アイスタイル Advent Calendar 2017 の 14 日目は、@tanit5699 が kaggleで拾ってきたDatasetsをpythonで可視化してみます。
Kaggle
Kaggle(カグル)とは、データ解析のコンペサイトで、企業や研究者が投稿した課題に対して、世界中のデータサイエンティストがより精度の高い「予測」モデルを競い合う場所になっています。
参加者の提示したモデルは即時に採点され、順位が表示されます。コンペに参加し、上位入賞者には企業や研究者から賞金が用意されていたり、データサイエンティストとして実力をアピールすることができて求人の際に有利になったりします。
企業や研究者が投稿した課題の他、kaggleが用意したチュートリアルチャレンジ、個人が投稿するデータなど、膨大な量のデータが投稿されていますので、それらを用いて学習するのにも最適な場所になっています。
Datasets
今回は、Kaggleが投稿した機械学習エンジニア/データサイエンティストに対する2017年のアンケートのDatasetsを使用します。
データを読み込む
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.cm as cm
%matplotlib inline
data = pd.read_csv('../kaggle/DataScience2017/multipleChoiceResponses.csv', encoding='ISO-8859-1')
print(data.shape)
上記のソースコードを実行すると、下記の結果が返ってきます。
(16716, 228)
読み込んだDatasetsは、16716人からの回答数があり、項目が228個が複数回答のアンケート結果になっています。
この中の項目から二つ選んで、データの可視化と軽い分析をしてみようと思います。
年齢別に回答数をヒストグラムで描画
plt.figure(figsize=(13, 10))
plt.hist(data['Age'].dropna(), bins=50, edgecolor='white')
plt.title("age distribution", fontsize=15)
plt.tick_params(labelsize=15)

20代後半が一番多くなっており、kaggleを利用するデータサイエンティストは全体的に若い人が多いことがわかります。0歳や100歳の回答のような明らかに嘘の回答も混じっています。
国別に回答数を棒グラフで描画
countryData = data['Country'].value_counts()
x = np.arange(len(countryData))
y = countryData.values
plt.figure(figsize=(12, 6))
colors = cm.jet(y /max(y))
plt.xticks(x, countryData.index.values.astype('str'), rotation=90)
plt.ylabel('samples')
plt.bar(x, y, color=colors)
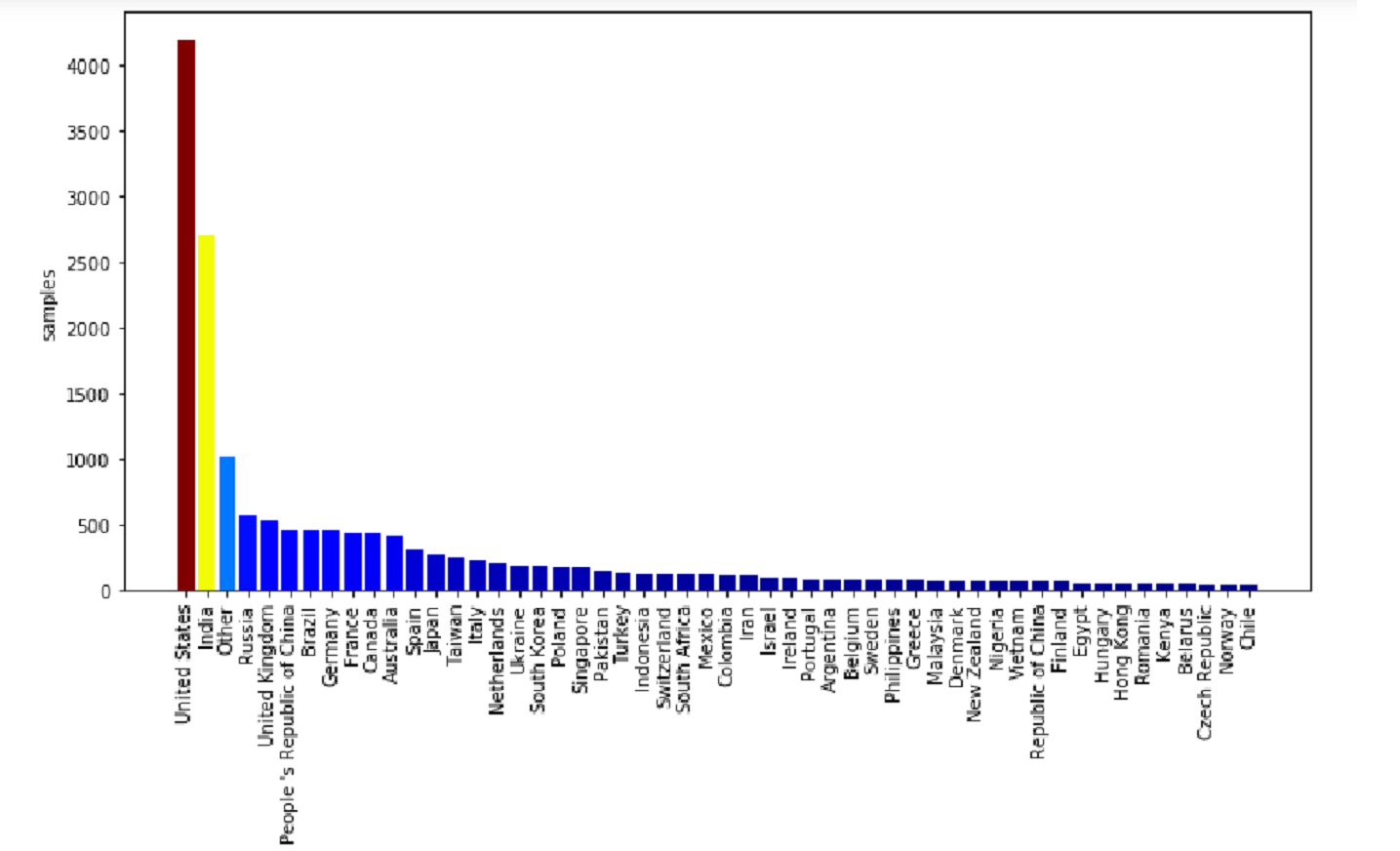
USAとインドの回答者の数が圧倒的に多くなっています。日本は13番目に多いです。ただし、kaggleの利用者は、100万人以上いるそうなので、1万6千人のサンプルで、USAとインドの利用者が多いとは言い切るのはまだ早そうです。
まとめ
今回はアンケートのDatasetsから年齢と国だけ可視化してみました。他にも、給料・使用しているツール・おすすめの言語など興味深い項目がありますので、見てみると面白いと思います。
pythonでは、簡単にデータを可視化できるので、今後、業務にも役立てていこうと思っています。
15日目はYuyaAboさんの「きっかけ」です!