はじめに
PandasのDataFrameを列単位、または行単位で一括処理できる関数にapply()がある。この機能を使えば、表計算処理が簡単にできそう。本記事では、下記をDataFrameを例としてapply()の動作を確認する。
| 番号 | 値A | 値B | |
|---|---|---|---|
| 0 | 一 | 1 | 10 |
| 1 | 二 | 2 | 20 |
| 2 | 三 | 3 | 30 |
| 3 | 四 | 4 | 40 |
| 4 | 五 | 5 | 50 |
DataFrameをエクセル、CSVの表から準備する場合は下記記事参照。
目次
applyの引数
applyの引数は下記の通り。その他パラメータ詳細は下記参照。
df.apply(func, axis=0, raw=False, result_type=None, args=(), by_row='compat', engine='python', engine_kwargs=None, **kwargs)
# func:一括処理する関数
# axis:列処理=0/行処理=1
# args:funcの引数がある場合に指定。tupleで指定
よく使う、 axis、args、result_typeについて以下補足。
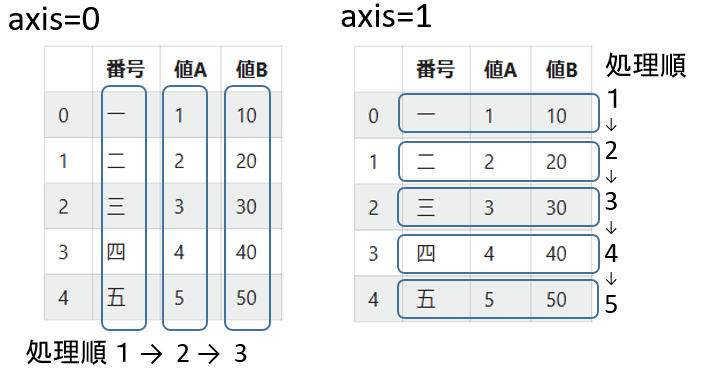
axis
applyは、Series単位で処理する。axisで列、行処理方向を指定できる。
func
funcの第一引数はSeriesで、axisによってアクセスの仕方が異なる。
axis=0で列処理の場合は
def func(x):
# x[0], x[1] ...とアクセス
df.apply(func, axis=0)
axis=1で行処理の場合は
def func(x):
# x['列名1'], x['列名2'] ...とアクセス
df.apply(func, axis=1)
args
funcの引数は、tuple型で指定する。tupleなので、引数が一つの場合は、,が必要。
# 引数1個 (xはapplyで処理するSeries)
def func(x,a):
...
df.apple(func, args=(1,))
# 引数2個以上 (xはapplyで処理するSeries)
def func(x,a,b):
...
df.apple(func, args=(1,2))
result_type
applyでreturnする値が2つ以上の場合は拡張するめexpandを設定する。ただし、行方向しかできないので、axis=1とすること。
def func(x):
return x*2, x*10
# axis=0 (列処理)
df[['2倍','10倍']]=df.apply(print_data, axis=1, result_type="expand")
axis列処理・行処理
df_apply_sample.py
import pandas as pd
#対象テーブル
df = pd.DataFrame(
{'番号':['一','二','三','四','五'],
'値A':[1,2,3,4,5],
'値B':[10,20,30,40,50]}
)
# 要素数とデータをprintする関数
def print_data(x):
print(f'{len(x)=}')
print(x)
print('---')
#----------------------------
# axis=0 (列処理)
#----------------------------
df.apply(print_data, axis=0)
# len(x)=5
# 0 一
# 1 二
# 2 三
# 3 四
# 4 五
# Name: 番号, dtype: object
# ---
# len(x)=5
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# Name: 値A, dtype: int64
# ---
# len(x)=5
# 0 10
# 1 20
# 2 30
# 3 40
# 4 50
# Name: 値B, dtype: int64
# ---
#----------------------------
# axis=1 (行処理)
#----------------------------
df.apply(print_data, axis=1)
# len(x)=3
# 番号 一
# 値A 1
# 値B 10
# Name: 0, dtype: object
# ---
# len(x)=3
# 番号 二
# 値A 2
# 値B 20
# Name: 1, dtype: object
# ---
# len(x)=3
# 番号 三
# 値A 3
# 値B 30
# Name: 2, dtype: object
# ---
# len(x)=3
# 番号 四
# 値A 4
# 値B 40
# Name: 3, dtype: object
# ---
# len(x)=3
# 番号 五
# 値A 5
# 値B 50
# Name: 4, dtype: object
# ---
列を絞って処理する
df_apply_sample.py
import pandas as pd
#対象テーブル
df = pd.DataFrame(
{'番号':['一','二','三','四','五'],
'値A':[1,2,3,4,5],
'値B':[10,20,30,40,50]}
)
# 最小と最大をprintする関数
def print_maxmin(x):
print(f'{max(x)=}/{min(x)=}')
# 数値に絞って処理 axis=0 (列処理)
df[['値A','値B']].apply(print_maxmin, axis=0)
# max(x)=5/min(x)=1
# max(x)=50/min(x)=10
# 数値に絞って処理 axis=1 (行処理)
df[['値A','値B']].apply(print_maxmin, axis=1)
# max(x)=10/min(x)=1
# max(x)=20/min(x)=2
# max(x)=30/min(x)=3
# max(x)=40/min(x)=4
# max(x)=50/min(x)=5
argsで引数を使う
df_apply_sample.py
import pandas as pd
#対象テーブル
df = pd.DataFrame(
{'番号':['一','二','三','四','五'],
'値A':[1,2,3,4,5],
'値B':[10,20,30,40,50]}
)
#------------------------------------
# a倍する
#------------------------------------
def func(x,a):
return x*a
# axis=0 (列処理)
df[['値A','値B']]=df[['値A','値B']].apply(func, args=(5,), result_type=None)
print(df)
# 番号 値A 値B
# 0 一 5 50
# 1 二 10 100
# 2 三 15 150
# 3 四 20 200
# 4 五 25 250
#------------------------------------
# 奇数行なら odd倍 偶数行なら even倍
#------------------------------------
def func(x,odd,even):
for cnt,data in enumerate(x):
if(cnt%2==0):
x[cnt]=data*even
else:
x[cnt]=data*odd
return x
# axis=0 (列処理)
df[['値A','値B']]=df[['値A','値B']].apply(func, args=(10,100), result_type=None)
print(df)
# 番号 値A 値B
# 0 一 500 5000
# 1 二 100 1000
# 2 三 1500 15000
# 3 四 200 2000
# 4 五 2500 25000
result_typeで戻り値を複数返す
df_apply_sample.py
import pandas as pd
#対象テーブル
df = pd.DataFrame(
{'番号':['一','二','三','四','五'],
'値A':[1,2,3,4,5],
'値B':[10,20,30,40,50]}
)
#------------------------------------------
# x['値A']の5倍 x['値B']の10倍を返す
#------------------------------------------
def func(x,c,d):
return x['値A']*c, x['値B']*d
# return値をdf_returnに代入
df_return=df.apply(func, args=(5,10), axis=1, result_type="expand")
print(df_return)
# 0 1
# 0 5 100
# 1 10 200
# 2 15 300
# 3 20 400
# 4 25 500
# 返した値を'値C','値D'列に追加する
df[['値C','値D']] = df.apply(func, args=(5,10), axis=1, result_type="expand")
print(df)
# 番号 値A 値B 値C 値D
# 0 一 1 10 5 100
# 1 二 2 20 10 200
# 2 三 3 30 15 300
# 3 四 4 40 20 400
# 4 五 5 50 25 500
参考にした記事