メモ書きになりますのでご了承ください。
統計をpython使って勉強していこうと思います。
一様分布(descrete uniform distribution)
$N$を正の整数とします。離散型確率変数$X$が、離散一様分布に従うとき確率関数は以下のように表せます。
$$
P(X=x|N)=\frac{1}{N},\ x=1,2,\cdots,N
$$
期待値
$$
E[X]=\frac{1}{N}\sum_{x=1}^Nx=\frac{1}{N}・\frac{N(N+1)}{2}=\frac{N+1}{2}
$$
分散
$$
E[X^2]=\frac{1}{N}\sum_{x=1}^Nx^2=\frac{1}{N}・\frac{N(N+1)(2N+1)}{6}=\frac{(N+1)(2N+1)}{6}
$$
から、
$$
Var(X)=E[X^2]-{E[X]}^2=\frac{(N+1)(2N+1)}{6}-\frac{N+1}{2}=\frac{(N+1)(N-1)}{12}
$$
となります。
pythonで確認していきます。
本来でなれば一様分布にはscipy.statsにuniformという関数がありますが、連続分布になってしまうのでここではnumpyを使用します。
$N=10$として、一様分布でサンプリングを行い確率分布を作ってみます。
from numpy.random import randint
import matplotlib.pyplot as plt
import numpy as np
samples = randint(1, 11, 1000)
x, count = np.unique(samples, return_counts=True)
p = count / 1000
plt.bar(x=x, height=p)
plt.hlines(0.1, 0, 11, linestyles='--')
plt.xlim(0,11)

どの数値においても$1/N=1/10=0.1$付近となっていることが分かります。
次に、平均・分散の計算を行います。まず、確率変数とその確率から計算します。
Ex = np.sum(p*x)
Ex2 = np.sum(p*x**2)
Varx = np.sum(p*(x-Ex)**2)
print('E[X]: ', Ex)
print('E[X2]: ', Ex2)
print('Var[X]: ', Varx)

上記の式から算出します。
print('E[X]: ', (10+1)/2)
print('E[X2]: ', (10+1)*(2*10+1)/6)
print('Var[X]: ', (10+1)*(2*10+1)/6 - ((10+1)/2)**2)

今後のために、確率変数とその確率から平均・分散の計算をする関数を定義しておきます。
def calc_mean_var(x ,p):
Ex = np.sum(p*x)
Ex2 = np.sum(p*x**2)
Varx = np.sum(p*(x-Ex)**2)
print('E[X]: ', Ex)
print('Var[X]: ', Varx)
ベルヌーイ分布(Bernoulli distribution)
ベルヌーイ試行とは、$p$の確率で成功、$1-p$の確率で失敗する実験を行うことをいいます。
確率偏巣$X$は成功のとき1、失敗のときに0をとるものとすると、確率変数の従う確率関数は次のように書けます。
P(X=x|p)=\left\{
\begin{array}\\
p&(x=1)\\
1-p&(x=0)
\end{array}
\right.
これをベルヌーイ分布と呼び、$Ber(p)$で表します。
期待値
$$
E[X]=1×p+0×(1-p)=p
$$
分散
$$
Var(X)=(1-p)^2×p+(0-p)^2×(1-p)=p(1-p)
$$
scipy.statsのbernoulliを使用して、分布を確認します。
from scipy.stats import bernoulli
samples = bernoulli.rvs(p=0.2, size=1000)
x, count = np.unique(samples, return_counts=True)
p = count / 1000
plt.bar(x=x, height=p)
plt.hlines(0.2, -0.5, 1.5, linestyles='--')
plt.xlim(-0.5,1.5)

Ex = np.sum(p*x)
Varx = np.sum(p*(x-Ex)**2)
print('E[X]: ', Ex)
print('Var[X]: ', Varx)
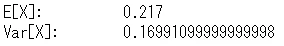
統計値の確認をします。左から平均、分散、尖度そして歪度の順番で出力されます。
bernoulli.stats(p=0.2, moments='mvsk')
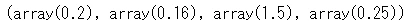
確率分布はpmfで計算できます。
bernoulli.pmf(k=np.array([0,1]), p=0.2)
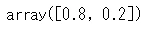
2項分布(binomial distribution)
ベルヌーイ試行を独立に$n$回行ったときの成功の回数の分布が2項分布となります。
$n$回の試行のうち$k$回成功、$n-k$回失敗となる確率は、2項係数$_nC_k$を、
_nC_k=\frac{n!}{k!(n-k)!}=\begin{pmatrix}n\\k\end{pmatrix}
と表したきに、
P(Y=k|n,p)=\begin{pmatrix}n\\k\end{pmatrix}p^k(1-p)^{n-k},\ k=0,1,2,\cdots,n
と書けます。これを2項分布と呼び、$Bin(n,p)$で表します。
期待値
\begin{align}
E[X]&=\sum_{k=0}^n\frac{n!}{k!(n-k)!}p^k(1-p)^{n-k}\times k\\
&=n\sum_{k=1}^n\frac{(n-1)!}{(k-1)!\bigl((n-1)-(k-1)\bigr)!}p^k(1-p)^{n-k}\\
&=np\sum_{k=1}^n\frac{(n-1)!}{(k-1)!\bigl((n-1)-(k-1)\bigr)!}p^{(k-1)}(1-p)^{(n-1)-(k-1)}\\
&=np\sum_{k=0}^{n-1}\frac{(n-1)!}{k!\bigl((n-1)-k\bigr)!}p^{k}(1-p)^{(n-1)-k}\\
&=np
\end{align}
分散
\begin{align}
E[X^2]&=\sum_{k=0}^n\frac{n!}{k!(n-k)!}p^k(1-p)^{n-k}\times k^2\\
&=\sum_{k=0}^nk(k-1)\frac{n!}{k!(n-k)!}p^k(1-p)^{n-k}+\sum_{k=0}^nk\frac{n!}{k!(n-k)!}p^k(1-p)^{n-k}\\
&=n(n-1)p^2\sum_{k=2}^{n}\frac{(n-2)!}{(k-2)!\bigl((n-2)-(k-2)\bigr)!}p^{k-2}(1-p)^{(n-2)-(k-2)}+np\\
&=n(n-1)p^2+np
\end{align}
であるから、
\begin{align}
Var(X)&=E[X^2]-\{E[X]\}^2\\
&=n(n-1)p^2+np-(np)^2\\
&=np(1-p)
\end{align}
モーメント母関数
\begin{align}
M_X(t)&=E[e^{tX}]\\
&=\sum_{k=0}^n\frac{n!}{k!(n-k)!}p^k(1-p)^{n-k}\times e^{tk}\\
&=\sum_{k=0}^n\frac{n!}{k!(n-k)!}(pe^t)^k(1-p)^{n-k}\\
&=(pe^t+1-p)^n
\end{align}
モーメント母関数の1次微分と2次微分はそれぞれ
M'_X(t)=npe^{t}(pe^t+1-p)^{n-1}\\
M''_X(t)=np\bigl\{e^{t}(pe^t+1-p) + e^{t}(n-1)pe^{t} \bigr\}(pe^t+1-p)^{n-2}
と計算できます。$t=0$とすると、
E[X]=M'_X(0)=np(p+1-p)^{n-1}=np\\
M''_X(0)=np\times (1 + p(n-1))\\
Var(X)=M''_X(0)-\{M'_X(0)\}^2=n(n-1)p^2
と求められる。
成功の確率が0.2であるベルヌーイ試行を10回行ったときの成功の回数の分布を確認してみます。
samples1 = [np.sum(bernoulli.rvs(p=0.2, size=10)) for _ in range(10000)]
samples2 = [np.sum(bernoulli.rvs(p=0.6, size=10)) for _ in range(10000)]
x1, count1 = np.unique(samples1, return_counts=True)
x2, count2 = np.unique(samples2, return_counts=True)
p1 = count1 / 1000
p2 = count2 / 1000
plt.bar(x=x1, height=p1, alpha=.5, label='p=0.2')
plt.bar(x=x2, height=p2, alpha=.5, label='p=0.6')
plt.xlim(-1,11)
plt.legend()

もちろん専用の関数が用意されています。scipy.statsのbinomialを使ってサンプリングをして分布を出してみます。
また、binom.pmfで確率変数の値を引数に与えれば、そのときの確率を出力してくれます。
これを使って算出した確率分布も重ねて表示します。
from scipy.stats import binom
samples1 = binom.rvs(p=0.2, n=10, size=1000)
samples2 = binom.rvs(p=0.6, n=10, size=1000)
x1, count1 = np.unique(samples1, return_counts=True)
x2, count2 = np.unique(samples2, return_counts=True)
p1 = count1 / 1000
p2 = count2 / 1000
x = np.arange(0, 10)
f1 = binom.pmf(k=x, n=10, p=0.2)
f2 = binom.pmf(k=x, n=10, p=0.6)
plt.bar(x=x1, height=p1, alpha=.5, label='p=0.2')
plt.bar(x=x2, height=p2, alpha=.5, label='p=0.6')
plt.plot(x, f1, '-o', alpha=.8, label='p=0.2')
plt.plot(x, f2, '-o', alpha=.8, label='p=0.6')
plt.xlim(-1,11)
plt.legend()

サンプリングして得られた確率分布から期待値と分散を計算してみます。
print('p=0.2')
calc_mean_var(x1 ,p1)
print('p=0.6')
calc_mean_var(x2 ,p2)

上で説明した計算結果に値を代入してみます。
print('p=0.2')
print('np=', 10*0.2)
print('np(1-p)=', 10*0.2*(1-0.2))
print('p=0.6')
print('np=', 10*0.6)
print('np(1-p)=', 10*0.6*(1-0.6))

計算しなくてもbinom.statsを使って確認できます。
print('p=0.2: ',binom.stats(n=10, p=0.2))
print('p=0.6: ',binom.stats(n=10, p=0.6))
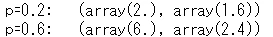
ポアソン分布(poisson distribution)
稀な現象の大量観測によって発生する現象の個数の分布を表すときポアソン分布が用いられます。
この現象が起こる個数を$X$で表すと、$X$の確率関数は次のように表されます。
P(X=x|\lambda)=\frac{\lambda^k}{k!}e^{-\lambda},\ k=1,2,\cdots
この確率分布をポアソン分布と呼び、$Po(\lambda)$と表します。
$\lambda>0$は強度と呼ばれるパラメータであり、回数の平均を表します。
期待値
\begin{align}
E[X]&=\sum_{k=0}^n\frac{\lambda^k}{k!}e^{-\lambda}\times k\\
&=\lambda\sum_{k=1}^n\frac{\lambda^{k-1}}{(k-1)!}e^{-\lambda}\\
&=\lambda
\end{align}
分散
\begin{align}
E[X^2]&=\sum_{k=0}^n\frac{\lambda^k}{k!}e^{-\lambda}\times k^2\\
&=\sum_{k=1}^nk(k-1)\frac{\lambda^{k}}{k!}e^{-\lambda}+\sum_{k=0}^nk\frac{\lambda^{k}}{k!}e^{-\lambda}\\
&=\lambda^2\sum_{k=2}^n\frac{\lambda^{k-2}}{(k-2)!}e^{-\lambda}+\lambda\\
&=\lambda^2+\lambda
\end{align}
から、
\begin{align}
Var(X)&=E[X^2]-\{E[X]\}^2\\
&=(\lambda^2+\lambda)-\lambda^2\\
&=\lambda
\end{align}
モーメント母関数
\begin{align}
M_X(t)&=E[e^{tX}]\\
&=\sum_{k=0}^n\frac{\lambda^k}{k!}e^{-\lambda}\times e^{tk}\\
&=e^{-\lambda(1-e^t)}\sum_{k=0}^n\frac{(\lambda e^t)^k}{k!}e^{-\lambda e^t}\\
&=e^{-\lambda(1-e^t)}
\end{align}
モーメント母関数の1次微分と2次微分はそれぞれ
M'_X(t)=\lambda e^t e^{-\lambda(1-e^t)}\\
M''_X(t)=\lambda e^t(1 + \lambda e^t)e^{-\lambda(1-e^t)}
と計算できます。$t=0$とすると、
E[X]=M'_X(0)=\lambda\\
M''_X(0)=\lambda(1+\lambda)\\
Var(X)=M''_X(0)-\{M'_X(0)\}^2=\lambda
と求められる。
scipy.statsのpoissonを使って、サンプリングを行ってみます。
from scipy.stats import poisson
samples1 = poisson.rvs(mu=2, size=1000)
samples2 =poisson.rvs(mu=5, size=1000)
samples3 =poisson.rvs(mu=10, size=1000)
x1, count1 = np.unique(samples1, return_counts=True)
x2, count2 = np.unique(samples2, return_counts=True)
x3, count3 = np.unique(samples3, return_counts=True)
p1 = count1 / 1000
p2 = count2 / 1000
p3 = count3 / 1000
x = np.arange(0, 20)
f1 = poisson.pmf(k=x, mu=2)
f2 = poisson.pmf(k=x, mu=5)
f3 = poisson.pmf(k=x, mu=10)
plt.bar(x=x1, height=p1, alpha=.5, label='mu=1')
plt.bar(x=x2, height=p2, alpha=.5, label='mu=5')
plt.bar(x=x3, height=p3, alpha=.5, label='mu=10')
plt.plot(x, f1, '-o', alpha=.8, label='p=2')
plt.plot(x, f2, '-o', alpha=.8, label='p=5')
plt.plot(x, f3, '-o', alpha=.8, label='p=10')
plt.xlim(-1,21)
plt.legend()
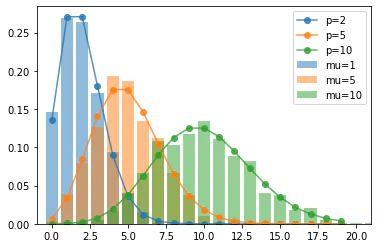
print('mu=2')
calc_mean_var(x1 ,p1)
print('mu=5')
calc_mean_var(x2 ,p2)
print('mu=10')
calc_mean_var(x3 ,p3)

print('mu=2: ', poisson.stats(mu=2))
print('mu=5: ', poisson.stats(mu=5))
print('mu=10: ', poisson.stats(mu=10))
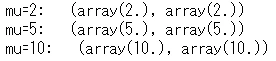
$np=\lambda$を一定とする条件のもとで$n→\infty,p→0$とすると、2項分布はポアソン分布に収束するという性質があります。
ここで$n=100000$として2項分布とポアソン分布の比較を行ってみます。
x = np.arange(0, 20)
n = 100000
g1 = binom.pmf(k=x, n=n, p=2/n)
g2 = binom.pmf(k=x, n=n, p=5/n)
g3 = binom.pmf(k=x, n=n, p=10/n)
plt.bar(x, g1, alpha=.5, label='np=2(binom)')
plt.bar(x, g2, alpha=.5, label='np=5(binom)')
plt.bar(x, g3, alpha=.5, label='np=10(binom)')
plt.plot(x, f1, '-o', alpha=.5, label='p=2(poisson)')
plt.plot(x, f2, '-o', alpha=.5, label='p=5(poisson)')
plt.plot(x, f3, '-o', alpha=.5, label='p=10(poisson)')
plt.xlim(-1,21)
plt.legend()

2項分布がポアソン分布とほぼ同じ形状になることがわかりました。
幾何分布(geometric distribution)
成功確率$p$のベルヌーイ試行を独立に行っていき、初めて成功するまでに要した失敗の回数を$X$とするとき、$X$の分布が幾何分布となります。
$X=k$となる確率は、次のように書けます。
P(X=k|p)=p(1-p)^k,/ k=0,1,2,\cdots
これを幾何分布と呼び、$Geo(p)$で表します。
期待値
\begin{align}
E[X]&=\sum_{k=0}^np(1-p)^k \times k
\end{align}
ここで、
f(x)=\frac{1}{1-x}
のマクローリン展開を考えます。
マクローリン展開は、
f(x)=\sum_{k=0}^\infty\frac{f^{(k)}(0)}{k!}x^k
と書けるので、まずはこのf$(x)$の微分を考えます。
f'(0)=\frac{1}{(1-x)^2}|_{x=0}=1\\
f''(0)=\frac{2}{(1-x)^3}|_{x=0}=2\\
f'''(0)=\frac{2\times3}{(1-x)^3}|_{x=0}=2\times3
となることから、
f^{(k)}(0)=k!
と考えられます。
従って、
f(x)=\frac{1}{1-x}=\sum_{k=0}^\infty x^k
が成り立ちます($x=0$付近で)。
ここで、$x=1-p$と置くと、
\frac{1}{p}=\sum_{k=0}^\infty (1-p)^k
さらに、両辺を$p$で微分すると(期待値の式に合わせるためです)、
\frac{1}{p^2}=\sum_{k=0}^\infty k(1-p)^{k-1}
以上より、
\begin{align}
E[X]&=\sum_{k=0}^np(1-p)^k \times k\\
&=p(1-p)\times\sum_{k=0}^n k(1-p)^{k-1}\\
&=\frac{1-p}{p}=\frac{q}{p}
\end{align}
分散
\begin{align}
E[X(X-1)]&=\sum_{k=0}^np(1-p)^k\times k(k-1)
\end{align}
期待値同様に、
f(x)=\frac{1}{1-x}
のマクローリン展開を考えます。
先ほどの結果から、
f(x)=\frac{1}{1-x}=\sum_{k=0}^\infty x^k
が成り立ちます。
$x=1-p$と置くと、
\frac{1}{p}=\sum_{k=0}^\infty (1-p)^k
さらに、両辺を$p$で微分すると、
\frac{1}{p^2}=\sum_{k=0}^\infty k(1-p)^{k-1}
そして、もう一度$p$で微分します。
\frac{2}{p^3}=\sum_{k=0}^\infty k(k-1)(1-p)^{k-2}
これを$E[X(X-1)]$の式に代入します。
\begin{align}
E[X(X-1)]&=\sum_{k=0}^np(1-p)^k\times k(k-1)\\
&= p(1-p)^2\sum_{k=0}^n k(k-1)(1-p)^{k-2}\\
&=2\frac{(1-p)^2}{p^2}
\end{align}
従って、
\begin{align}
Var(X)&=E[X(X-1)]+E[X]-\{E[X]\}^2\\
&=2\frac{(1-p)^2}{p^2}+\frac{1-p}{p}-\frac{(1-p)^2}{p^2}\\
&=\frac{1-p}{p^2}
\end{align}
モーメント母関数
\begin{align}
M_X(t)&=E[e^{tX}]\\
&=\sum_{k=0}^np(1-p)^k \times e^{tk}\\
&=\sum_{k=0}^np(e^t-pe^t)^k\\
&=p\frac{1}{1-(1-p)e^t}
\end{align}
モーメント母関数の1次微分と2次微分はそれぞれ
M'_X(t)=\frac{p(1-p)e^t}{(1-(1-p)e^t)^2}\\
M''_X(t)=\frac{p(1-p)e^t(1+(1-p)e^t)}{(1-(1-p)e^t)^{3}}
と計算できます。$t=0$とすると、
E[X]=M'_X(0)=\frac{1-p}{p}\\
M''_X(0)=\frac{(1-p)(2-p)}{p^2}\\
Var(X)=M''_X(0)-\{M'_X(0)\}^2=\frac{(2-3p+p^2)-(1-2p+p^2)}{p^2}=\frac{1-p}{p^2}
scipy.statsのgeomで分布などを確認します。
from scipy.stats import geom
samples1 = geom.rvs(p = 0.2, size=1000)
samples2 = geom.rvs(p = 0.4, size=1000)
samples3 = geom.rvs(p = 0.8, size=1000)
x1, count1 = np.unique(samples1, return_counts=True)
x2, count2 = np.unique(samples2, return_counts=True)
x3, count3 = np.unique(samples3, return_counts=True)
p1 = count1 / 1000
p2 = count2 / 1000
p3 = count3 / 1000
x = np.arange(1, 20)
f1 = geom.pmf(k=x, p=0.2)
f2 = geom.pmf(k=x, p=0.4)
f3 = geom.pmf(k=x, p=0.8)
plt.bar(x=x1, height=p1, alpha=.5, label='p=0.2')
plt.bar(x=x2, height=p2, alpha=.5, label='p=0.4')
plt.bar(x=x3, height=p3, alpha=.5, label='p=0.8')
plt.plot(x, f1, '-o', alpha=.5, label='p=0.2')
plt.plot(x, f2, '-o', alpha=.5, label='p=0.4')
plt.plot(x, f3, '-o', alpha=.5, label='p=0.8')
plt.xlim(-1,21)
plt.legend()
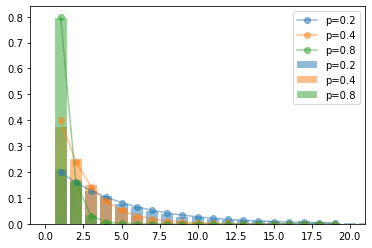
確率分布から平均と分散を求めてみます。
print('p=0.2')
calc_mean_var(x1 ,p1)
print('p=0.4')
calc_mean_var(x2 ,p2)
print('p=0.8')
calc_mean_var(x3 ,p3)

関数を使って求めます。
print('p=0.2: ', geom.stats(p=0.2))
print('p=0.4: ', geom.stats(p=0.4))
print('p=0.8: ', geom.stats(p=0.8))
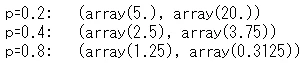
負の2項分布(negative binomial)
成功確率が$p$のベルヌーイ分布について、$r$回成功するまでに要した失敗の回数を$X$とするとき、$X$の分布が負の2項分布になります。
合計$r+k$の試行のうち、成功が$r$回、失敗が$k$回となるので、確率分布は次のようになります。
P(X=x|r,p)=\begin{pmatrix}r+k-1\\k\end{pmatrix}p^rq^k,\ k=0,1,2,\cdots
これを負の2項分布と呼び、$NB(r,p)$と表します。
期待値
\begin{align}
E[X]&=\sum_{k=0}^\infty\begin{pmatrix}r+k-1\\k\end{pmatrix}p^rq^k \times k\\
&=\sum_{k=0}^\infty k\frac{(r+k-1)\times\cdots\times r}{k\times\cdots\times 1}p^rq^k\\
&=r\frac{q}{p}\sum_{k=1}^\infty\frac{(r+k-1)\times\cdots\times (r+1)}{k-1\times\cdots\times 1}p^{r+1}q^{k-1}\\
&=\frac{rq}{p}
\end{align}
分散
\begin{align}
E[X(X-1)]&=\sum_{k=0}^\infty\begin{pmatrix}r+k-1\\k\end{pmatrix}p^rq^k \times k(k-1)\\
&=\sum_{k=0}^\infty k(k-1)\frac{(r+k-1)\times\cdots\times r}{k\times\cdots\times 1}p^rq^k\\
&=r(r+1)\frac{q^2}{p^2}\sum_{k=1}^\infty\frac{(r+k-1)\times\cdots\times (r+2)}{k-2\times\cdots\times 1}p^{r+2}q^{k-2}\\
&=\frac{r(r+1)q^2}{p^2}
\end{align}
従って、
\begin{align}
Var(X)&=E[X(X-1)]+E[X]-\{E[X]\}^2\\
&=\frac{r(r+1)q^2}{p^2}+\frac{rq}{p}-\frac{r^2q^2}{p^2}\\
&=\frac{rq}{p^2}
\end{align}
モーメント母関数
\begin{align}
M_X(t)&=E[e^{tX}]\\
&=\sum_{k=0}^\infty\begin{pmatrix}r+k-1\\k\end{pmatrix}p^rq^k \times e^{tk}\\
&=\sum_{k=0}^\infty\begin{pmatrix}r+k-1\\k\end{pmatrix}p^r(qe^t)^k\\
&=\frac{p^r}{(1-qe^t)^r}\sum_{k=0}^\infty\begin{pmatrix}r+k-1\\k\end{pmatrix}(1-qe^t)^r(qe^t)^k\\
&=\frac{p^r}{(1-qe^t)^r}
\end{align}
モーメント母関数の1次微分と2次微分はそれぞれ
M'_X(t)=rp^rq(1-qe^t)^{-r-1}(e^t)\\
M''_X(t)=rp^rq((-r-1)(1-qe^t)^{-r-2}(-qe^{2t}) + (1-qe^t)^{-r-1}(e^t))
と計算できます。$t=0$とすると、
E[X]=M'_X(0)=\frac{rq}{p}\\
M''_X(0)=r\frac{q(1+rq)}{p^2}\\
Var(X)=M''_X(0)-\{M'_X(0)\}^2=\frac{rq}{p^2}
scipy.statsのnbinomで分布などを確認します。
from scipy.stats import nbinom
samples1 = nbinom.rvs(p = 0.2, n=5, size=1000)
samples2 = nbinom.rvs(p = 0.4, n=5, size=1000)
samples3 = nbinom.rvs(p = 0.8, n=5, size=1000)
x1, count1 = np.unique(samples1, return_counts=True)
x2, count2 = np.unique(samples2, return_counts=True)
x3, count3 = np.unique(samples3, return_counts=True)
p1 = count1 / 1000
p2 = count2 / 1000
p3 = count3 / 1000
x = np.arange(0, 40)
f1 = nbinom.pmf(k=x, p=0.2, n=5)
f2 = nbinom.pmf(k=x, p=0.4, n=5)
f3 = nbinom.pmf(k=x, p=0.8, n=5)
plt.bar(x=x1, height=p1, alpha=.5, label='p=0.2')
plt.bar(x=x2, height=p2, alpha=.5, label='p=0.4')
plt.bar(x=x3, height=p3, alpha=.5, label='p=0.8')
plt.plot(x, f1, '-o', alpha=.5, label='p=0.2')
plt.plot(x, f2, '-o', alpha=.5, label='p=0.4')
plt.plot(x, f3, '-o', alpha=.5, label='p=0.8')
plt.xlim(-1,41)
plt.legend()

print('p=0.2 n=5')
calc_mean_var(x1 ,p1)
print('p=0.4 n=5')
calc_mean_var(x2 ,p2)
print('p=0.8 n=5')
calc_mean_var(x3 ,p3)

print('p=0.2 n=5: ', nbinom.stats(p=0.2, n=5))
print('p=0.4 n=5: ', nbinom.stats(p=0.4, n=5))
print('p=0.8 n=5: ', nbinom.stats(p=0.8, n=5))

samples1 = nbinom.rvs(p = 0.4, n=2, size=1000)
samples2 = nbinom.rvs(p = 0.4, n=5, size=1000)
samples3 = nbinom.rvs(p = 0.4, n=10, size=1000)
x1, count1 = np.unique(samples1, return_counts=True)
x2, count2 = np.unique(samples2, return_counts=True)
x3, count3 = np.unique(samples3, return_counts=True)
p1 = count1 / 1000
p2 = count2 / 1000
p3 = count3 / 1000
x = np.arange(0, 40)
f1 = nbinom.pmf(k=x, p=0.4, n=2)
f2 = nbinom.pmf(k=x, p=0.4, n=5)
f3 = nbinom.pmf(k=x, p=0.4, n=10)
plt.bar(x=x1, height=p1, alpha=.5, label='n=2')
plt.bar(x=x2, height=p2, alpha=.5, label='n=5')
plt.bar(x=x3, height=p3, alpha=.5, label='n=10')
plt.plot(x, f1, '-o', alpha=.5, label='n=2')
plt.plot(x, f2, '-o', alpha=.5, label='n=5')
plt.plot(x, f3, '-o', alpha=.5, label='n=10')
plt.xlim(-1,41)
plt.legend()

print('p=0.4 n=2')
calc_mean_var(x1 ,p1)
print('p=0.4 n=5')
calc_mean_var(x2 ,p2)
print('p=0.4 n=10')
calc_mean_var(x3 ,p3)

print('p=0.4 n=2: ', nbinom.stats(p=0.4, n=2))
print('p=0.4 n=5: ', nbinom.stats(p=0.4, n=5))
print('p=0.4 n=10: ', nbinom.stats(p=0.4, n=10))

超幾何分布(hypergeometric distribution)
$M$個の赤いボールと$N-M$個の白いボールが入っている壺の中から$K$個のボールを無作為に非復元中抽出で抽出したとき、赤いボールが$X$個であったとします。
このとき、$X$は次の確率分布に従います。
P(X=x|N,M,K)=\frac{\begin{pmatrix}M\\x\end{pmatrix}\begin{pmatrix}N-M\\K-x\end{pmatrix}}{\begin{pmatrix}N\\K\end{pmatrix}},\ x=0,1,\cdots,k
この分布を超幾何分布と呼びます。
期待値
\begin{align}
E[X]&=\sum_{x=0}^\infty\frac{\begin{pmatrix}M\\x\end{pmatrix}\begin{pmatrix}N-M\\K-x\end{pmatrix}}{\begin{pmatrix}N\\K\end{pmatrix}} \times x\\
&=\sum_{x=1}^\infty x\frac{\frac{M!}{x!(M-x)!}\times\frac{(N-M)!}{(K-x)!(N-M-K+x)!}}{\frac{N!}{K!(N-K)!}}\\
&=\sum_{x=1}^\infty K\frac{M}{N}\frac{\frac{(M-1)!}{(x-1)!((M-1)-(x-1))!}\times\frac{(N-M)!}{(K-x)!(N-M-K+x)!}}{\frac{(N-1)!}{(K-1)!((N-1)-(K-1))!}}\\
&= K\frac{M}{N}\sum_{x=1}^\infty \frac{\frac{(M-1)!}{(x-1)!((M-1)-(x-1))!}\times\frac{((N-1)-(M-1))!}{((K-1)-(x-1))!((N-1)-(M-1)-(K-1)+(x-1))!}}{\frac{(N-1)!}{(K-1)!((N-1)-(K-1))!}}\\
&=Kp\ (p=M/N)
\end{align}
分散
\begin{align}
E[X(X-1)]&=\sum_{x=0}^\infty\frac{\begin{pmatrix}M\\x\end{pmatrix}\begin{pmatrix}N-M\\K-x\end{pmatrix}}{\begin{pmatrix}N\\K\end{pmatrix}} \times x(x-1)\\
&=\sum_{x=1}^\infty x(x-1)\frac{\frac{M!}{x!(M-x)!}\times\frac{(N-M)!}{(K-x)!(N-M-K+x)!}}{\frac{N!}{K!(N-K)!}}\\
&=K(K-1)\frac{M(M-1)}{N(N-1)}
\end{align}
従って、
\begin{align}
Var(X)&=E[X(X-1)]+E[X]-\{E[X]\}^2\\
&=K(K-1)\frac{M(M-1)}{N(N-1)}+K\frac{M}{N}-K^2\frac{M^2}{N^2}\\
&=K(K-1)\frac{p(M-1)}{N-1}+Kp-K^2p^2\\
&=\frac{Kp}{N-1}(-K-Np+N+Kp)\\
&=\frac{N-K}{N-1}Kp(1-p)
\end{align}
scipy.statsのhypergeomを使って分布の確認していきます。
from scipy.stats import hypergeom
samples1 = hypergeom.rvs(M=100, n=10, N=10, size=1000)
samples2 = hypergeom.rvs(M=100, n=10, N=50, size=1000)
samples3 = hypergeom.rvs(M=100, n=10, N=90, size=1000)
x1, count1 = np.unique(samples1, return_counts=True)
x2, count2 = np.unique(samples2, return_counts=True)
x3, count3 = np.unique(samples3, return_counts=True)
p1 = count1 / 1000
p2 = count2 / 1000
p3 = count3 / 1000
x = np.arange(0, 40)
f1 = hypergeom.pmf(k=x, M=100, n=10, N=10)
f2 = hypergeom.pmf(k=x, M=100, n=10, N=50)
f3 = hypergeom.pmf(k=x, M=100, n=10, N=90)
plt.bar(x=x1, height=p1, alpha=.5, label='M=100 n=10 N=10')
plt.bar(x=x2, height=p2, alpha=.5, label='M=100 n=10 N=50')
plt.bar(x=x3, height=p3, alpha=.5, label='M=100 n=10 N=90')
plt.plot(x, f1, '-o', alpha=.5, label='M=100 n=10 N=10')
plt.plot(x, f2, '-o', alpha=.5, label='M=100 n=10 N=50')
plt.plot(x, f3, '-o', alpha=.5, label='M=100 n=10 N=90')
plt.xlim(-1,11)
plt.ylim(0,0.6)
plt.legend(loc='upper center')

print('M=100 n=10 N=10')
calc_mean_var(x1 ,p1)
print('M=100 n=10 N=50')
calc_mean_var(x2 ,p2)
print('M=100 n=10 N=90')
calc_mean_var(x3 ,p3)

print('M=100 n=10 N=10: ', hypergeom.stats(M=100, n=10, N=10))
print('M=100 n=10 N=50: ', hypergeom.stats(M=100, n=10, N=50))
print('M=100 n=10 N=90: ', hypergeom.stats(M=100, n=10, N=90))

samples1 = hypergeom.rvs(M=100, n=20, N=20, size=1000)
samples2 = hypergeom.rvs(M=100, n=50, N=20, size=1000)
samples3 = hypergeom.rvs(M=100, n=80, N=20, size=1000)
x1, count1 = np.unique(samples1, return_counts=True)
x2, count2 = np.unique(samples2, return_counts=True)
x3, count3 = np.unique(samples3, return_counts=True)
p1 = count1 / 1000
p2 = count2 / 1000
p3 = count3 / 1000
x = np.arange(0, 40)
f1 = hypergeom.pmf(k=x, M=100, n=20, N=20)
f2 = hypergeom.pmf(k=x, M=100, n=50, N=20)
f3 = hypergeom.pmf(k=x, M=100, n=80, N=20)
plt.bar(x=x1, height=p1, alpha=.5, label='M=100 n=20 N=20')
plt.bar(x=x2, height=p2, alpha=.5, label='M=100 n=50 N=20')
plt.bar(x=x3, height=p3, alpha=.5, label='M=100 n=80 N=20')
plt.plot(x, f1, '-o', alpha=.5, label='M=100 n=20 N=20')
plt.plot(x, f2, '-o', alpha=.5, label='M=100 n=50 N=20')
plt.plot(x, f3, '-o', alpha=.5, label='M=100 n=80 N=20')
plt.xlim(-1,21)
plt.ylim(0,0.6)
plt.legend(loc='upper center')

print('M=100 n=20 N=20')
calc_mean_var(x1 ,p1)
print('M=100 n=50 N=20')
calc_mean_var(x2 ,p2)
print('M=100 n=80 N=20')
calc_mean_var(x3 ,p3)

print('M=100 n=20 N=20: ', hypergeom.stats(M=100, n=20, N=20))
print('M=100 n=50 N=20: ', hypergeom.stats(M=100, n=50, N=20))
print('M=100 n=80 N=20: ', hypergeom.stats(M=100, n=80, N=20))

参考