「入門 機械学習による異常検知」はRで書かれた異常検知の本です。
今回は実装部分をpythonで書き直していこうと思います。
個人的な勉強のメモ書きとなります。
1章当たりのボリュームが多く、数式もかなりあるためうまくまとまっていません。
数式が多いと編集する際に重く動かなくなるので、「まとめる」というよりは抜粋してボリュームを小さくしています。
実装もうまくいかない部分があり信用せずに見ていただければと思います。
また、schikit-learnなどで関数が提供されていれば使っています。
導出や詳細などは「入門 機械学習による異常検知」を読んでいただければと思います。
前回
不要な次元を含むデータからの異常検知
1. 入出力がある場合の異常検知の考え方
- 系は、入力$\boldsymbol{x}$が与えられたときに、値$f(\boldsymbol{x})$を出力として返すように設計されている
- したがって、ある任意の観測値$\boldsymbol{x}'$が与えられたときに期待される出力値は$f(\boldsymbol{x}')$である
- もし、出力の実測値$y'$が、期待値$f(\boldsymbol{x}')$と大幅にずれていたら異常を疑う
例えば、次のようなモデルを設定できる。
p(y|\boldsymbol{x})=N(y|f(\boldsymbol{x}),\sigma^2)
実際の観測値は、期待値$f(\boldsymbol{x})$の周りに、分散$\sigma^2$の正規分布でばらつくと考える。
問題は、関数$f$およびパラメータ$\sigma^2$をどうデータから学習するか、という点である。これは、任意の入力$\boldsymbol{x}$に対してその出力$y$の確率分布を求める問題である。この問題を、回帰問題と呼ぶ。
異常検知の手順は次の通りになる。
- 準備: 系の機構ないし動作についての事前知識を基に、入力と出力の間に成り立つであろう関数系$y=f(\boldsymbol{x})$を、なにかのパラメータを含んだ形で仮定しておく。また、出力値のばらつきについての事前知識を基に、適切な観測モデルを仮定しておく。
- ステップ1(分布推定): データ$D$を基に回帰問題を解き、関数$f$のパラメータを求める。それにより、任意の$\boldsymbol{x}$が与えられたときの、$y$の予測分布$p(y|\boldsymbol{x},D)$を求める
- ステップ2(異常度の定義): 典型的には、予測分布を基に、新たに観測された1点$(y',\boldsymbol{x}')$に対する負の対数尤度$-\ln p(y'|\boldsymbol{x}',D')$を異常度とする
- ステップ3(閾値の設定): 可能なら異常度についての確率分布を用いて、それが難しければ訓練データに基づく分位点の情報を使って、適切な閾値を与え、異常を判定する
3. リッジ回帰モデルと異常検知
リッジ回帰の解
変数の間に近似的にせよなにか線形の関係式がある場合、行列$\tilde{X}\tilde{X}^T$の階数$M$より小さくなり、ゼロ固有値が生じる。
固有値がゼロにならないように対角要素に小さな数を足すことでこれを防ぐ。
最小二乗法の解の代わりに
\hat{\boldsymbol{\alpha}}_{ridge}=[\tilde{X}\tilde{X}^T+\lambda I_M]^{-1}\tilde{X}\tilde{\boldsymbol{y}}_N
を使うことで問題が解決される。$\lambda$はある定数、$I_M$は$M$次元の単位行列である。
これで多重共線性があってもつねに解が計算可能となる。この式で推定するモデルをリッジ回帰と呼ぶ。
この解は、最適化問題
|\tilde{\boldsymbol{y}}_N-\tilde{X}^T\boldsymbol{\alpha}|^2+\lambda\boldsymbol{\alpha}^T\boldsymbol{\alpha}→最小
の解になっている。
第2項は$\boldsymbol{\alpha}$の要素が極端に大きくなることを防ぐ罰則項のような働きをしていると解釈できる。
このような付加項を正則化項と呼ぶ。この場合、$L_2$正則化とも呼ばれる。
定理(リッジ回帰の1つ抜き交差確認誤差)
第$n$番目の標本を抜いて計算したリッジ回帰の回帰係数を$\boldsymbol{\alpha}^{(-n)}$と表すと、これは次のように表せる。
\hat{\boldsymbol{\alpha}}^{(-n)}=[\tilde{X}\tilde{X}^T-\tilde{\boldsymbol{x}}^{(n)}\tilde{\boldsymbol{x}}^{(n)T}+\lambda I_M]^{-1}(\tilde{X}\tilde{\boldsymbol{y}}_N-\tilde{\boldsymbol{x}}^{(n)}\tilde{y}^{(n)})
ただし$\tilde{y}^{(n)}=y^{(n)}-\bar{y}$および$\tilde{\boldsymbol{x}}^{(n)}=\boldsymbol{x}^{(n)}-\bar{\boldsymbol{x}}$である。
このとき、1つ抜き交差確認法による二乗誤差
e(\lambda)=\frac{1}{N}\sum_{n=1}^N\bigl[\tilde{y}^{(n)}-\tilde{\boldsymbol{x}}^{(n)T}\hat{\boldsymbol{\alpha}}^{(-n)} \bigr]^2
は次式を満たす。
e(\lambda)=\frac{1}{N}|diag(I_M-H)^{-1}(I_M-H)\tilde{\boldsymbol{y}}_N|^2
ただし行列$H$は次式で定義される。
H=\tilde{X}^T(\tilde{X}\tilde{X}^T+\lambda I_M)^{-1}\tilde{X}
また、$diag(I_M-H)^{-1}$は、第$i$対角要素が$(1-H_{i,i})^{-1}$となる対角行列である。
あらかじめ何種類かの$\lambda$を用意しておいてそれぞれ$e(\lambda)$を計算して最小となるものが最善の値となる。
異常検知手順
手順(線形回帰のリッジ解による異常検知)
- 訓練時: $\lambda$の候補をいくつかあらかじめ挙げておく
a. $\lambda$の候補のそれぞれについて、$e(\lambda)$か$e_{GCV}(\lambda)$を計算し、最小の評価値を与える$\lambda$を記憶する
e(\lambda)=\frac{1}{N}\sum_{n=1}^N\frac{1}{(1-H_{n,n})^2}\bigl[\tilde{y}^{(n)} - \tilde{\boldsymbol{x}}^{(n)T}\hat{\boldsymbol{\alpha}}_{ridge} \bigr]^2\\
e_{GCV}(\lambda)=\frac{1}{N}\frac{|(I_M-H)\tilde{\boldsymbol{y}_N}|^2}{[1-Tr(H)/N]^2}
b. 回帰係数 $\hat{\boldsymbol{\alpha_{ridge}}}$ を計算し記憶する
\hat{\boldsymbol{\alpha}}_{ridge}=[\tilde{X}\tilde{X}^T+\lambda I_M]^{-1}\tilde{X}\tilde{\boldsymbol{y}}_N
c. $\hat{\sigma}^2_{ridge}$を計算し記憶する
\hat{\sigma}^2_{ridge}=\frac{1}{N}\biggl\{\hat{\lambda}\hat{\boldsymbol{\alpha}}_{ridge}^T\hat{\boldsymbol{\alpha}}_{ridge}+\sum_{n=1}^N\bigl[\tilde{y}^{(n)} - \hat{\boldsymbol{\alpha}}_{ridge}^T\tilde{\boldsymbol{x}}^{(n)} \bigr]^2 \biggr\}
d. 各標本$(\boldsymbol{x}^{(n)},y^{(n)})$について、異常度$a(y^{(n)},\boldsymbol{x}^{(n)})$を計算し、異常度の閾値$a_{th}$を計算し記憶する
a(y',\boldsymbol{x}')=\frac{1}{\hat{\sigma}^2_{ridge}}[y'-\bar{y}-\hat{\boldsymbol{\alpha}}_{ridge}^T(\boldsymbol{x}'-\bar{\boldsymbol{x}})]^2
訓練標本数$N$が次元$M$に比べて大きくないときは
a^{(n)}=\frac{1}{(1-H_{n,n})^2\hat{\sigma}^2_{ridge}}[y^{(n)}-\bar{y}-\hat{\boldsymbol{\alpha}}_{ridge}^T(\boldsymbol{x}^{(n)}-\bar{\boldsymbol{x}})]^2
- 運用時:
a. 観測データ$(\boldsymbol{x}',y')$に対して、異常度$a(y',\boldsymbol{x}')$を計算する
b. $a(y',\boldsymbol{x}')>a_{th}$なら異常と判定、警報を発する
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# データの準備
data = pd.read_csv('USCrime.csv')
y = data['y']
X = data.iloc[:,[0,2,3,4,5,6,7,8,9,10,11,12,13,14]]
# 中心化
Xc = ((X - X.mean())/X.std())
yc = (y - y.mean())
# サンプル数と説明変数の数
N = len(y)
M = Xc.shape[1]
e_list = []
x = np.array(Xc)
# λの候補
lmd_list = np.linspace(0,5,101)
# λの探索
# 一般化交差確認法の式に従って各λの二乗誤差を求める
for lmd in lmd_list:
x_ = x.T
M = x_.shape[0]
H = x_.T @ np.linalg.solve(x_@x_.T + lmd*np.eye(M), x_)
e = np.sum(((np.eye(N)-H)@yc)**2) / ((1-np.trace(H)/N)**2)/N
e_list.append(e)
# 二乗誤差の最も低いものを選択
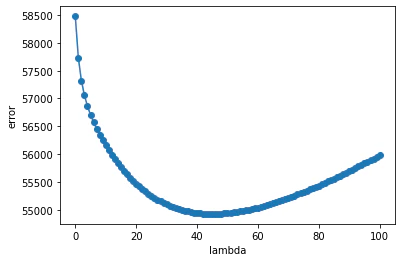
bestIdx = np.argmin(e_list)
lam = lmd_list[bestIdx]
print('lambda: ', lam)
# 各λに対する二乗誤差のプロット
plt.plot(e_list, '-o');
plt.xlabel('lambda')
plt.ylabel('error')
plt.show()
# 回帰係数αの計算
x_= np.vstack((x.T, np.ones((1,47))))
alpha = np.linalg.inv(x_@x_.T + lam*np.eye(M+1)) @ x_ @ yc
print('alpha: ', alpha)
# 予測値
y_pred = x_.T @ alpha +y.mean()
# σ2の計算
sig2 = (lam*((np.sum(alpha[:14]**2))) + np.sum(y_pred - y)**2)/N
# 異常度の計算
H = x_.T@ np.linalg.inv((x_@x_.T + lam*np.eye(M+1))) @ x_
TrHN = np.sum(np.diag(H))/N
a = (y_pred - y)**2 / ((1-TrHN)**2*sig2)
# 閾値の設定
# 上側95%を閾値に設定
th = np.sort(a)[int(np.floor(N*(1-0.05)))]
print('threshold: ', th)
# 正解値と予測値のプロット
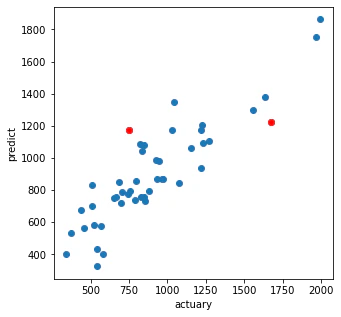
plt.figure(figsize=(5,5))
plt.plot(yc+y.mean(), y_pred, 'o')
plt.plot(yc[a>th]+y.mean(), y_pred[a>th], 'ro')
plt.xlabel('actuary')
plt.ylabel('predict')
plt.show()
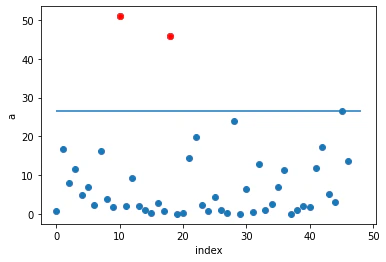
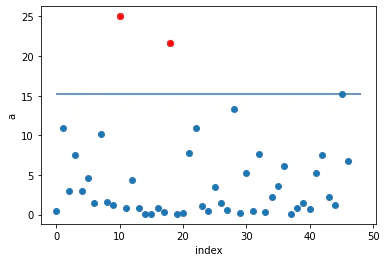
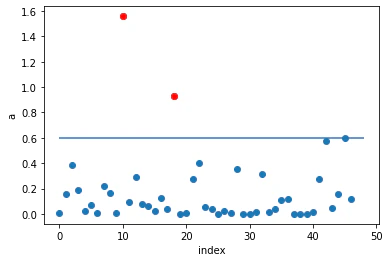
# 各データ点の異常度をプロット
plt.plot(a, 'o')
plt.plot(a[a>th], 'ro')
plt.hlines(th, 0, 48)
plt.xlabel('index')
plt.ylabel('a')
plt.show()
schikit-learnのRidgeCVによりλの探索とモデルの作成を行う。
from sklearn.linear_model import RidgeCV
from sklearn.model_selection import LeaveOneOut
Xc = np.array(((X - X.mean())/X.std()))
yc = np.array((y - y.mean())/y.std())
# ridgeCVでλの探索を行う
ridge = RidgeCV(alphas=lmd_list[1:]).fit(np.array(Xc), yc.reshape(-1,1))
# 回帰係数αの計算
alpha = ridge.coef_
print('alpha: ', alpha)
# 予測値
y_pred = Xc @ alpha.T
# σ2の計算
sig2 = (lam*((np.sum(alpha[:14]**2))) + np.sum(y_pred[:,0] - yc)**2)/N
# 異常度の計算
H = Xc.T@ np.linalg.inv((Xc@Xc.T + lam*np.eye(M))) @ Xc
TrHN = np.sum(np.diag(H))/N
a = (y_pred[:,0] - yc)**2 / ((1-TrHN)**2*sig2)
# 閾値の設定
# 上側95%を閾値に設定
th = np.sort(a)[int(np.floor(N*(1-0.05)))]
print('threshold: ', th)
# 正解値と予測値のプロット
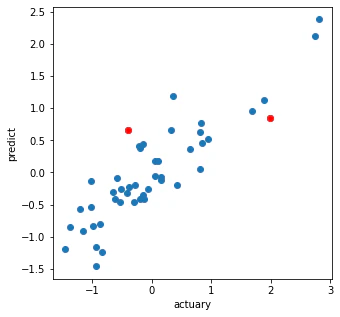
plt.figure(figsize=(5,5))
plt.plot(yc, y_pred, 'o')
plt.plot(yc[a>th], y_pred[a>th], 'ro')
plt.xlabel('actuary')
plt.ylabel('predict')
plt.show()
# 各データ点の異常度をプロット
plt.plot(np.arange(M), a, 'o')
plt.plot(np.arange(M)[a>th], a[a>th], 'ro')
plt.hlines(th, 0, 48)
plt.xlabel('index')
plt.ylabel('a')
plt.show()
4. 偏最小二乗法と統計的プロセス制御(1次元出力)
統計的プロセス制御(SPC)は、広義には統計学的な手法を使って工場などの状態監視を行うことを指す言葉であるが、狭義には、入力と出力がある系において、両者の関係が正常範囲にあるべく状態監視を行うことを指す。
**偏最小二乗法(PLS)**は統計的プロセス制御の標準的手法である。
偏最小二乗法では、出力変数を最もよく説明すると思われる変数を選択的に使うことで、解の安定性と精度の両立を計る。
データとして入力と出力の組$D={(\boldsymbol{x}^{(1)},y^{(1)}),(\boldsymbol{x}^{(2)},y^{(2)}),\cdots,(\boldsymbol{x}^{(N)},y^{(N)})}$が与えられているとする。
ここで、$\boldsymbol{x},y$は平均0,分散1になるように標準化されているとする。これらのデータの時間軸上での相関は無視できるものとし、$N$個は統計的に独立とする。また、各$\boldsymbol{x}^{(n)}$は$M$次元ベクトルとする。
偏最小二乗法では、$m$個の正規直交基底($m<M$)
\boldsymbol{p}_1,\boldsymbol{p}_2,\cdots,\boldsymbol{p}_m\ ここで\ \boldsymbol{p}_i^T\boldsymbol{p}_j=\delta_{i,j}
を使って変換した$\boldsymbol{x}$を使って線形回帰の問題を解く。
問題は以下の2つにある。
(1)基底$\boldsymbol{p}_1,\boldsymbol{p}_2,\cdots,\boldsymbol{p}_N$を、出力変数を最も効率よく表せるように選ぶこと
(2)それらの基底を使って線形回帰モデルを表現し、対応する回帰係数を求めること
手順(NIPALS法による回帰モデル(1変数入力))
- 訓練時
a. 入力:データ行列$X$、出力のベクトル$\boldsymbol{y}_N$、基底の数$m$
b. 出力:基底ベクトルの行列$P=[\boldsymbol{p}_1,\boldsymbol{p}_2,\cdots,\boldsymbol{p}_m]$
c. 計算手順:$i=1,2,\cdots,m$に対して以下を繰り返す
\boldsymbol{p}_i=\frac{X\boldsymbol{y}_N}{|X\boldsymbol{y}_N|}\\
\boldsymbol{d}_i=\frac{X^T\boldsymbol{p}_i}{|X^T\boldsymbol{p}_i|}\\
X←X-X\boldsymbol{d}_i\boldsymbol{d}_i^T
d. 回帰係数$\hat{\boldsymbol{\beta_{PLS}}}=[P^TXX^TP]^{-1}P^TX\boldsymbol{y_N}$を求めておく
2. 予測時
a. 入力$\boldsymbol{x}$
b. 出力$y=\hat{\boldsymbol{\beta}}_{PLS}P^T\boldsymbol{x}$
異常度の定義と異常検知手順
手順(線形回帰の偏最小二乗解による異常検知)
- 訓練時:異常度の確率分布をデータから学習する
a. 基底の行列$P$により変換された訓練データ$(\boldsymbol{r}^{(1)},y^{(1)}),\cdots,(\boldsymbol{r}^{(N)},y^{(N)})$から、回帰係数$\hat{\boldsymbol{\beta}}_{PLS}$と、観測のばらつき
\hat{\sigma}_{PLS}^2=\frac{1}{2}\sum_{n=1}^N\bigl[y^{(N)}- \hat{\boldsymbol{\beta}}_{PLS}^T\boldsymbol{r}^{(N)} \bigr]^2
を求める。
b. 各標本について、異常度を次式を使って計算する。
a(y,\boldsymbol{x})=\frac{1}{\hat{\sigma}_{PLS}^2}\bigl[y- \hat{\boldsymbol{\beta}}_{PLS}^TP\boldsymbol{x} \bigr]^2
c. モーメント法を用いて、計算された異常度$a^{(1)},\cdots,a^{(N)}$に対してカイ二乗分布$\chi(\hat{m_{mo}},\hat{s_{mo}})$を当てはめる。
2. 運用時:当てはめられたカイ二乗分布を基に、異常度の閾値$a_{th}$を求めておく
a. 観測データ$(\boldsymbol{x}',y')$に対して、異常度$a(y',\boldsymbol{x}')$を計算する。
b. $a(y',\boldsymbol{x}')>a_{th}$なら異常と判定、警報を発する
# 改めてデータを読み込む
data = pd.read_csv('USCrime.csv')
y = data['y']
X = data.iloc[:,[0,2,3,4,5,6,7,8,9,10,11,12,13,14]]
# 標準化
Xc = np.array(((X - X.mean())/X.std())).T
yc = np.array((y - y.mean())/y.std()).reshape((47,1))
# 各次元
N = len(y)
M = Xc.shape[0]
m = 5 # 削減後の次数の設定
print('N:',N,' M:',M,' m:',m)
# NIPLAS法
X_new = Xc
P = []
for i in range(m):
p = X_new@yc/np.linalg.norm(X_new@yc, ord=2)
d = X_new.T@p/np.linalg.norm(X_new.T@p, ord=2)
P.append(p)
X_new = Xc - Xc@(d@d.T) # Xを更新する
# 基底ベクトル
P = np.array(P)[:,:,0].T
# 回帰係数の計算
beta = np.linalg.inv(P.T@Xc@Xc.T@P)@P.T@Xc@yc
# 予測値
ypls = beta.T@(P.T@Xc)
ypls = ypls[0]
# σ2の計算
s2 = np.sum((yc - ypls.T)**2)/2
# 異常度の計算
a_pls = (yc.T - ypls.T)**2/s2
a_pls = a_pls[0]
# 閾値の設定
# 上側95%を閾値に設定
th = np.sort(a_pls)[int(np.floor(N*(1-0.05)))]
print('threshold: ', th)
# 正解値と予測値のプロット
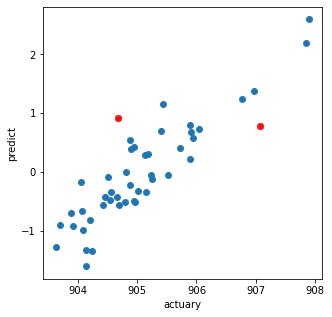
plt.figure(figsize=(5,5))
plt.plot(yc+y.mean(), ypls, 'o')
plt.plot(yc[a_pls>th]+y.mean(), ypls[a_pls>th], 'ro')
plt.xlabel('actuary')
plt.ylabel('predict')
plt.show()
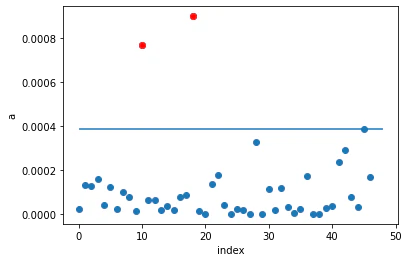
# 各データ点の異常度をプロット
plt.plot(np.arange(N), a_pls, 'o')
plt.plot(np.arange(N)[a_pls>th], a_pls[a_pls>th], 'ro')
plt.hlines(th, 0, 48)
plt.xlabel('index')
plt.ylabel('a')
plt.show()
schikit-learnのPLSRegressionを使って同様の処理をする。
from sklearn.cross_decomposition import PLSRegression
# PLS回帰
reg = PLSRegression(n_components=5)
reg.fit(Xc.T, yc)
# σ2の計算
s2 = np.sum((yc - reg.predict(Xc.T))**2)/2
# 異常度の計算
a_pls = (yc - reg.predict(Xc.T)).T[0]**2/s2
# 閾値の設定
# 上側95%を閾値に設定
th = np.sort(a_pls)[int(np.floor(N*(1-0.05)))]
print('threshold: ', th)
# 正解値と予測値のプロット
plt.figure(figsize=(5,5))
plt.plot(yc+y.mean(), ypls, 'o')
plt.plot(yc[a_pls>th]+y.mean(), ypls[a_pls>th], 'ro')
plt.xlabel('actuary')
plt.ylabel('predict')
plt.show()
# 各データ点の異常度をプロット
plt.plot(np.arange(N), a_pls, 'o')
plt.plot(np.arange(N)[a_pls>th], a_pls[a_pls>th], 'ro')
plt.hlines(th, 0, 48)
plt.xlabel('index')
plt.ylabel('a')
plt.show()
5. 正準相関分析による異常検知
偏最小二乗法では、出力が1変数の場合のみを考えたが、ここでは多出力に拡張することを考える。正準相関分析という手法を説明する。
$M$次元の変数$\boldsymbol{x}$と$L$次元の変数$\boldsymbol{y}$があり、それらが組として$N$個
$$
D={(\boldsymbol{x}^{(1)},y^{(1)}),\cdots,(\boldsymbol{x}^{(N)},y^{(N)}) }
$$
のように観測されているとする。
たとえば、ある装置のパラメータ$\boldsymbol{x}$と、その出力として得られるセンサー値$\boldsymbol{y}$があるとする。正準相関分析とは、パラメータの一次結合
$$
\alpha_1x_1+\alpha_2x_2+\cdots+\alpha_Mx_M\ すなわち\ \boldsymbol{\alpha}^T\boldsymbol{x}
$$
とセンサー出力の一次結合
$$
\beta_1y_1+\beta_2y_2+\cdots+\beta_Ly_L\ すなわち\ \boldsymbol{\beta}^T\boldsymbol{y}
$$
をつくり、両者の相関係数が最大になるように係数$\boldsymbol{\alpha},\boldsymbol{\beta}$を定める問題である。
手順(正準相関分析による異常検知)
- 訓練時(その1:正準変数を求める)
a.行列$W$をつくり、その特異値分解を行う
W=\Sigma_{xx}^{-1/2}\Sigma_{xy}\Sigma_{yy}^{-1/2}
ここで、
\Sigma_{xy}=\frac{1}{N}\sum_{n=1}^N(\boldsymbol{x}^{(n)}-\bar{\boldsymbol{x}})(\boldsymbol{y}^{(n)}-\bar{\boldsymbol{y}})^T\\
\Sigma_{xx}=\frac{1}{N}\sum_{n=1}^N(\boldsymbol{x}^{(n)}-\bar{\boldsymbol{x}})(\boldsymbol{x}^{(n)}-\bar{\boldsymbol{x}})^T\\
\Sigma_{yy}=\frac{1}{N}\sum_{n=1}^N(\boldsymbol{y}^{(n)}-\bar{\boldsymbol{y}})(\boldsymbol{y}^{(n)}-\bar{\boldsymbol{y}})^T
b.$W$の特異ベクトル$(\tilde{\boldsymbol{\alpha}}^i,\tilde{\boldsymbol{\beta}}^i)$を$\lambda^i$の値の大きい順に必要な個数を選ぶ
\tilde{\boldsymbol{\alpha}}=\Sigma_{xx}^{1/2}\boldsymbol{\alpha}\\
\tilde{\boldsymbol{\beta}}=\Sigma_{yy}^{1/2}\boldsymbol{\beta}
- 訓練時(その2:回帰モデルをあてはめる)
a.正準変数を一組(第$i$正準変数とする)選び、元のデータ$D$から、第$i$正準変数からなるデータ
$$
D_i={(f_i^{(1)},g_i^{(1)}),\cdots,(f_i^{(N)},g_i^{(N)}) }
$$
をつくる。ここで、
$$
f_i=\boldsymbol{x}^T\Sigma_{xx}^{-1/2}\tilde{\boldsymbol{\alpha}}^i\
g_i=\boldsymbol{y}^T\Sigma_{yy}^{-1/2}\tilde{\boldsymbol{\beta}}^i
$$
b.$f_i$と$g_i$について1変数の線形回帰モデルをあてはめる
c.異常度を計算し、必要に応じてカイ二乗分布を当てはめるか、分位点を求めるかして閾値を設定する
d.上記を正準変数の数だけ繰り返す
これまで同様のデータを使用します。
$y$が1次元となるので、多次元ではうまく動かない可能性が高いので注意する。
from scipy import linalg
data = pd.read_csv('USCrime.csv')
y = data['y']
X = data.iloc[:,[0,2,3,4,5,6,7,8,9,10,11,12,13,14]]
# 各種次元
dx = 14 # xの次元
dy = 1 # yの次元
N = len(y) # データ数
# 標準化
X_ = np.array(X).T
Xc = (X_ - np.mean(X_, axis=1).reshape(dx,1))/np.std(X_, ddof=0, axis=1).reshape(dx,1)
y_ = np.array(y).reshape(dy,N)
yc = (y_-y_.mean())/y_.std(ddof=0)
# 行列Wを作る
# 分散行列・共分散行列の計算
Sxx = Xc@Xc.T / N
Syy = (yc@yc.T).reshape(dy,dy) / N
Sxy = Xc@yc.T / N
# 定義に従いWの計算
W = linalg.pinv2(linalg.sqrtm(Sxx)) @ Sxy @ linalg.pinv2(linalg.sqrtm(Syy))
# 特異値分解
U, S_diags, V_t = linalg.svd(Sxy, full_matrices=False)
# 正準変数
f1 = (Xc.T@U).reshape(1,N)
g1 = yc.T@V_t
# 回帰係数の計算
alpha1 = linalg.inv(f1@f1.T)@f1@g1
# σ2の計算
sig2 = np.sum((g1 - alpha1*f1.T)**2) / N
# 異常度の計算
a = (g1 - alpha1*f1)**2/sig2
a = a.T[0]
# 閾値の設定
# 上側95%を閾値に設定
th = np.sort(a)[int(np.floor(N*(1-0.05)))]
print('threshold: ', th)
# 正解値と予測値のプロット
plt.figure(figsize=(5,5))
plt.plot(f1[0], g1, 'o')
plt.plot(f1[0][a>th], g1[a>th], 'ro')
plt.xlabel('actuary')
plt.ylabel('predict')
plt.show()
# 各データ点の異常度をプロット
plt.plot(np.arange(N), a, 'o')
plt.plot(np.arange(N)[a>th], a[a>th], 'ro')
plt.hlines(th, 0, 48)
plt.xlabel('index')
plt.ylabel('a')
plt.show()
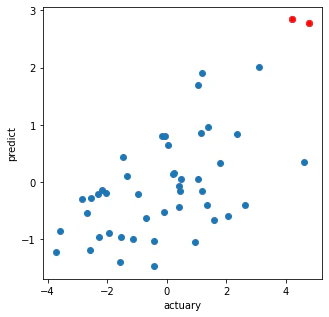
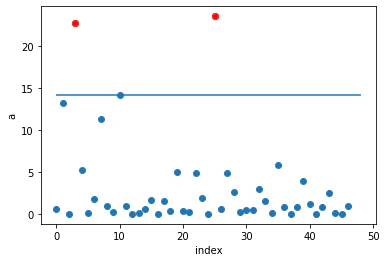
あまりうまく計算できていないようだったので、次に説明するshikiti-learnの関数の中身をみて計算したものが次のものである。
# CCA関数の中身を参考にしたもの
# NIPLAS法
X_pinv = linalg.pinv2(Xc.T, check_finite=False, cond=10*1e-6)
y_pinv = linalg.pinv2(yc.T, check_finite=False, cond=10*1e-6)
x_weights_old = 100
for i in range(100):
x_weights = np.dot(X_pinv, yc.T)
x_weights /= np.sqrt(np.dot(x_weights.T, x_weights)) + 1e-6
x_score = np.dot(X, x_weights)
y_weights = np.dot(y_pinv, x_score)
y_weights /= np.sqrt(np.dot(y_weights, y_weights)) + 1e-6
y_score = np.dot(yc.T, y_weights) / (np.dot(y_weights, y_weights) + 1e-6)
x_weights_diff = x_weights - x_weights_old
if np.dot(x_weights_diff.T, x_weights_diff) < 1e-6 or yc.shape[1] == 1:
break
x_weights_old = x_weights
# 正準変数
f1 = np.dot(Xc.T, x_weights)
g1 = np.dot(yc.T, y_weights)
# 回帰係数の計算
alpha1 = linalg.inv(f1.T@f1)@f1.T@g1
# σ2の計算
sig2 = np.sum((g1.T - alpha1*f1)[0]**2) / N
# 異常度の計算
a = (g1 - alpha1*f1)**2/sig2
a = a.T[0]
# 閾値の設定
# 上側95%を閾値に設定
th = np.sort(a)[int(np.floor(N*(1-0.05)))]
print('threshold: ', th)
# 正解値と予測値のプロット
plt.figure(figsize=(5,5))
plt.plot(f1, g1, 'o')
plt.plot(f1[a>th], g1[a>th], 'ro')
plt.xlabel('actuary')
plt.ylabel('predict')
plt.show()
# 各データ点の異常度をプロット
plt.plot(np.arange(N), a, 'o')
plt.plot(np.arange(N)[a>th], a[a>th], 'ro')
plt.hlines(th, 0, 48)
plt.xlabel('index')
plt.ylabel('a')
plt.show()
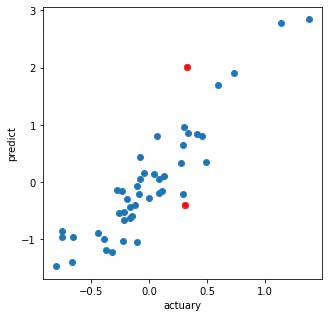
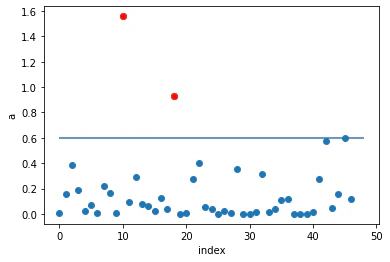
そして、shikit-learnのCCAを使って同様の処理を行う。
from sklearn.cross_decomposition import CCA
from scipy import linalg
y = data['y']
X = data.iloc[:,[0,2,3,4,5,6,7,8,9,10,11,12,13,14]]
# 各種次元
dx = 14 # xの次元
dy = 1 # yの次元
N = len(y) # データ数
# 標準化
X_ = np.array(X).T
Xc = (X_ - np.mean(X_, axis=1).reshape(dx,1))/np.std(X_, ddof=0, axis=1).reshape(dx,1)
y_ = np.array(y).reshape(dy,N)
yc = (y_-y_.mean())/y_.std(ddof=0)
# CCA
cca = CCA(n_components=1)
cca.fit(Xc.T, yc.T)
# 正準変数
f1_cca, g1_cca = cca.transform(Xc.T, yc.T)
# 回帰係数の計算
alpha1 = linalg.inv(f1_cca.T@f1_cca)@f1_cca.T@g1_cca
# σ2の計算
sig2 = np.sum((g1_cca.T - alpha1*f1_cca)[0]**2) / N
# 異常度の計算
a = (g1_cca - alpha1*f1_cca)**2/sig2
a = a.T[0]
# 閾値の設定
# 上側95%を閾値に設定
th = np.sort(a)[int(np.floor(N*(1-0.05)))]
print('threshold: ', th)
# 正解値と予測値のプロット
plt.figure(figsize=(5,5))
plt.plot(f1_cca, g1_cca, 'o')
plt.plot(f1_cca[a>th], g1_cca[a>th], 'ro')
plt.xlabel('actuary')
plt.ylabel('predict')
plt.show()
# 各データ点の異常度をプロット
plt.plot(np.arange(N), a, 'o')
plt.plot(np.arange(N)[a>th], a[a>th], 'ro')
plt.hlines(th, 0, 48)
plt.xlabel('index')
plt.ylabel('a')
plt.show()
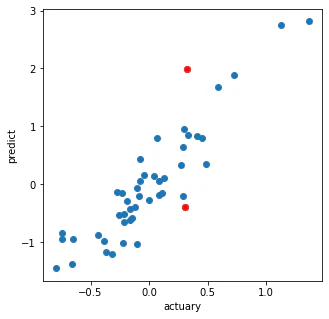
まとめる能力がなく申し訳ないです。
計算内容、コーディングも低いレベルで改善できたらと思います。
次回
時系列データの異常検知
参考文献