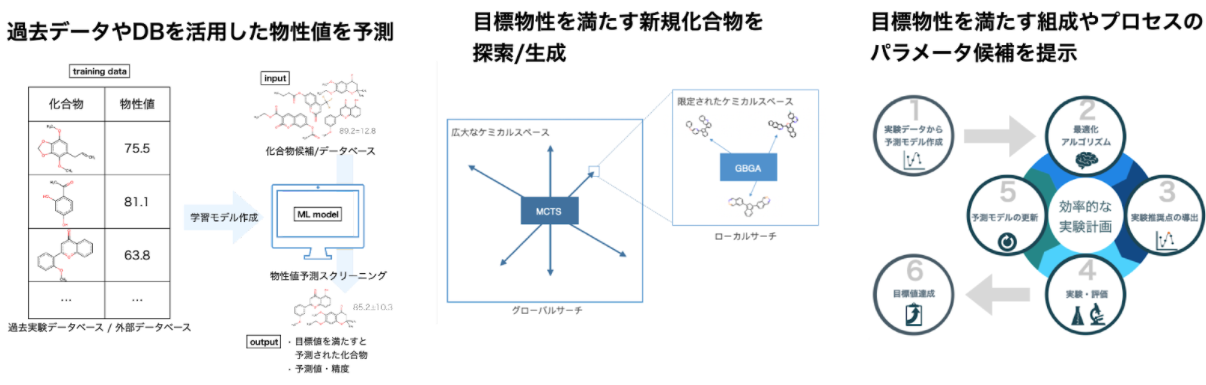
はじめに
こんにちは。MI-6 データサイエンスチームのtanishim006です。本記事では、マテリアルズインフォマティクスでも利用される数理最適化の手法、「ベイズ最適化」の概要についてご紹介します。
ベイズ最適化とは
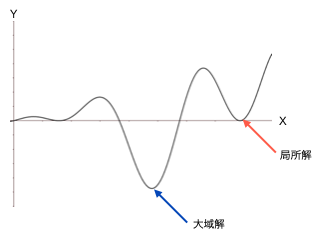
「ベイズ最適化(Bayesian Optimization)」とは、未知の関数 f(x) の大域的な最大値(最小値)を効率的に発見することを考えた際に、次に観測するベストな点を得るための逐次最適化手法です。少数データに対しても有効な手法であることから、特に評価コストが高い関数の最適化に用いられ、機械学習のパラメータチューニングのみならず、実験の配合条件やプロセスの最適化などにも応用されています。なお、評価コストとは時間的コスト、金銭的コスト、機会的コストなどが挙げられます。
材料開発におけるベイズ最適化
材料開発において、ある所望の物性を満たす最適な条件を得るためにさまざまな原料の配合比やプロセスを考慮しなければならないことは少なくありません。
検討対象の原料やプロセスが増えれば増えるほどその組み合わせは膨大となり、網羅的に実験を行うことは現実的ではなくなります。また、実験者の知見は非常に重要ですが、広大な探索空間においてはそれだけで大域解を見出すことは困難です。
このような課題を解決する手法として、ベイズ最適化は注目を集めています。
ベイズ最適化の流れ
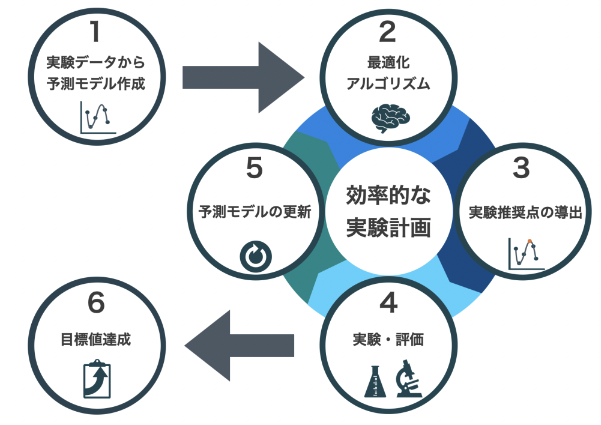
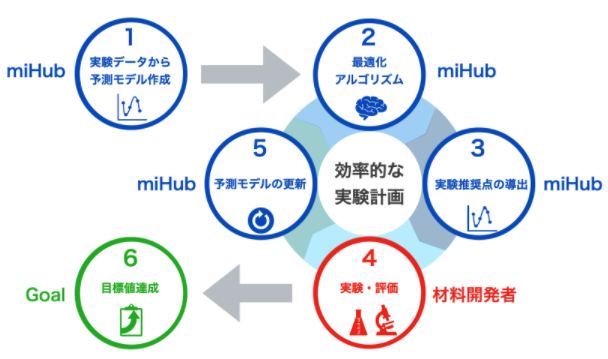
ベイズ最適化では、下記のサイクルを繰り返すことで効率的に目標達成を目指します。
1. 実験データから予測モデルを構築
2. 最適化アルゴリズムを予測モデルに適用
3.最適化アルゴリズムで推奨点を導出
4.推奨点を実験し評価
5.4の結果をもとにモデルの更新
6.1~5 の繰り返し
ガウス過程回帰
一般にベイズ最適化ではガウス過程回帰(Gaussian Process Regression) と呼ばれる回帰手法が用いられます。
ガウス過程回帰は確率論モデルの一種で、予測の不確かさを表現することができます(Fig.3A)。例えば、Fig3 のように4点の学習データからフィッティングを行った際に、右の2点の中間付近のようなデータがない領域では予測が困難になります。確率論モデル、決定論モデル、いずれも予測値を得ることはできますが、その信頼度は高くありません。確率論モデルでは、データ量に依存する予測信頼度の情報を、予測分散の大小で表現することができます。詳細は後述しますが、この不確かさを表現できるという点がベイズ最適化と組み合わせて利用される理由の一つになります。
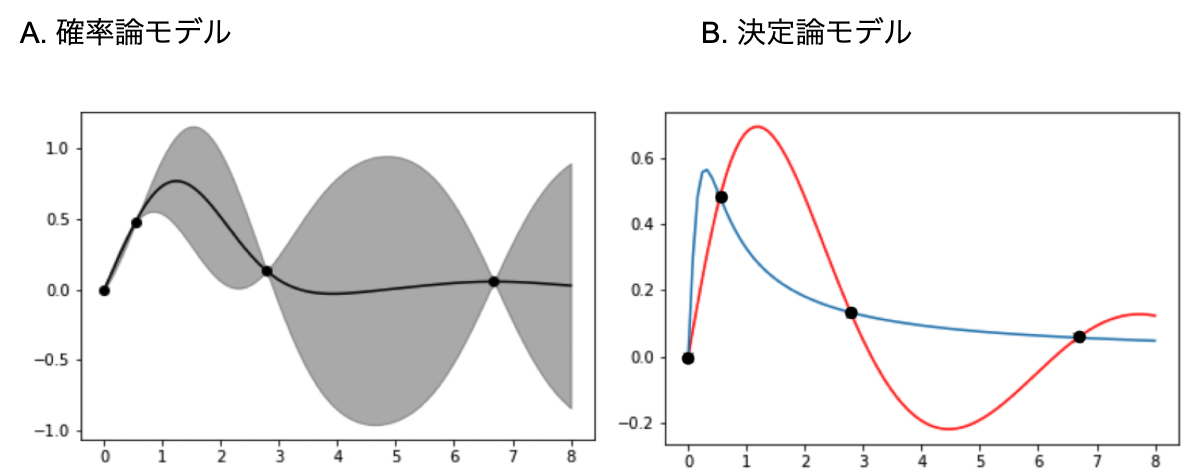
A:確率論的モデル。黒い線でフィッティングしており、灰色の領域が予測の不確かさを表現している。
B:決定論的モデル。あるデータに対し決定論的にフィッティングを行う。
ベイズ最適化による推奨点導出方法
ベイズ最適化では探索と活用という二つのトレードオフを考慮して次に観測すべき点を導きます。
- 探索
今までに経験がない(不確かさの大きい)点に挑戦する - 活用
既に経験のある(不確かさの小さい)中で良いとわかっている情報を利用する
探索のみでは蓄積した情報を生かすことができず、活用のみでは局所的な観測に留まり全く新規の知見を得ることができません。
そのため、これら二つのパラメータを同時に考慮することが重要になります。
具体的には、ある点の予測期待値と予測分散から、その点を観測することの「良さ」を評価する獲得関数と呼ばれる関数を用います。
ここから、ベイズ最適化を用いて推奨点が導出される過程をご説明します。
-
観測データを用意
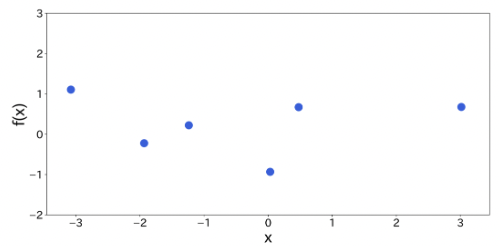
-
観測データから予測モデルを構築
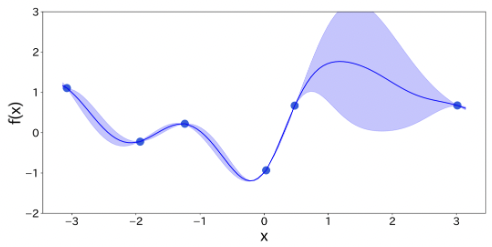
-
予測期待値と予測分散から次の観測点を取得( 緑:活用的な点、橙:探索的な点、赤:推奨点)
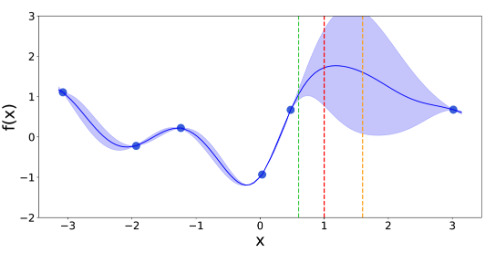
-
推奨点を観測し、モデルを更新
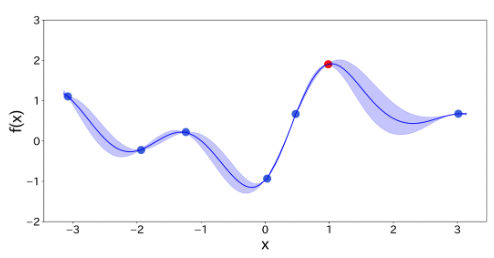
miHub

MI-6 では、データの可視化、モデルの構築、ベイズ最適化による実験推奨点の導出をブラウザ上で行うことができる「miHub」 というSaaS プロダクトを提供しています。
また、ソフトウェアによるソリューションだけではなく、MIの導入や技術的な支援も提供しております。
おわりに
本記事ではベイズ最適化についてご紹介しましたが、MI-6 では、目的に応じた技術を用い、材料開発ならではの様々な課題解決に取り組んでいます。そして、困難な課題を如何にして解くかを考え抜くこともMI-6 で働く醍醐味の一つです。MI-6では、データサイエンスを駆使して材料開発の支援を行う仲間を幅広く募集していますので、この記事を読んで少しでも興味をお持ちになりましたらぜひご連絡ください!