Speech Signal Processing Toolkit (SPTK)は、音声分析、音声合成、ベクトル量子化,データ処理などを行うことができるC言語のライブラリです。振動などの信号処理に使えないかと思い、試してみることにしました。
今回、SPTKを使って実現したい内容は下記の通りです。
- python経由で操作可能であること
- 解析に伴うデータの受け渡しをnumpy.ndarrayで行えること
- できればwindows上で利用可能なこと
pythonのモジュールとして、librosaという高機能な信号処理ツールや、pysptkという有志の方が公開してくださっているSPTKのラッパーもあるのですが、私が使いたいSPTKのコマンドに対応していないようだったので、止むを得ず取り組んだ次第です。
尚、わたくし信号処理の知識が皆無(プログラミングも怪しい)ですので、用語などの間違いがあるかもしれません。悪しからずご了承ください。
1. SPTKの導入
windowsの場合
下記HPを参考にさせて頂きました。
VisualStudio2019 x64 Native Toolsでビルドします。思っていたよりも手軽に導入できたのですが、私の環境では「pitch.exe」のビルドでコケるという問題が発生しました。
なので、bin/Makefile.makファイルの「pitch.exe」関係の記述を全部削除してからビルドするという強引な方法で回避しました・・・。
ubuntuの場合
下記HPを参考にさせて頂きました。
aptでも導入できるのですが、aptでインストールできるSPTKは一部のコマンドでオプションの機能に制限があるようでした(これは私の環境の問題かもしれません)。コマンド使用時に余計なことでハマってしまう可能性があるので、素直にソースファイルからビルドした方が良いと思います。
$ tar xvzf SPTK-3.11.tar.gz
$ cd SPTK-3.11
$ ./configure
$ make
$ sudo make install
1. SPTKの使い方
まずはSPTKの使い方について勉強しました。参考になる素晴らしいHPがあります。かなり詳細な解説をしてくださっており大変勉強になりました。ありがとうございます。
SPTKのコマンド操作
SPTKは基本的にコンソール経由でコマンドを使って操作するツールのようです。ここでは、SPTKのsinというコマンドでsin波のデータを作成し、sin.dataというファイル名で保存してみます。
コンソールを開いて下記コマンドを入力してください。周期16で長さが48(3周期分)のsin波のバイト列が、sin.dataというファイル名で保存されます。
$ sin -l 48 -p 16 > sin.data
ファイルの中身を確認するには、次のようにSPTKコマンドを入力します。
$ x2x +f < sin.data | dmp +f
以下のように結果が出力され、ファイルの中身を確認することができます。左側の数字はインデックス番号です。インデックス番号は表示用に自動的に追加されたもので、実際のデータファイルには(右側の)数値のみが格納されていることに留意してください。
0 0
1 0.382683
2 0.707107
3 0.92388
4 1
5 0.92388
…
なお、テキストデータも読み込むことができるようです。その場合は、数値をスペースでセパレートした(スペース・セパレート・バリュー?)テキストデータファイル(下記例ではsin.txt)を用意して、次のようなコマンドで読み込んでください。
$ x2x +af < sin.txt | dmp +f
テキストデータを読み込む場合は、オプションを+afのようにASCIIに対応したものにしないといけません。(このような基本的な仕様を把握していなたったので、思うような解析結果が出ず、半日ほど時間を無駄にすることになりました・・・)
pythonでのデータの読み込み
では、先ほど保存しておいたバイト列のデータsin.dataを、pythonで読み込んでみます。
import numpy as np
with open('sin.data', mode='rb') as f:
data = np.frombuffer(f.read(), dtype='float32')
print(data)
結果
[ 0.0000000e+00 3.8268343e-01 7.0710677e-01 9.2387950e-01
1.0000000e+00 9.2387950e-01 7.0710677e-01 3.8268343e-01
1.2246469e-16 -3.8268343e-01 -7.0710677e-01 -9.2387950e-01
-1.0000000e+00 -9.2387950e-01 -7.0710677e-01 -3.8268343e-01
-2.4492937e-16 3.8268343e-01 7.0710677e-01 9.2387950e-01
1.0000000e+00 9.2387950e-01 7.0710677e-01 3.8268343e-01
3.6739403e-16 -3.8268343e-01 -7.0710677e-01 -9.2387950e-01
-1.0000000e+00 -9.2387950e-01 -7.0710677e-01 -3.8268343e-01
-4.8985874e-16 3.8268343e-01 7.0710677e-01 9.2387950e-01
1.0000000e+00 9.2387950e-01 7.0710677e-01 3.8268343e-01
6.1232340e-16 -3.8268343e-01 -7.0710677e-01 -9.2387950e-01
-1.0000000e+00 -9.2387950e-01 -7.0710677e-01 -3.8268343e-01]
pythonでのデータの作成
次に、SPTKに渡すバイト列データをpythonで作成してみます。型を指定するところが結構大事です。(私はここでもハマりました)
arr = np.array(range(0,5)) # 適当に数列を作る
with open('test.data', mode='wb') as f:
arr = arr.astype(np.float32) # float32型にする
barr = bytearray(arr.tobytes()) # bytarrayにする
f.write(barr)
ファイルをSPTKで読み込んで確認します。
$ x2x +f < test.data | dmp +f
0 0
1 1
2 2
3 3
4 4
pythonとSPTKの連携
この要領でpythonで作成したnumpy.ndarrayをバイト列でファイルに保存し、そのファイルをコマンドを介して渡してやればSPTKでデータ処理できそうです。
試しにsin.dataを使ってちょっとやってみます。
import subprocess
# データを読み込み、窓関数をかけるコマンド
cmd = 'x2x +f < sin.data | window -l 16'
p = subprocess.check_output(cmd, shell = True)
out = np.frombuffer(p, dtype='float32')
print(out)
[-0.0000000e+00 3.0001572e-03 2.5496081e-02 8.6776853e-02
1.8433140e-01 2.7229854e-01 2.8093100e-01 1.7583697e-01
5.6270582e-17 -1.5203877e-01 -2.0840828e-01 -1.7030001e-01
-9.3926586e-02 -3.3312235e-02 -5.5435672e-03 2.4845590e-18
1.5901955e-33 3.0001572e-03 2.5496081e-02 8.6776853e-02
1.8433140e-01 2.7229854e-01 2.8093100e-01 1.7583697e-01
1.6881173e-16 -1.5203877e-01 -2.0840828e-01 -1.7030001e-01
-9.3926586e-02 -3.3312235e-02 -5.5435672e-03 2.4845590e-18
3.1803911e-33 3.0001572e-03 2.5496081e-02 8.6776853e-02
1.8433140e-01 2.7229854e-01 2.8093100e-01 1.7583697e-01
2.8135290e-16 -1.5203877e-01 -2.0840828e-01 -1.7030001e-01
-9.3926586e-02 -3.3312235e-02 -5.5435672e-03 2.4845590e-18]
より効率的なデータの受け渡し
SPTKにデータを渡すためだけにファイルを作成するなんて、なんとまぁ無駄な行為なんだろうと嘆いていたのですが、io.BytesIOなる便利なものがあるのですね。
最終的にはこんなものを用意しました。
import io
import shlex, subprocess
from typing import List
import numpy
def sptk_wrap(in_array : numpy.ndarray, sptk_cmd : str) -> numpy.ndarray:
'''
入力
in_array : 波形データ
sptk_cmd : sptkのコマンド(例 'window -l 16')
出力
解析後のデータ
'''
# numpy.ndarrayをbytearrayに変換
arr = in_array.astype(np.float32)
barr = bytearray(arr.tobytes())
bio = io.BytesIO(barr)
# sptkのコマンド
cmd = shlex.split(sptk_cmd)
proc = subprocess.Popen(cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE)
out, err = proc.communicate(input=bio.read())
return np.frombuffer(out, dtype='float32')
def sptk_wrap_pipe(in_array : numpy.ndarray, sptk_cmd_pipe : List[str]) -> numpy.ndarray:
'''
入力
in_array : 波形データ
sptk_cmd_pipe : sptkのコマンドをパイプしたい順にリストに格納したもの
(例)
cmd_list = [
'window -l 512 -L 512 -w 2',
'spec -l 512 -o 0',
]
出力
解析後のデータ
'''
out_array = numpy.copy(in_array)
for l in sptk_cmd_pipe:
out_array = sptk_wrap(out_array, l)
return out_array
# スペクトルの解析例
def ndarr2sp_ndarr(in_array : numpy.ndarray, length : int, wo : int = 2, oo : int = 0) -> numpy.ndarray:
'''
入力 : 波形データ
出力 : Logパワースペクトル
オプション:
wo : 窓関数のオプション(0:blackman 1:hammin 2:hanning 3:barlett)
oo : 出力するスペクトルの形態(0: 20 × log |Xk| )
sptkコマンド例
window -l 512 -L 512 -w 2 | spec -l 512 -o 0
'''
cmd_list = [
"window -l {0} -L {0} -w {1} ".format(length, wo),
"spec -l {0} -o {1}".format(length, oo),
]
return sptk_wrap_pipe(in_array, cmd_list)
2.使用例
適当な波形データを作成して実際に解析してみます。ここでは、作成するデータの周波数を変えながら、データ長さ512のサンプルを10セット作成しました。
import numpy as np
import matplotlib.pyplot as plt
N = 2**9 # 解析する波形のサンプル数 512
dt = 0.01 # サンプリング間隔
t = np.arange(0, N*dt, dt) # 時間軸
freq = np.linspace(0, 1.0/dt, N) # 周波数軸
samples = []
for f in range(1,11):
# 作成する波形の周波数を1~10に変えながら10セットの波形サンプルを作成
wave = np.sin(2*np.pi*f*t)
samples.append(wave)
samples = np.asarray(samples)
print(samples.shape)
出力:(10, 512)
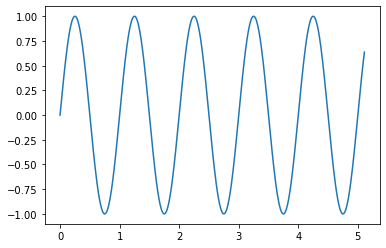
作成したデータをプロットするとこんな感じです。
1個目のデータ(周波数1Hz)
plt.plot(t, samples[0])
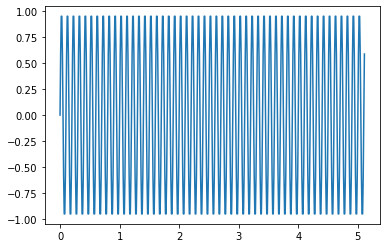
10個目のデータ(周波数10Hz)
plt.plot(t, samples[9])
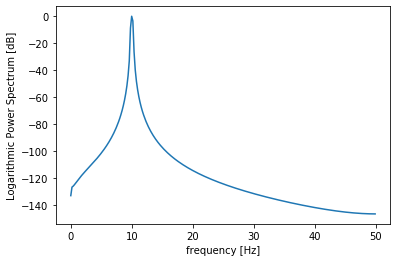
では、10個目のデータのスペクトルをSPTKを使って解析してみます。
ps = ndarr2sp_ndarr(samples[9], N)
plt.plot(freq[:N//2+1], ps)
plt.xlabel("frequency [Hz]")
plt.ylabel("Logarithmic Power Spectrum [dB]")
複数のデータをまとめて解析することもできます。ただし、結果がフラットに連結された状態で出力されるのでリシェイプが必要です。
まずはデータセットのshapeを確認しておく。
samples_shape = samples.shape
print(samples_shape)
出力:(10, 512)
10個まとめてSPTKで解析。
ps_s = ndarr2sp_ndarr(samples, N)
print(ps_s.shape)
出力:(2570,)
リシェイプする。
ps_s = ps_s.reshape((samples_shape[0],-1))
print(ps_s.shape)
出力:(10, 257)
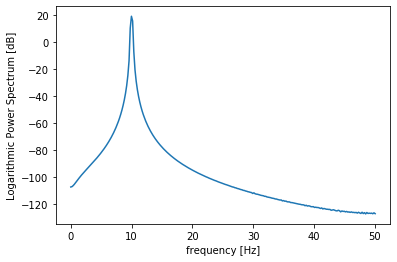
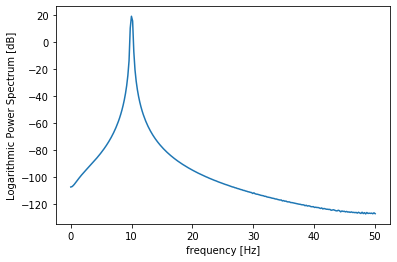
10個目のデータ(周波数10Hz)
print(np.max(ps_s[9]))
plt.plot(freq[:N//2+1], ps_s[9])
plt.xlabel("frequency [Hz]")
plt.ylabel("Logarithmic Power Spectrum [dB]")
出力:19.078928
3.補足
自分で解析した結果との比較を行ってみました。データ数で正規化したり窓関数の補正値を掛けたりしてみたのですが、SPTKで解析した結果と比較するとデシベル値が微妙にズレています。
理由が分からない・・・。何かアホなことをしている可能性が高いです。(どなたか詳しい方教えてください)
wavedata = samples[9]
# ハニング窓をかける
hanningWindow = np.hanning(len(wavedata))
wavedata = wavedata * hanningWindow
# 補正係数を計算しておく
acf = 1/(sum(hanningWindow)/len(wavedata))
# フーリエ変換(周波数信号に変換)
F = np.fft.fft(wavedata)
# 正規化 + 交流成分2倍
F = 2*(F/N)
F[0] = F[0]/2
# 振幅スペクトル
Adft = np.abs(F)
# 窓関数を掛けた際の補正係数をかける
Adft = acf * Adft
# パワースペクトル
Pdft = Adft ** 2
# 対数パワースペクトル
PdftLog = 10 * np.log10(Pdft)
# PdftLog = 10 * np.log(Pdft)
print(np.max(PdftLog))
start=0
stop=int(N/2)
plt.plot(freq[start:stop], PdftLog[start:stop])
plt.xlabel("frequency [Hz]")
plt.ylabel("Logarithmic Power Spectrum [dB]")
plt.show()
出力:-0.2237693