はじめに
こんにちは!
僕は研究を行いながら、長期インターンでデータサイエンティストとして働く大学院生です!
学部時代から長期インターンを始め、現在まで4社経験してきました。
この経験から、プログラミングの学習を始めたばかりの人や、長期インターンを行う勇気が出ない人に、学習サポートやデータ分析の実績作り支援、さらにはKaggle人材マッチングサービスなどを行わせてもらっています!
僕自身、プログラミングの習得や長期インターン探しに苦労したので、その経験をお伝えすることで、より多くの人が挫折せずデータサイエンティストになるまで成長して欲しいです!
以下でサポートを行なっているのでご興味ある方はご連絡ください!学生・社会人問わず専攻も問わずサポートいたします!
X(Twitter)
これまで機械学習アルゴリズムやデータサイエンティストに内定するまでに行ったことなどQiitaで記事にしているので、興味ある方はぜひ読んでみてください!
今回は統計検定準1級を受けるためには必須の統計学実践ワークブックを解説します👍
僕は1ヶ月間統計学実践ワークブックと公式問題集を解きまくって、一発で準1級に合格しています。
統計学ワークブックは合格には必須アイテムですが、式変形が省略されていたり、説明がなされていない箇所などが散見されて、初学者にとっては非常に難しい参考書です。
各章の重要事項と例題の解き方を丁寧に解説するので、少しでも学習者にご活用頂ければと思っています。重要事項というのは、例題を解く上で必ず必要な知識と思ってもらえたらOKです!
まずこの記事では1章〜4章の解説を行います。
1章 事象と確率
この章で重要なポイントは、3つあります。
- 事象・余事象の理解
- ベイズの定理
- 期待値・分散の算出
事象・余事象の理解
まずは以下のベン図を書けるようにしましょう。この図を使うことでどのような状況かを視覚的に捉えることができます。あとは和事象を積事象を用いて求める式さえ覚えてしまえば、難しい範囲ではないと思います。
(和事象)=A∪B
(積事象)=A∩B

ベイズの定理
ベイズの定理は少し頭がこんがらがるポイントのため、詳しく式変形を説明します。
ベイズの定理とは、基本的には条件付き確率を式変形したものと考えれば良いでしょう。
Aが起きたという条件のもとでBが起きる条件付き確率$P(B|A)$を
P(B|A)=\frac{P(A∩B)}{P(A)}
と表せ、式変形すると
P(A∩B)={P(A)}\times{P(B|A)}\tag{1-1}
となります。同様に$B$が起きたという条件のもと$A$が起きる条件付き確率$P(A|B)$も式変形すると以下で表すことができます。
P(A∩B)={P(B)}\times{P(A|B)}\tag{1-2}
更に$(1-1)(1-2)$より
{P(A)}\times{P(B|A)}={P(B)}\times{P(A|B)}\tag{1-3}
となります。したがって、$(1-3)$を式変形すると
P(A|B)=\frac{{P(A)}\times{P(B|A)}}{P(B)}
$P(B)$は$A$が起こった時に$B$も起こる場合と$A$が起こらなかった時に$B$は起こる場合を足し合わせれば良いので、
P(A|B)=\frac{{P(A)}\times{P(B|A)}}{P(A){P(B|A)}+P(\bar{A})P(B|\bar{A})}
と変形できます。これをベイズの定理と呼びます。式変形により算出できるようにしておけば十分でしょう。
期待値・分散の算出
期待値と分散も式を覚えてしまうというより算出できるようにしておきましょう。
一つだけ覚えるのはこれだけです。
E[g(X)]=\sum_{x}{g(x)p(x)}
期待値を算出するときは$g(X)=X$, 分散を算出するときは$g(X)=(X-μ)^2$を代入するだけです。
(期待値)=E[X]=\sum_x{xp(x)}
\displaylines{
(分散)=V[X]=E[(X-μ)^2]\\
=E[X^2-2Xμ+μ^2]=E[X^2]-2μE[X]+μ^2
}
ここで$μ$は平均(Xの期待値)を表しているので$E[X]=μ$を用いて
\displaylines{
V[X]=E[X^2]-2μE[X]+μ^2=E[X^2]-2μ^2+μ^2\\
=E[X^2]-μ^2
}
と求められます。
続いてやや難しい例題問1.3の解説を以下で行います。
例題(問1.3)

2章 確率分布と母関数
2章では多くの新しい語句が出てくるのですが、以下3つの重要な関数について解説します。
- 同時確率関数(離散)
- 同時確率密度関数(連続)
- 母関数
同時確率関数(離散)
$X, Y$を2つの離散確率変数とするとき、「$X$が値$x$をとり、$Y$が値$y$をとる確率」を同時確率関数と呼び以下で表されます。
p(x,y)=P(X=x,Y=y)\tag{2-1}
また、$X<=x$かつ$Y<=y$となる確率のことを累積分布関数と呼び、以下で表されます。
F(x,y)=P(X<=x, Y<=y)=\sum_{x'<=x, y'<=y}{p(x',y')
}
同時確率関数から、$Y$を無視した$X$のみの確率関数を周辺確率関数と言い、$p_X(x)=P(X=x)$で表されます。これを得るためには、$\sum_y{P(X=x,Y=y)}$を求める必要があります。したがって、$(2-1)$より以下で表されます。
p_X(x)=\sum_y{p(x,y)}\tag{2-2}
また、$X=x$が与えられた時に$Y=y$となる条件付き確率は、$p_{Y|X}(y|x)$で表され条件付き確率の公式$(P(A|B)=\frac{P(A)P(A∩B)}{P(B)})$を用いることで以下となります。
p_{Y|X}(y|x)=\frac{p(x,y)}{p_X(x)}\tag{2-3}
これは2変数だけでなくn変数でも同様のことが言えます。
同時確率密度関数(連続)
続いては同様のことを連続変数の時にも当てはめて考えます。$X,Y$を連続確率変数として累積分布関数を$F(x,y)=P(X<=x,Y<=y)$と仮定します。$X,Y$の同時確率密度関数は$F(x,y)をx,y$それぞれで偏微分した値で、$f(x,y)$で表されます。
f(x,y)=\frac{\partial ^2}{\partial x \partial y}F(x,y)
$X$の周辺確率密度関数は、離散値の時の$(2-2)$と同様に考えて、以下で表されます。
f_{X}(x)=\int_{-∞}^{∞}f(x,y)dy
$X=x$を所与としたときの$y$の条件付き確率密度関数は$(2-3)$と同様に考えて以下となります。
f_{Y|X}(y|x)=\frac{f(x,y)}{f_X(x)}
母関数
確率関数(離散値)や確率密度関数(連続値)の性質を調べるために有用なものが母関数であり、モーメント母関数や確率母関数が存在します。離散値確率変数の時は確率母関数を、連続変数確率変数の時はモーメント母関数を主に用います。
まず確率母関数の説明です。$X$の確率関数を$p(x)$とした時の確率母関数は以下です。
G(s)=E[s^X]=\sum_x{s^xp(x)}
ここで、次のように微分をうまく活用することで、期待値と分散を$G$で表すことができます。
\displaylines{
G'(s)=E[Xs^{X-1}]\\
G''(s)=E[X(X-1)s^{X-2}]\\
}
\displaylines{
G'(1)=E[x]\\
G''(1)=E[X(X-1)]
}
以上の式から、式変形をおこなって以下のように期待値と分散を表すことができます。
\displaylines{
E[X]=G'(1)\\
V[X]=E[X^2]-(E[X])^2=E[X(X-1)+X]-(E[X])^2\\
=E[X(X-1)]+E[X]-(E[X])^2\\
=G''(1)+G'(1)-(G'(1))^2
}
連続確率関数の時に用いられることが多いモーメント母関数は$s=e^θ$とおいたものであり、次で表されます。
m(θ)=E[e^{θX}]=G(e^θ)
確率母関数の時と同様に微分して、$θ=0$を代入することで期待値や分散を求められます。
例・例題
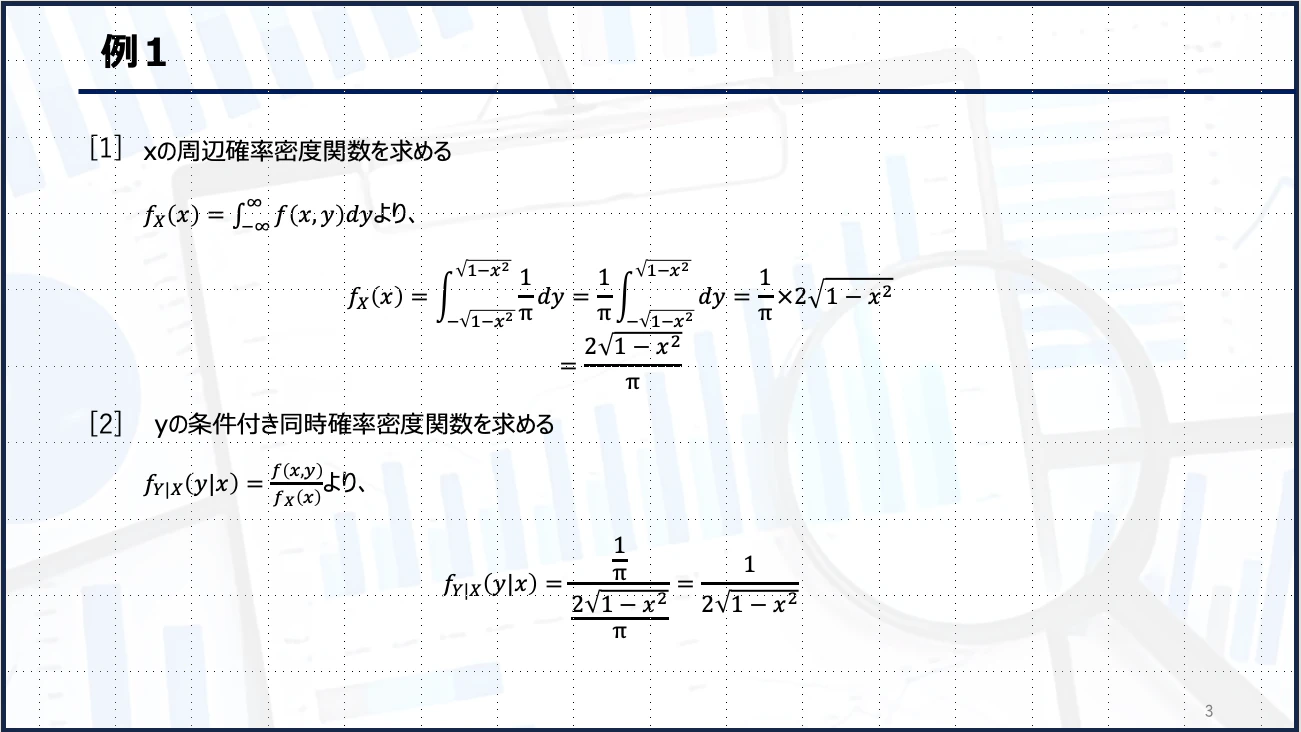



3章 分布の特性値
この章の重要事項は以下の3つです!
- 期待値の性質
- 分散の性質
- 多様な平均
期待値の性質
期待値には以下の性質があります。ここは暗記しましょう。
E[aX+bY+c]=aE[X]+bE[Y]+c
また、$X$と$Y$が独立の時以下となります。
E[XY]=E[X]E[Y]
また、$Y$が与えられた条件付き期待値に関しては以下が成り立ちます。
E[E[X|Y]]=E[X]
分散の性質
続いて分散には以下の性質があります。こちらも暗記しましょう。
\displaylines{
V[aX+b]=a^2V[X]\\
V[X\pm{Y}]=V[X]+V[Y]\pm{2Cov[X,Y]}
}
ここで$Cov[X,Y]$は$X, Y$の共分散を示しています。$V[X]+V[Y]$である点に注意しましょう。
またYが与えられた条件付き期待値に関しては以下が成り立ちます。
V[X]=E[V[X|Y]]+V[E[X|Y]]
多様な平均
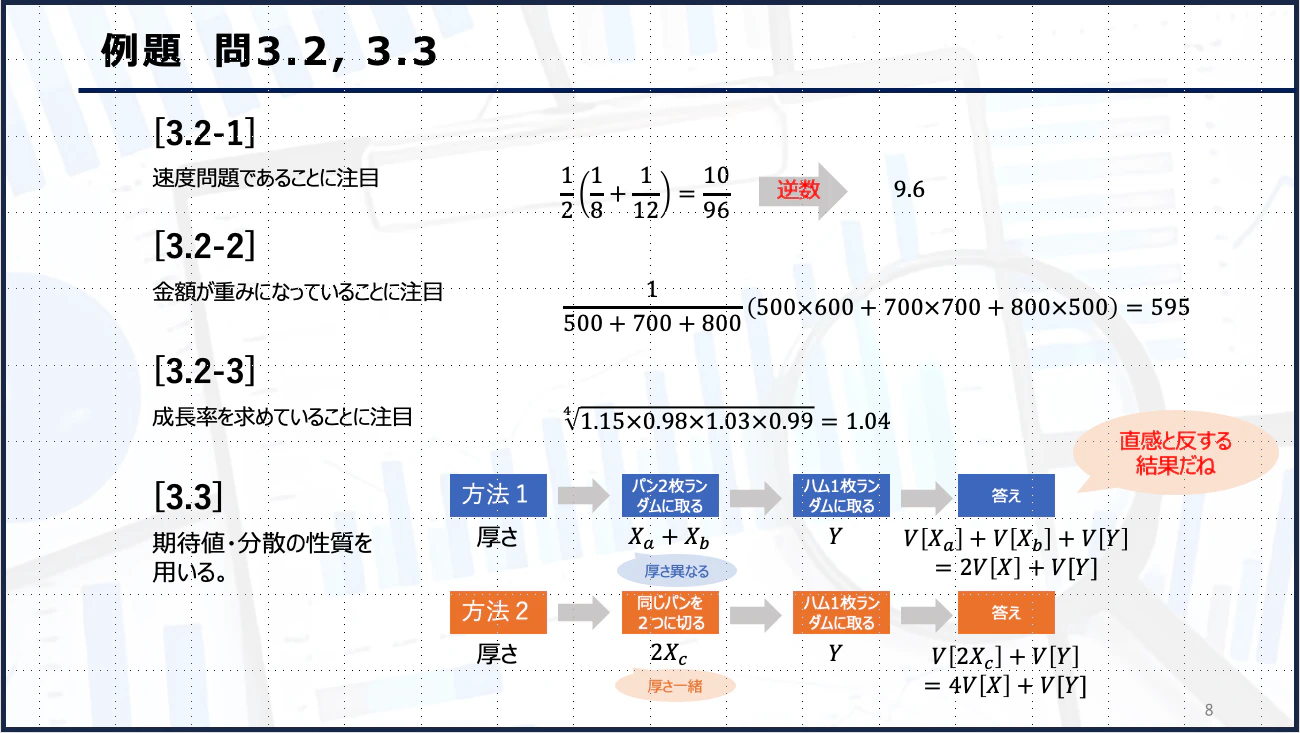
平均の計算方法については、加重平均, 幾何平均, 調和平均の3つが紹介されています。それぞれをどのタイミングで使うかを瞬時に判断することが大切です。
以下に3つの使い分け方を示します。

例題 問3.2, 3.3
4章 変数変換
この章で問いを解くために重要な語句は、以下の2点です。
- 1変数の確率密度関数の変数変換
- 2変数の確率密度関数の変数変換
1変数の確率密度関数の変数変換
連続型確率変数$X$の確率密度関数を$f(x)$とします。新たな確率変数$Y=g(X)$の確率密度関数について考えます。この時の$Y$の確率密度関数は以下となります。
f(y)=\frac{f(g^{-1}(y))}{|g'(g^{-1}(y))|}
つまり、
\frac{f(x)}{|g'(x)|}
の$x$を$y$に変換したものとして与えられます。
この式変形の証明は、非常に難しいので、暗記してしまうことをオススメします。
2変数の確率密度関数の変数変換
2変数$(X,Y)$の確率密度関数を$f(x,y)$として、変数変換$(Z,W)=(u(X,Y), v(X,Y))$について考えます。
ここで変換するためには、以下のようにヤコビアンを算出する必要があります。
\displaylines{
J(X,Y)=\frac{\partial (u(X,Y), v(X,Y))}{\partial (X,Y)}=\begin{vmatrix}{\frac{\partial u(X,Y)}{\partial X}} & {\frac{\partial u(X,Y)}{\partial Y}} \\{\frac{\partial v(X,Y)}{\partial X}} & {\frac{\partial v(X,Y)}{\partial Y}} \\\end{vmatrix}
}
そしてヤコビアンを用いて以下のように変換後の確率密度関数$f(z,w)$は次のように求まります。ただし、逆変換$(X,Y)=(s(Z,W), t(Z,W))$とします。
f(z,w)=\frac{f(s(z,w),t(z,w))}{|J(s(z,w),t(z,w))|}
つまり、
\frac{f(x,y)}{|J(x,y)|}
の$(x,y)$を$(z,w)$に変換したものとして与えられます。
例・例題


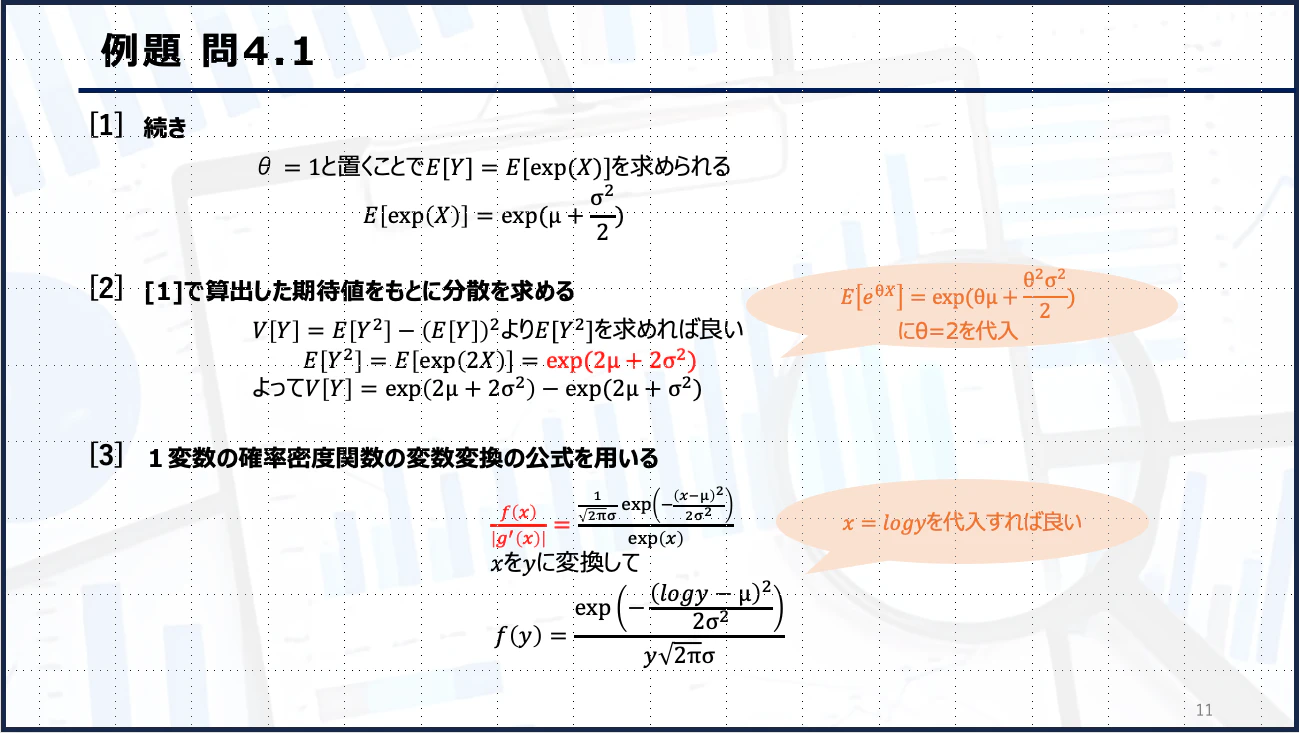

さいごに
最後まで読んでいただきありがとうございました!
少しでも統計検定を受ける方の一助となればと思います。
需要が高そうでしたら、統計学実践ワークブック完全攻略(5章〜8章)の記事も書いていくので、いいなと思った方は「いいね」お願いいたします。
もし僕の活動にもご興味を持っていただけたら、X(Twitter)もフォローしていただけると嬉しいです!
X(Twitter)
統計学実践ワークブック完全攻略(5章〜8章)