要旨
- Elasticsearchに「インデックス」を作成する
- 単純にPDFファイルを「インデックス化」する
- PDFファイルの埋め込みデータを作成しながら「インデックス化」する
-
インデックス
RDBMSで言うところの「テーブル定義」「列定義」に近い概念
elasticsearchの「インデックス」は、特定の種類のドキュメントを格納する「論理的な場所」のこと
ドキュメントの「構造」や「マッピング」(RDBMSでのスキーマに相当)を定義する
…らしい -
インデックス化
elasticsearchにデータをアップロードするようなもの
elasticsearchはユーザーが投入した内容を解析し、検索可能な形式で保存する
今回のようにPDF文書をアップロードする場合、以下のような処理仮定になる…らしい
- PDFを解析してテキストデータを抽出。
- 抽出したデータをElasticsearchのドキュメントとしてインデックスに登録。
1. インデックス作成
とりあえず最も単純な方法として、curlコマンドでのインデックス作成を試みる。
以下はknowledge_baseインデックスを作成する例。
curl --cacert /elasticsearchコンテナから取り出したca.crtの格納先パス/ca.crt \
-u elastic:[ユーザー「elastic」のパスワード] \
-X PUT "https://localhost:9200/knowledge_base" \
-H 'Content-Type: application/json' \
-d '{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "kuromoji"
},
"content": {
"type": "text",
"analyzer": "kuromoji"
},
"embedding": {
"type": "dense_vector",
"dims": 768
}
}
}
}'
ポイント
- ElasticsearchがSSL証明書を使用している場合、
--cacertオプションでCA証明書を指定する必要がある。docker composeで構築されたelasticsearchクラスタの場合はCA証明書でのhttps通信を行う設計担っている。 - 認証情報(
-u elastic:password)を忘れずに指定する。
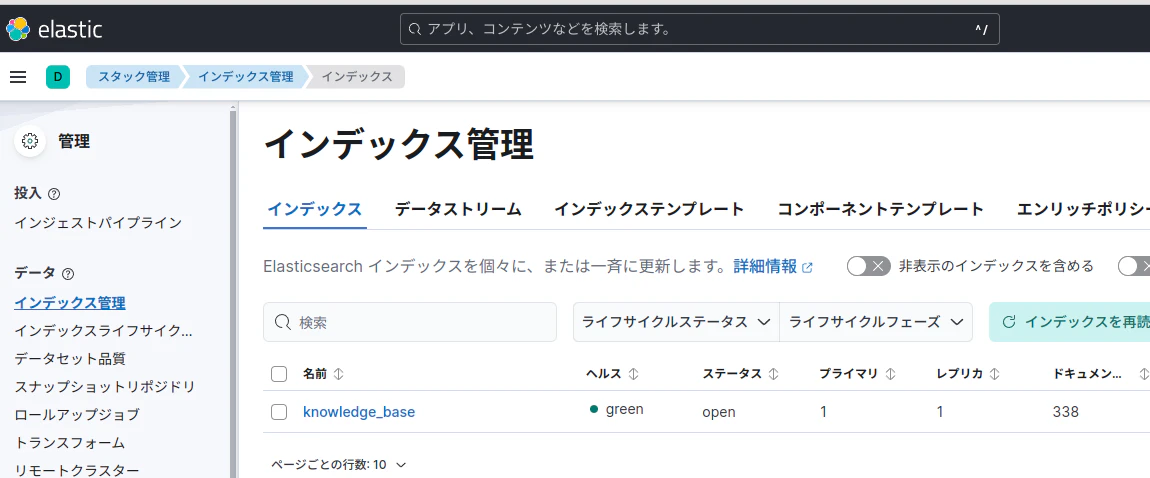
2. 作成したインデックスを確認
インデックス作成後は、Kibanaの管理画面を使用してインデックスが正しく作成されているか確認する。
- Kibanaにログインする。
- 「Stack Management」 > 「Index Management」に移動。
- 作成したインデックス(例:
knowledge_base)がリストに表示されることを確認する。
できたっぽい。
3. PDF文書を単純にインデックス化
- PDF文書を単純にアップロードしてインデックス化する
- そのための「パイプライン」を作成する
パイプライン作成
curl --cacert /elasticsearchコンテナから取り出したca.crtの格納先パス/ca.crt \
-u elastic:[ユーザー「elastic」のパスワード] \
-X PUT "https://localhost:9200/_ingest/pipeline/attachment" \
-H 'Content-Type: application/json' \
-d '{
"description": "Extract attachment information",
"processors": [
{
"attachment": {
"field": "data",
"target_field": "attachment",
"indexed_chars": -1
}
}
]
}'
- PDF文書はelasticsearch的には「非構造データ(PDF、画像、XMLなど)」なので、インデックス化する際はファイル内のテキストやメタデータを抽出し、それを検索可能なJSON形式に変換する必要がある。PDFの場合、専用の「ingest-attachmentプラグイン」が用意されているので、PDF文書の登録時にはこのプラグインを使うべし、と指示するために上記pipelineを作成している
PDFのアップロード
base64 /path/to/test.pdf > test.pdf.base64
curl --cacert /elasticsearchコンテナから取り出したca.crtの格納先パス/ca.crt \
-u elastic:[ユーザー「elastic」のパスワード] \
-X PUT "https://localhost:9200/knowledge_base/_doc/1?pipeline=attachment" \
-H 'Content-Type: application/json' \
-d '{
"data": "'$(cat test.pdf.base64 | tr -d '\n')'",
"title": "Test PDF Document"
}'
注意点
-
dataフィールドにBase64エンコードしたデータを渡す際、改行文字を削除する必要がある。 - この手順では埋め込み(embedding)データは生成されない。単純にPDF文書の内容を対象のインデックス(今回の場合はインデックス「knoledge_base」)に登録するのみ
4. 埋め込み処理付きでPDFをインデックス化する
埋め込みデータを作成するには、Pythonコードを使用する必要がある。
Pythonコードでの処理
以下は、PDFファイルを読み込んで埋め込みデータを生成し、チャンク化したテキストと埋め込みデータをElasticsearchに(と言うかそこに作成したインデックスknowledge_baseに登録するコード。
import os
import json
import base64
import requests
from PyPDF2 import PdfReader
from sentence_transformers import SentenceTransformer
# 設定
pdf_path = '/[PDF文書の格納先パス]/test2.pdf'
index_name = 'knowledge_base'
es_host = 'https://localhost:9200'
es_user = 'elastic'
es_password = '[ユーザー「elastic」のパスワード]'
ca_cert_path = '/elasticsearchコンテナから取り出したca.crtの格納先パス/ca.crt'
# Elasticsearchへの認証情報
auth = (es_user, es_password)
# SSL証明書の検証設定
verify = ca_cert_path
# PDFからテキストを抽出する関数
def extract_text_from_pdf(pdf_path):
reader = PdfReader(pdf_path)
text = ''
for page in reader.pages:
text += page.extract_text()
return text
# テキストを指定した長さでチャンクに分割する関数
def chunk_text(text, max_length=512):
words = text.split()
chunks = []
current_chunk = []
current_length = 0
for word in words:
if current_length + len(word) + 1 > max_length:
chunks.append(' '.join(current_chunk))
current_chunk = []
current_length = 0
current_chunk.append(word)
current_length += len(word) + 1
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
# Elasticsearchにドキュメントをインデックスする関数
def index_document(doc_id, title, content, embedding):
document = {
'title': title,
'content': content,
'embedding': embedding
}
response = requests.put(
f'{es_host}/{index_name}/_doc/{doc_id}',
auth=auth,
headers={'Content-Type': 'application/json'},
data=json.dumps(document),
verify=verify
)
if response.status_code not in [200, 201]:
print(f'Error indexing document {doc_id}: {response.text}')
else:
print(f'Document {doc_id} indexed successfully.')
# メイン処理
def main():
# PDFからテキストを抽出
text = extract_text_from_pdf(pdf_path)
print('PDFからテキストを抽出しました。')
# テキストをチャンクに分割
chunks = chunk_text(text)
print(f'{len(chunks)}個のチャンクに分割しました。')
# 埋め込みモデルのロード
model = SentenceTransformer('pkshatech/RoSEtta-base-ja', trust_remote_code=True)
print('埋め込みモデルをロードしました。')
# 各チャンクをベクトル化してElasticsearchにインデックス
for i, chunk in enumerate(chunks):
embedding = model.encode(chunk).tolist()
index_document(doc_id=i+1, title=f'チャンク {i+1}', content=chunk, embedding=embedding)
if __name__ == '__main__':
main()
注意点
- 埋め込みモデルのダウンロード先は、環境変数
HF_HOMEで指定可能。デフォルトだとスクリプトを実行したユーザーのホームディレクトリ配下に保存されてしまうので、/homeの容量が少ない場合は事前にHF_HOMEを指定して保存先を明示的に指定しておくこと
5. 文書を登録できたかどうか確認
kibanaの管理画面の左上のハンバーガーアイコン?(三みたいなやつ)を開くと見える「Discovery」メニューを選択。
画面なりに進んで適当に「データビュー」を作成し、「フィールド統計情報」を見てみる
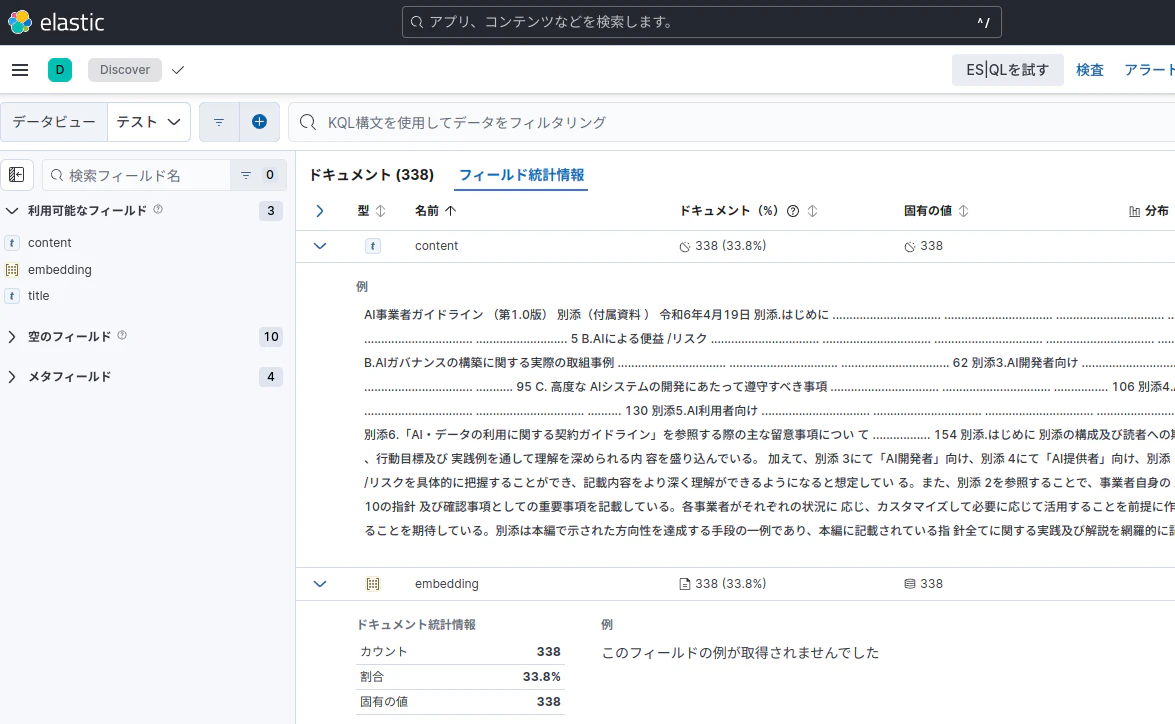
登録できたっぽい
次回は登録したデータの検索をやってみる。
以上