はじめに
この記事はシスコ社員有志による Cisco Systems Japan Advent Calendar 2021 🎁 1枚目の 9日目として投稿しています![]() 。
。
2021年版(1枚目): https://qiita.com/advent-calendar/2021/cisco
2021年版(2枚目): https://qiita.com/advent-calendar/2021/cisco2
以下、昨年までのものです。
2020年版(1枚目): https://qiita.com/advent-calendar/2020/cisco
2020年版(2枚目): https://qiita.com/advent-calendar/2020/cisco2
2019年版: https://qiita.com/advent-calendar/2019/cisco
2018年版: https://qiita.com/advent-calendar/2018/cisco
2017年版: https://qiita.com/advent-calendar/2017/cisco
まえおき
シスコが提供するルータやスイッチには、Cisco IOxと呼ばれるLinuxをホスティングする機能が備わっているものがあります。そして、このCisco IOxを提供するハードウエアをIOxプラットフォームといいます。
IOxプラットフォームは、機種ごとに異なるハードウエアで構成されています。例えばIR1101のCPUは ARM64ですし、Catalyst 9300は Intel Corei7です。また、それぞれの動作速度も異なります。さらに仮想化ソフトウエアも異なります。例えば、IC3000の仮想環境は QEMUですし、IE4000は LXCで動きます。このあたりの詳細については、Platform Support Matrixにリストされています。
さて、同じアプリを異なるプラットフォームで動作させる時に、ある程度の指標があると比較する時に便利です。そのために、Cisco IOxではリソースプロファイルというものを定義しています。
リソースプロファイルについては、DevNetの Resource profilesに説明があります。
これによると、リソースプロファイルはメモリとCPUユニット、ディスクサイズの3つで構成されているとあります。また、CPUユニットの値が同じであれば IOxプラットフォームを変えても「同様のパフォーマンス」が得られるとあります。さらに、開発したIOxアプリを同じリソースプロファイルを使って Cisco DevNetの IOxサンドボックスで動かせば、実際のIOxプラットフォームがなくてもある程度の性能評価ができるともあります。
便利ですね。
では、このCPUユニットとは何を基準に決められているのでしょうか?
同じく Resource profilesに、下記の様に書いてありす。
The CPU unit values for a platform is obtained by executing standard benchmarking tools on that platform and assigning a unit value based on their relative score when compared against a standard base platform.
Based on the benchmarking results, x86 based 64 bit Intel Xeon processor with one core of CPU @ 2GHz will have 10000 cpu units.
これは、
IOxプラットフォームのCPUユニットの値は、2GHzで動作する1コアのIntel Xeon プロセッサで、「標準的なベンチマークツール」を動かして得た結果を 10000 CPUユニットとした時の相対値である。
と読めます。
さて、このプロセッサのCPUユニットの値が 10000なので、Platform Support Matrixと照らし合わせながら、手元にあるIOxプラットフォームの性能を相対的に判断すればよいことになります。
ところが、PC Watchのニュースによれば、このプロセッサは2001年に最初にリリースされた様です。ということは、このプロセッサを使っているハードウエアを入手するのは非常に困難です。
「このIOxプラットフォームのCPU性能は、Intel Xeon 2GHz 1コアと比較して4分の1です!」
と説明しても、うなずくユーザはゼロとは言いませんが多くはないでしょう。そもそも、どの様なベンチマークをしたのか分からないので比較のしようがありません。
ソフトウエア・ベンチマーク
というわけで、前置きが長くなりましたが「身近なもの」で「標準的な」ソフトウエア・ベンチマークをやってみて、IOxプラットフォームと比較してみました。
下記は「身近なもの」のリストです。知名度、入手のしやすさ、事例の多さの点でラズパイは外せません。PC代表として手元の Mac Book Proに参加してもらいました。そして、IOxプラットフォーム代表は、Cisco Catalyst IR1101を使いました。
| 略称 | HW | CPU | メモリ | OS |
|---|---|---|---|---|
| RPi | Raspberry Pi Model B | ARMv6 | 256MB | Raspberry Pi OS Lite 2021-10-30版 |
| RPi3 | Raspberry Pi 3 Model B | ARMv8 4-Core 1.2 GHz | 1GB | Raspberry Pi OS Lite 2021-10-30版 |
| RPi4 | Raspberry Pi 4 Model B | ARMv8 4-Core 1.5 GHz | 4GB | Raspberry Pi OS Lite 2021-10-30版 |
| MBP | Mac Book Pro Model A1990 | Intel Core i7 6-Core 2.2 GHz | 16GB | macOS 10.15.7 |
| IR1K | Cisco Catalyst IR1101 | ARMv8 4-Core 600MHz | 862MB1 | IOS-XE 17.3.4 2 |
「標準的な」ソフトウエア・ベンチマークとしては、整数演算、浮動小数点演算、一般的なアプリの3種類で、かつ Linux OSで動作する下記3つを選びました。
- sysbench
- LINPACK
- OpenSSL speed
さて、それでは一つずつ試してみます。
以降、断りがなければ IOxアプリは、Dockerタイプで CPUユニット 512, メモリ 64MB, ディスクサイズ 2MB で動作させています。
sysbench
sysbenchは、代表的なベンチマークツールと言っていいと思います。1990年前後から少しずつ改良3が加えられて、今でも Githubでメンテナンスされています。
データベースのベンチマークとして作られたようですが、CPUのベンチマークもできます。CPUのベンチマークでは、素数を求める計算を行っています。平方根を使っているので倍精度浮動小数点が出てきますが、整数値と比較しているだけです。それ以外は整数の除算を行っていて、比率でいうと整数演算が10倍になります。
測定は、10000までの素数を求める計算を1イベントとして10秒間実行します。そして、1秒あたり何回イベントを実行できたか(EPS: Events Per Second)を記録します。この測定を20回やって平均を出します。
計算を複数同時に行う評価もできますので、これも測定してみます。スレッドは pthread(3)を使っています。
まずはスレッドを1つで比較してみます。
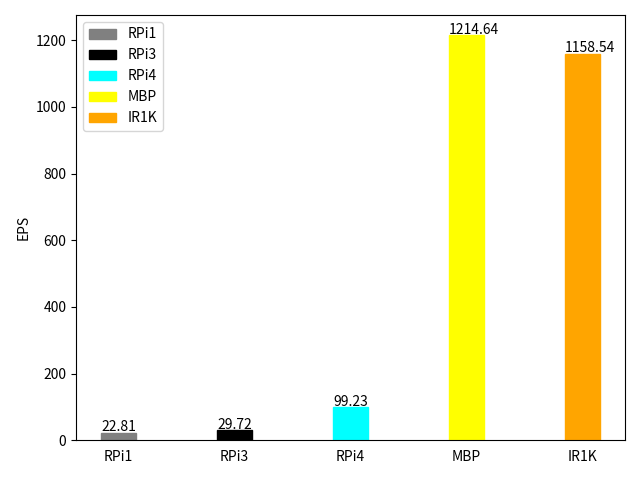
| HW | TH | EPS |
|---|---|---|
| RPi1 | 1 | 22.81 |
| RPi3 | 1 | 29.72 |
| RPi4 | 1 | 99.23 |
| MBP | 1 | 1214.64 |
| IR1K | 1 | 1158.54 |
RPi1とRPi3とは2桁の差がでました。RPi4と比較してもほぼ10倍の差がでました。考えられる大きな要因としては、Raspberry Pi OSは歴史的な理由で 32ビットで動作しています。64ビット版OSも入手可能ですが、現在のところβ版という状況になっていますので、今回は採用しませんでした。またの機会に測定して比較してみたいと思います。
IOxが発表された当初のプラットフォームは、RPi1といい勝負だったので、だいぶ進化した印象です。8年前から関わってきた者としては感慨深いものがあります。macと比較してもまさかのいい勝負をしています。
「おお!IR1101君、わりとできる子かも?!」と思ったのですが、スレッドを増やすとmacとの性能の違いは歴然としています。
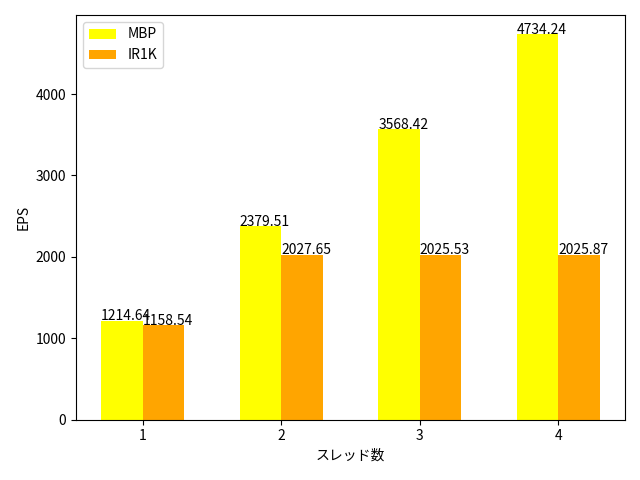
| スレッド数 | MBP EPS | IR1K EPS |
|---|---|---|
| 1 | 1214.64 | 1158.54 |
| 2 | 2379.51 | 2027.65 |
| 3 | 3568.42 | 2025.53 |
| 4 | 4734.24 | 2025.87 |
macはスレッドを増やせばリニアに性能がよくなっています。一方で IR1101の場合、1スレッドと2スレッドを比較するとほぼ倍の性能が出ていますが、2スレッド以上はスレッドを増やしても性能に差がでません。CPUの4コアのうち2コアだけを使うように制限がかかっていることがわかります。これはIR1101本来の機能であるネットワーク機能に影響を与えないためと予想できます。こちらもいつか性能測定を行ってみたいと思います。
というわけで、さすがに本気の macにはかないませんが、sysbenchを1スレッドで動作させる分には、IR1101も macと同程度の性能が出せるということがわかりました。
次、行ってみましょう!🎄
LINPACK
LINPACKは、古くからある浮動小数点演算のベンチマークです。wikipediaによると最初のリリースは1979年だそうです。一部のスピード狂の方々はご存知かと思います。
LINPACKは、ガウスの消去法を使って線形方程式をひたすら解いてFLOPSを出力します。多くの亜種がネットにありますが、今回は下記を使いました。
さて、結果は…。
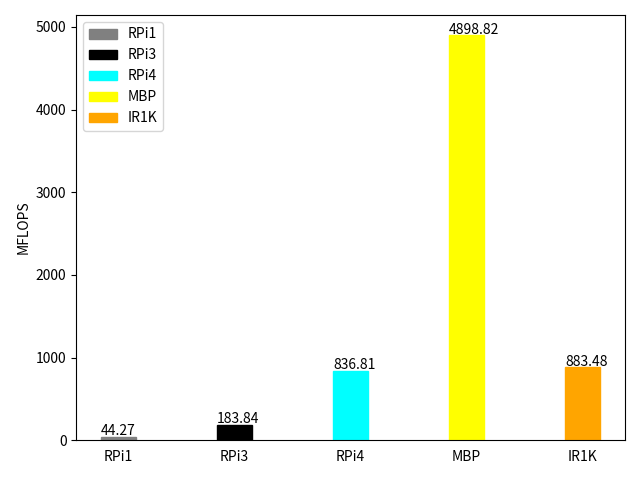
| HW | MFLOPS |
|---|---|
| RPi1 | 44.274 |
| RPi3 | 183.841 |
| RPi4 | 836.807 |
| MBP | 4898.820 |
| IR1K | 883.475 |
RPi1や RPi3と比較すると、それぞれ約20倍、約5倍の性能が出ています。RPi4とは同程度でしたが、macと比較すると約6分の1でした。
RPi4や IR1101は、ARM Cortex-A72なので浮動小数点演算用コプロセッサが載っています。それにも関わらずこの差はどうして出たのでしょうか?
理由としては2つ考えられます。1つは、gccには ARM Cortex-A72用のビルドオプションがいくつか用意されていますが、LINPACKをビルドする時には -O3以外のオプションを指定しませんでした。したがって、浮動小数点演算に最適な命令を組み込めていなかったのではないかと考えられます。もう1つは、IR1101 IOXアプリは Dockerで動いています。何らかの制約で浮動小数点演算用コプロセッサが使えていなかったのではと考えられます。この辺は、もう少し深堀りしたいので冬休みの宿題にしたいと思います。
もやもやしますが、サンタ🎅🏽は待ってくれません。次に行ってみましょう。
OpenSSL speed
OpenSSLツールに含まれている speedは OSにおける暗号の性能をテストするのによく使われるツールです。アプリが通信する時は必ずと行っていいくらい暗号化を行いますので、一般的なアプリ代表としてふさわしいと思います。OpenSSL speedは数多くの測定ができますが、今回は暗号化通信によく使われる RSA-2048による署名と検証を使いました。RSAの署名と検証は多倍長整数演算を使っています。また、検証よりも署名に時間がかかることが知られています。
ベンチマークは、署名と検証をそれぞれ 1イベントとして 10秒間実行します。そして、1秒あたり何回イベントを実行できたかを記録します。これを 20回行って平均を取りました。
OpenSSL speedは、マルチスレッドにも対応していますので、これも測定してみます。ちなみに、こちらは pthread(3)ではなく fork(2)を使っています。
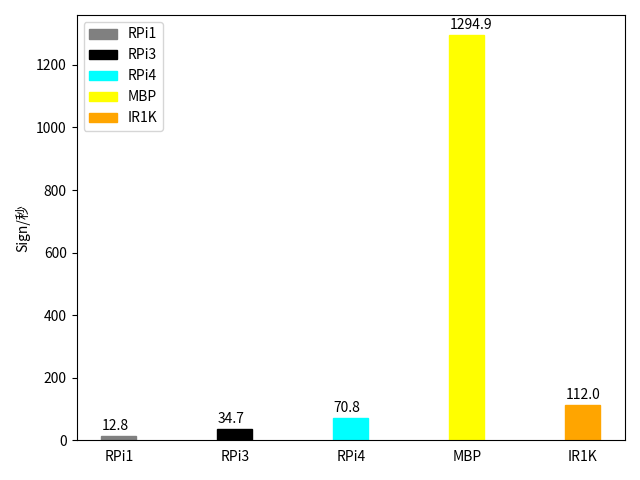
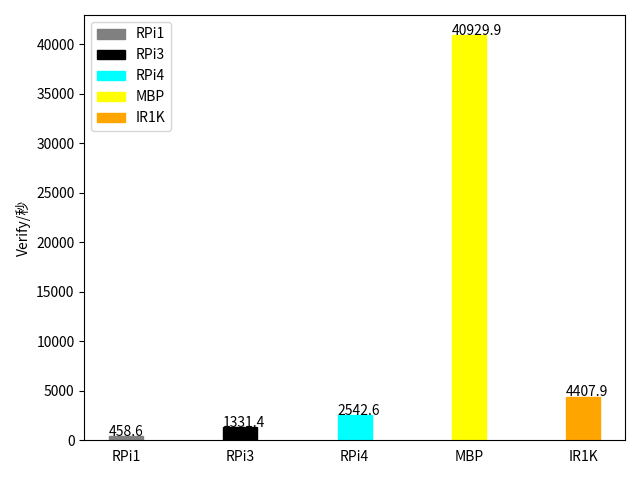
| HW | スレッド数 | 署名/秒 | 検証/秒 |
|---|---|---|---|
| RPi1 | 1 | 12.8 | 458.6 |
| PPi3 | 1 | 34.7 | 1331.4 |
| RPi4 | 1 | 70.8 | 2542.6 |
| MBP | 1 | 1294.9 | 40929.9 |
| IR1K | 1 | 112.0 | 4407.9 |
1つ目のグラフは署名で、2つ目が検証した数です。RPi1や RPi3と比較するとそれぞれ約10倍、約3倍の性能がでました。RPi4と比較しても 6割増程度の性能が出ています。しかし、macと比較すると約10分の1以下でした。エッジのアプリをホスティングするという観点では十分かもしれませんが惨敗です。mac強いよ。
考えられる要因としては、ラズパイや macの OpenSSLツールは特定の暗号方式のアセンブラ最適化コードを利用してビルドされています。一方、DevNetが提供している IR1101 IOx用Dockerイメージに含まれている OpenSSLツールには、最適化オプションはついていませんでした。時間の都合上、今回は深堀りはできませんでしたが、そのうち IR1101でも最適化された OpenSSLツールをビルドして測定してみたいと思います。
さて、スレッドを複数で測定してみましたが、予想通りです。macはスレッドを増やせばリニアに性能がよくなる一方で、IR1101は2スレッドが上限になっています。
| HW | スレッド数 | sign/s | verify/s |
|---|---|---|---|
| MBP | 1 | 1294.9 | 40929.9 |
| 2 | 2582.2 | 82000.0 | |
| 3 | 3601.6 | 113165.0 | |
| 4 | 4460.4 | 141259.6 | |
| IR1K | 1 | 112.0 | 4407.9 |
| 2 | 192.5 | 7662.9 | |
| 3 | 190.3 | 7633.4 | |
| 4 | 190.6 | 7639.2 |
ところで、IOxアプリに割り当てたメモリは64MBでしたので、256MBと512MBを割り当てて試してみました。
| MEM | スレッド数 | sign/s | verify/s |
|---|---|---|---|
| 16 | 1 | 112.2 | 4411.1 |
| 64 | 1 | 112.0 | 4407.9 |
| 512 | 1 | 112.1 | 4406.4 |
| 16 | 2 | 194.4 | 7605.7 |
| 64 | 2 | 192.5 | 7662.9 |
| 512 | 2 | 193.8 | 7622.1 |
目立った違いはないので CPU性能という観点では意識しないでよさそうです。
まとめ
今回は、標準的なソフトウエア・ベンチマークとして、sysbench, LINPACK, OpenSSL speedの3つを使い、ラズパイ、Mac Book Pro、そして Cisco IOxプラットフォームの1つ、Cisco Catalyst IR1101 IOxの性能を比較してみました。
結果としては、
- ラズパイと比較すると概ね IR1101 IOxの方が性能がよい。
- sysbenchを 1スレッドで実行した場合、macと比較しても同程度の性能がでる。
- ただし、それ以外の条件では、macの方が圧倒的に性能がよい。
- IR1101 IOxは2スレッドが上限である。
さて、いくつか冬休みの宿題となりましたが、時間を見つけて片付けてみたいと思います。
今年の冬⛄は寒いと聞いています。皆様、風邪などひかぬよう暖かくして来年🐯をお迎え下さい。
ここまで読んで頂きまして、ありがとうございました。
免責事項
本サイトおよび対応するコメントにおいて表明される意見は、投稿者本人の個人的意見であり、私の所属する組織の意見ではありません。本サイトの内容は、情報の提供のみを目的として掲載されており、私の所属する組織や他の関係者による推奨や表明を目的としたものではありません。各利用者は、本Webサイトへの掲載により、投稿、リンクその他の方法でアップロードした全ての情報の内容に対して全責任を負い、本Web サイトの利用に関するあらゆる責任から私の所属する組織を免責することに同意したものとします。