論文の勉強をメモ書きレベルですがのせていきます。
構造部分に注目し、その他の部分は書いていません。ご了承ください。
今回は、以下の論文のWide ResNetの実装を行います。
実装はほとんどResNetと変わりません。
wide residual network
恒等変換を使用したresidual blockは、
x_{l+1}=x_l+F(x_l,W_l)
で表されます。
ここで、$x_l,x_{l+1}$はネットワークの$l$番目のブロックの出力で、$F$は残差関数、そして$W_l$はそのネットワークでの重みを表します。
residuak networkはこのブロックの積み重ねとなります。
residual networkには2種類のブロックがあります。
- basic 2つの3×3の畳み込み層で構成されます
- bottleneck 3×3の畳み込み層を1×1の畳み込み層ではさみこんだ構成となります
今回は、basicに注目して話を進めていきます。
このbasicnの2つの3×3の畳み込み層をB(3,3)、bottlebeckはB(1,3,1)とここでは表すこととします。
ここで、この論文で出てくるresidual blockのイメージを示します。
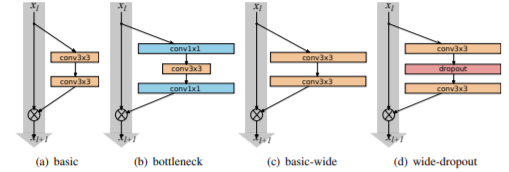
今回はResNetのときより、よりワイドな構造をもったresidual blockを実装していきます。
ResNetでBatchNormalizationとReLUは、「conv-BN-ReLU」という順番で挿入していましたが、「BN-ReLU-conv」という順番に変更します。
畳み込み層をReLUの間にドロップアウト層を入れることで過学習を防いでいます。
構造
本来、さまざまな層の深さやブロック内での畳み込み層の数などを比較していますが、ここでは割愛します。
詳細は論文を参照してください。
今回実装する構造は以下に示すものです。
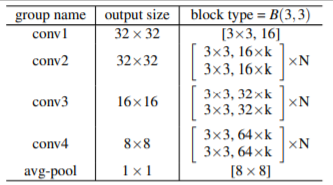
ここで、$k$はチャンネル数の大きさを表すもので$k=1$は「薄い」ネットワークであり、$k>1$のときに「ワイドな」ネットワークであるとします。
また、$N$は各ブロックの繰り返し数を決める値で、全体の層の数$n(depth)$から求められます。
ここでは、全体の層の数が$n$、チャンネルの大きさを決める因子が$k$のresidualネットワークをWRN-n-kと表すこととします。
さらに、ブロックの種類がB(3,3)であるときは、WRN-n-k-B(3,3)と表します。
学習
今回は、WRN-28-10モデルを実装していきます。
入力は、32×32のカラー画像とします。
学習には、Nesterovの加速勾配降下法を使用したSGDと、交差エントロピー誤差を使用します。
学習率は0.1で、weight decayを0.0005、momentumを0.9とします。
学習率は、エポック数が60、120、160のときに0.2倍して減衰させていきます。
実装
keras
必要なライブラリのインポートを行います。
import tensorflow.keras as keras
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Input, Conv2D, Activation, MaxPooling2D, Flatten, Dense, Dropout, GlobalAveragePooling2D, BatchNormalization, Add
from keras import backend as K
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.callbacks import LearningRateScheduler
from keras.datasets import cifar10
import numpy as np
import cv2
wide residual blockの実装をします。B(3,3)タイプのものです。
実装はResNetとほぼ同じです。
class wide_res_block(Model):
"""wide residual block"""
def __init__(self, out_channels, block_num, layer_num):
super(wide_res_block, self).__init__(name='block'+'_'+str(block_num)+'_'+str(layer_num))
block_name = '_'+str(block_num)+'_'+str(layer_num)
# shortcutとstrideの設定
if (layer_num == 0):
# 最初のresblockは(W、 H)は変更しないのでstrideは1にする
if (block_num==1):
self._is_change = False
stride = 1
else:
self._is_change = True
stride = 2
self.conv_sc = Conv2D(out_channels, kernel_size=1, strides=stride, padding='same', use_bias=False, name='conv_sc'+block_name)
self.bn_sc = BatchNormalization(name='bn_sc'+block_name)
else:
self._is_change = False
stride = 1
# 1層目 3×3 畳み込み処理を行います
self.bn1 = BatchNormalization(name='bn1'+block_name)
self.act1 = Activation('relu', name='act1'+block_name)
self.drop1 = Dropout(rate=0.3, name='drop1'+block_name)
self.conv1 = Conv2D(out_channels, kernel_size=3, strides=stride, padding='same', use_bias=False, name='conv1'+block_name)
# 2層目 3×3 畳み込み処理を行います
self.bn2 = BatchNormalization(name='bn2'+block_name)
self.act2 = Activation('relu', name='act2'+block_name)
self.drop2 = Dropout(rate=0.3, name='drop2'+block_name)
self.conv2 = Conv2D(out_channels, kernel_size=3, strides=1, padding='same', use_bias=False, name='conv2'+block_name)
self.add = Add(name='add'+block_name)
def call(self, x):
out = self.bn1(x)
out = self.act1(out)
out = self.drop1(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.act2(out)
out = self.drop2(out)
out = self.conv2(out)
if K.int_shape(x) != K.int_shape(out):
shortcut = self.conv_sc(x)
shortcut = self.bn_sc(shortcut)
else:
shortcut = x
out = self.add([out, shortcut])
return out
WideResNetを実装していきます。
depthとkを引数に与えて構築します。
class WideResNet(Model):
def __init__(self, depth, k, num_classes=10):
super().__init__()
self._layers = []
# 各ネットワークでのブロックの数
N = (depth - 4) // 6
# 入力層
self._layers += [
Conv2D(filters = 16, kernel_size = 3, strides = 1, padding = 'same', name='conv_input')
]
# Residualブロック
self._layers += [wide_res_block(out_channels=16*k, block_num=1, layer_num=i) for i in range(N)]
self._layers += [wide_res_block(out_channels=32*k, block_num=2, layer_num=i) for i in range(N)]
self._layers += [wide_res_block(out_channels=64*k, block_num=3, layer_num=i) for i in range(N)]
# 出力層
self._layers += [
BatchNormalization(name='bn_input'),
Activation('relu', name='act_input'),
GlobalAveragePooling2D(name='pool_output'),
Dense(num_classes, activation='softmax', name='output')
]
def call(self, x):
for layer in self._layers:
x = layer(x)
return x
ここで、構造の確認をします。
WideResNetでは、入力は32×32×です。
model = WideResNet(depth=28, k=10, num_classes=10)
model.build((None, 32, 32, 3)) # build with input shape.
dummy_input = Input(shape=(32, 32, 3)) # declare without batch demension.
model_summary = Model(inputs=[dummy_input], outputs=model.call(dummy_input))
model_summary.summary()
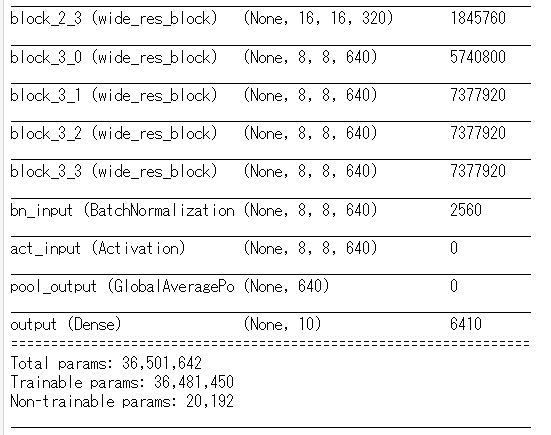
今回の学習ではエポック数に応じて学習率を小さくしていきます。
# 学習率を返す関数を用意する
def lr_schedul(epoch):
x = 0.1
if epoch >= 60:
x = 0.1*0.2
if epoch >= 120:
x = 0.1*(0.2**2)
if epoch >= 160:
x = 0.1*(0.2**3)
return x
lr_decay = LearningRateScheduler(
lr_schedul,
verbose=1,
)
sgd = SGD(lr=0.1, momentum=0.9, decay=1e-4, nesterov=True)
model.compile(loss=['categorical_crossentropy'], optimizer=sgd, metrics=['accuracy'])
pytorch
次にpytorchで実装を行います。
ほとんどResNetと同じため説明は割愛します。
import torch
import torch.nn as nn
import torch.optim as optim
import pytorch_lightning as pl
from torchmetrics import Accuracy as accuracy
class wide_res_block(nn.Module):
"""wide residual block"""
def __init__(self, out_channels, block_num, layer_num):
super(wide_res_block, self).__init__()
# 1番目のブロック以外はチャンネル数がinputとoutputで変わる(output=4×input)
if (layer_num==0):
if (block_num==1):
input_channels = 16
else:
input_channels = out_channels//2
else:
input_channels = out_channels
# shortcutとstrideの設定
if (layer_num == 0):
self._is_change = True
# 最初のresblockは(W、 H)は変更しないのでstrideは1にする
if (block_num==1):
stride = 1
else:
stride = 2
self.conv_sc = nn.Conv2d(input_channels, out_channels, kernel_size=1, stride=stride)
self.bn_sc = nn.BatchNorm2d(out_channels)
else:
self._is_change = False
stride = 1
# 1層目 3×3 畳み込み処理を行います
self.bn1 = nn.BatchNorm2d(input_channels)
self.drop1 = nn.Dropout(p=0.3)
self.conv1 = nn.Conv2d(input_channels, out_channels, kernel_size=3, stride=stride, padding=1)
# 2層目 3×3 畳み込み処理を行います
self.bn2 = nn.BatchNorm2d(out_channels)
self.drop2 = nn.Dropout(p=0.3)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
shortcut = x
out = self.bn1(x)
out = self.relu(out)
out = self.drop1(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.relu(out)
out = self.drop2(out)
out = self.conv2(out)
# Projection shortcutの場合
if self._is_change:
shortcut = self.conv_sc(shortcut)
shortcut = self.bn_sc(shortcut)
out += shortcut
return out
class WideResNet(nn.Module):
def __init__(self, depth, k, num_classes=10):
super(WideResNet, self).__init__()
# 各ネットワークでのブロックの数
N = (depth - 4) // 6
conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
self.conv1 = nn.Sequential(*[conv1])
self.conv2_x = nn.Sequential(*[wide_res_block(out_channels=16*k, block_num=1, layer_num=i) for i in range(N)])
self.conv3_x = nn.Sequential(*[wide_res_block(out_channels=32*k, block_num=2, layer_num=i) for i in range(N)])
self.conv4_x = nn.Sequential(*[wide_res_block(out_channels=64*k, block_num=3, layer_num=i) for i in range(N)])
bn = nn.BatchNorm2d(64*k)
relu = nn.ReLU(inplace=True)
pool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Sequential(*[bn, relu, pool])
self.linear = nn.Linear(in_features=640, out_features=num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.conv2_x(out)
out = self.conv3_x(out)
out = self.conv4_x(out)
out = self.fc(out)
out = out.view(out.shape[0], -1)
out = self.linear(out)
return out
from torchsummary import summary
summary(WideResNet(depth=28, k=10, num_classes=10), (3,32,32))

エポック数に応じて、学習率を下げるときにはMultiStepLRという関数が用意されています。
class WRNTrainer(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = WideResNet(depth=28, k=10, num_classes=10)
def forward(self, x):
x = self.model(x)
return x
def training_step(self, batch, batch_idx):
x, y = batch
#x, y = x.to(device), y.to(device)
y_hat = self.forward(x)
loss = nn.CrossEntropyLoss()(y_hat, y)
return {'loss': loss, 'y_hat':y_hat, 'y':y, 'batch_loss': loss.item()*x.size(0)}
def validation_step(self, batch, batch_idx):
x, y = batch
#x, y = x.to(device), y.to(device)
y_hat = self.forward(x)
loss = nn.CrossEntropyLoss()(y_hat, y)
return {'y_hat':y_hat, 'y':y, 'batch_loss': loss.item()*x.size(0)}
def test_step(self, batch, batch_nb):
x, y = batch
#x, y = x.to(device), y.to(device)
y_hat = self.forward(x)
loss = nn.CrossEntropyLoss()(y_hat, y)
y_label = torch.argmax(y_hat, dim=1)
acc = accuracy()(y_label, y)
return {'test_loss': loss, 'test_acc': acc}
def training_epoch_end(self, train_step_output):
y_hat = torch.cat([val['y_hat'] for val in train_step_outputs], dim=0)
y = torch.cat([val['y'] for val in train_step_outputs], dim=0)
epoch_loss = sum([val['batch_loss'] for val in train_step_outputs]) / y_hat.size(0)
preds = torch.argmax(y_hat, dim=1)
acc = accuracy()(preds, y)
self.log('train_loss', epoch_loss, prog_bar=True, on_epoch=True)
self.log('train_acc', acc, prog_bar=True, on_epoch=True)
print('---------- Current Epoch {} ----------'.format(self.current_epoch + 1))
print('train Loss: {:.4f} train Acc: {:.4f}'.format(epoch_loass, acc))
def validation_epoch_end(self, val_step_outputs):
y_hat = torch.cat([val['y_hat'] for val in val_step_outputs], dim=0)
y = torch.cat([val['y'] for val in val_step_outputs], dim=0)
epoch_loss = sum([val['batch_loss'] for val in val_step_outputs]) / y_hat.size(0)
preds = torch.argmax(y_hat, dim=1)
acc = accuracy()(preds, y)
self.log('val_loss', epoch_loss, prog_bar=True, on_epoch=True)
self.log('val_acc', acc, prog_bar=True, on_epoch=True)
print('valid Loss: {:.4f} valid Acc: {:.4f}'.format(epoch_loss, acc))
# New: テストデータに対するエポックごとの処理
def test_epoch_end(self, test_step_outputs):
y_hat = torch.cat([val['y_hat'] for val in test_step_outputs], dim=0)
y = torch.cat([val['y'] for val in test_step_outputs], dim=0)
epoch_loss = sum([val['batch_loss'] for val in test_step_outputs]) / y_hat.size(0)
preds = torch.argmax(y_hat, dim=1)
acc = accuracy()(preds, y)
self.log('test_loss', epoch_loss, prog_bar=True, on_epoch=True)
self.log('test_acc', acc, prog_bar=True, on_epoch=True)
print('test Loss: {:.4f} test Acc: {:.4f}'.format(epoch_loss, acc))
def configure_optimizers(self):
optimizer = optim.SGD(self.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4, nesterov=True)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[60, 120, 160], gamma=0.2)
return {'optimizer': optimizer, 'lr_scheduler': scheduler, 'monitor': 'val_loss'}
これでWideResNetの実装を終わります。
ResNetの派生形をしばらく扱っていきます。