自分用にデータベースの基本的なことについてまとめました。
主に「データベースのきほん」の内容についてまとめたものになります。データベースのことをほとんど知らない自分でもとてもわかりやすく読めました。
1. データベースとは?
データベースとは、蓄積・検索・更新などに便利なように有機的に整理された情報の集まりのこと。
1.1 基本機能
DBの基本機能は以下の4つ。
1. データの検索と更新(登録・修正・削除)
2. 同時実行制御
3. 耐障害性
4. セキュリティ
1. データの検索と更新(登録・修正・削除)
欲しいと思ったデータを見つける、または更新する
2. 同時実行制御
更新の整合性をどのように保障するか
3. 耐障害性
なかなか壊れにくく、壊れても復旧できる(※)
4. セキュリティ
DBに保存されているデータをいかにして隠すか
※ データの消失防止方法
①データの冗長化
②バックアップ
1.2 DBの種類
DBには以下の種類がある。
1. 階層型DB
2. リレーショナルDB (←現在最も主流なDB)
3. オブジェクト指向DB
4. XMLDB
5. NoSQLDB
2. リレーショナルデータベースとは?
2.1 リレーショナルデータベースとSQL
- リレーショナルデータベースとは、データをエクセルのように二次元表を使って管理するデータベースのこと。
- SQLとは、リレーショナルデータベースがデータ操作のために備えている言語のこと。
2.2 DBMSとデータベースの違い
- データベースの機能を提供するソフトウェアのことを「DBMS(DataBase Management System)」と呼ぶ。厳密に言えば、OracleやMySQLといった具体的な製品は「DBMSであってデータベースではない」というのが正しい区別になる。
3. データベースのお金の話
3.1 システムのトータル費用の内訳
-
イニシャルコスト:最初にまとめて払うお金のこと。DBMSのライセンス料がイニシャルコストになる。ライセンス料には以下二種類の販売単位がある。
①プロセッサライセンス
DBMSをインストールして動作させるハードウェア(DBサーバ)のCPU性能に応じて価格が決まる。
②ユーザライセンス
DBMSを利用するユーザ数に応じて価格が決まる。 - ランニングコスト:サービスを利用する期間、継続的に払うお金
4. データベースとアーキテクチャ構成
4.1 アーキテクチャの歴史
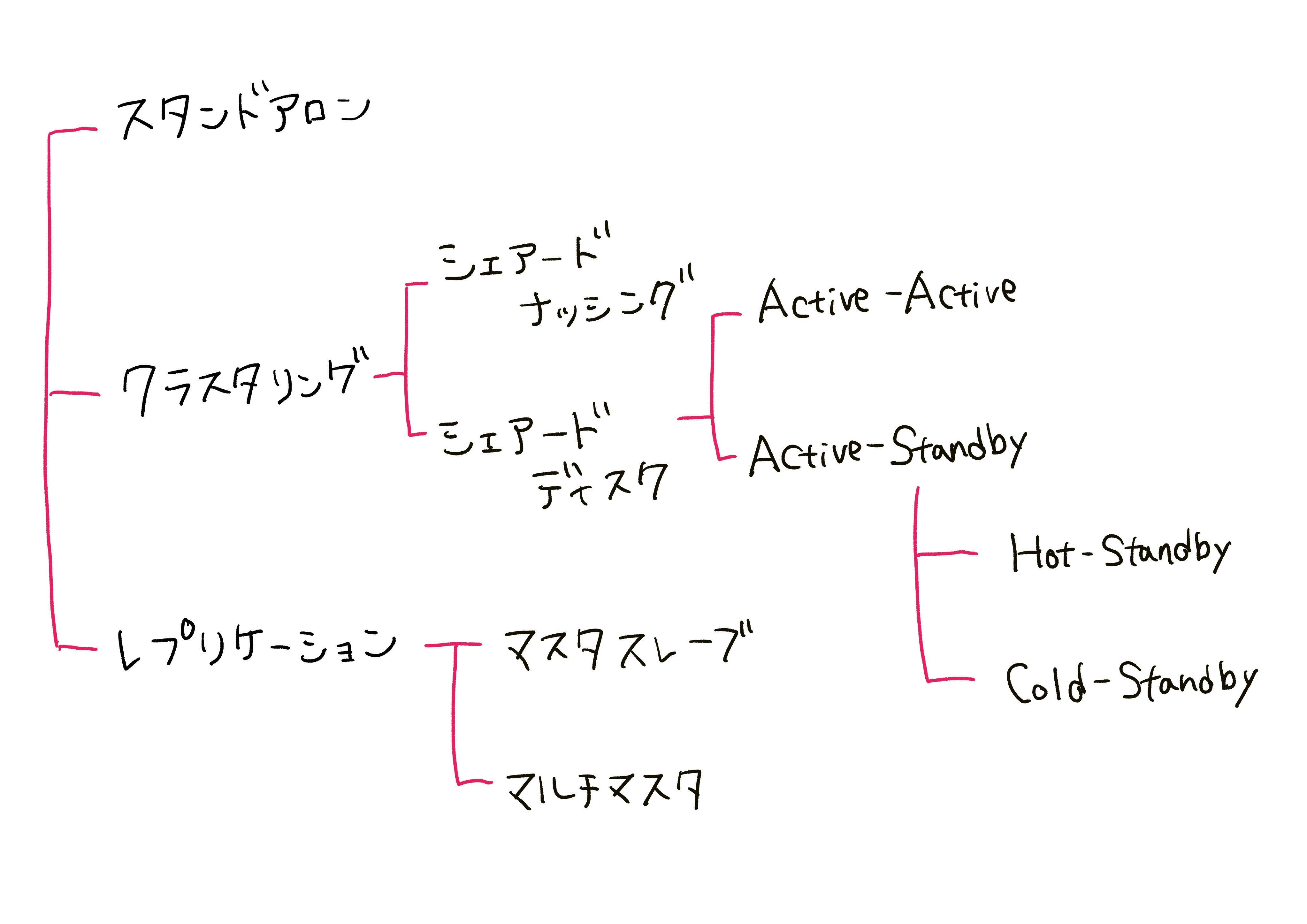
1. スタンドアロン(〜1980年代)
2. クライアント/サーバ(1990年代〜2000年)
3. Web3層(2000年〜現在)
-
スタンドアロン
データベースだけでシステムを成立させる最もシンプルな方法。
データベースサーバが、LANやインターネットなどのネットワークに接続されておらず、孤立して動作する構成。■スタンドアロンの欠点
①物理的に離れた場所からのアクセスができない
②複数ユーザによる同時作業ができない
③可用性が低い(サーバが1台しかないため、その1台に障害が起きるとサービスが停止する)
④拡張性に乏しい(サーバが1台しかないため、当該サーバの性能が限界に達した場合、サーバを上位機種に交換したりより高性能の部品で交換する以外にパフォーマンス改善の手段がない)
2. **クライアント/サーバ** スタンドアロンの欠点①②を克服するために、データベースをネットワークにつないだ方法。組織内の閉じた用途のシステムに利用されるケースが多い。
3. **Web3層** 以下の3つのレイヤの組み合わせとして考えられるモデルのこと。現在のWebシステムではほぼ標準の構成。 **①Webサーバ層** **②アプリケーション層** **③データベース層** - Webサーバは、クライアントからのアクセス(HTTPリクエスト)を直接受けて、その後の処理を後段のアプリケーションサーバに渡し、結果をクライアントに返却する。 - アプリケーション層は、ビジネスロジックを実装したアプリケーションが動作するレイヤのこと。Webサーバから連携されたリクエストを処理し、必要ならばデータベース層へアクセスを行ってデータを抽出し、それを加工した結果をWebサーバに返却する。
- - -
4.2 「停止しない」システム作り(可用性の上げ方)
可用性を上げるためのアプローチは大きく以下の2つ。
-
心臓戦略:高品質-少数戦略
システムを構成する各コンポーネントの信頼性を上げることで障害の発生率を低く抑え、可用性を上げる。 -
肝臓戦略:低品質-多数路線
システムを構成する各コンポーネントの信頼性を頑張って上げるよりも「物はいつか壊れるものだ」という概念を前提に、スペアを用意しておく。これを徹底することを「物量作戦」と呼ぶ。
- クラスタリング:肝臓戦略において、同じ機能を持つコンポーネントを並列させること。
-
冗長化:クラスタを組んでシステムを稼働率を高めること。
(冗長という言葉は「無駄が多い」というマイナスなニュアンスが伴うことがあるが、システムの世界では、「より耐久性が高く堅牢である」といういい意味を持っている。) - 単一障害点(SPOF - Single Point Of Failure):そこが故障すればシステム全体のサービス継続性に影響を与えるコンポーネントのこと。
4.3 データベースの冗長化
- データベースはサーバとストレージで構成される。
- 最も簡単な冗長化は、DBサーバのみを冗長化して、ストレージは単一構成とするパターン
冗長化したサーバでは、同時に動作することを許すかによって以下の動作がある。
- Active-Active:クラスタを構成するコンポーネントが同時に稼働する
- Active-Standby:クラスタを構成するコンポーネントのうち、同時に稼働するのはActiveのみで、残りは待機している
-
Active-Active
- 複数のDBサーバが動いているため、1台に障害が起きても処理を継続できる
- 各DBサーバのCPUやメモリが同時に稼働するため、処理のパフォーマンスが向上する
- ストレージがボトルネックになることもある
-
Active-Standby
Standby側のデータベースは普段は使われず、Active側に障害が起きたときだけ使われる。その際、切り替わるまでのタイムラグが生じる。Active-Standbyは以下の二種類に分類される。-
Active-Standby(Hot-Standby)
待機系のデータベースを普段は起動させず、現用系のデータベースがダウンした時点で待機系を起動するタイプ。 -
Active-Standby(Cold-Standby)
普段から待機系のデータベースを起動させておくタイプ。
-
Active-Standby(Hot-Standby)
4.4 DBサーバとデータの冗長化
- レプリケーション:DBサーバとストレージのセットを複数用意し複製し、DBサーバとストレージが同時に使用不能になった際にも、他のセットでサービスを継続可能とするアーキテクチャ。ある一定の間隔で更新差分をStandbyサーバに書き込む。
4.5 パフォーマンスを追求するための冗長化
- シェアードディスク:複数のサーバが1つのストレージを共有。DBサーバを増やしても無限にスループットが向上するのではなく、どこかで頭打ちになる。
-
シェアードナッシング:サーバとストレージのセットを増やしていく。
サーバとストレージのセットを増やせば、並列処理によって線形に性能が向上する。Googleが有効性を証明し、注目が集まった手法。
データベースのアーキテクチャパターンまとめ