はじめに、この記事はどういう人向け?
Google App ScriptとCOTOHA API及び、SlackやLine notifyなどを使用して
簡単にチャットボットを作りたいと考えてる人向けかも・・
概要
会社Slackで、SlackBotを個人的に作成していたのですが、その際にチャットボット機能の
一部実装にて、形態素解析部分にCOTOHA APIを使用させて頂いてました。
たまたま、Qiita x COTOHA API プレゼント企画 を見かけたので、簡単にまとめてみました。
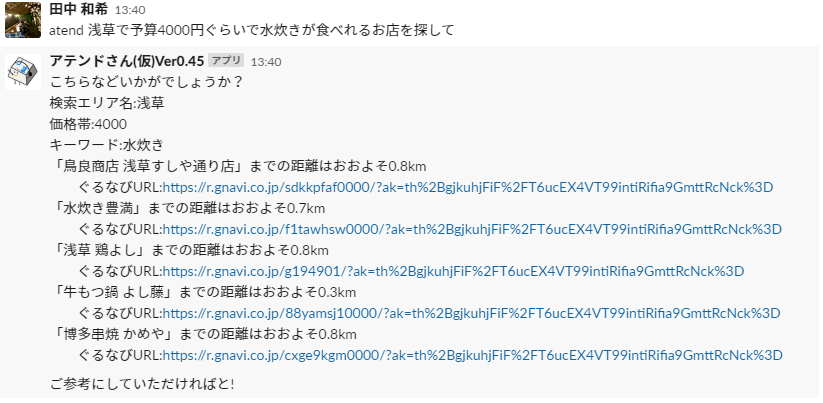
実際の動いているSlackBotは以下のようなものです。(飲食店舗検索っぽい機能のやつ)
仕組みについて
Slackからの入力に対して、Google App ScriptとCOTOHA APIを用いて、飲食っぽいワードがあるかどうかを判定して
飲食っぽいワードがあれば、必要情報をぐるなびAPIに投げて、取得した情報をSlackに返してます。
実際のコード
入力された値に対して、形態素解析&単語判定をしている部分を、簡単に記述したいと思います。
//メイン
function sentenceAnalysis(sentence){
var sentence = '浅草で水炊きが予算3000円ぐらいで食べれるを店を探して'//INPUT
var token = cotohaApiTokenGet();//token取得
var morphemeWord = cotohaApiExec(token,sentence)//api実行&取得データ整形
var msg = wordAnalysis(morphemeWord)//解析
//Logger.log(msg)
return msg
}
//token発行
function cotohaApiTokenGet(){
var url = "https://api.ce-cotoha.com/v1/oauth/accesstokens";
var headers = {
"Accept": "application/json",
"Content-type": "application/json"
}
var data = {
"grantType":"client_credentials",
"clientId":"CLIENTID", //ここにユーザ固有の値
"clientSecret":"CLIENTSECRET" //ここにユーザ固有の値
}
var options = {
"method": "post",
"payload": JSON.stringify(data),
"headers": headers
}
var json_data = UrlFetchApp.fetch(url, options);
var data = JSON.parse(json_data);
var token = data.access_token
return token
}
//形態素解析実行
function cotohaApiExec(key,sentence){
var url = "https://api.ce-cotoha.com/api/dev/nlp/v1/parse"
var token = 'Bearer ' + key
var headers = {
"Authorization": token,
"Accept": "application/json",
"Content-type": "application/json"
}
var data = {
"sentence":sentence,
"type":"default"
}
var options = {
"method": "post",
"payload": JSON.stringify(data),
"headers": headers
}
var json_data = UrlFetchApp.fetch(url, options)
var data = JSON.parse(json_data)
//単語、種別、品詞、カナのタグのみを抽出
var morphemeConvWord = []
for (var j in data.result){
for (var i in data.result[j].tokens){
morphemeConvWord.push({'word': data.result[j].tokens[i].form,'type': data.result[j].tokens[i].features, 'class': data.result[j].tokens[i].pos,'kana': data.result[j].tokens[i].kana})
//Logger.log(data.result[j].tokens[i].form + "____syubetu(" + data.result[j].tokens[i].features + ")" + "____hinsi(" + data.result[j].tokens[i].pos + ")" + "____kana(" + data.result[j].tokens[i].kana + ")")
}
}
return morphemeConvWord
}
//単語判定
function wordAnalysis(targetword){
//地名判定(固有地名もしくは駅を含み名詞となるもの)
var locflg = []
var loc = []
var cop = []
for(var i in targetword){
if(targetword[i].type[1] == '地'){
locflg.push(1)
loc.push(targetword[i].word)
}else if(targetword[i].word.match('駅') && targetword[i].class.match('名詞')){
locflg.push(1)
loc.push(targetword[i].word)
}
}
//飲食っぽいワード判定(カナはぐるなびの検索タグから)
var grmflg = []
var grm= []
for(var i in targetword){
if(targetword[i].kana.match('ミズタキ|ラーメン|ビール|ワイン|ニホンシュ|ショウチュウ|ウイスキー|インショクテン|ヤショク|チュウショク|チョウショク|スシ|サカナ|カイセン|サシミ|ワショク|ニホン|ラーメン|ウドン|ソバ|カレー|ドン|アゲモノ|ショクドウ|オコノミヤキ|コナモノ|キョウド|アジア|エスニック|チュウカ|イタリアン|ヨウショク|フレンチ|アメリカ|アフリカ|ヤキニク|ステーキ|ヤキトリ|ニク|ナベ|シャブシャブ|スキヤキ|イザカヤ|バー|カフェ|スイーツ|ファミレス|ファーストフード|ビュッフェ|バイキング')){
grmflg.push(1)
grm.push(targetword[i].word)
}
}
//額面入力判定CHK(額面指定の入力があれば)
var mnyflg = []
var mny= []
for(var i in targetword){
if(targetword[i].word.match('([0-9]{2}|[0-9]{3}|[0-9]{4}|[0-9]{5})円')){
mnyflg.push(1)
mny.push(targetword[i].word)
}
}
//CHK
if((Number(grmflg) + Number(locflg) + Number(mnyflg)) >= 2){
return([[grm[0],loc[0],mny[0]])
}else{
return [1]
}
}
[yy-mm-dd hh:mm:ss:sss JST] [[水炊き, 浅草, 3000円]]
あとは出力結果をもとに、ぐるなびAPIに、上記の「飲食ワード」、「地名(駅名)」※、「指定額面」を渡してあげてます。
※「地名(駅名)」はGeocodingしたものを実際は渡してます。
コードの簡単な解説
sentenceAnalysis()
形態素解析用のメイン関数、以下3つの関数を実行してます。
cotohaApiTokenGet()
api実行用のtoken取得をしている関数。(以下の部分は適宜変更で)
"clientId":"CLIENTID", //ここにユーザ固有の値
"clientSecret":"CLIENTSECRET" //ここにユーザ固有の値
cotohaApiExec()
実際に形態素解析を実行しているモジュール。
また、今回の判定に必要最低限な情報タグ(単語、種別、品詞、カナ)のみに整形してます。
wordAnalysis()
形態素解析実行後に、「飲食っぽいワード」と「固有値名、駅名」を判定している関数です。
飲食っぽいワードについては、単純に形態素解析しただけでは、基本的に、名詞となるだけなので
判定をするために取得したカナを飲食っぽい単語群(カナ)にマッチしてます。
最後に
Google App Scriptの場合、COTOHA APIで形態素解析をするのが、一番手軽に感じたので使わせて頂きました。
以上、簡単でしたが、ご一読ありがとうございました!