はじめに
Pythonの学習を始めました。
Webスクレイピングについて理解を深めたいため、自分なりにまとめてみます。
Webの仕組み
本記事では割愛しますが、分散系の開発を行うならば、ある程度理解しておく必要があると思います。
個人的に、学習にはこちらの書籍がおすすめです。
Webを支える技術 -HTTP、URI、HTML、そしてREST (WEB+DB PRESS plus)
BeautifulSoupとは
本題です。
書籍などでは、HTMLの解析を行うライブラリと説明されています。
公式サイトも確認しましょう。特徴は以下3点。
- ツリー構造をナビゲート、検索、変更するためのメソッドを提供している。
- 自動的にエンコードしてくれる(BeautifulSoupがドキュメントのencodeを特定できない場合を除く)。
- 受信ドキュメントはUnicode
- 送信ドキュメントはUTF-8
- 利用するParserを選択できる。
- html.parser:標準ライブラリ。処理速度は早くもなく遅くもなく。
- lxml:サードパーティ製ライブラリ。処理速度の速さが特徴的。
- html5lib:サードパーティ製ライブラリ。HTML5の文法をサポートしWebブラウザと同様の方法の解釈を行うなど高性能。処理速度は他より劣る。
BeautifulSoupのインストール
BeautifulSoupライブラリをインストールします。
- 私はMacOSを使っているため、「pip3」コマンドを利用します。
- BeautifulSoupの最新バージョンは4.9.1です(2020/05/23現在)。
インタラクティブシェルで以下のコマンドを実行します。
> pip3 install BeautifulSoup4
importできればインストールに成功しています。
bs4はライブラリです。
>>> from bs4 import BeautifulSoup4
BeautifulSoupを使ってWebサイトから情報抽出してみる
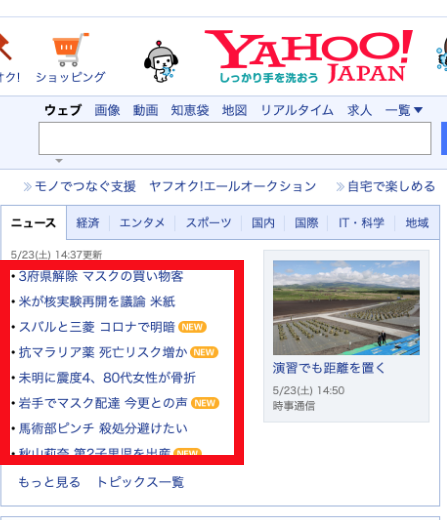
今回は、YAHOO!JAPANのニュース一覧のタイトルとURLを抽出します。
実装すること
- requestsを利用し、サイト情報を取得する。
- BeautifulSoupを利用し、要素を解析する。
- reを利用し、正規表現で項目を取得する。
- ブラウザの開発者ツールから取得対象のタグ構造を特定する。
- 今回は、href属性"news.yahoo.co.jp/pickup"にマッチさせれば取得できる。
- 正規表現を利用するため、標準ライブラリであるreモジュールをimportする。
- 公式ドキュメントを後で確認。
- 取得した項目から、テキスト属性とhref属性を抽出する。
コード
ScrapingSample.py
import requests
from bs4 import BeautifulSoup
import re
url = "https://www.yahoo.co.jp/"
# requetsを使ってサイト情報を取得
result = requests.get(url)
# 要素を解析
bs = BeautifulSoup(result.text, "html.parser")
# リンクが"news.yahoo.co.jp/pickup"にマッチする項目を取得
news_list = bs.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
# 取得した項目からテキスト属性とhref属性を抽出
for news in news_list:
print("{0} , {1}".format(news.getText(), news.get('href')))
実行結果
3府県解除 マスクの買い物客 , https://news.yahoo.co.jp/pickup/6360522
米が核実験再開を議論 米紙 , https://news.yahoo.co.jp/pickup/6360527
スバルと三菱 コロナで明暗NEW , https://news.yahoo.co.jp/pickup/6360528
抗マラリア薬 死亡リスク増かNEW , https://news.yahoo.co.jp/pickup/6360523
未明に震度4、80代女性が骨折 , https://news.yahoo.co.jp/pickup/6360529
岩手でマスク配達 今更との声NEW , https://news.yahoo.co.jp/pickup/6360521
馬術部ピンチ 殺処分避けたい , https://news.yahoo.co.jp/pickup/6360510
秋山莉奈 第2子男児を出産NEW , https://news.yahoo.co.jp/pickup/6360531
「NEW」も抽出されてしまっていますが、不要であればreplaceしてあげれば良いのかなと思っています(今回の実装には含めていません)。
おわりに
簡単な内容でしたが、公式ドキュメントなども読んで、理解の幅を深めて行きたいと思います。