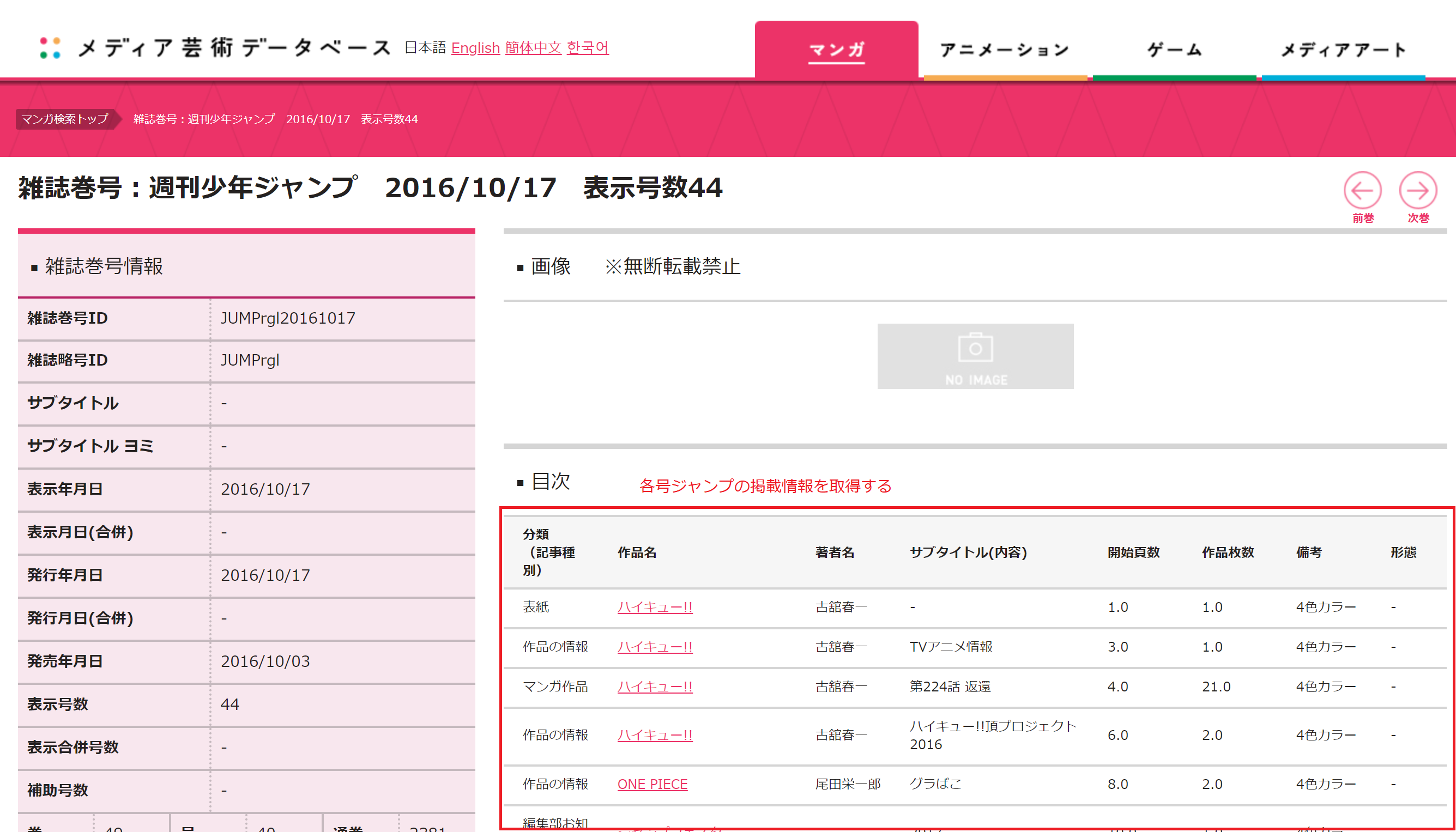
次に、各号ジャンプの詳細情報を取得していきます。
一部で取得したデータの文字化けが発生したため、ロケールを一時的に変更する対策を行います。
処理が終了した後はロケールを元に戻す処理を行っています。
# ジャンプのURLから各作品の掲載情報を取得する
df_jump <- data_frame()
for (i in 1:nrow(url_path)) {
url_txt2 <- paste0("https://mediaarts-db.bunka.go.jp",url_path$.[i])
#ロケールを変更しないとテーブル情報を正しく読み込めないため、一時的にロケールを変更する
if(i == 527){
Sys.setlocale("LC_ALL","C")
}
data2 <- read_html(url_txt2)
jump_data <- data2 %>>%
#ノード情報を取得
html_nodes(xpath = "//table[@class = 'infoTbl2']") %>>%
#テーブル情報を取得
html_table() %>>%
'[['(1)
#一時的に変更したロケールを元に戻す
if(i == 527){
Sys.setlocale("LC_ALL", '.932')
}
jump_title <- data2 %>>%
html_nodes(xpath = "//h1[@class='ttl']") %>>%
html_text(trim = FALSE)
jump_data <- jump_data %>>%
mutate(タイトル=jump_title)
jump_data$作品枚数 <- as.character(jump_data$作品枚数)
#ジャンプの掲載情報を行結合で集約していく
df_jump <- bind_rows(df_jump,jump_data)
}
データを取得した後は可視化のための仕上げを行った後に可視化します。
# 列名を変更
names(df_jump) <- c("category","title","author","sub_title","start_page","pages","remarks","form","number")
# 表紙を飾ったマンガ作品のみを抽出
df_top <- df_jump %>>%
#表紙のみ抽出
filter(grepl("表紙",category)) %>>%
#オールスター等は除きたいため、フィルタする
filter(!grepl("[表紙]",title))
# カラーで載ったマンガ作品のみを抽出
df_1st <- df_jump %>>%
#マンガ作品のみ抽出
filter(grepl("マンガ作品",category)) %>>%
#カラーのみ抽出
filter(grepl("4色カラー",remarks))
# 可視化
# 表紙を飾ったマンガのbest100
df_top <- table(df_top$title) %>>%
as.data.frame() %>>%
arrange(desc(Freq)) %>>%
head(100)
# カラーで載ったマンガのbest100
df_1st <- table(df_1st$title) %>>%
as.data.frame() %>>%
arrange(desc(Freq)) %>>%
head(100)
# グラフで可視化する
# ggplotで可視化(100件だと見づらいので50件に絞る)
ggplot(df_top %>>% head(50),mapping = aes(x=reorder(Var1, Freq),y=Freq)) +
geom_bar(stat = "identity") +
coord_flip()
ggplot(df_1st %>>% head(50),mapping = aes(x=reorder(Var1, Freq),y=Freq)) +
geom_bar(stat = "identity") +
coord_flip()
さて、どうなるでしょうか。
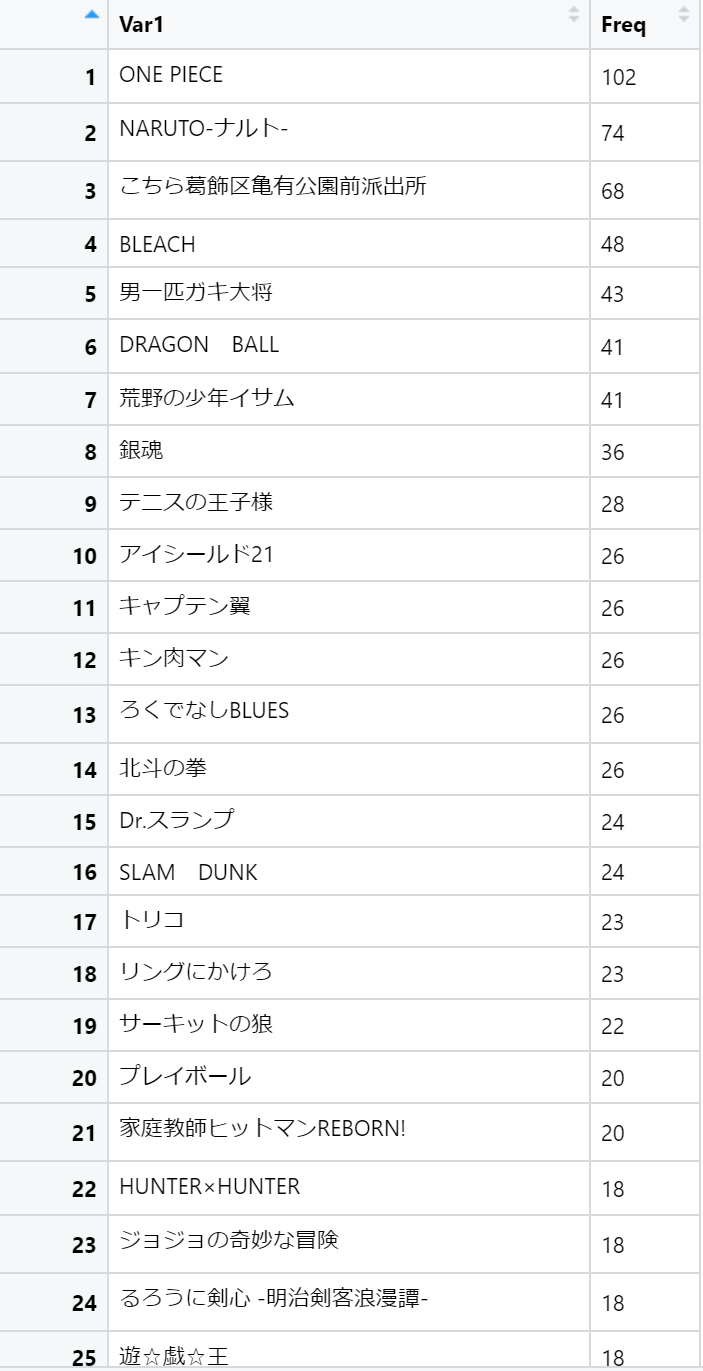
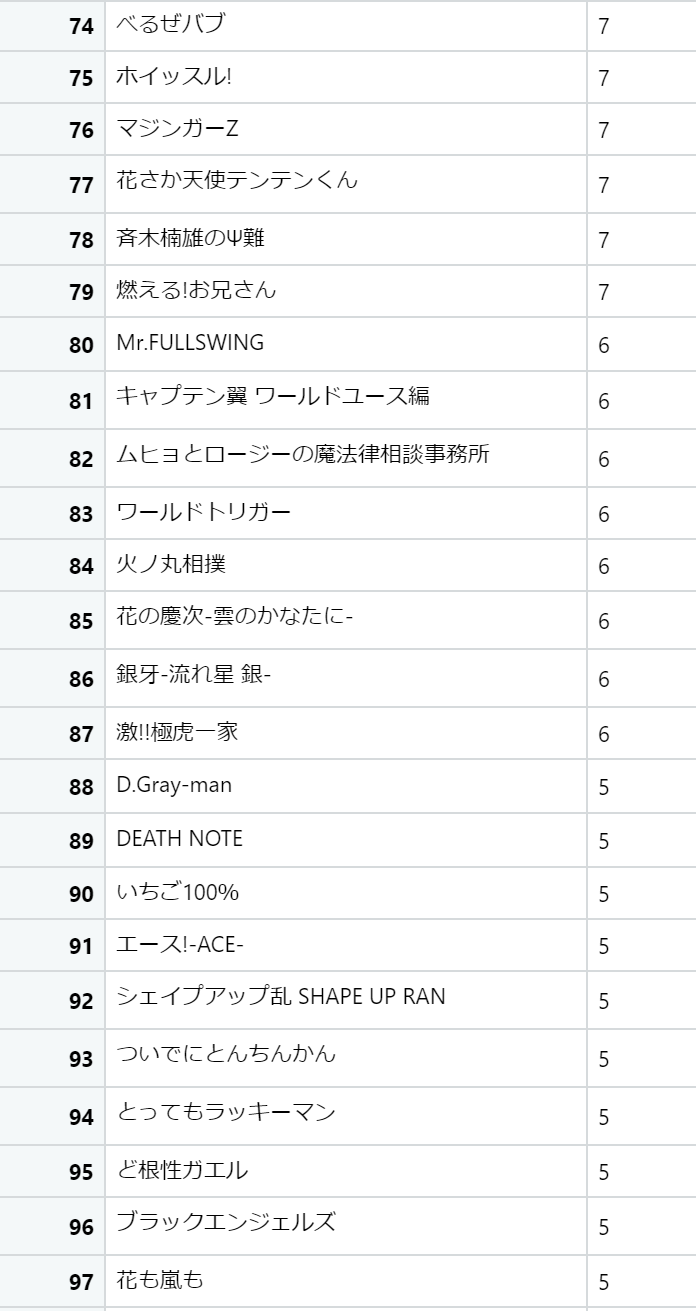
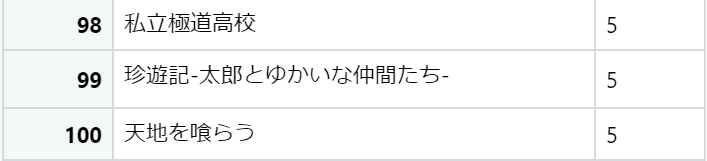
表紙を飾った作品Best100
では結果を発表していきましょう。
まずは表紙を飾った作品Best100です。じゃん!


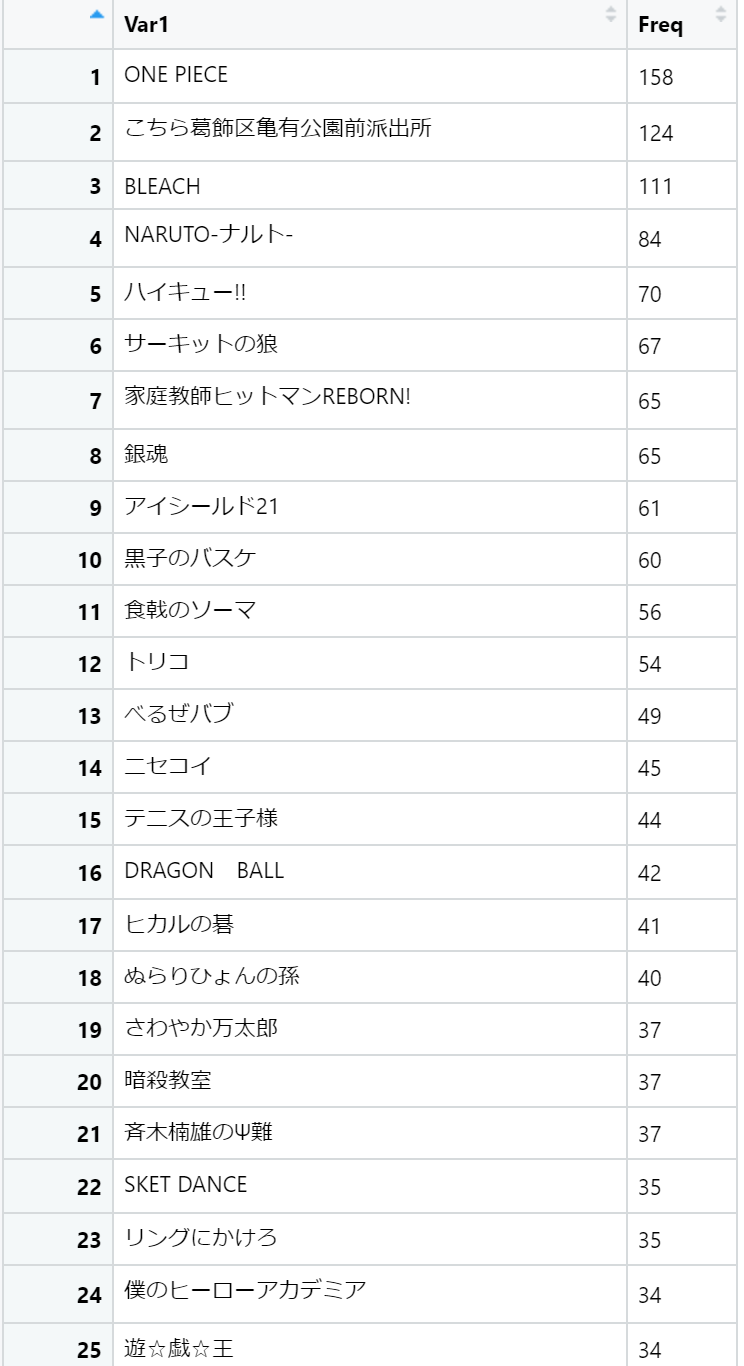
カラーを飾った作品Best100
続いてカラーを飾った作品Best100の紹介です。




グラフ化
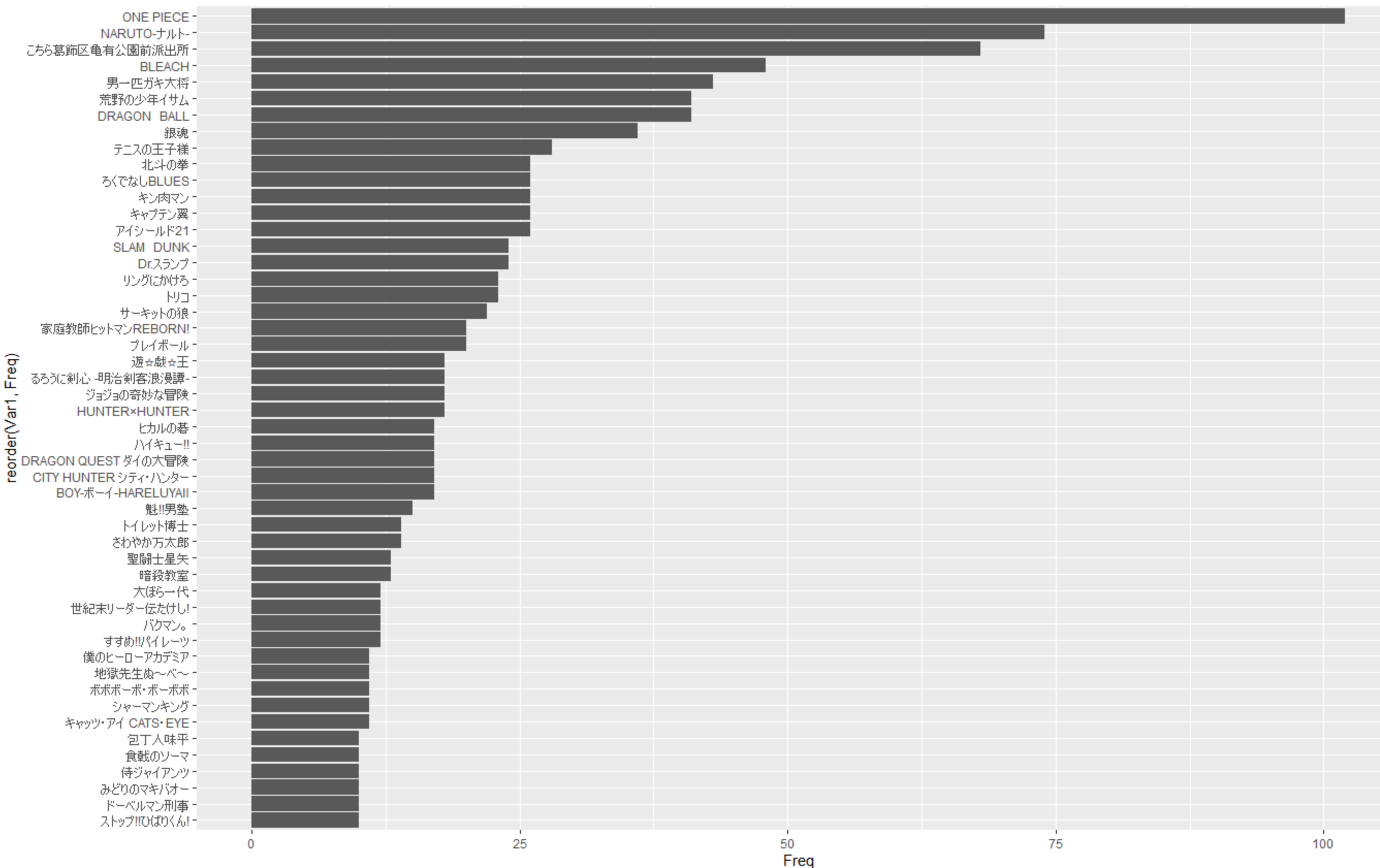
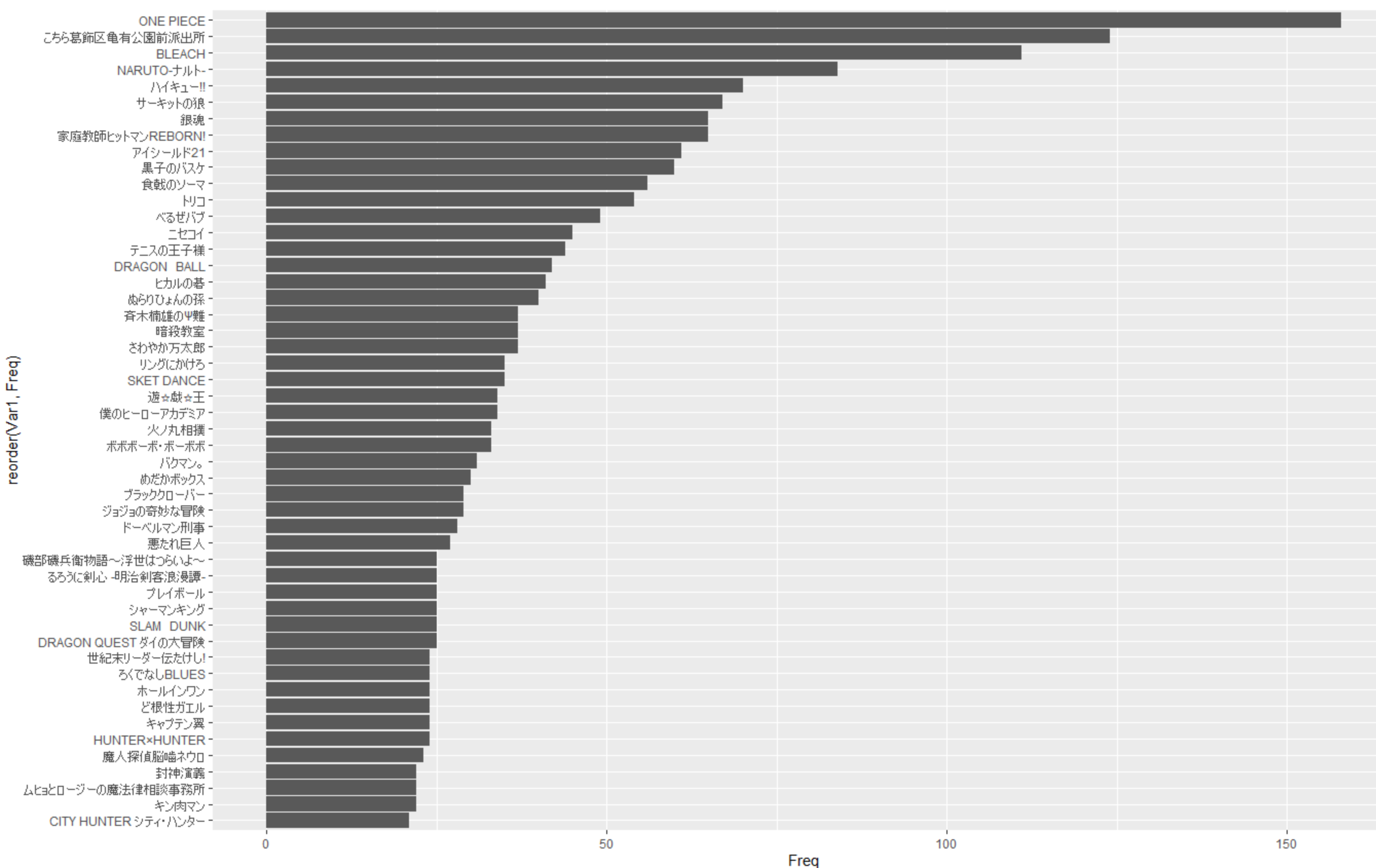
ついでにグラフ化した結果も見せちゃいます。
見づらいので上位50件まで表示しています。ご容赦ください…
表紙を飾った作品Best50
カラーを飾った作品Best50
好きな作品はランクインしていたでしょうか?
所感
rvest is 神!という感想はさておき、そもそもこのスクレイピングをやろうと思ったのは週刊少年ジャンプ30年分と同棲する剛の者がツイッターランドに降臨されたことでして、『ドラゴンボール』ってめちゃめちゃ面白かったんだけど、連載当時はどれぐらい人気あったんだろうなー、と思ったのがきっかけです。
ジャンプ30年分が家にあると、ちょっと嫌なことがあっても「家に帰ればドラゴンボール読めるしな」ってなるし仕事でむかつく人に会っても「そんな口きいていいのか?私は家でフリーザ戦とか読んでる身だぞ」ってなれる。戦闘力53万を求められる現代社会においてジャンプ30年分と同棲することは有効 pic.twitter.com/GAPRR5yOQg
— ペキンさん (@pekindaq) 2019年7月9日
というかもしかしてこれ重要文化財なんじゃねえのっていう気がするのはぼくだけではないはず。
話が逸れそうなので話を元に戻します。
『ワンピース』の圧倒的な強さは予想できていたことなので驚きはありませんが、『遊戯王』が地味に上位だったのは驚き。今でこそジャンプ読者は知らない人の方が少ないほど知名度の高い作品ですが、連載当時は最下位争いをしていた記憶があります。近年のマンガと太古の昔に連載されていたマンガの両方が入り乱れる形で結果に表れたのは中々に面白い結果だったと思います。
あと欲を言えば2017年8月以降の更新が途絶えているようなので、更新お願い…という切実な願いを残すとともに、〆とさせていただきます。