Nextremer Advent Calendar 2017 の20日目の記事です。
かなり昔に Chord Worker という、コード(和音; Chord)を弾きながら次のコードをリアルタイムにサジェストするという Web アプリを開発していました(なお、Nextremer とは全く関係のない個人プロジェクトです)。開発当時は、ディープラーニングブームに火がつく前で、この Web アプリではマルコフモデルにもとづいてコードをサジェストするという方法をとっていました。
時代の波に乗るべく、本記事では、Chord Worker のコードサジェスチョン部を(ディープ)ニューラルネットに置き換えようと、いろいろ開発・実験を行っているというお話をします。ニューラルネットのモデルは Chainer を使って実装します。
類似事例
学術研究はサーベイできていないのですが、Qiita を探しただけでもこれらの記事が見つかります。
ここでも使用する要素技術は基本的に同じです(なので、本記事の意義はあまりないかもしれません)。ただし、今回の記事では触れませんが、Chord Worker では、ユーザが演奏しつつ、アプリ側でコードをサジェストしていかなければならないため、ニューラルネットによる推論をできるだけ早く行うこと(実時間性)が重視されます。単純に思いつく解決法としては、ニューラルネットのサイズを小さくして、計算量を減らすなどが挙げられます。また、推論をクライアント側で行うか、サーバ側で行うかでも、制約条件は変わってくると思います。この辺は別途検討する予定です。
データ収集
楽器.me から、コード進行を収集しました。収集期間は 2017/09/22 〜 12/18 の約3ヶ月間で、収集した曲数は全部で799曲になります。できるだけ人気の曲を収集するために、ランキングに登場した曲のみを収集していたのですが、想定よりランキングの入れ替えがそれほどなく、なかなか曲が集まりませんでした。本来は総当りでクロールしたあとに、学習データセットとして使用する曲を選定すべきだと思います。
Web ページからコードを抽出して、1曲1行でコードを半角スペース区切りにしたテキストファイルを作成しました。イメージは次のような感じです。
E♭ Fm7 Gm7 A♭ G Cm7 Fm7 B♭ A♭onB♭ B♭ E♭ Fm7 Gm7
D F#m7 Bm F#m7 GM7 F#m G AonG F#m7 Bm7 E7 A7
...
データの前処理
学習を行う前に、モデルの性能を高めるために、データを綺麗にしておく必要があります。ここでは、次の2つの処理を行いました。
- コード表記の正規化
- 調の正規化
これらの詳細を説明します。
コード表記の正規化
楽器.me では、ほとんどコードの表記は統一されていましたが、Cm9 と Cm7(9) のように、統一されていない表記が一部存在していたので、それらを正規化しました。
表記正規化後のコードのリストは、ここにあります。
調の正規化
調によってコードの性質は異なるため、あらゆる曲、あらゆる調のコード進行をそのまま学習するとうまくいかない可能性が高いです。そこで、あらかじめすべての曲を C 調 / Am 調に移調することとしました。
今回は完全自動による調の正規化を試みました。正規化のルールは次の通りです。
- 曲全体のコード進行を、他の11個の調に移調する
- 12個の調の中でもっとも C 調 / Am 調に含まれるコードが多いものを正規化後のコード進行とする
例えば、次のコード進行について考えてみます。
Aadd9 DM7 E7 F#m9 Bm9 Bb7(b9) Aadd9
+1 移調してみると次のようになります。これは、C 調 / Am 調に存在するコードが1つもありません。
Bbadd9 EbM7 F7 Gm9 Cm9 Cb7(b9) Bbadd9
では +3 移調してみると、7つ中6つのコードが C 調 / Am 調に含まれます。この移調のとき、12の調の中でもっとも C 調 / Am 調のコードが多くなります。したがって、これを正規化後のコード進行とします。
Cadd9 FM7 G7 Am9 Dm9 Db7(b9) Cadd9
// Db7(b9) だけ C 調 / Am 調のコードではない
このような方法で12個の調に書き直して、どれが一番 C 調 / Am 調にふさわしいかを探っていきます。
これで OK かというと、そういうわけでもありません。この方法では、曲全体に対して調の正規化が行うことを前提としているので、曲の途中で完全転調するコード進行に対応できません。
完全転調してしまうと、転調後は他調のコード進行を学習していることになるため、本セクション冒頭に書いたように良くない状態です。回避策として、完全転調を考慮した正規化も検討しましたが、今回は時間がなかったので、とりあえず次の方法で雑に対応したいと思います。
- 調の正規化後、C 調 / Am 調に存在するコードの使用頻度が 70% 未満の曲はデータセットから除外する
70% という基準はデータを見ながら適当に決めた値です。このフィルターにより、データ数が799 → 721曲に減りました。ただでさえ少ないデータがさらに少なくなってしまいますが、とりあえず今回はこのまま進みます。
また実際には、近親調のコード進行もいくつか C 調 / Am 調と判定されており、この方法は微妙でした…。特に G 調が比較的多く引っかかっていたことから、ハーモニックマイナー、メロディックマイナーのコードも OK としてしまったのが悪影響を与えていると考えられます。とはいえ、これらを完全に防ぐのは無理なので、無視します。
# 良い例(C 調 / Am 調のコードとして使用できる)
C Em7 F Fm C Em7 F G7 G7 C Em7 Am7 Em7 C Em7 F G7 F G7 F C Am7 Dm7 G7 F G7 C C Em7 Am7 Em7 C Em7 F G7 F G7 F C … 略 …
Am Dm7 Dm7/G CM7 Am7 Dm7 G7 CM7 E7 Am Dm7 E7 Am E7 Am Dm7 E7 Am E7 Am AmM7 Am7 G FM7 E7 Am … 略 …
# 悪い例(C調 / Am 調のコードとしてはふさわしくない)
G 調
G D C G D C G D C G D C C C G D C G D C G D C G D C G D C G D C G D C G D C G C Am7 Bm7 C Bm7 Am7 Bm7 C D G … 略 …
F 調 // シャープ表記が気持ち悪い・・・
Am A#M7 C F E Am A#M7 C F E Am A#M7 C F E Am A#/C F E Am A#M7 C F E Am A#/C F E Am Gm7 FM7 E Am C7 F Am C7 FM7(9) … 略 …
# フィルターにより除外された例
曲の途中で完全転調
C FM7 G E/G# Am7 Dm7 Dφ G G C G/B Am7 FM7 G C … 略 … Dm7 Dm7/G G G# C# F# G# F7 A#m7 D#m7 F#M7 C# … 略 …
学習
ニューラルネットの構築、学習には Chainer を使いました。モデルは Embedding → 2層 LSTM → Linear (→ Softmax) という構成です。Embedding 次元数、LSTM ユニット数は [128, 256, 512] の3種類を試しました。その他のハイパーパラメータは次の通りです。
- 最適化アルゴリズム: Adam(パラメータは Chainer のデフォルト)
- ドロップアウト: 50%
- Gradient clipping: 5
また、学習は、721曲のデータを training 650曲 (90%)、validation 72曲 (10%) に分割して行いました。各コード進行には開始記号 <s> と終端記号 </s> を付与した上でモデルに入力しました。
ニューラルネットのソースコードはこちらにあります。
https://github.com/tanikawa04/chord-suggester
結果
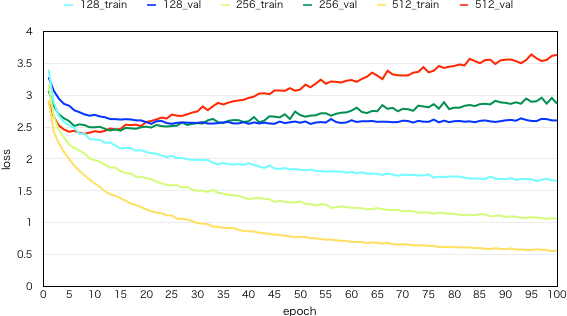
先述のモデルをそれぞれ、100 epoch まで学習させたときの training と validation の loss (per chord) は次の図の通りになりました(が、データセットが小規模ということもあり、現状何とも言えません…)。パラメータチューニング等いろいろと工夫することにより、さらに loss が下がる余地はあると思います。
コード進行の生成
validation loss がもっとも低かった、次元数 512 epoch 8 のモデル (val loss = 2.396) を使ってコード進行を生成してみました。
まずは、開始記号 <s> だけを与えて、あとは Softmax の出力からサンプリングして、16小節のコード進行を生成してみます。
1.
C Em Am F Em Dm7 G C Am Em F G C G C C
2.
C/E F G C/E F G D7 G C/E F G C/E F G Am C
3.
G G#aug A D G Gaug D#dim Bm F#m/A G C G Em C G G
4.
Gaug C D Bm Em C D D D G D C D D D F#
何度か試してみましたが、大半は 1 や 2 のようなコード進行が生成されました。まあまあ良さそうですが、C 調 / Am 調のダイアトニックコードがほとんどなので面白みがあまりないような気もします。3 は不思議なコード進行です。4 はどちらかというと G 調のコード進行っぽい感じがします。
定番進行を予測してみる
Chord Worker では、完璧なコード進行を生成するというより、次に進行するコードの候補を良い感じにいくつかサジェストできることが重要です。そこで、特定のコード進行に続く次のコードを予測するタスクについても検証してみました。モデルは、先ほどと同じものを使用しました。
1. ポップスでよく使われる 4536 進行
F G Em [ ? ]
正解 *:
Am
ニューラルネットの出力 上位10個:
Am 0.883977
F 0.0316056
C 0.0165342
E 0.0103408
Dm 0.0100925
A 0.00976508
G 0.00507439
Am7 0.0050501
D 0.00274232
Em 0.00262847
* 「正解」と書いていますが、実際にはいろいろなコードが考えられます
うまくいっています。Am の確率がかなり高いです。
2. カノン進行
C G Am Em F C F [ ? ]
正解:
G
ニューラルネットの出力 上位10個:
G 0.554789
C 0.282795
Em 0.0381741
F 0.0189741
Gsus4 0.0144331
Am 0.0141817
Dm 0.0101137
D 0.00835111
D7 0.00831824
C/E 0.00705262
こちらもうまくいっているようです。
3. ベース半音下降進行
Am G#aug C/G [ ? ]
正解:
F#φ
ニューラルネットの出力 上位10個:
F#φ 0.604325
D/F# 0.213807
Am6 0.023317
C/G 0.0171608
G 0.016939
FM7 0.0137234
F 0.0115972
D7 0.0100939
Dm 0.0071109
A 0.00596148
普通に予測できていてびっくりしました。F#φ, D/F#, Am6 が上位3つなので、ファ♯の重要性を理解できているっぽいです。
このように、定番進行なら結構的確に予測してくれそうです。
おわりに
コードを予測するニューラルネットを構築しました。想定よりもいい感じにコード進行を予測できました。個人的には、ダイアトニックコードばかり出てくるのが物足りない気もしていますが、データセットを変えて複数のモデル(eg. ポップスモデル、ジャズモデル、…)を作るなどすれば良いかなと思っています。精度自体もいろいろと改善の余地はあると思います(データ数、調の正規化、モデルの調整など)。
現状、下調べレベルなので、早いところ本格的に Web アプリ化を目指して開発を進めたいです。