趣旨
Ubuntu 22.04環境でコンテナ版Lettaを動かすことに成功したので、備忘録として手順や注意点を記載します。
前提条件
本記事は以下の環境および前提を想定しています。
- OS: Ubuntu 22.04
- Ollama: 既にインストール済み
- LLM: Ollamaに任意のLLMをpull済み
- Docker: 使用可能な状態
必要に応じてこれらの環境を事前に構築してください。
導入と起動
Lettaの公式ドキュメントは以下の2つが参考になりますが、非常に分かりづらいため、結論だけをまとめました。
以下のコマンドを実行してください。
docker run \
-v /[ローカルホスト側の任意のパス]/letta:/var/lib/postgresql/data \
-p 8283:8283 \
-e OLLAMA_BASE_URL=http://[自ホストのIPアドレス]:11434 \
letta/letta:latest
ポイント
-
OLLAMA_BASE_URLの設定
- ベースURLは
localhostや127.0.0.1ではなく、自ホストのIPアドレス(例:192.168.1.10)を指定してください。 - Lettaはコンテナ内で動作しているため、
localhostや127.0.0.1を指定すると、コンテナ内部の自分自身を参照してしまいます。
- ベースURLは
-
UFWの設定
- Ubuntuのファイアウォール(UFW)でポート
11434への接続を許可する必要があります。Dockerコンテナはデフォルトでdocker0インターフェースを使用して通信します。この通信はUbuntuホストから見ると「外部からの通信」として扱われるため、UFWでブロックされ、見かけ上は原因不明のトラブルになります(letta側がエラーとか出さずに無言で疎通に失敗するため、そもそもOllamaと通信できてない、ということすら中々気づけない)
- Ubuntuのファイアウォール(UFW)でポート
上記の設定により、http://localhost:8283でLettaの画面を開き、またエージェント作成画面でOllama上にpull済みの各種LLMを参照することができます。
現状の制約と問題点
日本語テキストのEmbeddingが機能しない
2024年12月20日時点のコンテナ版Lettaでは(もしかするとpip版も)日本語テキストのEmbeddingに問題があり、かつデータソースの作成にも不具合が生じています。
データソースの作成
以下のようにcurlを使用してAPIを直接叩くことでデータソースを作成可能です。
GUI上にあるデータソース作成ボタンは実行してもエラーになって何も作成できません。
curl --request POST \
--url http://localhost:8283/v1/sources/ \
--header 'Content-Type: application/json' \
--data '{
"name": "test-datasource",
"embedding_config": {
"embedding_endpoint_type": "ollama",
"embedding_endpoint": "http://[自ホストのIPアドレス]:11434",
"embedding_model": "nomic-embed-text:latest",
"embedding_dim": 768,
"embedding_chunk_size": 300
},
"description": "test",
"metadata_": {}
}'
参考: https://docs.letta.com/api-reference/sources/create-source
データソースへのファイルアップロード
作成したデータソースに対してはGUI上でファイルをアップロードすることができます。
しかし、50MB規模の英語PDFの処理に失敗するケースがありました。これは以下に起因しているのかもしれないし、していないのかもしれません。
- 使用しているEmbeddingモデルの限界
- GPUやPCの性能不足
(ただし、VRAMにEmbeddingモデルをロードしようとする挙動すら見られないため、個人的には別のところに原因があるような気がします)
データソースを活用した質疑応答
現状、データソース内の文章を参照した質疑応答は機能していません。
問題の原因の推測
以下の要因が関連していると考えられます。
- プロンプトが日本語である
- データソース内のテキストも日本語である
- 内部のRAG検索用プロンプトが英語で記述されている
まあこの辺が原因なのかは定かではないものの、うまく知識を検索できていない以上、letta本来の売りである「過去の会話履歴を記憶として保持&想起する機能」が日本語環境では正常に動作しない可能性があります。
終わりに
lettaの売りである「擬似的に無制限のコンテキスト長を実現」「ファイルアップロードも可能なのでこれまた擬似的に無制限のデータサイズでのRAGを実現」といったコンセプトに夢を見たものの、見事に夢破れました。
ただまあ、結局lettaがデータソースとして登録したファイルの扱いは、単純なRAGに過ぎなかったので仮に動作したとしても「長大なテキストを苦もなく把握!」みたいな挙動にはならなそうな気がします。将来に期待、といったところでしょうか。
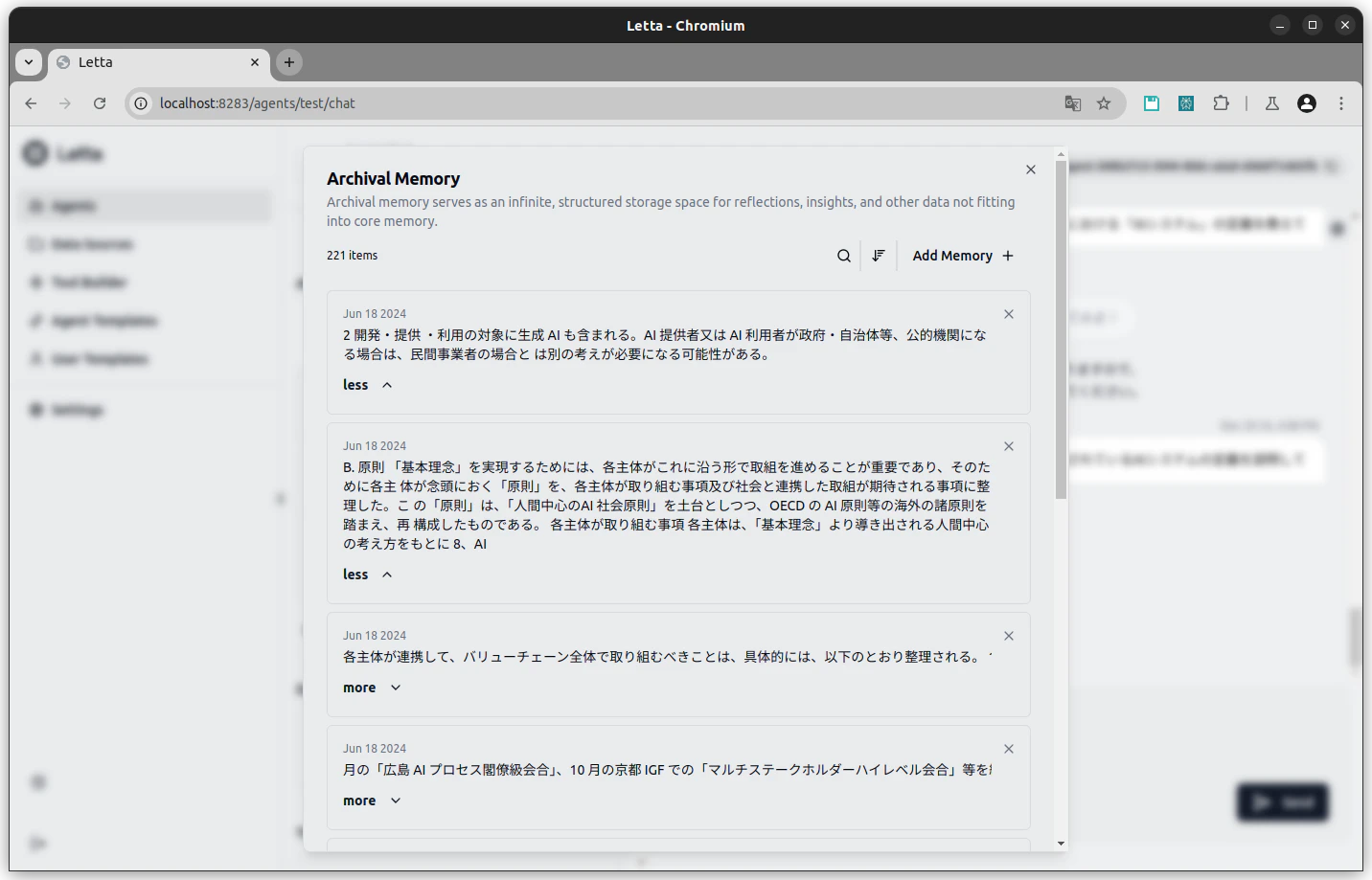
※データソースにPDF文書を登録し、エージェント側に接続してからArchived Memoryの項目で中身を表示してみた様子。
いかにも単純にベクトルDBにチャンク化した細切れのテキストを格納した様子が見て取れる。