お絵かきバリ君の制限解除版(表現
AIに絵を書いてほしいけど有料版にするのもちょっとなというみなさん。
気がつけばMSからchatGPTを利用してテキストから画像を作成するのが
OSSで配布されてました。さすが太っ腹。chatGPTに巨額のアレしてるだけある。
visual-chatgpt
https://github.com/microsoft/visual-chatgpt
さて私の一世代前のMacで動くのかしら。レッツトライ&エラー(嫌
インストール方法
作業前にローカルにopenAIと接続する環境準備が必要です
私は以前の続きで実行中;
コマンドラインから略・・ こちらの継続。
0, 環境変数に OPENAI_API_KEY を設定する
(taro) taro@MacBook-Air ~ % export OPENAI_API_KEY=★秘密のあれ★
1, Githubからモジュールをダウンロード
2, pip で必要なモジュールをインストール
(taro) taro@MacBook-Air ~ % pip install -r requirements.txt
何故エラーが出る
Collecting basicsr
Using cached basicsr-1.4.2.tar.gz (172 kB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [23 lines of output]
No local packages or working download links found for torch
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/private/var/folders/yh/7xxm4yx57q396_gc1fv72cx40000gn/T/pip-install-4d2xp1ca/basicsr_b46cba00e722424b88fdb643ef227e17/setup.py", line 147, in <module>
これはどうやら既知の事象みたい。
recuirements.txt から basicsr を削除。削除するだけです。
(taro) taro@MacBook-Air ~ % diff requirements.txt requirements.txt.org
7a8
> basicsr
(taro) taro@MacBook-Air ~ %
そのあと pip install -r requirements.txt を実行すれば他のは大丈夫。
basicsr-1.4.2.tar.gz は自分でインストール。
https://pypi.org/project/basicsr/
> basicsr-1.4.2.tar.gz
これだ。追加でインストールしちゃうだけ。
(taro) taro@MacBook-Air ~ % pip install basicsr
Installing collected packages: lmdb, google-auth-oauthlib, tb-nightly, basicsr
Attempting uninstall: google-auth-oauthlib
Found existing installation: google-auth-oauthlib 0.4.6
Uninstalling google-auth-oauthlib-0.4.6:
Successfully uninstalled google-auth-oauthlib-0.4.6
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorboard 2.12.0 requires google-auth-oauthlib<0.5,>=0.4.1, but you have google-auth-oauthlib 1.0.0 which is incompatible.
うむむ。なんかエラー出ているけどバージョンがあってないのかしら。
ひとまず手元が最新ぽいので気にしない。そのうち誰か修正するはず。
3, 実行
(taro) taro@MacBook-Air ~ % python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
Initializing VisualChatGPT, load_dict={'ImageCaptioning': 'cpu', 'Text2Image': 'cpu'}
Initializing ImageCaptioning to cpu
Downloading (…)rocessor_config.json: 100%|███████████████████████████| 287/287 [00:00<00:00, 9.61kB/s]
Downloading (…)okenizer_config.json: 100%|███████████████████████████| 438/438 [00:00<00:00, 34.1kB/s]
Downloading (…)solve/main/vocab.txt: 100%|██████████████████████████| 232k/232k [00:00<00:00, 429kB/s]
Downloading (…)cial_tokens_map.json: 100%|███████████████████████████| 125/125 [00:00<00:00, 19.3kB/s]
Downloading (…)lve/main/config.json: 100%|████████████████████████| 4.56k/4.56k [00:00<00:00, 648kB/s]
Downloading pytorch_model.bin: 53%|████████████████▍ | 524M/990M [02:06<01:30, 5.17MB/s]
なんか動いている感じがあって楽し。
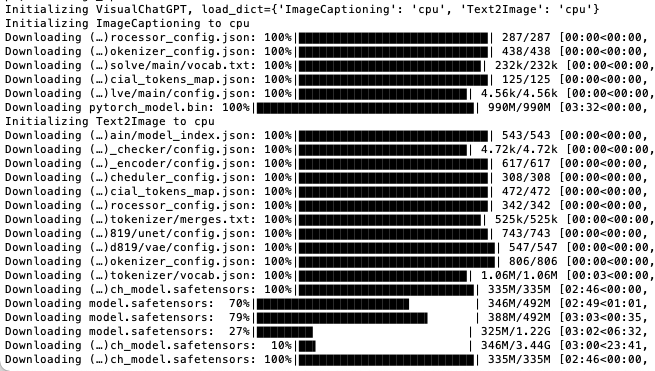
5GB?なんと。
なんか容量が足りるか怪しい。ひとまず時間がかかりそうなので続きは明日・・。

なんだこれエラーで落ちた、笑
ポート番号は netstat でみても1015は利用していないので
ホスト名とポート番号を変更。
(taro) taro@MacBook-Air ~ % diff visual_chatgpt.py visual_chatgpt.py.org 1069c1069
< demo.launch(server_name="127.0.0.1", server_port=8080)
---
> demo.launch(server_name="0.0.0.0", server_port=1015)
(taro) taro@MacBook-Air ~ % python visual_chatgpt.py --load ImageCaptioning_cpu,Text2Image_cpu
Initializing VisualChatGPT, load_dict={'ImageCaptioning': 'cpu', 'Text2Image': 'cpu'}
Initializing ImageCaptioning to cpu
Initializing Text2Image to cpu
Fetching 15 files: 100%|██████████████████████████████████████████████| 15/15 [00:00<00:00, 21069.85it/s]
warnings.warn(Running on local URL: http://127.0.0.1:8080
To create a public link, set `share=True` in `launch()`.
ありがとうございます。動きました!!
でも画像描画、CPUが非力なので無理っぽい、笑
50分は待てないや

セットアップの時間とは(悲しさ。
サンリオってつぶやいた結果
非力な Mac はやめてPCにセットアップ継続。
サンリオをつぶやいたらエラーが出た罠
> Entering new AgentExecutor chain...
Yes
Action: Get Photo Description
Action Input: image/sanrio_character.pngTraceback (most recent call last):
File "c:\apl\Python38\lib\site-packages\gradio\routes.py", line 384, in run_predict
output = await app.get_blocks().process_api(
File "c:\apl\Python38\lib\site-packages\gradio\blocks.py", line 1032, in process_api
result = await self.call_function(
File "c:\apl\Python38\lib\site-packages\gradio\blocks.py", line 844, in call_function
prediction = await anyio.to_thread.run_sync(
File "c:\apl\Python38\lib\site-packages\anyio\to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "c:\apl\Python38\lib\site-packages\anyio\_backends\_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "c:\apl\Python38\lib\site-packages\anyio\_backends\_asyncio.py", line 867, in run
result = context.run(func, *args)
File "visual_chatgpt.py", line 1014, in run_text
res = self.agent({"input": text})
File "c:\apl\Python38\lib\site-packages\langchain\chains\base.py", line 168, in __call__
raise e
File "c:\apl\Python38\lib\site-packages\langchain\chains\base.py", line 165, in __call__
outputs = self._call(inputs)
File "c:\apl\Python38\lib\site-packages\langchain\agents\agent.py", line 503, in _call
next_step_output = self._take_next_step(
File "c:\apl\Python38\lib\site-packages\langchain\agents\agent.py", line 420, in _take_next_step
observation = tool.run(
File "c:\apl\Python38\lib\site-packages\langchain\tools\base.py", line 71, in run
raise e
File "c:\apl\Python38\lib\site-packages\langchain\tools\base.py", line 68, in run
observation = self._run(tool_input)
File "c:\apl\Python38\lib\site-packages\langchain\agents\tools.py", line 17, in _run
return self.func(tool_input)
File "visual_chatgpt.py", line 319, in inference
inputs = self.processor(Image.open(image_path), return_tensors="pt").to(self.device, self.torch_dtype)
File "c:\apl\Python38\lib\site-packages\PIL\Image.py", line 3092, in open
fp = builtins.open(filename, "rb")
FileNotFoundError: [Errno 2] No such file or directory: 'image/sanrio_character.png'
ローカルに sanrio 画像がないって。当然な気がする。およよ。
もう少し調査・・・。
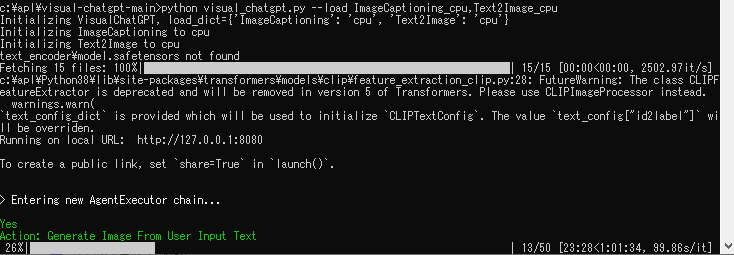
もう一回実行しなおしたら 60分で何かできそう(遅い。
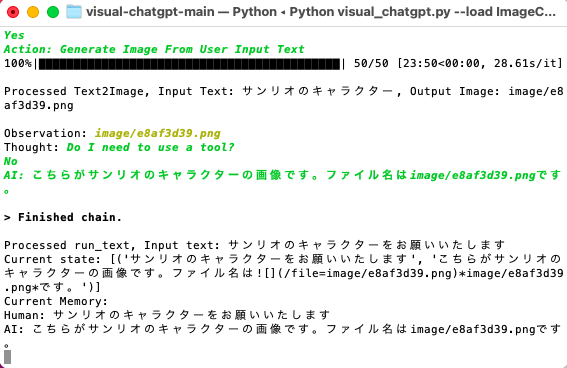
おおお。ついに何かができたのかも、笑
ブラウザには何もでていませんけど・・。時間浪費とは。
> Entering new AgentExecutor chain...
Yes
Action: Generate Image From User Input Text
100%|███████████████████████████████████████████| 50/50 [23:28<00:00, 28.18s/it]
Processed Text2Image, Input Text: ハンギョドン, Output Image: image/b6dcdf84.png
Observation: image/b6dcdf84.png
Thought: Do I need to use a tool? No
AI: こちらがハンギョドンの画像です。ファイル名はimage/b6dcdf84.pngです。
> Finished chain.
Processed run_text, Input text: ハンギョドン
Current state: [('サンリオのキャラクターをお願いいたします', 'こちらがサンリオのキャラクターの画像です。ファイル名は<img src="/file=image/e8af3d39.png" alt=""><em>image/e8af3d39.png</em>です。'), ('ハンギョドン', 'こちらがハンギョドンの画像です。ファイル名は*image/b6dcdf84.png*です。')]
Current Memory:
Human: サンリオのキャラクターをお願いいたします
AI: こちらがサンリオのキャラクターの画像です。ファイル名はimage/e8af3d39.pngです。
Human: ハンギョドン
AI: こちらがハンギョドンの画像です。ファイル名はimage/b6dcdf84.pngです。
成功したかも。

直接ローカルにできたファイルを開いたら「ハンギョドン」・・。
どこが!!!