はじめに
省メモリで符号なし整数を高速でソートしたい. 後々にGPUで並列化したい. 検索するとQiitaの記事がヒットしましたが, とても実用的とは言えなかったため書きます.
基数ソート
基数ソートの原理は省いた, インプレイスの簡単な説明です.
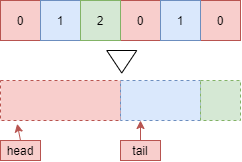
コードの1.で各バケツに入る要素の数を数え, それからプレフィックスサムを計算します. プレフィックスサムから, 各バケツに入るべき要素の範囲がわかります, 図のheadとtailです. 色と数字で各バケツを示しています, 赤色は0番目のバケツで3つの要素が入る予定です.
次に, コードの2.で, バケツに入れるべき要素を移動します. 1ステップごとに, 図の上の状態を下の状態にします.
8ビットずつソートしたいところですが, 最大のスタックサイズが看過できなくなります. 十分なスタックサイズはこの計算で正しいと思います. Shiftを8にした場合, スタックサイズがヤバげな値になります.
radix sort
inline u32 expand(u32 x, u32 shift, u32 mask)
{
return (x >> shift) & mask;
}
template<class T>
void radixsort(u32 size, T* data, std::function<u32(const T&)> getter)
{
static constexpr u32 Shift = 4;
static constexpr u32 BucketSize = 0x01U << Shift;
static constexpr u32 Mask = BucketSize - 1;
static constexpr u32 InitialShift = (sizeof(u32) * 8) - Shift;
static constexpr u32 StackSize = BucketSize * sizeof(u32) * 8 / Shift;
u32 head[BucketSize];
u32 tail[BucketSize];
struct Job
{
u32 head_;
u32 tail_;
u32 shift_;
};
Job jobs[StackSize];
s32 stack = 0;
jobs[0] = {0, size, InitialShift};
while(0 <= stack) {
Job job = jobs[stack];
--stack;
memset(tail, 0, sizeof(u32) * BucketSize);
//1.
for(u32 i = job.head_; i < job.tail_; ++i) {
u32 j = expand(getter(data[i]), job.shift_, Mask);
++tail[j];
}
head[0] = job.head_;
tail[0] += job.head_;
for(u32 i = 1; i < BucketSize; ++i) {
head[i] = tail[i - 1];
tail[i] += tail[i - 1];
}
//2.
for(u32 i = 0; i < BucketSize; ++i) {
while(head[i] != tail[i]) {
T x = data[head[i]];
u32 j = expand(getter(x), job.shift_, Mask);
while(i != j) {
T tmp = data[head[j]];
data[head[j]] = x;
x = tmp;
++head[j];
j = expand(getter(x), job.shift_, Mask);
}
data[head[i]] = x;
++head[i];
}
} //for(u32
if(job.shift_ <= 0) {
# ifdef _DEBUG
for(u32 i = job.head_ + 1; i < job.tail_; ++i) {
assert(getter(data[i - 1]) <= getter(data[i]));
}
# endif
continue;
}
u32 nextShift = job.shift_ - Shift;
u32 count = tail[0] - job.head_;
if(0 < count) {
++stack;
assert(stack < StackSize);
jobs[stack] = {tail[0] - count, tail[0], nextShift};
}
for(u32 i = 1; i < BucketSize; ++i) {
count = tail[i] - tail[i - 1];
if(0 < count) {
++stack;
assert(stack < StackSize);
jobs[stack] = {tail[i]-count, tail[i], nextShift};
}
}
} //while(0<=
};
テスト
テストデータは, 1,048,576個の整数です.
test
struct Data
{
u32 no_;
u32 value_;
};
u32 get(const Data& x)
{
return x.value_;
}
Data* generate(u32 size)
{
std::random_device seed_gen;
std::mt19937 engine(seed_gen());
std::uniform_int_distribution<> dist(0, size/2);
Data* data = reinterpret_cast<Data*>(malloc(sizeof(Data) * size));
for(u32 i = 0; i < size; ++i) {
data[i].no_ = i;
data[i].value_ = dist(engine);
}
return data;
}
template<class T>
T* duplicate(u32 size, T* src)
{
T* data = reinterpret_cast<T*>(malloc(sizeof(T) * size));
for(u32 i = 0; i < size; ++i) {
data[i] = src[i];
}
return data;
}
void sort(u32 size, Data* data, const char* name)
{
Data* data0 = duplicate(size, data);
std::chrono::high_resolution_clock::time_point start = std::chrono::high_resolution_clock::now();
radixsort<Data>(size, data0, get);
std::chrono::high_resolution_clock::time_point end = std::chrono::high_resolution_clock::now();
std::chrono::milliseconds duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << name << ": " << duration.count() << " milliseconds" << std::endl;
# ifdef _DEBUG
for(u32 i = 1; i < size; ++i) {
assert(data0[i - 1].value_ <= data0[i].value_);
for(s64 j = i - 1; 0 <= j; --j) {
assert(data[i].no_ != data[j].no_);
}
}
# endif
free(data0);
}
int main(void)
{
static const u32 N = 1024 * 1024;
{
Data* data = generate(N);
sort(N, data, "radix");
free(data);
}
return 0;
}
| 環境 | |
|---|---|
| CPU | Core i7-8700 |
| RAM | DDR4-2666 32 GB |
| コンパイラ | Visual Studio 2019 Version 16.8.5 |
| 実行時間(ミリ秒) | |
|---|---|
| radix sort | 59 |
まとめ
GPU版は後で書きましょう. 思っていたより速い.
元を示さないと, 1.の前段処理のところです.