スクラムサインの反甫です。この記事はスクラムサインでのインターン活動で学習を目的として、DCASE2020にて行われたTask6に挑戦した記録のまとめです。
なお、このタスクに挑戦するにあたって、コンペ参加者のYusong Wuさんの手法を使わせていただいています。手法を詳しく知りたい方はテクニカルレポートまたはプログラムを確認してください。
タスクで使用したプログラムはこちら
タスクについて
このタスクでは、音声データを入力として、その音声データのキャプションをテキストでの自動生成を行います。
環境
Googleコラボでの実装を想定しています。キャプションをベクトルに変換する際に使うgensimのバージョンがGoogleコラボにデフォルトでインストールされているバージョンでは対応していない部分がありますので、以下のコードを実行して最新版にアップデートしてください。
pip install --upgrade gensim
使用するデータについて
IEEE ICASSP 2020で提供されるClothoデータセットを使用します。
提供されるデータは15秒〜30秒の音声データと、各音声データにつき8単語〜20単語で構成された5種類のキャプションがあります。
4981の音声データと24905のキャプションデータがあり、開発用60%、評価用20%、テスト用20%に分割されます。
なお、Clothoデータセットには4365単語が使われており、開発用データセットにすべての単語が含まれているため、評価用またはテスト用データセットでしか使われていない単語はありません。
データセットは以下のリンクから4つのファイルをダウンロードしてください。
開発用音声データ:clotho_audio_development.7z
開発用キャプションデータ:clotho_captions_development.csv
評価用音声データ:clotho_audio_evaluation.7z
評価用キャプションデータ:clotho_captions_evaluation.csv
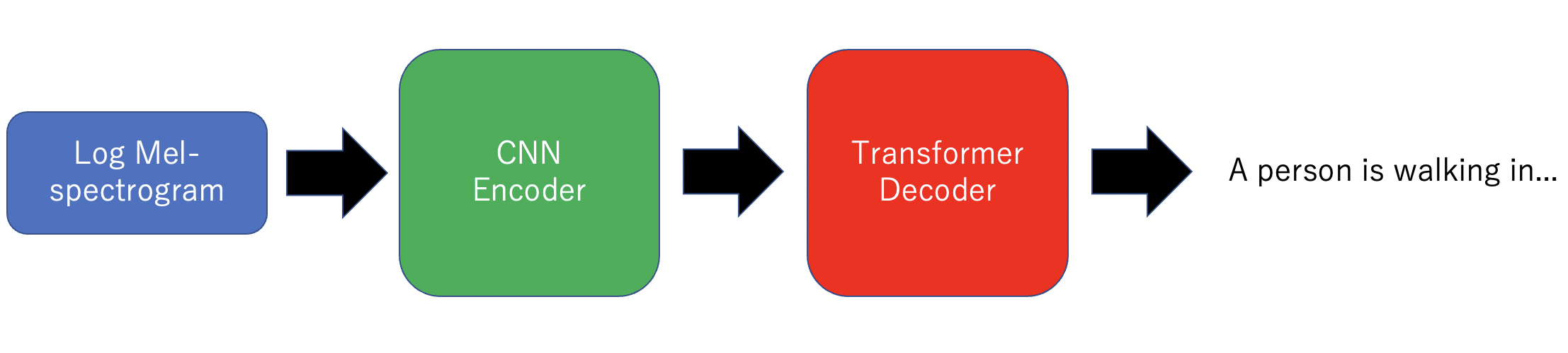
モデルの概要
モデルはエンコーダとしてのCNNとデコーダとしてのTransformerで構成されています。ログメルスペクトログラムをエンコーダに入力し、キャプションを生成します。
学習は3回に分けて行われます。まず最初に、データ不足を補うためにエンコーダCNNの事前学習行います。次に、CNNエンコーダのパラメータを固定して学習を行い、最後に学習率を低くしてすべてのパラメータを更新するファンチューニングを行います。

エンコーダCNNの事前学習
エンコーダCNNの事前学習では、入力をログメルスペクトログラムとして、入力した音声データのキャプションに含まれる複数の単語を予測する、マルチラベル分類を行います。
CNNは4つのブロックと2層の全結合層で構成されており、各ブロックには3×3の畳み込み層、Relu活性化関数、バッチノーマリゼーション層、2×2のアベレージプーリング層が含まれています。
データの前処理
CNNエンコーダの事前学習では開発用データセットを使います。
予測する単語の選出
- 開発用キャプションデータセットに含まれる出現頻度が上位20位の単語を除く
- 2文字以下の単語を除く
- "s", "ly", "ing"などを取り除くステミングを行い語幹に変換する
- 1〜3の処理を行なったあとの頻出単語上位300個の単語を予測する単語として使う
教師データの作成
- 各音声データに対応する5つのキャプションを重複を許さない単語の集合にする
- 単語の集合から上記の処理で選出した上位300個の単語のみを残す
- 残った単語から各インデックスが300個の単語に対応するマルチワンホットベクトルを作成し、教師データとして使う
音声データの前処理
- 全ての音声データを1番短い15秒にそろえる
- librosa 0.8.1 を用いて音声データをメルスペクトログラムに変換する
以上で事前学習で使うデータの前処理は完了です。
学習
以下の条件で学習を行います。
クラス数:300
学習率:1e-3
バッチサイズ:16
エポック:60
損失関数:バイナリ交差エントロピー
最適化アルゴリズム:Adam
結果
以下が学習結果です。1エポック目から60エポック目までtrain、test共に損失が順調に減少しています。
epoch:1 trainloss:0.191097 testloss:0.175619
epoch:10 trainloss:0.159588 testloss:0.157775
epoch:20 trainloss:0.151603 testloss:0.149042
epoch:30 trainloss:0.145857 testloss:0.143931
epoch:40 trainloss:0.141565 testloss:0.136728
epoch:50 trainloss:0.138008 testloss:0.133549
epoch:60 trainloss:0.134164 testloss:0.129831
CNN + Transformerの学習
事前学習させたCNNの出力をpytorchで提供されているTransformerDecoderに入力します。
今回はCNNのパラメータを固定した状態で学習を行います。
学習
以下の条件で学習を行います。
学習率:3e-4
バッチサイズ:16
エポック:100
損失関数:交差エントロピー
最適化関数:Adam
L2正則化:λ=1e-6
ラベルスムーシング:ε = 0.1
結果
以下が学習結果です。損失はバッチごとの損失の平均を計算しています。trainとtestとの損失の差が大きくなる結果となりました。
1epoch train mean loss : 5.226716177125947 test mean loss 7.841926097869873
10epoch train mean loss : 3.739801677718627 test mean loss 9.185269355773926
20epoch train mean loss : 3.2899816930294037 test mean loss 9.473353385925293
30epoch train mean loss : 2.999895176265092 test mean loss 9.60256290435791
40epoch train mean loss : 2.805177899588526 test mean loss 10.100188255310059
50epoch train mean loss : 2.6505848754823735 test mean loss 10.10529899597168
60epoch train mean loss : 2.565974382436381 test mean loss 10.014985084533691
70epoch train mean loss : 2.4416530115150774 test mean loss 10.202888488769531
80epoch train mean loss : 2.36368575573495 test mean loss 10.414170265197754
90epoch train mean loss : 2.3168762252394077 test mean loss 10.309037208557129
100epoch train mean loss : 2.336798207158536 test mean loss 10.409688949584961
ファインチューニング
ファインチューニングでは学習率を変更し、CNNのパラメータを固定せずに学習します。
学習率:1e-4
バッチサイズ:16
エポック:20
損失関数:交差エントロピー
最適化関数:Adam
L2正則化:λ=1e-6
ラベルスムーシング:ε = 0.1
結果
以下が学習結果です。前回の学習時と変わらず、trainとtestの損失の差が大きい結果となりました。
1epoch train mean loss : 2.2561808566076564 test mean loss 10.239677429199219
10epoch train mean loss : 2.1242637080428874 test mean loss 10.487401008605957
20epoch train mean loss : 2.082565786959851 test mean loss 10.690967559814453
評価
生成したキャプションのBLEUでの評価です。
最高値の出力文では「creatures」や「birds are singing」など参照文にある文と似ている文を出力していることがわかります。
最高値
BLEU:0.29022661152914203
出力文
creatures are squawking and cawing with other birds are singing in the background and a gentle breeze is blowing
参照文
a car starts quiet and gets louder then quiet again with birds tweeting in background
最低値
BLEU:0
出力文
creatures are making noises and insects are buzzing sound while birds are making noises are chirping noises are buzzing
参照文
a fork being banged onto a drinking glass
平均値
BLEU:0.030597722660226864
| BLEU | |
|---|---|
| ベースライン | 0.000 |
| 参考モデル | 0.141 |
| 実装モデル | 0.030 |
まとめ
今回はインターン活動としてDCASE2020のTask6にYusong Wuさんの手法を使って挑戦してみました。結果としては、ベースラインは超えることができましたが、参考にした手法のスコアにはとどきませんでした。テクニカルレポートをできるだけ再現はしましたが、データの前処理などの情報が得られなかった部分は自分で実装しましたので、そこに原因があるのではないかと考えられます。
最後に
最後に初めて論文などの資料を参考に実装に挑戦しようとしている方へのアドバイスです。論文の内容を実装することはとても難しいです。1から10まで実装に必要なことが全て書かれているわけではなく、環境構築、理解できないプログラム、謎のエラー、計算リソースの不足など、多くの障害があります。私は妥協したり違う手段を使って対処してきましたが、それらが正しい対処方法かは分かりません。今回は学習を目的として挑戦しましたが、結果が求められる状況で今回のように良い結果が出ないかもしれません。しかし、自分よりはるかに優れた方の論文やプログラムを熟読することで、作者の意図がわかることがあります。そして、その経験は次に活かすことができますので、結果が出ないかもしれませんが、挑戦する意味は十分にありますので頑張ってください。