DynamoDBの基礎まとめ ― 書き込み(WCU)検証
ではWCUの挙動を検証してから大分時間が経ちましたが、今回はRCUについてやってみました。
テーブル作成
前回のSampleTableを利用
読み込み(RCU)
DynamoDBはデータ読み取りのために基本三つのアクションを提供しています。
テーブルからデータを読み込む を参考
| アクション | 説明 |
|---|---|
| GetItem | テーブルから単一の項目を取り出します。 |
| Query | 特定のパーティションキーがあるすべての項目を取り出します。 |
| Scan | 指定されたテーブルで、すべての項目を取り出します。 |
それぞれ実行してみます。
PythonでLambda関数
パターン1:GetItemで1レコード読み取り
RCUの課金境界線は4KBなので、それぞれデータサイズ4KB以下と4KB超えの2回実施
| 回数 | userid | updatedatetime | itemid | itemstatus | データ |
|---|---|---|---|---|---|
| 1回目 | U00001 | 2018-04-09 09:02:00 | IT007 | good | レコード全体4KB未満 |
| 2回目 | U00001 | 2018-04-09 09:01:00 | IT006 | 4,938バイトの長い文字列 | レコード全体4KB超え |
import boto3
import logging
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table("SampleTable")
def lambda_handler(event, context):
try:
itemdata = table.get_item(
Key={
"userid" : "U00001",
"updatedatetime" : "2018-04-08 09:01:00"
},
ConsistentRead=True
)
except Exception as e:
logging.error("type : %s", type(e))
logging.error(e)
RCU計算しやすいように、ConsistentReadをTrueにし、DynamoDB はオペレーション時に強い整合性のある読み込みを使用します。
GetItemは1行ずつの読み込みが基本ですので、Keyの条件から「"updatedatetime" : "2018-04-08 09:01:00"」を抜くとThe provided key element does not match the schemaエラーが出ます。
[ERROR] 2018-05-02T06:53:18.565Z caf6a9b7-66fa-11e8-a314-1579052166ad type : <class 'botocore.exceptions.ClientError'>
[ERROR] 2018-05-02T06:53:18.586Z caf6a9b7-66fa-11e8-a314-1579052166ad An error occurred (ValidationException) when calling the GetItem operation: The provided key element does not match the schema
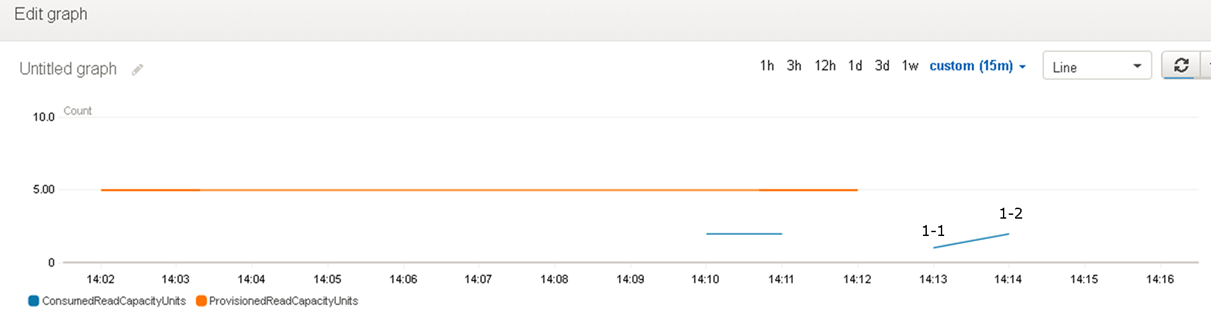
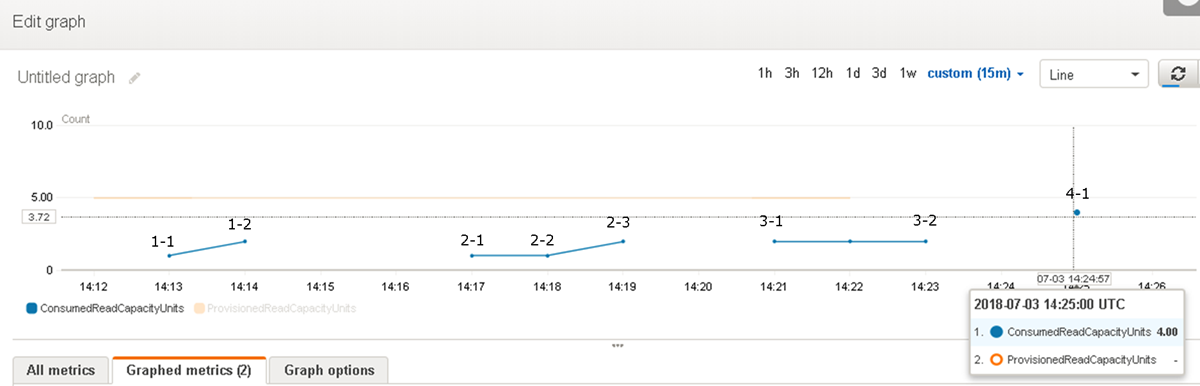
パターン1:CloudWatch結果
1-1は4KB未満で4KB(1RCU)に切り上げ、1-2は4KB超えで8KB(2RCU)に切り上げられました。
パターン2:Queryで1パーティションすべてのレコードを読み取り
| 回数 | userid | データ |
|---|---|---|
| 1回目 | U00003 | 1レコード、データサイズ4KB未満 |
| 2回目 | U00002 | 合計3レコード、データサイズ4KB未満 |
| 3回目 | U00001 | 7レコード、データサイズ4KB超え |
import boto3
import logging
from boto3.dynamodb.conditions import Key
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table("SampleTable")
def lambda_handler(event, context):
try:
itemdata = table.query(
KeyConditionExpression=Key("userid").eq("U00003"),
ConsistentRead=True
)
except Exception as e:
logging.error("type : %s", type(e))
logging.error(e)
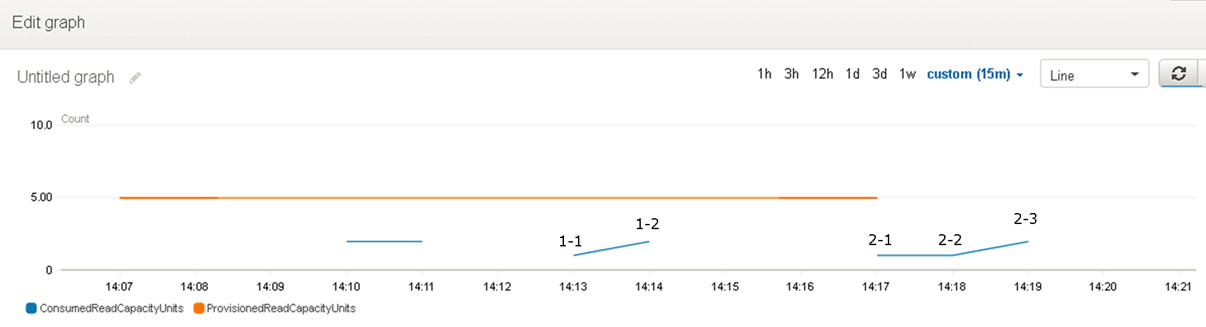
パターン2:CloudWatch結果
読み取りレコード数に関係なく、あくまで合計サイズが4KBまたはその倍数かで切り上げられています。
パターン3:Queryで1パーティションの一部レコード(or 一部項目)取得
| 回数 | userid | 条件 | データ |
|---|---|---|---|
| 1回目 | U00001 | itemid=IT004 | 1レコード、データサイズ4KB未満、パーティションデータサイズ4KB超え |
| 2回目 | U00001 | Select itemid | 合計7レコード、取得項目データサイズ4KB未満、パーティションデータサイズ4KB超え |
import boto3
import logging
from boto3.dynamodb.conditions import Key, Attr
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table("SampleTable")
def lambda_handler(event, context):
try:
itemdata = table.query(
KeyConditionExpression=Key("userid").eq("U00001"),
FilterExpression=Attr("itemid").eq("IT004"),
ConsistentRead=True
)
except Exception as e:
logging.error("type : %s", type(e))
logging.error(e)
import boto3
import logging
from boto3.dynamodb.conditions import Key, Attr
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table("SampleTable")
def lambda_handler(event, context):
try:
itemdata = table.query(
ProjectionExpression="itemid",
KeyConditionExpression=Key("userid").eq("U00001"),
ConsistentRead=True
)
except Exception as e:
logging.error("type : %s", type(e))
logging.error(e)
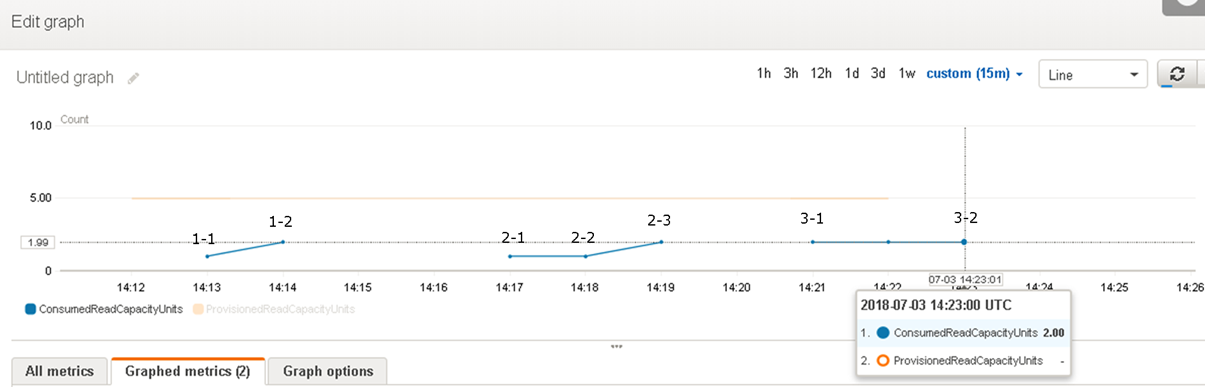
パターン3:CloudWatch結果
3-1でたとえ結果はIT004という1レコードのみがヒットしたとしても、検索範囲(パーティションのサイズ)でRCUが計上されました。3-2も同様、結果が1カラムのみほしいにもかかわらず、RCUは検索範囲(パーティションのサイズ)で計上されます。
パターン4:Scanでテーブル全レコードを読み取り
| 回数 | userid | データ |
|---|---|---|
| 1回目 | すべて | 16レコード、15.33 KB |
 |
import boto3
import logging
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table("SampleTable")
def lambda_handler(event, context):
try:
itemdata = table.scan(
ConsistentRead=True
)
except Exception as e:
logging.error("type : %s", type(e))
logging.error(e)
パターン4:CloudWatch結果
スキャンの場合、テーブルの合計サイズでRCUが計上されます。
考察
WCU時と同様、1レコードのデータサイズを4KB未満(あるいはKBに比例する)に抑えるのがよく、プロビジョニングする際にも読み取りレコード数/秒で算出するので良いです。
すこし勘違いしました。WCUは1レコードずつ(挿入、更新、削除は1レコード単位のため)のサイズを1KB未満(あるいはKBに比例する)に抑えるとよいです。
RCUは基本パーティション単位の読み取りとなるので、
1パーティション=1レコードの場合、4KBを意識すればよいですが、
1パーティションが複数レコードの場合、レコード数も変動となるはずで、4KBという境界線を気にすることがなく、あくまで全体的にデータサイズ(Key、Value)を抑えたテーブル設計を念頭に置けばよいかと思います。
また、テーブルサイズが肥大化すると、Scan時のRCUが膨大になるため、基本Scanは使用しないようにアプリケーション設計が必要です。