最近HTMLの中身を読み込むツールを作ろうとしたのだが,ブラウザのデベロッパーツールの中に書いてある文をどうにかして取り出せないかと考えた時に強引に取り出すことに成功した.本記事ではQiitaの本文を取り出す方法についてPythonで実装してみたので紹介する.
実装内容
Pythonの標準入力としてwebページのURLを叩き,出力でQiitaの本文を出すようにする.
Beautiful Soup ライブラリ
まずスクレイピングをするにあたってのBeautiful Soup ライブラリについて説明する.
Beautiful Soup は Python のライブラリで、HTML や XML ファイルからデータを抽出するためのツールである.ウェブスクレイピングやウェブページの解析に広く使用されている.
-
html.parserPython 標準ライブラリ(速度は中程度) -
lxml高速で柔軟性が高い(別途インストールが必要) -
html5lib最も寛容だが遅い(別途インストールが必要)
これらのパーサーを使って解析する.
パーサーとは
特定の形式で書かれたデータを解析し,プログラムが理解できる形に変換するソフトウェアコンポーネントのこと.
ウェブ開発,コンパイラ設計,データ処理,自然言語処理などの分野で広く使用されている.
具体的には以下のようにして使用する.
from bs4 import BeautifulSoup
# HTML文字列を解析
soup = BeautifulSoup(html_doc, 'html.parser')
# ファイルから解析
with open("index.html") as file:
soup = BeautifulSoup(file, 'html.parser')
また,タグ内の要素を取得するために以下のメソッドを使用する.
-
find()最初に一致する要素を返す -
find_all()全ての一致する要素をリストで返す
HTMLを書いたことがある人ならば見たことがあるタグなのではないか.
# タグ名で検索
soup.find('title')
soup.find_all('a')
# 属性で検索
soup.find('div', class_='content')
soup.find_all('a', href=True)
# テキスト内容で検索
soup.find(text="Python")
これでQiitaの本文を取り出すには?
まずQiitaのテンプレートを見る必要がある.このような投稿プラットフォームサービスは一般的に同じようなHTMLの構造になっている.
私のQiita記事の中身を調べてみると以下のような画像の構造になっていた.
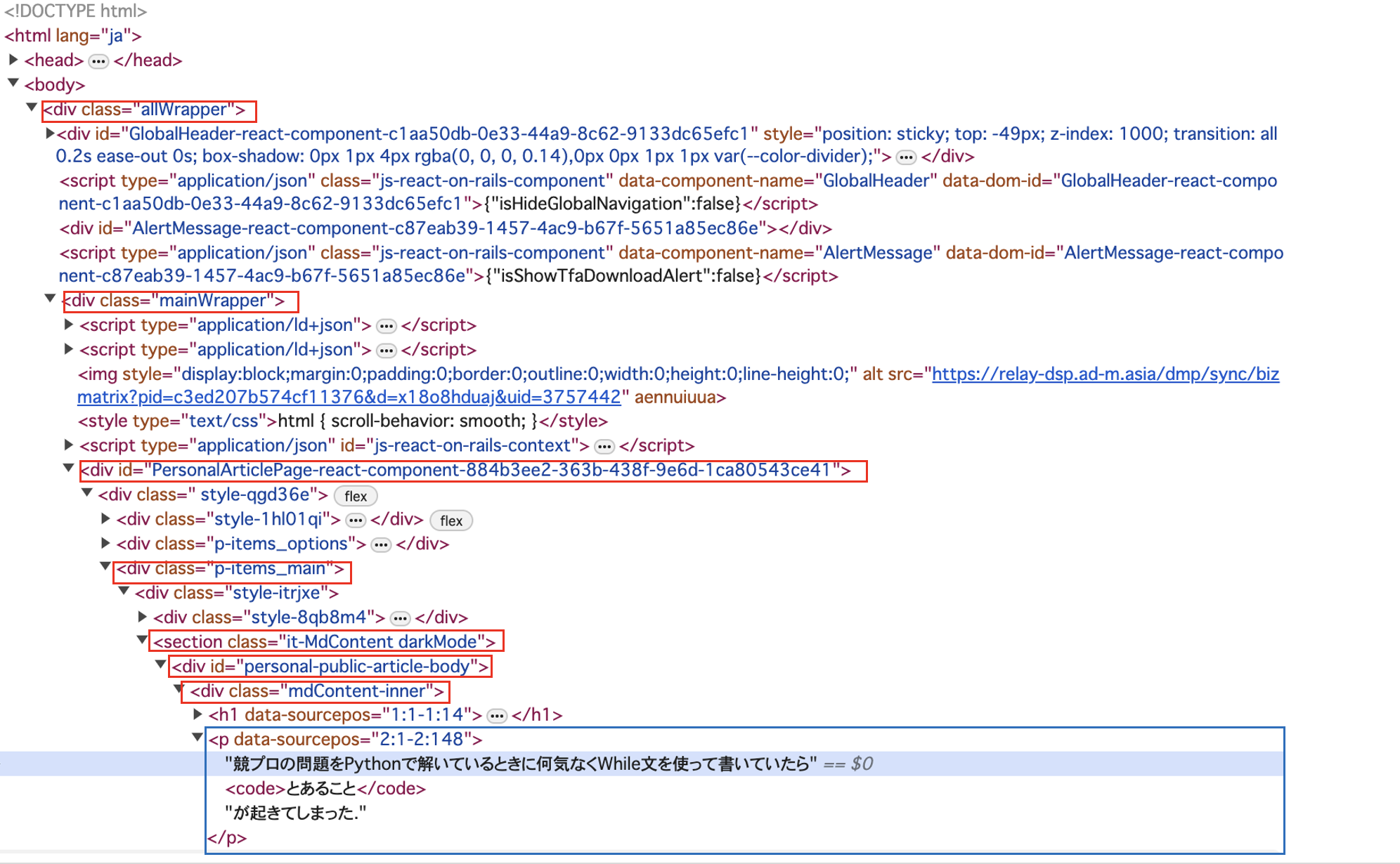
この構造をもとにスクレイピングするコードが以下の通りである.
url = input("URLを入力")
response = requests.get(url)
if response.status_code != 200:
return "ウェブページを取得できませんでした."
soup = BeautifulSoup(response.text, 'html.parser')
all_wrapper = soup.find('div', class_='allWrapper')
if not all_wrapper:
return "allWrapperクラスが見つかりません."
main_wrapper = all_wrapper.find('div', class_='mainWrapper')
if not main_wrapper:
return "mainWrapperクラスが見つかりません."
personal_article = main_wrapper.find('div', id=lambda x: x and x.startswith('PersonalArticlePage'))
if not personal_article:
return "PersonalArticlePageで始まるIDのdivが見つかりません."
p_items_main = personal_article.find('div', class_='p-items_main')
if not p_items_main:
return "p-items_mainクラスのdivが見つかりません."
it_MdContent = p_items_main.find('section', class_=lambda x: x and x.startswith('it-MdContent'))
if not it_MdContent:
return "it-MdContentで始まるクラスのsectionが見つかりません."
personal_public = it_MdContent.find('div', id='personal-public-article-body')
if not personal_public:
return "personal-public-article-bodyIDのdivが見つかりません."
MdContent_inner = personal_public.find('div', class_='mdContent-inner')
if not MdContent_inner:
return "mdContent-innerクラスのdivが見つかりません."
paragraphs = MdContent_inner.find_all('p')
text_content = ' '.join([paragraph.get_text() for paragraph in paragraphs])
return text_content
print(text_content)
出力結果が以下の通りである.
競プロの問題をPythonで解いているときに何気なくWhile文を使って書いていたらとあることが起きてしまった. Pythonで以下のようにコードを書いたとしよう. OKは何回出力されるだろうか? ではこの出力結果はどうか? 一度結果と根拠を考えてからスクロールしてほしい,どのようになるかな?
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. 結論を言うと結果は以下のようになる.
OKの数は, ほんの一部分の出力にすぎません の結果は, まあ記事のタイトル的に予想できただろう.OKは10回出力されるわけではなく無限ループが起きてしまった.また,0.1を10回足しても1.0ではないみたいだ. なぜだろうか? 強引に10回繰り返してみてxの値を確認してみる. この出力結果は ??? 1.0にならない?? Pythonにおいて,浮動小数点数は一般的にIEEE 754倍精度浮動小数点数形式(64ビット)で表現される.この形式では,0.1を正確に表現することができない.0.1を2進数で表現すると,次のような無限循環小数になる. Pythonでは,この無限に続く2進数を64ビットの範囲で丸めて表現する.この丸めにより,わずかな誤差が発生する.
このような仕様により0.1を10回足しても1.0になるわけではないのだ. この問題の本質は浮動小数点型の精度にある.コンピュータにおける浮動小数点型の定義と計算をもう一度考え直してみるいい機会だと思う. コメント欄から以下の解決策をいただきました.
引用元@YottyPGさんのコメント PythonのDecimalクラスを使用することで,正確な10進数の計算が可能になる.
浮動小数点値の0.1の代わりにDecimal('0.1')を使用することで,このコードでは10進数の精度で加算が行われることが保証される.Decimal('0.1')をxに加算するたびに正確に行われ,最終的な値は1.0になる.
Decimalクラスは,正確な10進数の計算が必要な場合に役立つ. 浮動小数点数で発生する可能性のある丸め誤差や精度の問題を回避することができる. 競プロの問題を解く際は浮動小数点型の表現に気をつけよう.
本文は...なんとか抽出できたようだ.
問題点
コードブロックの読み込みができていなかったので改良したい
応用例
これを使って記事の要約をGPTに投げるChrome拡張機能を作ってみた.以下の記事に記載している.