とても有名な「統計学入門」をpythonで実装しながら読んでいきます。
本をしっかり読むことと実装の勉強が目的ですので説明が不足していたりします。
また、実装方法に関してはベストなものではないと思いますのでご了承ください。
前回
推定
仮説検定
検定の考え方
有意性検定
仮説検定の目的は、母集団について仮定された命題を、標本に基づいて検証することである。
理論比からのずれが誤差の範囲内であるか、それ以上の何かの意味のあるものかということが重要である。
後者の場合、統計学では仮説からのずれは有意であるという。
ここに立てられた仮説を統計的仮説または仮説という。したがって、仮説検定とは統計的仮説の有意性検定にほかならない。
有意性は標本が有意なずれを示す確率で表される。あらかじめその程度の基準の確率である有意水準$\alpha$を考えておく。
仮説検定とは、仮説が有意であるか否かに応じてそれを棄却するかしないかを決定することである。
帰無仮説と対立仮説
もとの仮説を帰無仮説、これと対立する仮説を対立仮説という。
それぞれ、$H_0,H_1$ あるいは$H_1,H_2$と記す。
ここで、2つの誤り、(a)帰無仮説が正しいのに、それを棄却する第一種の誤り、および(b)帰無仮説が誤っているのに、それを採択する第二種の誤りが考えられる。
帰無仮説の採択について
有意性検定は、帰無仮説の下でわれわれが期待する結果が生じなかったことを根拠として、仮説を棄却、否定することが主な内容である。
これは、論理学では背理法といわれているものである。
棄却域と両側・片側検定
ここでは、t検定の例を考える。
正規母集団$N(\mu,\sigma^2)$から大きさ$n=25$の標本を抽出して、$\bar{X}=13.7,s=2.3$を得た。
これをもとに帰無仮説
$$
H_0:\mu=15
$$
を対立仮説
$$
H_1:\mu\neq 15
$$
に対して、有意水準$\alpha=0.05$で検定する。
検定に用いる統計量(検定統計量)として、スチューデントのt統計量を計算すると、
$$
t=\frac{13.7-15}{2.3\sqrt{25}}=-2.83
$$
となる。
有意水準$\alpha=0.05$にちょうど対応する$t$分布$t(24)$のパーセント点は、$t_{0.025}(24)=2.06$であるから、$|-2.83|>2.06$より、有意水準5%で帰無仮説を棄却する。
いま、帰無仮説はそのままで、対立仮説を、
$$
H_1':\mu<15
$$
とすると、$\bar{X}$が$\mu=15$より相当に小さくなった場合にだけ帰無仮説を棄却すればよいから、
$$
t=(\bar{X}-15)\ /\ (2\sqrt{n})
$$
において、$t$が十分負になったときにだけ、帰無仮説を棄却すればよい。
いま、$t_{0.05}(24)=1.71$であるから、$-2.83<-1.71$、よって、この場合も有意水準5%で帰無仮説を棄却する。
片側及び両側検定における棄却域を図に示す。
from scipy import stats
import numpy as np
import matplotlib.pyplot as plt
# t分布
x = np.arange(-4,4,0.1)
t_dist = stats.t.pdf(x, df=25)
# パーセント点
t0025 = stats.t.ppf(0.025,24)
t005 = stats.t.ppf(0.05,24)
# プロット
plt.plot(x, t_dist)
plt.vlines([t0025, -t0025],0,0.5, color='red', linestyles='--')
plt.vlines([t005],0,0.5, color='green', linestyles='--')
plt.fill_between(x=np.arange(-4,t005,0.01), y1=stats.t.pdf(np.arange(-4,t005,0.01), df=25), color='green', alpha=.5)
plt.fill_between(x=np.arange(-4,t0025,0.01), y1=stats.t.pdf(np.arange(-4,t0025,0.01), df=25)*0.7, color='red', alpha=.5)
plt.fill_between(x=np.arange(-t0025,4,0.01), y1=stats.t.pdf(np.arange(-t0025,4,0.01), df=25)*0.7, color='red', alpha=.5)
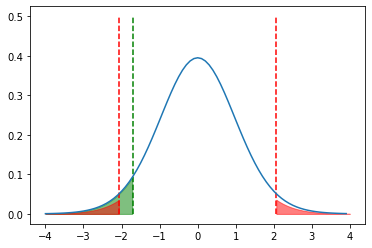
帰無仮説の棄却すべき統計量の値の集合を棄却域といい、棄却しない領域を採択域という。
採択域は%T=0%の周辺の領域となるが、棄却域は対立仮説が$H_1$のような両側対立仮説のときは、$t$の値が著しく0から外れた領域
$$
|t|>t_{\alpha\ /\ 2}(n-1)
$$
となる。
これを両側検定という。
$H_1'$のような片側対立仮説に対しては、$\bar{X}$が十分小さいところに棄却域が定められ、片側検定となる。
$$
t<-t_{\alpha}(n-1)
$$
となる。なた、$\mu>c$の形の片側対立仮説もあるが、
$$
t>t_{\alpha}(n-1)
$$
が棄却域となる。
正規母集団に対する仮説検定
母平均に関する検定
両側検定
両側検定では、帰無仮説、対立仮説は、
$$
H_0:\mu=\mu_0,\hspace{5mm}H_1:\mu\neq\mu_0
$$
で与えられる。
$\mu$に関する検定は標本平均$\bar{X}$が$\mu_0$からどれくらい離れているかを比較することによって行われる。
$\sigma^2$が既知のとき 検定統計量$Z$は、$\bar{X}$の標準化変数
$$
Z=\frac{\bar{X}-\mu}{\sigma\ /\ \sqrt{n}}
$$
である。
帰無仮説が正しければ、$\mu=\mu_0$において$Z$は標準正規分布$N(0,1)$に従う。
パーセント点$Z_{\alpha\ /\ 2}$と比較して$|Z|>Z_{\alpha/2}$では$H_0$を棄却し、$Z\leq Z_{\alpha\ /\ 2}$では$H_0$を棄却しない。
$\sigma^2$が未知のとき 母分散$\sigma^2$が未知であるときは、$\sigma^2$を$s^2$で置き換えたスチューデントのt統計量
$$
t=\frac{\bar{X}-\mu}{s\ /\ \sqrt{n}}
$$
を検定統計量とする。仮説が正しければ、$\mu=\mu_0$のときには、$t$は自由度$n-1$の$t$分布$t(n-1)$に従うからパーセント点$t_{\alpha\ /\ 2}(n-1)$と比較して、$|t|>t_{\alpha\ /\ 2}$では$H_0$を棄却し、$t\leq t_{\alpha\ /\ 2}$では$H_0$を棄却しない。
これらの検定をスチューデントのt検定と呼ぶ。
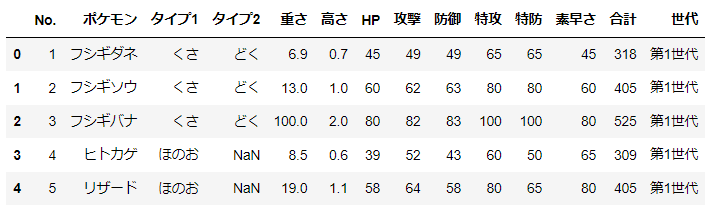
ポケモンデータを準備し、これを母集団とする。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
d = pd.read_csv('pokemon_for_stats.csv').iloc[:,1:]
gen = ["第1世代"]*151+["第2世代"]*100+["第3世代"]*135+["第4世代"]*107+["第5世代"]*156+["第6世代"]*72+["第7世代"]*88+["第8世代"]*89
d['世代'] = gen
num_cols = ['重さ','高さ','HP','攻撃','防御','特攻','特防','素早さ','合計']
d.head()
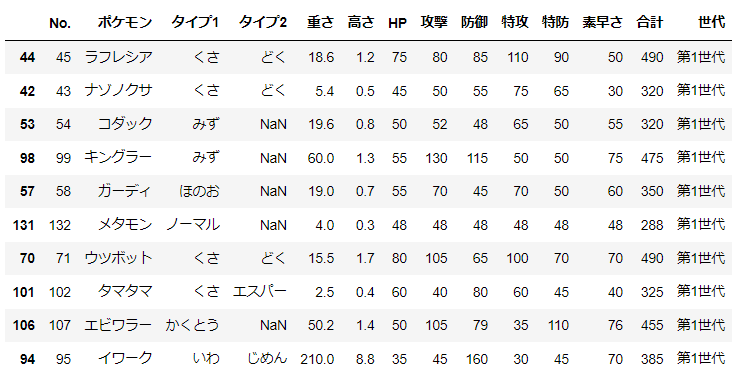
「第1世代のポケモンの種族値は全体に対して差はあるか」を確認する。
差はない、つまり「第1世代のポケモンの種族値と全体の種族値は等しい」を帰無仮説、「第1世代のポケモンの種族値と全体の種族値は異なる」を対立仮説として検定を行う。有意水準は5%とする。
n = 10
d_1gen = d.query("世代=='第1世代'").sample(n)
d_1gen
# 有意水準
alpha = 0.05
# 母集団の平均値
mu = d['合計'].mean()
# 対称の平均値・標準偏差
X_bar = d_1gen['合計'].mean()
s = d_1gen['合計'].std(ddof=1)
# t統計量
t = (X_bar-mu)/(s/np.sqrt(n))
# p値
p = stats.t.sf(t, n-1)*2
# t分布のパーセント点
t0025 = stats.t.ppf(alpha/2, n-1)
print('t 0.025: ', -t0025)
print('t value: ', t)
print('p value: ', p)
print('judge: ', p<alpha)
t 0.025: 2.262157162740992
t value: -2.263445638144181
p value: 1.9501051900089519
judge: False
帰無仮説は棄却されず採択される。
「第1世代のポケモンの種族値は全体に対して差があるとは言えない」と結論される。
同様の計算はscipyで実装されている関数を利用できる。
stats.ttest_1samp(d_1gen['合計'], d['合計'].mean(), alternative='two-sided')
Ttest_1sampResult(statistic=-2.263445638144181, pvalue=0.049894809991048145)
片側検定
帰無仮説、対立仮説は、
$$
H_0:\mu=\mu_0,\hspace{5mm}H_1:\mu>\mu_0
$$
で与えられる時を考える(右肩側対立仮説)。
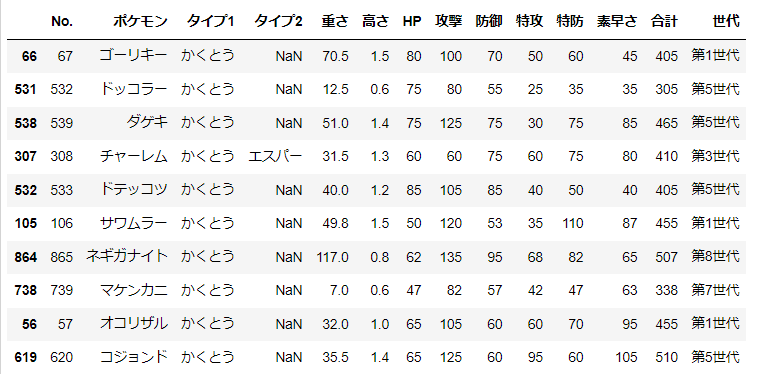
「かくとうタイプのポケモンは全体と比べて攻撃力が高い」という主張が正しいかを確認を行う。
帰無仮説は「かくとうタイプの攻撃力の平均値と全体の攻撃力の平均値が等しい」であり対立仮説は「かくとうタイプのポケモンは全体と比べて攻撃力が高い」である。高いことを確認したので右片側検定を行う。
有意水準は5%とする。
d_kakuto = d.query("タイプ1=='かくとう'").sample(n)
d_kakuto
# 有意水準
alpha = 0.05
# 母集団の平均値
mu = d['攻撃'].mean()
# 対称の平均値・標準偏差
X_bar = d_kakuto['攻撃'].mean()
s = d_kakuto['攻撃'].std(ddof=1)
# t統計量
t = (X_bar-mu)/(s/np.sqrt(n))
# p値
p = stats.t.sf(t, n-1)
# t分布のパーセント点
t095 = stats.t.ppf(1-alpha, n-1)
print('t 0.95: ', t095)
print('t pavlue: ', t)
print('p value: ', p)
print('judge: ', p<alpha)
t 0.95: 1.8331129326536335
t pavlue: 3.4536095631774475
p value: 0.0036166906944846053
judge: True
帰無仮説は棄却され、「かくとうタイプのポケモンは全体と比べて攻撃力が高い」という対立仮説が採択された。
scipyを使って同様の計算を行う。
stats.ttest_1samp(d_kakuto['攻撃'], d['攻撃'].mean(), alternative='greater')
Ttest_1sampResult(statistic=3.4536095631774466, pvalue=0.0036166906944846127)
母分散に対する仮説検定
母分散$\sigma^2$に対する帰無仮説$H_0:\sigma^2=\sigma_0^2$の検定は、標本分散$s^2$によって検定統計量
$$
\chi^2=(n-1)s^2\ /\ \sigma_0^2
$$
が、帰無仮説のもとで自由度$(n-1)$の$\chi^2$分布$\chi^2(n-1)$に従うという性質を用いて行われる。
検定の有意水準を$\alpha$とするとき、$\chi^2(n-1)$のパーセント点$\chi_{1-\alpha\ /\ 2}^2(n-1),\chi_{\alpha\ /\ 2}^2(n-1)$などを求めておき、
(a)対立仮説が$H_1:\sigma^2\neq\sigma_0^2$のときは、両側検定
$\chi_{1-\alpha\ /\ 2}^2(n-1)<\chi^2<\chi_{\alpha\ /\ 2}^2(n-1)$のとき$H_0$を棄却せず、それ以外は棄却する
(b)対立仮説が$H_1:\sigma^2>\sigma_0^2$のときは、右片側検定
$\chi^2>\chi_{\alpha}^2(n-1)$のとき$H_0$を棄却し、それ以外は棄却しない
同じく、$H_1:\sigma^2<\sigma_0^2$のときは、右片側検定
$\chi^2<\chi_{1-\alpha}^2(n-1)$のとき$H_0$を棄却し、それ以外は棄却しない
これらの検定を正規母集団の母分散についての$\chi^2$検定という。
ここでは例として、「第2世代のポケモンの攻撃力は全体と比べてばらつきが異なるか」を調べる。
帰無仮説は「第2世代のポケモンの攻撃力の分散は全体の分散と等しい」であり、対立仮説は「第2世代のポケモンの攻撃力は全体と比べてばらつきが異なる」である。有意水準5%の両側検定を行う。
# 有意水準
alpha = 0.05
# 標本数
n = 20
# サンプリング
d_2gen = d.query("世代=='第2世代'").sample(n)
# 母分散
sigma2 = d['攻撃'].var()
# 標本分散
s2 = d_2gen['攻撃'].var(ddof=1)
print('sigma0^2: ', sigma2)
print('s2: ', s2)
# カイ二乗統計量
chi_value = (n-1)*(s2)/(sigma2)
# p値
p = stats.chi2.sf(chi_value, df=n-1)*2
# パーセント点
chi0025 = stats.chi2.ppf(0.025, df=n-1)
chi0975 = stats.chi2.ppf(0.975, df=n-1)
print('chi 0.025 - 0.975: ', chi0025, chi0975)
print('chi pavlue: ', chi_value)
print('p value: ', p)
print('judge: ', p<alpha)
sigma0^2: 880.0453938269858
s2: 713.1447368421053
chi 0.025 - 0.975: 8.906516481987971 32.85232686172969
chi pavlue: 15.396648962705486
p value: 1.3941520374094625
judge: False
帰無仮説は棄却されず、「第2世代のポケモンの攻撃力の分散は全体の分散と異なる」とはいえないと結論される。
次に「いわタイプのポケモンの防御力の分散は全体の分散より大きい」ことを確かめる。
帰無仮説は「いわタイプのポケモンの防御力の分散は全体の分散と等しい」とし、対立仮説を「いわタイプのポケモンの防御力の分散は全体の分散より大きい」とした有意水準5%の右片側検定を行う。
# 有意水準
alpha = 0.05
# 標本数
n = 30
# サンプリング
d_kakuto = d.query("タイプ1=='いわ'").sample(n)
# 母分散
sigma2 = d['防御'].var()
# 標本分散
s2 = d_kakuto['防御'].var(ddof=1)
print('sigma0^2: ', sigma2)
print('s2: ', s2)
# カイ二乗統計量
chi_value = (n-1)*(s2)/(sigma2)
# p値
p = stats.chi2.sf(chi_value, df=n-1)
# パーセント点
chi095 = stats.chi2.ppf(0.95, df=n-1)
print('chi 0.95: ', chi095)
print('chi pavlue: ', chi_value)
print('p value: ', p)
print('judge: ', p<alpha)
sigma0^2: 874.0162481719565
s2: 1325.4436781609193
chi 0.95: 42.55696780429269
chi pavlue: 43.978434894158035
p value: 0.03687465019157979
judge: True
帰無仮説は棄却され、「いわタイプのポケモンの防御力の分散は全体の分散より大きい」という対立仮説が採択された。
母平均の差の検定
たとえば、新しい治療法の効果を調べる場合を考え、患者を二つのグループに分けて、一方のみに新しい治療法を行い、二つのグループで結果に差があるかどうかを検定する。
これを2標本検定という。
治療等を行ったグループを一般的に処理群、行わずに比較対照の基準とするグループを対照群あるいは制御群という。
二つの正規母集団$N(\mu_1,\sigma_1^2),N(\mu_2,\sigma_2^2)$それぞれから大きさ$m,n$の標本、$X_1,X_2,\cdots,Y_1,Y_2,\cdots,Y_n$を抽出したとする。このとき、帰無仮説は
$$
H_0:\mu_1=\mu_2
$$
であり、対立仮説は、
(a)両側ならば$H_1:\mu_1\neq\mu_2$
(b)片側ならば$H_1:\mu_1>\mu_2$または$H_1:\mu_1<\mu_2$
である。
2つの分散が等しく、$\sigma_1^2=\sigma_2^2=\sigma^2$であるときには、二つの標本平均を$\bar{X},\bar{Y}$とし、$\sigma^2$を
$$
s^2=\frac{\sum_{i=1}^m(X_i-\bar{X})^2+\sum_{j=1}^n(Y_i-\bar{Y})^2}{m+n-2}=\frac{(m-1)s_1^2+(n-1)s_2^2}{m+n-2}
$$
で推定すると、$H_0$のもとでは2標本t統計量
$$
t=\frac{\bar{X}-\bar{Y}}{s\sqrt{\frac{1}{m}+\frac{1}{n}}}
$$
は、$m+n-2$のt分布$t(m+n-2)$に従う。
(a)では両側検定となり、$|t|>t_{\alpha\ /\ 2}(m+n-2)$のとき帰無仮説を棄却し、それ以外は棄却しない。
(b)では片側検定となり、それぞれ$t>t_{\alpha}(m+n-2),t<-t_{\alpha}(m+n-2)$のとき帰無仮説を棄却し、それ以外は棄却しない。
母分散が等しくないときは、$s_1^2=\sum(X_i-\bar{X})\ /\ (m-1),s_2^2=\sum(X_i-\bar{X})\ /\ (n-1)$とすると、帰無仮説が正しい場合、
$$
t=\frac{\bar{X}-\bar{Y}}{\sqrt{\frac{s_1^2}{m}+\frac{s_2^2}{n}}}
$$
は近似的に自由度が
$$
\nu=\frac{(s_1^2\ /\ m+s_2^2\ /\ n)^2}{\frac{(s_1^2\ /\ m)^2}{m-1}+\frac{(s_2^2\ /\ n)^2}{n-1}}
$$
に最も近い整数$\nu^$の自由度の$t$分布$t(\nu^)$に従う。
この$t$値を使用した検定をウェルチの検定と呼ぶ。
ここでは、「第1世代のポケモンの攻撃力と第2世代のポケモンの攻撃力が変わらない」という帰無仮説のもと、有意水準5%の両側検定を行う。
ただし、第1世代のポケモンの攻撃力と第2世代のポケモンの攻撃力は等分散であると仮定した。
# 有意水準
alpha = 0.05
# 標本数
m = 30
n = 20
# サンプリング
d_1gen = d.query("世代=='第1世代'").sample(m)
d_2gen = d.query("世代=='第2世代'").sample(n)
# 標本平均
X_bar = d_1gen['攻撃'].mean()
Y_bar = d_2gen['攻撃'].mean()
# 母分散
sigma2 = d['攻撃'].var()
# 標本分散
s12 = d_1gen['攻撃'].var(ddof=1)
s22 = d_2gen['攻撃'].var(ddof=1)
# 標本分散の合計
s2 = ((m-1)*s12+(n-1)*s22)/(m+n-2)
# t統計量
t_value = (X_bar-Y_bar)/(np.sqrt(s2*(1/m+1/n)))
# p値
p = stats.t.sf(t_value, m+n-2)*2
print('X_bar: ',X_bar)
print('Y_bar: ',Y_bar)
print('sigma0^2: ', sigma2)
print('s2: ', s2)
# パーセント点
t0025 = stats.t.ppf(0.025, df=m+n-2)
t0975 = stats.t.ppf(0.975, df=m+n-2)
print('t 0.025 - 0.975: ', t0025, t0975)
print('t pavlue: ', t_value)
print('p pavlue: ', p)
print('judge: ', p<alpha)
X_bar: 74.5
Y_bar: 69.55
sigma0^2: 880.0453938269858
s2: 667.9677083333332
t 0.025 - 0.975: -2.010634754696446 2.0106347546964454
t pavlue: 0.6634651080559695
p pavlue: 0.5102068014325126
judge: False
「第1世代のポケモンの攻撃力と第2世代のポケモンの攻撃力が変わらない」という帰無仮説は棄却されず、「第1世代のポケモンの攻撃力と第2世代のポケモンの攻撃力に違いがある」とは言えない。
scipyを使った計算例も示す。
stats.ttest_ind(d_1gen['攻撃'], d_2gen['攻撃'], alternative='two-sided')
Ttest_indResult(statistic=0.6634651080559695, pvalue=0.5102068014325126)
(棄却される例として)もう1つ例を示す。
「かくとうタイプの方がフェアリータイプより攻撃力が高い」ことを確認するため、「かくとうタイプとフェアリータイプは攻撃力が同じ」という帰無仮説のもと、右側片側検定を行う。有意水準は5%とする。
ただし、かくとうタイプのポケモンの攻撃力とフェアリータイプのポケモンの攻撃力は等分散ではない仮定した。
# 有意水準
alpha = 0.05
# 標本数
m = 30
n = 20
# サンプリング
d_type1 = d.query("タイプ1=='かくとう'").sample(m)
d_type2 = d.query("タイプ2=='フェアリー'").sample(n)
# 標本平均
X_bar = d_type1['攻撃'].mean()
Y_bar = d_type2['攻撃'].mean()
# 母分散
sigma2 = d['攻撃'].var()
# 標本分散
s12 = d_type1['攻撃'].var(ddof=1)
s22 = d_type2['攻撃'].var(ddof=1)
# t統計量
t_value = (X_bar-Y_bar)/(np.sqrt((s12/m+s22/n)))
# p値
p = stats.t.sf(t_value, m+n-2)
print('X_bar: ',X_bar)
print('Y_bar: ',Y_bar)
# パーセント点
t005 = stats.t.ppf(0.95, df=m+n-2)
print('t 0.95: ', t005)
print('t pavlue: ', t_value)
print('p pavlue: ', p)
print('judge: ', p<alpha)
X_bar: 98.76666666666667
Y_bar: 65.75
t 0.95: 1.6772241953450393
t pavlue: 4.06871259114461
p pavlue: 8.76429109569337e-05
judge: True
帰無仮説は棄却され、「かくとうタイプの方がフェアリータイプより攻撃力が高い」という対立仮説が採択された。
ここでもscipyによる計算例を示す。
stats.ttest_ind(d_type1['攻撃'], d_type2['攻撃'], equal_var=False, alternative='greater')
Ttest_indResult(statistic=4.06871259114461, pvalue=0.00010545831099807586)
母分散の比の検定
母分散の比の検定の帰無仮説は
$$
H_0:\sigma_1^2=\sigma_2^2
$$
対立仮説は
$$
H_0:\sigma_1^2\neq\sigma_2^2
$$
である。
ここで、$H_0$のもとでのフィッシャーの分散比を
$$
F=s_1^2\ /\ s_2^2
$$
ただし、
$$
s_1^2=\sum(X_i-\bar{X})\ /\ (m-1),\hspace{5mm},s_2^2=\sum(X_i-\bar{X})\ /\ (n-1)
$$
とすると、帰無仮説が正しい場合、$F$は自由度$(m-1,n-1)$のF分布$F(m-1,n-1)$に従う。
したがって、このF値が
$$
F_{1-\alpha\ /\ 2}(m-1,n-1)\leq F \leq F_{\alpha\ /\ 2}(m-1,n-1)
$$
であるときは帰無仮説を棄却せず
$$
FF_{\alpha\ /\ 2}(m-1,n-1)
$$
であるときは、帰無仮説を棄却する。
これらF統計量を検定統計量として用いる検定を一般にF検定という。
ここでは、「第1世代のポケモンの攻撃力と第2世代のポケモンの攻撃力分散が等しい」を帰無仮説、「第1世代のポケモンの攻撃力と第2世代のポケモンの攻撃力分散は異なる」を対立仮説として、有意水準5%の両側検定を行う。
# 有意水準
alpha = 0.05
# 標本数
m = 30
n = 20
# サンプリング
d_1gen = d.query("世代=='第1世代'").sample(m)
d_2gen = d.query("世代=='第2世代'").sample(n)
# 標本分散
s12 = d_1gen['攻撃'].var(ddof=1)
s22 = d_2gen['攻撃'].var(ddof=1)
# F統計量
F_value = s12/s22
# p値
p = stats.f.sf(F_value, dfn=m-1, dfd=n-1)*2
if p >= 1:
p = 1
# パーセント点
F0025 = stats.f.ppf(0.025, dfn=n-1, dfd=m-1)
F0975 = stats.f.ppf(0.975, dfn=n-1, dfd=m-1)
print('F 0025 - F 0975: ', F0025, F0975)
print('F value: ', F_value)
print('p pavlue: ', p)
print('judge: ', p<alpha)
F 0025 - F 0975: 0.4163296675877341 2.2312738331007584
F value: 1.3918921554800008
p pavlue: 0.4567599372718125
judge: False
帰無仮説は棄却されず、「第1世代のポケモンの攻撃力と第2世代のポケモンの攻撃力分散は異なるといえない」と結論される。
stats.levene(d_1gen['攻撃'], d_2gen['攻撃'])
LeveneResult(statistic=1.0083634528016154, pvalue=0.32033074637027253)
次に、平均の差の検定で見たようにかくとうタイプとフェアリータイプについて確認する。
「かくとうタイプとフェアとリータイプの攻撃力の分散は等しい」を帰無仮説、「かくとうタイプとフェアリータイプの攻撃力の分散は異なる」を対立仮説として、有意水準5%の右片側検定を行う。
# 有意水準
alpha = 0.05
# 標本数
m = 30
n = 20
# サンプリング
d_type1 = d.query("タイプ1=='かくとう'").sample(m)
d_type2 = d.query("タイプ2=='フェアリー'").sample(n)
# 標本分散
s12 = d_type1['攻撃'].var(ddof=1)
s22 = d_type2['攻撃'].var(ddof=1)
# F統計量
F_value = s12/s22
# p値
p = stats.f.sf(F_value, dfn=m-1, dfd=n-1)
if p >= 1:
p = 1
# パーセント点
F095 = stats.f.ppf(0.95, dfn=m-1, dfd=m-1)
print('F 095: ', F095)
print('F value: ', F_value)
print('p pavlue: ', p)
print('judge: ', p<alpha)
F 095: 1.8608114354760754
F value: 0.9067798189558943
p pavlue: 0.6032878016690615
judge: False
帰無仮説は棄却されず、「かくとうタイプはフェアの攻撃力の分散はリータイプの攻撃力の分散が異なるとはいえない」と結論される。
stats.bartlett(d_type1['攻撃'], d_type2['攻撃'])
BartlettResult(statistic=0.054119052330868195, pvalue=0.8160448315732844)
いろいろのカイ二乗検定
適合度の検定
仮定された理論上の確率分布に対して、標本から求められた度数が適合するか否かを検証するのが適合度の$\chi^2$検定である。
ある属性$A$によって、$n$個の個体が$k$種のカテゴリー$A_1,A_2,\cdots,A_k$へ分類されたとし、各カテゴリへ属する観測度数が$f_1,f_2,\cdots,f_k$であったとする。これが、各カテゴリの理論確率$p_1,p_2,\cdots,p_k$に適合するかを見るためには、理論度数$np_1,np_2,\cdots,np_k$を、観測度数と比べ、K.ピアソンの適応基準
$$
\chi^2=\sum_{i=1}^k\frac{(f_i-np_i)^2}{np_i}
$$
で判断すればよい。
この適合度の$\chi^2$統計量$\chi^2$は$n$が大きいとき、自由度$k-1$の$\chi^2$分布$\chi^2(k-1)$に従う。
帰無仮説を、
$$
H_0:P(A_1)=p_1,\cdots,P(A_k)=p_k
$$
とするとき、
$$
\chi^2>\chi^2_\alpha(k-1)
$$
ならば、仮説$H_0$は有意水準$\alpha$で棄却される。
ここで、適合度の検定の原理を
$$
\chi^2=\sum(O-E)^2\ /\ E
$$
と要約する。ここで、$(O-E)/E$は相対誤差であり、$\sum$は一般にすべてのカテゴリにわたる和である。
分割表の独立性と検定
$n$個の個体に対して二つの異なる属性$A,B$を同時に測定したとする。
$A$は$A_1,A_2,\cdots,A_r$のカテゴリに、$B$は$B_1,B_2,\cdots,B_c$のカテゴリに分割されているとする。
この二つの属性について度数を集計することにより、分割表を得ることができる。
分割表において独立とは、$A_i\cap B_j$の各確率に対し、帰無仮説
$H_0$すべての$i,j$に対し、$P(A_i\cap B_j)=P(A_i)P(B_j)$
であることをいう。いいかえれば、$A_1,\cdots,A_r$の条件付確率がすべての$B_j$によらないことである。
$$
P(A_i\cap B_j)=p_{ij}\
P(A_i)=p_{i・}=\sum_jp_{ij}\
P(B_j)=p_{・j}=\sum_ip_{ij}
$$
と表せば、$p_{i・},p_{・j}$は$p_{ij}$の周辺確率分布で、独立とは、
すべての$i,j$に対し、$p_{ij}=p_{i・}p_{・j}$
が成立することを意味する。
$p_{i・},p_{・j}$は、分割表の周辺度数$f_{i・},f_{・j}$に対応するから、相対度数による推定値
\hat{p}_{i・}=f_{i・}\ /\ n\hspace{5mm}\hat{p}_{・j}=f_{・j}\ /\ n
によって置き換えれば、$H_0$が成立しているときには、$\hat{p}{ij}=\hat{p}{i・}\hat{p}{・j}$は確率$p{ij}=P(A_i\cap B_i)$の推定値
、そこの理論度数は、
E_{ij}=n\hat{p}_{i・}\hat{p}_{・j}=f_{i・}f_{・j}\ /\ n
となる。
他方、観測度数を
$$
O_{ij}=f_{ij}
$$
とおいて、$n$が大きいとき、適合度の検定の原理を用いれば、独立性の$\chi^2$検定の基準
$$
\begin{align}
\chi^2&=\sum_i\sum_j\frac{(f_{ij}-f_{i・}-f_{・j}\ /\ n)^2}{f_{i・}f_{・j}/n}\
&=\sum_i\sum_j\frac{(nf_{ij}-f_{i・}-f_{・j})^2}{nf_{i・}f_{・j}}
\end{align}
$$
を得る。$\chi^2$分布の自由度は$(r-1)(c-1)$となる。
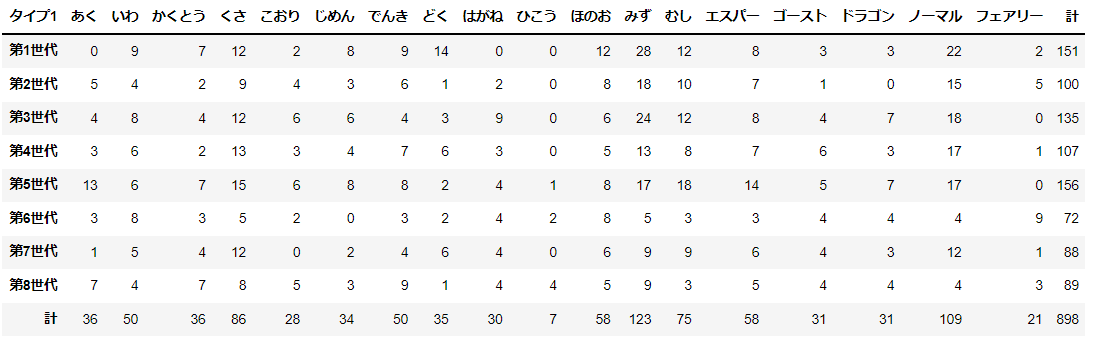
世代とタイプの分割表を示す。
d_cross = pd.crosstab(d['世代'], d['タイプ1'])
d_cross2 = pd.concat([d_cross, pd.DataFrame(d_cross.sum(axis=0), columns=['計']).T])
d_cross2['計'] = d_cross2.sum(axis=1)
d_cross2
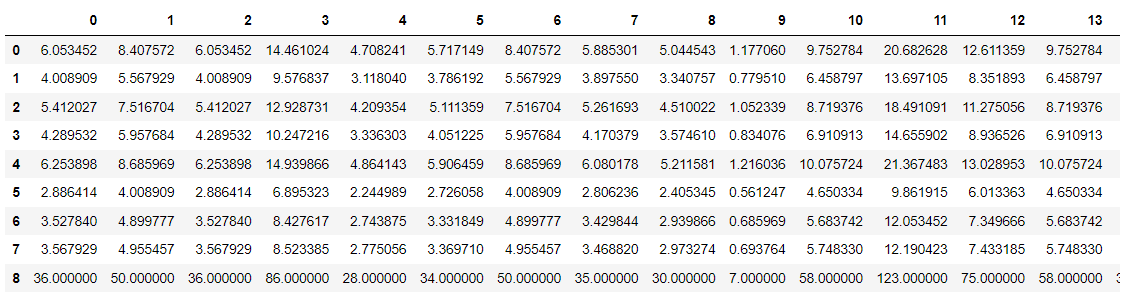
期待度数の計算を行う。
E = pd.DataFrame(np.matrix(d_cross2.iloc[:,-1]).T @ np.matrix(d_cross2.iloc[-1,:])/len(d))
E
この分割表の$\chi^2$統計量を示す。
chi2_value = np.sum((d_cross2.values[:-1,:-1] - E.values[:-1,:-1])**2/E.values[:-1,:-1])
chi2_value
203.61047516399066
この分割表の$\chi^2$統計量およびp値を示す。
chi2_value = np.sum((d_cross2.values[:-1,:-1] - E.values[:-1,:-1])**2/E.values[:-1,:-1])
chi2_value
203.61047516399066
# p値
p = stats.chi2.sf(chi2_value, df=(E.shape[0]-1)*(E.shape[1]-1))
p
0.0007961578679062336
従って、ポケモンの世代とタイプの数の関係は独立ではなく、何か関係があると結論される。
同様の計算はscipyに実装されている。
stats.chi2_contingency(d_cross2, correction=False)
(203.61047516399066,
0.0007961578679062336,
144,
array([[6.05345212e+00, 8.40757238e+00, 6.05345212e+00, 1.44610245e+01,
4.70824053e+00, 5.71714922e+00, 8.40757238e+00, 5.88530067e+00,
5.04454343e+00, 1.17706013e+00, 9.75278396e+00, 2.06826281e+01,
1.26113586e+01, 9.75278396e+00, 5.21269488e+00, 5.21269488e+00,
1.83285078e+01, 3.53118040e+00, 1.51000000e+02],
[4.00890869e+00, 5.56792873e+00, 4.00890869e+00, 9.57683742e+00,
3.11804009e+00, 3.78619154e+00, 5.56792873e+00, 3.89755011e+00,
3.34075724e+00, 7.79510022e-01, 6.45879733e+00, 1.36971047e+01,
8.35189310e+00, 6.45879733e+00, 3.45211581e+00, 3.45211581e+00,
1.21380846e+01, 2.33853007e+00, 1.00000000e+02],
[5.41202673e+00, 7.51670379e+00, 5.41202673e+00, 1.29287305e+01,
4.20935412e+00, 5.11135857e+00, 7.51670379e+00, 5.26169265e+00,
4.51002227e+00, 1.05233853e+00, 8.71937639e+00, 1.84910913e+01,
1.12750557e+01, 8.71937639e+00, 4.66035635e+00, 4.66035635e+00,
1.63864143e+01, 3.15701559e+00, 1.35000000e+02],
[4.28953229e+00, 5.95768374e+00, 4.28953229e+00, 1.02472160e+01,
3.33630290e+00, 4.05122494e+00, 5.95768374e+00, 4.17037862e+00,
3.57461024e+00, 8.34075724e-01, 6.91091314e+00, 1.46559020e+01,
8.93652561e+00, 6.91091314e+00, 3.69376392e+00, 3.69376392e+00,
1.29877506e+01, 2.50222717e+00, 1.07000000e+02],
[6.25389755e+00, 8.68596882e+00, 6.25389755e+00, 1.49398664e+01,
4.86414254e+00, 5.90645880e+00, 8.68596882e+00, 6.08017817e+00,
5.21158129e+00, 1.21603563e+00, 1.00757238e+01, 2.13674833e+01,
1.30289532e+01, 1.00757238e+01, 5.38530067e+00, 5.38530067e+00,
1.89354120e+01, 3.64810690e+00, 1.56000000e+02],
[2.88641425e+00, 4.00890869e+00, 2.88641425e+00, 6.89532294e+00,
2.24498886e+00, 2.72605791e+00, 4.00890869e+00, 2.80623608e+00,
2.40534521e+00, 5.61247216e-01, 4.65033408e+00, 9.86191537e+00,
6.01336303e+00, 4.65033408e+00, 2.48552339e+00, 2.48552339e+00,
8.73942094e+00, 1.68374165e+00, 7.20000000e+01],
[3.52783964e+00, 4.89977728e+00, 3.52783964e+00, 8.42761693e+00,
2.74387528e+00, 3.33184855e+00, 4.89977728e+00, 3.42984410e+00,
2.93986637e+00, 6.85968820e-01, 5.68374165e+00, 1.20534521e+01,
7.34966592e+00, 5.68374165e+00, 3.03786192e+00, 3.03786192e+00,
1.06815145e+01, 2.05790646e+00, 8.80000000e+01],
[3.56792873e+00, 4.95545657e+00, 3.56792873e+00, 8.52338530e+00,
2.77505568e+00, 3.36971047e+00, 4.95545657e+00, 3.46881960e+00,
2.97327394e+00, 6.93763920e-01, 5.74832962e+00, 1.21904232e+01,
7.43318486e+00, 5.74832962e+00, 3.07238307e+00, 3.07238307e+00,
1.08028953e+01, 2.08129176e+00, 8.90000000e+01],
[3.60000000e+01, 5.00000000e+01, 3.60000000e+01, 8.60000000e+01,
2.80000000e+01, 3.40000000e+01, 5.00000000e+01, 3.50000000e+01,
3.00000000e+01, 7.00000000e+00, 5.80000000e+01, 1.23000000e+02,
7.50000000e+01, 5.80000000e+01, 3.10000000e+01, 3.10000000e+01,
1.09000000e+02, 2.10000000e+01, 8.98000000e+02]]))
検出力
有意性検定の理論は、帰無仮説について下す決定が誤っていることを前提としている。
もしも帰無仮説$H_0$が正しければとうてい出そうもない検定量の値が出れば、帰無仮説を偽として棄却する。
したがって、帰無仮説が正しくても、出そうもない棄却域の値がたまたま出てしまい帰無仮説の棄却に帰することがあり得る。
これは第一種の誤りであるが、その確率は有意水準に等しい。
帰無仮説$H_0$が偽であるにも関わらず、たまたま(この確率を$\beta$とする)統計量の値が棄却域に入らなかったために、$H_0$を棄却しない誤りが生じる。これは第2種の誤りである。$\beta$は対立仮説の各値が正しいという条件のもとに棄却域に入らないという確率を求めればよい。
なお、一般に仮説が1個の値のとき単純仮説、2個以上のとき複合仮説という。
$\alpha,\beta$は検定方法、つまり、棄却域の取り方によるが、棄却域の範囲を狭くすれば$\alpha$は小となるが、$\beta$は大となる。
標本の大きさ一定というもとでは、$\alpha,\beta$をともに小さくすることはできない。
有意性検定では、$\alpha$を先に固定してる。
その条件で$\beta$をなるべく小さく、すなわち、第二種の誤りを犯さない確率$1-\beta$をなるべく大きくする、この確率を検出力という。
検出力は、帰無仮説$H_0$が真でないとき、その通りに、これを棄却する確率である。
検出力は、検定方法の良さの基準であり、検出力の大きいものほど、そのような誤りをおかさない厳しい検定である。
次回
回帰分析
参考書