はじめに
普段はUbuntuでGPUを使っていますが、MacでもGPUで計算したくなりました。eGPUの存在を知ったので、セットアップしてみた。
注意
- PCの画像出力をGPU経由で行うようにできていませんが気にしていません。
- 以下の手順ではホットスタートできるようにはなりませんでした。
- GPU1枚で遊ぶので、ncclは入れていません。
環境
- MacBook Pro 2017
- High Sierra 10.13.2 (10.13.6よりあとでは動かないらしいので要ダウングレード)
- GTX1080 ti (ZTGTX1080Ti-11GD5MIN)
- Razor Core X
- Nvidia Web Driver (378.10.10.10.25.102)
- CUDA 10.0 (V10.0.130)
- cuDNN 7.3
- anaconda3-5.0.1 (pyenv)
- PyTorch 1.0
- Apple LLVM version 9.0.0 (clang-900.0.37)
後日メモ
CUDAのバージョンの確認
cat /usr/local/cuda/version.txt
eGPUのセットアップ
SIPをオフにする
最近のMacOSには、System Integrity Protection(SIP)なるセキュリティー保持のための機能が追加されましたが、eGPUのセットアップの段階では妨げになるのでOFFにします。
リカバリーモードで起動
電源ボタンを押した後、りんごマークとともにロードしてるっぽいブート画面に入る前から、Commandキー(⌘)とRキーを押下しておきます。
ユーティリティー > ターミナル
を選択した後、
$ csrutil disable
を入力します。
場合によっては、言語の選択画面が出てきますが、日本語を選ばなくても特に問題ないです。
再起動する
ターミナル画面のままで、
$ reboot
を入力すればmacOSが再起動します。
macOS-eGPU.shを実行する
macOSはオフィシャルではGTX系のGPUをサポートしていません。困ったものですが、GTX系のGPUを使ったeGPUを使いたい人のために、セットアップスクリプトがいくらか公開されています。
「This script is not applicable to High Sierra.」を見落して、うまくいかないほうで一度スクリプトを回しきりましたが、案の定失敗しました。知らないふりをしてその上からmacOS-eGPU.shを実行してみたら、GPUが認識されるようになっていました。
$ bash <(curl -s https://raw.githubusercontent.com/learex/macOS-eGPU/master/macOS-eGPU.sh)
これだけでできるすごいスクリプト。ここにも書いてありますが、必ずバックアップを取りましょう(自戒)。それぞれの作業環境によって、うまくいかないどころかいろいろ吹き飛ぶ可能性は否定出来ないですからね。
GPUが認識されたことを確認する
Apple メニュー () > システム情報
から、
ハードウェア > グラフィックス/ディスプレイ
を選択し、ビデオカードのリストに自分のGPUが表示されているかを見ます。
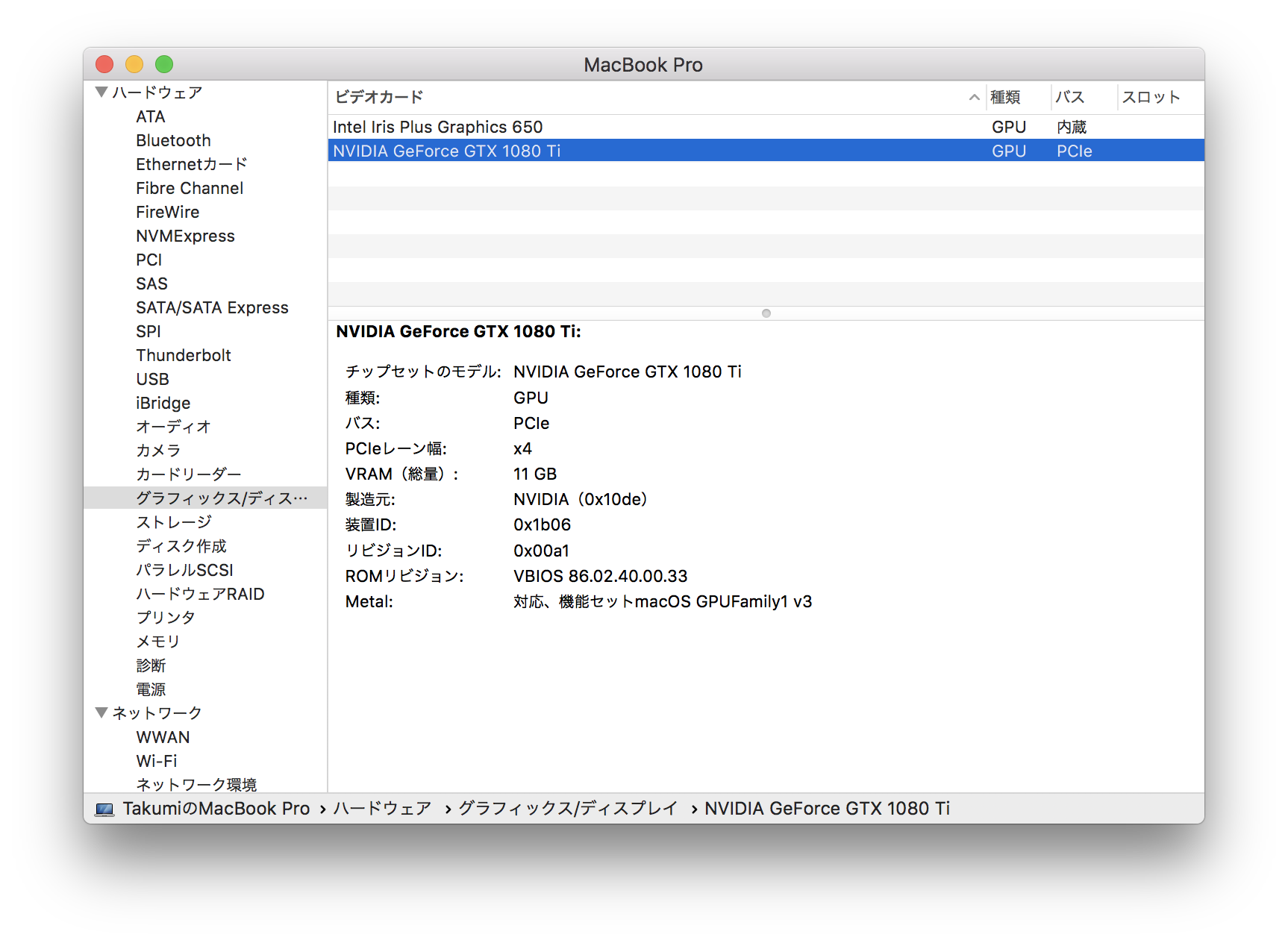
ちなみに、「システム情報」は、Appleメニューを開いた状態でoptionボタンを押すと表示されます。
PyTorchのセットアップ
Nvidia Driver Managerをインストールする
必要なのかわかりませんが、一応入れました。
このスクリプトを使いました。すごくあっさり終わります。
CUDAをインストールする
GPUとの情報のやり取りにはCUDA(Compute Unified Device Architecture)を使います。ここではv10.0を使います。dmgファイルを公式からダウンロードしてインストールする方法もありますが、何故かうまく行きませんでした。オフィシャルのドキュメント上にはありませんでしたが、homebrewでCUDAをインストールすることにします。
以下の3つは試して失敗した例です。失敗とは、PyTorchのビルドが途中で止まるケースのことです。
- CUDA9.2(dmg local) + cuDNN7.4.1
- CUDA9.0(dmg local) + cuDNN7.4.1
- CUDA10.0(dmg local) + cuDNN7.3.0
まずはcaskをインストールします(私はすでに入っていたのでやってません)
xcode-select --install
brew uninstall --force brew-cask; brew update
brew tap caskroom/cask
次にCUDAをインストールします(こっちはやりました)
brew upgrade
brew install coreutils
brew install swig
brew install bazel
# brew cask install cuda の代わりに下記
brew tap caskroom/drivers
brew cask install nvidia-cuda
上記caskインストール〜CUDAインストールはこちらを参考にしました。ありがとうございました。
うまく行っていることの確認
この段階でCuPyはインストールできました。上記リンクから試してみると安心できます。
もしかすると、Xcode Command Line Toolsのダウングレードが必要かもしれません。
cuDNNをインストールする
cudnn.h、libcudnn_static.a等各ファイルを特定の場所にコピーすることでインストールします。オフィシャルのドキュメントは、CUDA9.0+cuDNN7系で表記してありますが、参考になります。
まずは、インストールしたCUDA10.0に対応したcuDNNを、ここからダウンロードします。アカウントがなければ作成しましょう。以下は、「cudnn-10.0-osx-x64-v7.3.0.29.tgz」をダウンロードして実行しました。
$ tar xzvf cudnn-10.0-osx-x64-v7.3.0.29.tgz
解凍できたら、
$ sudo cp cuda/include/cudnn.h /usr/local/cuda/include
$ sudo cp cuda/lib/libcudnn* /usr/local/cuda/lib
$ sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib/libcudnn*
これで適切なディレクトリにコピーできました。
PyTorchをビルドする
PyTorchは、macOS向けのGPUを使えるwheelを提供していません。仕方ないのでソースからビルドします。手順はここにあります。pipでも通るかもしれませんが、オフィシャルがcondaを推奨しているのでcondaでがんばります。私は、pyenvでanacondaを準備しました。
$ git clone --recursive https://github.com/pytorch/pytorch
でレポジトリをクローンした後、
$ export CMAKE_PREFIX_PATH=`which anaconda`
$ conda install numpy pyyaml mkl mkl-include setuptools cmake cffi typing
で必要なライブラリをインストールし、
$ MACOSX_DEPLOYMENT_TARGET=10.13 CC=clang CXX=clang++ python setup.py install
で実行します。
ちなみに、anaconda root directoryは
$ which anaconda
で確認できます。あとは数時間待機します。
ビルド終了直後にREPLから実行しようとしたところ、何故かCUDAが有効じゃない旨のエラーを吐きましたが、ターミナルを落としてもう一度立ち上げ直して実行したところうまくできていました。ちゃんと動くかの確認は
>>> import torch
>>> a = torch.tensor(1)
>>> a.to("cuda")
tensor(1, device='cuda:0')
で十分でしょうか。
その他
問題点がいろいろあります。
- thunderbolt3ケーブルを抜くとOSが落ちる。
- (私の環境では)GPU経由で画面を出力できない。
- 有効に使うためには、ブート画面表示時にthunderboltで繋がなければいけない。
- brewでインストールできるCUDAのバージョンはその時々で変わる。
- nvidia-smi的なものがない。
一応MNIST回しました
このサンプルコードを使いました。
- GPU : 75.07196378707886秒
- CPU : 392.6573271751404秒
期待したほど早くなかったです。Thunderbolt3の通信速度が40Gbpsなのに対して、PCIe x16が128Gbpsであるのがボトルネックかと思うので、トレーニングデータもGPUに全部のせてGPUだけで計算を行えばだいぶ早くなるのか・・・?