Inception V3について構造の説明と実装のメモ書きです。
ただし、論文すべてを見るわけでなく構造のところを中心に見ていきます。
勉強のメモ書き程度でありあまり正確に実装されていませんので、ご了承ください。
以下の論文について実装を行っていきます。
タイトル:Rethinking the Inception Architecture for Computer Vision
Inception V2とV3は同じ論文で紹介されており、GoogleNet(Inception V1)の改良となっています。
factorizationにより、ある畳み込み層をそれより小さいkernel sizeの畳み込みに分解することで計算コストを削減しています。
また、V3はV2を少し修正したものであり実装はほとんど変わりません。
ここではV3の実装を行います。
Inception V3
Inception Modules
Inception V3では複数の種類のInception Moduleがでてきます。
まず、Inception V3の構造を見ます。
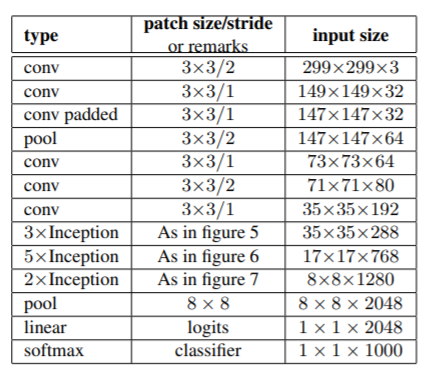
表内の3種類のInception以外にそれぞれのInception間にチャンネル数と画像サイズを変えるためのInceptionが挿入されます。
従って全部で5種類のInceptionが出てきますが論文内では特に名前が付いていないので
- Inceptionx3
- Inceptionx5
- Inceptionx2
- Inception3to5
- Inception5to2
とします。
さらに、5xInceptionの後には、GoogleNet(Inception V1)同様にAuxiliary Classifierが挿入され、この出力も使って学習を行います。ただし、V1では2つありましたが今回は1つです。
Inceptionx3
下の図の通り5×5の畳み込み層を2つの3×3の畳み込み層に分解することができて、これにより計算コストを下げることができます。

次の上の図はGoogleNetのInception Moduleですが、今回はこの5×5の畳み込み層を下図のように2つの3×3の畳み込み層に分解します。

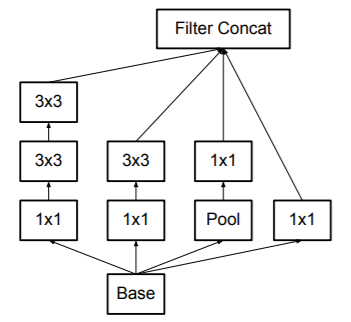
Inceptionx5
さらに、計算コストを下げるため$n×n$の畳み込み層を$1×n$と$n×1$の2つの畳み込み層に分解します。
$3×3$の畳み込み層の場合の例を図に示します。
$1×3$と$3×1$の2つの畳み込み層の出力は$3×3$の畳み込み層と同じになることが分かります。

これを利用するとInception Moduleは次の図のようになります。

この構造のInception Moduleは画像サイズが17×17のものに使用し、そのときは$n=7$とします。
Inceptionx2
さらに、直列に分解するのではなく下図のように並列に分解したInception Moduleも使用します。

Inception3to5(Inception5to2)
Inception Module間では画像サイズが半減し、チャンネル数が増加します。
この処理は以下のような、畳み込みとプーリングを並列に処理する構造のInception Moduleを使用します。

ただし、図の構造はInceptionx3とInceptionx5の間で使用し、Inceptionx5とInceptionx2の間では別の構造のInception Moculeを使用します。
Inception5to2の場合は、3×3の畳み込みが2つ並んでいる部分の1つ目の畳み込みが7×1と1×7の畳み込みの2つの層に置き換えたものを使用します。
Auxiliary Classifier
論文では以下のように紹介されていますが、今回は参考サイトをもとに図のプーリングと畳み込みの間にもう一つ畳み込み層を入れて使用します。

Label Smoothing
学習の際にLabel Smoothingと呼ばれる正則化を行います。
正解ラベルを以下のように変形したものに変更します。

ここで$K$はクラス数、$\epsilon$は足し合わせる割合です。
$\delta$は正解ラベルをワンホットエンコーディングしたものです。
学習
バッチサイズ32で100エポックで学習を行います。
RMSPropを使用し、decayは0.9、$\epsilon$は1.0です。
学習率は0.045で、2エポックごとにrateを0.94として指数的に減衰させていきます。
勾配を2でクリッピングすると学習を安定させることができることもわかりました。
実装
keras
まず必要なライブラリのインポートをします。
import tensorflow.keras as keras
import tensorflow as tf
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Conv2D, Activation, MaxPooling2D, AveragePooling2D, Flatten, Dense, Dropout, GlobalAveragePooling2D, BatchNormalization, Add
from keras.layers.merge import concatenate
from tensorflow.keras import backend as K
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.callbacks import LearningRateScheduler
from keras.datasets import cifar10
import numpy as np
import math
import cv2
畳み込み層の後にはBatchNormalizationとReLUをつけるので、セットで定義しておきます。
class conv_bn_relu(Model):
def __init__(self, out_channels, kernel_size=1, strides=1, padding='same'):
super(conv_bn_relu, self).__init__()
self.conv = Conv2D(out_channels, kernel_size=kernel_size, strides=strides, padding=padding)
self.bn = BatchNormalization()
self.relu = Activation("relu")
def call(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
Inceptionx3の実装をします。
class Inceptionx3(Model):
def __init__(self):
super(Inceptionx3, self).__init__()
self.brabch1 = conv_bn_relu(out_channels=64, kernel_size=1, strides=1)
self.branch2 = Sequential([conv_bn_relu(out_channels=48, kernel_size=1, strides=1),
conv_bn_relu(out_channels=64, kernel_size=3, strides=1)])
self.branch3 = Sequential([conv_bn_relu(out_channels=64, kernel_size=1, strides=1),
conv_bn_relu(out_channels=96, kernel_size=3, strides=1),
conv_bn_relu(out_channels=96, kernel_size=3, strides=1)])
self.branch4 = Sequential([MaxPooling2D(pool_size=3, strides=1, padding='same'),
conv_bn_relu(out_channels=64, kernel_size=1, strides=1)])
def call(self, x):
brabch1 = self.brabch1(x)
brabch2 = self.branch2(x)
brabch3 = self.branch3(x)
brabch4 = self.branch4(x)
out = concatenate([brabch1, brabch2, brabch3, brabch4], axis = -1)
return out
次にInceptionx5の実装をします。
kernel_sizeが非対称になっています。
class Inceptionx5(Model):
def __init__(self):
super(Inceptionx5, self).__init__()
self.brabch1 = conv_bn_relu(out_channels=192, kernel_size=1, strides=1)
self.branch2 = Sequential([conv_bn_relu(out_channels=128, kernel_size=1, strides=1),
conv_bn_relu(out_channels=128, kernel_size=(1,7), strides=1),
conv_bn_relu(out_channels=192, kernel_size=(7,1), strides=1)])
self.branch3 = Sequential([conv_bn_relu(out_channels=128, kernel_size=1, strides=1),
conv_bn_relu(out_channels=128, kernel_size=(1,7), strides=1),
conv_bn_relu(out_channels=128, kernel_size=(7,1), strides=1),
conv_bn_relu(out_channels=128, kernel_size=(1,7), strides=1),
conv_bn_relu(out_channels=192, kernel_size=(7,1), strides=1)])
self.branch4 = Sequential([MaxPooling2D(pool_size=3, strides=1, padding='same'),
conv_bn_relu(out_channels=192, kernel_size=1, strides=1)])
def call(self, x):
brabch1 = self.brabch1(x)
brabch2 = self.branch2(x)
brabch3 = self.branch3(x)
brabch4 = self.branch4(x)
out = concatenate([brabch1, brabch2, brabch3, brabch4], axis = -1)
return out
次にInceptionx2の実装をします。
kernel_sizeが非対称で、枝分かれが多いので注意します。
class Inceptionx2(Model):
def __init__(self):
super(Inceptionx2, self).__init__()
self.brabch1 = conv_bn_relu(out_channels=320, kernel_size=1, strides=1)
self.branch2 = Sequential([conv_bn_relu(out_channels=384, kernel_size=1, strides=1)])
self.brabch2_1 = Sequential([conv_bn_relu(out_channels=384, kernel_size=(1,3), strides=1)])
self.brabch2_2 = Sequential([conv_bn_relu(out_channels=384, kernel_size=(3,1), strides=1)])
self.branch3 = Sequential([conv_bn_relu(out_channels=448, kernel_size=1, strides=1),
conv_bn_relu(out_channels=384, kernel_size=3, strides=1)])
self.brabch3_1 = Sequential([conv_bn_relu(out_channels=384, kernel_size=(1,3), strides=1)])
self.brabch3_2 = Sequential([conv_bn_relu(out_channels=384, kernel_size=(3,1), strides=1)])
self.branch4 = Sequential([MaxPooling2D(pool_size=3, strides=1, padding='same'),
conv_bn_relu(out_channels=192, kernel_size=1, strides=1)])
def call(self, x):
brabch1 = self.brabch1(x)
brabch2 = self.branch2(x)
brabch2_1 = self.brabch2_1(brabch2)
brabch2_2 = self.brabch2_2(brabch2)
brabch3 = self.branch3(x)
brabch3_1 = self.brabch3_1(brabch3)
brabch3_2 = self.brabch3_2(brabch3)
brabch4 = self.branch4(x)
out = concatenate([brabch1, brabch2_1, brabch2_2, brabch3_1, brabch3_2, brabch4], axis = -1)
return out
次に特徴マップのサイズを変換するInception3to5の実装をします。
strideが2のときはpaddingをvalidとします。
class Inception3to5(Model):
def __init__(self):
super(Inception3to5, self).__init__()
self.branch1 = Sequential([conv_bn_relu(out_channels=64, kernel_size=1, strides=1, padding='same'),
conv_bn_relu(out_channels=96, kernel_size=3, strides=1, padding='same'),
conv_bn_relu(out_channels=96, kernel_size=3, strides=2, padding='valid')])
self.branch2 = Sequential([conv_bn_relu(out_channels=384, kernel_size=1, strides=1, padding='same'),
conv_bn_relu(out_channels=384, kernel_size=3, strides=2, padding='valid')])
self.branch3 = Sequential([MaxPooling2D(pool_size=3, strides=2)])
def call(self, x):
brabch1 = self.branch1(x)
brabch2 = self.branch2(x)
brabch3 = self.branch3(x)
out = concatenate([brabch1, brabch2, brabch3], axis = -1)
return out
もう1つの特徴マップのサイズを変換するInception5to2の実装をします。
class Inception5to2(Model):
def __init__(self):
super(Inception5to2, self).__init__()
self.branch1 = Sequential([conv_bn_relu(out_channels=192, kernel_size=1, strides=1, padding='same'),
conv_bn_relu(out_channels=320, kernel_size=3, strides=2, padding='valid')])
self.branch2 = Sequential([conv_bn_relu(out_channels=192, kernel_size=1, strides=1, padding='same'),
conv_bn_relu(out_channels=192, kernel_size=(1, 7), strides=1, padding='same'),
conv_bn_relu(out_channels=192, kernel_size=(7, 1), strides=1, padding='same'),
conv_bn_relu(out_channels=192, kernel_size=3, strides=2, padding='valid')])
self.branch3 = Sequential([MaxPooling2D(pool_size=3, strides=2)])
def call(self, x):
brabch1 = self.branch1(x)
brabch2 = self.branch2(x)
brabch3 = self.branch3(x)
out = concatenate([brabch1, brabch2, brabch3], axis = -1)
return out
ここでは学習で使用するInceptionAuxの実装をします。
class InceptionAux(Model):
def __init__(self, num_classes=10):
super(InceptionAux, self).__init__()
self.pool1 = AveragePooling2D(pool_size=5, strides=3)
self.conv0 = conv_bn_relu(128, kernel_size=1)
self.conv1 = conv_bn_relu(768, kernel_size=5)
self.pool2 = GlobalAveragePooling2D()
self.fc = Dense(num_classes, activation = 'softmax')
def call(self, x):
x = self.pool1(x)
x = self.conv0(x)
x = self.conv1(x)
x = self.pool2(x)
x = self.fc(x)
return x
今まで実装したモジュールを使用してInceptionV3の本体を実装をします。
class InceptionV3(Model):
def __init__(self, aux=True):
super(InceptionV3, self).__init__()
self.conv1 = conv_bn_relu(out_channels=32, kernel_size=3, strides=2, padding='valid')
self.conv2 = conv_bn_relu(out_channels=32, kernel_size=3, strides=1, padding='valid')
self.conv3 = conv_bn_relu(out_channels=64, kernel_size=3, strides=1, padding='same')
self.pool1 = MaxPooling2D(pool_size=3, strides=2)
self.conv4 = conv_bn_relu(out_channels=80, kernel_size=3, strides=1, padding='valid')
self.conv5 = conv_bn_relu(out_channels=192, kernel_size=3, strides=2, padding='valid')
self.conv6 = conv_bn_relu(out_channels=288, kernel_size=3, strides=1, padding='same')
self.inception3 = Sequential([Inceptionx3() for _ in range(3)])
self.inception3to5 = Inception3to5()
self.inception5 = Sequential([Inceptionx5() for _ in range(4)])
self.inception5to2 = Inception5to2()
self.inception2 = Sequential([Inceptionx2() for _ in range(2)])
self.pool2 = GlobalAveragePooling2D()
self.fc = Dense(10, activation = 'softmax')
if aux:
self.aux = InceptionAux(num_classes=10)
else:
self.aux = None
def call(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.pool1(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.conv6(out)
out = self.inception3(out)
out = self.inception3to5(out)
out = self.inception5(out)
if self.aux:
out1 = self.aux(out)
out = self.inception5to2(out)
out = self.inception2(out)
out = self.pool2(out)
out = self.fc(out)
if self.aux:
return out, out1
else:
return out
学習する際はLabel Smoothingで正解ラベルを変換するのでlabel_smoothing_lossを定義します。
def label_smoothing_loss(y_true, y_pred, K=10, eps=0.1):
y_true_smooth = y_true*(1-eps) + eps/K
return keras.losses.categorical_crossentropy(y_true_smooth, y_pred)
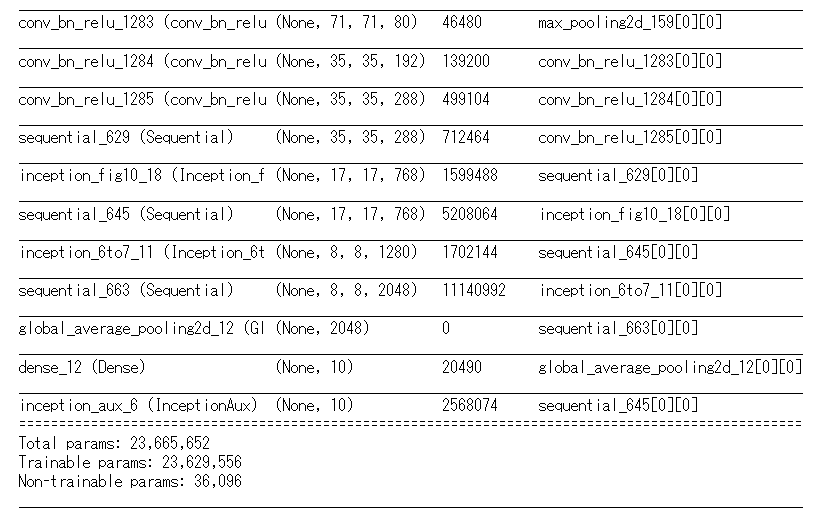
作成したモデルの構造を確認します。
model = InceptionV3()
model.build((None, 299, 299, 3)) # build with input shape.
dummy_input = Input(shape=(299, 299, 3)) # declare without batch demension.
model_summary = Model(inputs=[dummy_input], outputs=model.call(dummy_input))
model_summary.summary()
学習の設定をします。
epochs = 25
initial_lrate = 0.01
def decay(epoch, steps=100):
initial_lrate = 0.0045
drop = 0.94
epochs_drop = 2
lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lrate
sgd = RMSprop(lr=0.045, rho=0.9, epsilon=1.0, decay=0.9)
lr_sc = LearningRateScheduler(decay, verbose=1)
model.compile(loss=[label_smoothing_loss, label_smoothing_loss], loss_weights=[1, 0.3], optimizer=sgd, metrics=['accuracy'])
学習は実行しません。
pytorch
必要なライブラリのインポートをします。
import torch
import torch.nn as nn
import torch.optim as optim
from torchsummary import summary
import torch.nn.functional as F
import pytorch_lightning as pl
from torchmetrics import Accuracy as accuracy
畳み込み層+BatchNormalization+relu
class conv_bn_relu(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0):
super(conv_bn_relu, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
Inceptionx3
class Inceptionx3(nn.Module):
def __init__(self, in_channels):
super(Inceptionx3, self).__init__()
self.brabch1 = conv_bn_relu(in_channels=in_channels, out_channels=64, kernel_size=1, stride=1)
self.branch2 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=48, kernel_size=1, stride=1),
conv_bn_relu(in_channels=48, out_channels=64, kernel_size=3, stride=1, padding=1)])
self.branch3 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=64, kernel_size=1, stride=1),
conv_bn_relu(in_channels=64, out_channels=96, kernel_size=3, stride=1, padding=1),
conv_bn_relu(in_channels=96, out_channels=96, kernel_size=3, stride=1, padding=1)])
self.branch4 = nn.Sequential(*[nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
conv_bn_relu(in_channels=in_channels, out_channels=64, kernel_size=1, stride=1)])
def forward(self, x):
brabch1 = self.brabch1(x)
brabch2 = self.branch2(x)
brabch3 = self.branch3(x)
brabch4 = self.branch4(x)
out = torch.cat([brabch1, brabch2, brabch3, brabch4], axis = 1)
return out
Inceptionx5の実装
非対称なkernel_sizeの畳み込みではpaddingも非対称に設定します。
class Inceptionx5(nn.Module):
def __init__(self, in_channels):
super(Inceptionx5, self).__init__()
self.brabch1 = conv_bn_relu(in_channels=in_channels, out_channels=192, kernel_size=1, stride=1)
self.branch2 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=128, kernel_size=1, stride=1),
conv_bn_relu(in_channels=128, out_channels=128, kernel_size=(1,7), stride=1, padding=(0,3)),
conv_bn_relu(in_channels=128, out_channels=192, kernel_size=(7,1), stride=1, padding=(3,0))])
self.branch3 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=128, kernel_size=1, stride=1),
conv_bn_relu(in_channels=128, out_channels=128, kernel_size=(1,7), stride=1, padding=(0,3)),
conv_bn_relu(in_channels=128, out_channels=128, kernel_size=(7,1), stride=1, padding=(3,0)),
conv_bn_relu(in_channels=128, out_channels=128, kernel_size=(1,7), stride=1, padding=(0,3)),
conv_bn_relu(in_channels=128, out_channels=192, kernel_size=(7,1), stride=1, padding=(3,0))])
self.branch4 = nn.Sequential(*[nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
conv_bn_relu(in_channels=in_channels, out_channels=192, kernel_size=1, stride=1)])
def forward(self, x):
brabch1 = self.brabch1(x)
brabch2 = self.branch2(x)
brabch3 = self.branch3(x)
brabch4 = self.branch4(x)
out = torch.cat([brabch1, brabch2, brabch3, brabch4], axis = 1)
return out
Inceptionx2
class Inceptionx2(nn.Module):
def __init__(self, in_channels):
super(Inceptionx2, self).__init__()
self.brabch1 = conv_bn_relu(in_channels=in_channels, out_channels=320, kernel_size=1, stride=1)
self.branch2 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=384, kernel_size=1, stride=1)])
self.brabch2_1 = nn.Sequential(*[conv_bn_relu(in_channels=384, out_channels=384, kernel_size=(1,3), stride=1, padding=(0,1))])
self.brabch2_2 = nn.Sequential(*[conv_bn_relu(in_channels=384, out_channels=384, kernel_size=(3,1), stride=1, padding=(1,0))])
self.branch3 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=448, kernel_size=1, stride=1),
conv_bn_relu(in_channels=448, out_channels=384, kernel_size=3, stride=1, padding=1)])
self.brabch3_1 = nn.Sequential(*[conv_bn_relu(in_channels=384, out_channels=384, kernel_size=(1,3), stride=1, padding=(0,1))])
self.brabch3_2 = nn.Sequential(*[conv_bn_relu(in_channels=384, out_channels=384, kernel_size=(3,1), stride=1, padding=(1,0))])
self.branch4 = nn.Sequential(*[nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
conv_bn_relu(in_channels=in_channels, out_channels=192, kernel_size=1, stride=1)])
def forward(self, x):
brabch1 = self.brabch1(x)
brabch2 = self.branch2(x)
brabch2_1 = self.brabch2_1(brabch2)
brabch2_2 = self.brabch2_2(brabch2)
brabch3 = self.branch3(x)
brabch3_1 = self.brabch3_1(brabch3)
brabch3_2 = self.brabch3_2(brabch3)
brabch4 = self.branch4(x)
out = torch.cat([brabch1, brabch2_1, brabch2_2, brabch3_1, brabch3_2, brabch4], axis = 1)
return out
Inception3to5
class Inception3to5(nn.Module):
def __init__(self, in_channels):
super(Inception3to5, self).__init__()
self.branch1 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=64, kernel_size=1, stride=1, padding=0),
conv_bn_relu(in_channels=64, out_channels=96, kernel_size=3, stride=1, padding=1),
conv_bn_relu(in_channels=96, out_channels=96, kernel_size=3, stride=2, padding=0)])
self.branch2 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=384, kernel_size=1, stride=1, padding=0),
conv_bn_relu(in_channels=384, out_channels=384, kernel_size=3, stride=2, padding=0)])
self.branch3 = nn.Sequential(*[nn.MaxPool2d(kernel_size=3, stride=2)])
def forward(self, x):
brabch1 = self.branch1(x)
brabch2 = self.branch2(x)
brabch3 = self.branch3(x)
out = torch.cat([brabch1, brabch2, brabch3], axis = 1)
return out
Inception5to2
class Inception5to2(nn.Module):
def __init__(self, in_channels):
super(Inception5to2, self).__init__()
self.branch1 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=192, kernel_size=1, stride=1, padding=0),
conv_bn_relu(in_channels=192, out_channels=320, kernel_size=3, stride=2, padding=0)])
self.branch2 = nn.Sequential(*[conv_bn_relu(in_channels=in_channels, out_channels=192, kernel_size=1, stride=1, padding=0),
conv_bn_relu(in_channels=192, out_channels=192, kernel_size=(1, 7), stride=1, padding=(0,3)),
conv_bn_relu(in_channels=192, out_channels=192, kernel_size=(7, 1), stride=1, padding=(3,0)),
conv_bn_relu(in_channels=192, out_channels=192, kernel_size=3, stride=2, padding=0)])
self.branch3 = nn.Sequential(*[nn.MaxPool2d(kernel_size=3, stride=2)])
def forward(self, x):
brabch1 = self.branch1(x)
brabch2 = self.branch2(x)
brabch3 = self.branch3(x)
out = torch.cat([brabch1, brabch2, brabch3], axis = 1)
return out
InceptionAux
class InceptionAux(nn.Module):
def __init__(self, num_classes=10):
super(InceptionAux, self).__init__()
self.pool1 = nn.AvgPool2d(kernel_size=5, stride=3, padding=0)
self.conv0 = conv_bn_relu(in_channels=768, out_channels=128, kernel_size=1, stride=1,padding=0)
self.conv1 = conv_bn_relu(in_channels=128, out_channels=768, kernel_size=5, stride=1,padding=2)
self.fc = nn.Linear(768*5*5, num_classes)
def forward(self, x):
x = self.pool1(x)
x = self.conv0(x)
x = self.conv1(x)
x = x.view(x.shape[0], -1)
x = self.fc(x)
return x
InceptionV3の本体の実装を行います。
class InceptionV3(nn.Module):
def __init__(self):
super(InceptionV3, self).__init__()
self.conv1 = conv_bn_relu(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=0)
self.conv2 = conv_bn_relu(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=0)
self.conv3 = conv_bn_relu(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv4 = conv_bn_relu(in_channels=64, out_channels=80, kernel_size=3, stride=1, padding=0)
self.conv5 = conv_bn_relu(in_channels=80, out_channels=192, kernel_size=3, stride=2, padding=0)
self.conv6 = conv_bn_relu(in_channels=192, out_channels=288, kernel_size=3, stride=1, padding=1)
self.inception3 = nn.Sequential(*[Inceptionx3(in_channels=288) for _ in range(3)])
self.inception3to5 = Inception3to5(in_channels=288)
self.inception5 = nn.Sequential(*[Inceptionx5(in_channels=768) for _ in range(4)])
self.inception5to2 = Inception5to2(in_channels=768)
self.inception2 = nn.Sequential(*[Inceptionx2(in_channels=1280),
Inceptionx2(in_channels=2048)])
self.pool2 = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(2048, 10)
self.aux = InceptionAux(num_classes=10)
def forward(self, x, training=False):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.pool1(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.conv6(out)
out = self.inception3(out)
out = self.inception3to5(out)
out = self.inception5(out)
if self.aux:
out1 = self.aux(out)
out = self.inception5to2(out)
out = self.inception2(out)
out = self.pool2(out)
out = out.view(out.shape[0], -1)
out = self.fc(out)
if training:
return out, out1
else:
return out
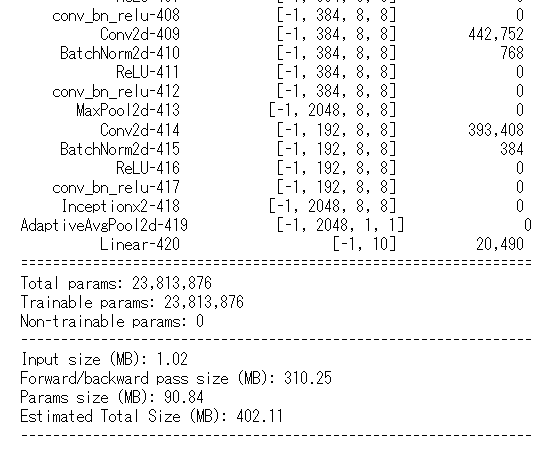
構造を確認します。
from torchsummary import summary
summary(InceptionV3(), (3,299,299))
学習の設定をします。
Label smoothingについてもここで定義します。
class InceptionV3Trainer(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = InceptionV3()
def forward(self, x, training=False):
x = self.model(x, training=training)
return x
def labelsmoothing_loss(self, y_hat, y):
eps = 0.1
K = 10
y_onehot = torch.empty(size=(y.size(0), K), device='cpu') \
.fill_(eps /(K-1)) \
.scatter_(1, y.unsqueeze(1), 1.-eps)
y_true_smooth = y_onehot*(1-eps) + eps/K
loss = -(y_true_smooth*F.log_softmax(y_hat, -1)).sum()/y.size(0)
return loss
def training_step(self, batch, batch_idx):
x, y = batch
#x, y = x.to(device), y.to(device)
y_hat, y_aux1 = self.forward(x, training=True)
loss = self.labelsmoothing_loss(y_hat, y)+0.3*self.labelsmoothing_loss(y_aux1, y)
return {'loss': loss, 'y_hat':y_hat, 'y':y, 'batch_loss': loss.item()*x.size(0)}
def validation_step(self, batch, batch_idx):
x, y = batch
#x, y = x.to(device), y.to(device)
y_hat, y_aux1 = self.forward(x, training=True)
loss = self.labelsmoothing_loss(y_hat, y)+0.3*self.labelsmoothing_loss(y_aux1, y)
return {'y_hat':y_hat, 'y':y, 'batch_loss': loss.item()*x.size(0)}
def test_step(self, batch, batch_nb):
x, y = batch
#x, y = x.to(device), y.to(device)
y_hat = self.forward(x, aux=False)
loss = nn.CrossEntropyLoss()(y_hat, y)
y_label = torch.argmax(y_hat, dim=1)
acc = accuracy()(y_label, y)
return {'test_loss': loss, 'test_acc': acc}
def training_epoch_end(self, train_step_output):
y_hat = torch.cat([val['y_hat'] for val in train_step_outputs], dim=0)
y = torch.cat([val['y'] for val in train_step_outputs], dim=0)
epoch_loss = sum([val['batch_loss'] for val in train_step_outputs]) / y_hat.size(0)
preds = torch.argmax(y_hat, dim=1)
acc = accuracy()(preds, y)
self.log('train_loss', epoch_loss, prog_bar=True, on_epoch=True)
self.log('train_acc', acc, prog_bar=True, on_epoch=True)
print('---------- Current Epoch {} ----------'.format(self.current_epoch + 1))
print('train Loss: {:.4f} train Acc: {:.4f}'.format(epoch_loass, acc))
def validation_epoch_end(self, val_step_outputs):
y_hat = torch.cat([val['y_hat'] for val in val_step_outputs], dim=0)
y = torch.cat([val['y'] for val in val_step_outputs], dim=0)
epoch_loss = sum([val['batch_loss'] for val in val_step_outputs]) / y_hat.size(0)
preds = torch.argmax(y_hat, dim=1)
acc = accuracy()(preds, y)
self.log('val_loss', epoch_loss, prog_bar=True, on_epoch=True)
self.log('val_acc', acc, prog_bar=True, on_epoch=True)
print('valid Loss: {:.4f} valid Acc: {:.4f}'.format(epoch_loss, acc))
# New: テストデータに対するエポックごとの処理
def test_epoch_end(self, test_step_outputs):
y_hat = torch.cat([val['y_hat'] for val in test_step_outputs], dim=0)
y = torch.cat([val['y'] for val in test_step_outputs], dim=0)
epoch_loss = sum([val['batch_loss'] for val in test_step_outputs]) / y_hat.size(0)
preds = torch.argmax(y_hat, dim=1)
acc = accuracy()(preds, y)
self.log('test_loss', epoch_loss, prog_bar=True, on_epoch=True)
self.log('test_acc', acc, prog_bar=True, on_epoch=True)
print('test Loss: {:.4f} test Acc: {:.4f}'.format(epoch_loss, acc))
def configure_optimizers(self):
optimizer = optim.RMSprop(self.parameters(), lr=0.045, eps=1.0, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.06)
return {'optimizer': optimizer, 'lr_scheduler': scheduler}
学習は実行しません。
以上で、InceptionV3の実装を終わります。