はじめに
GlueCrawlerの設定周りを調査したので、設定内容についてまとめていきます。
今回はS3のCSVデータをAthenaからクエリ出来るように設定することを想定しています。
GlueCrawlerとは
DBやS3などからメタデータを取得し自動でデータカタログを作成してくれるツールでスキーマの更新やパーティションの追加なども行ってくれます。
事前準備
データカタログを登録するデータベースを作成します。
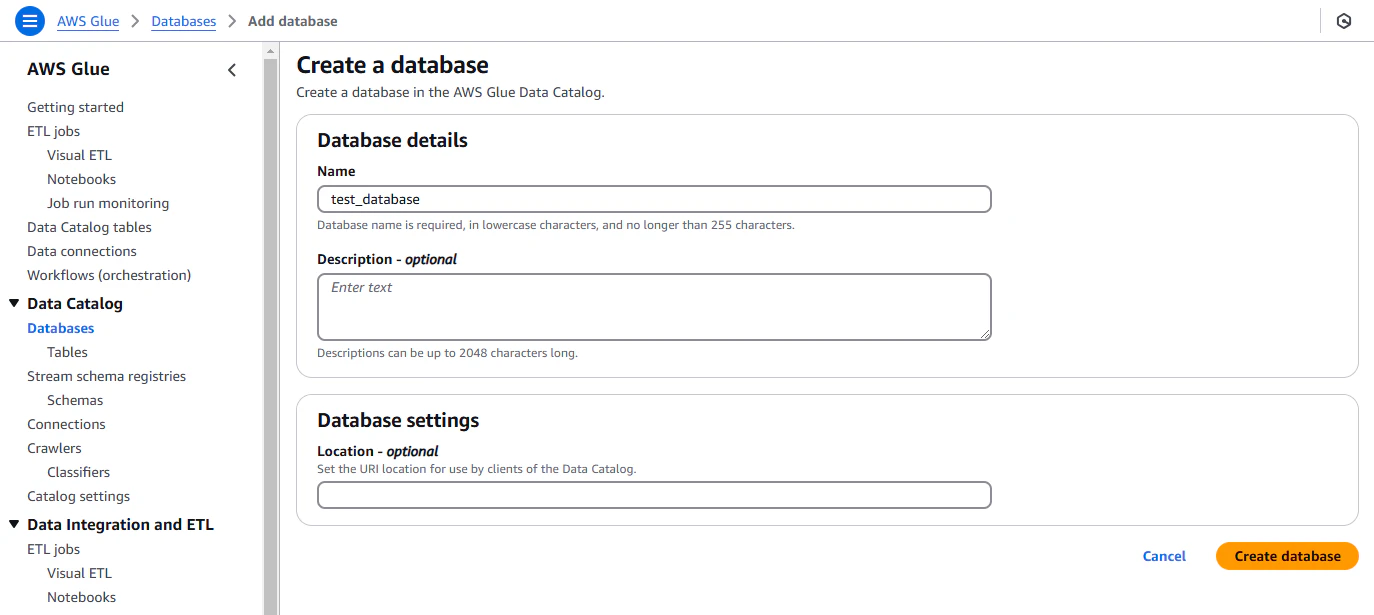
s3にcsvファイルを用意します。
(作成されるテーブル名は指定したバケットのディレクトリ名になるので注意する。)
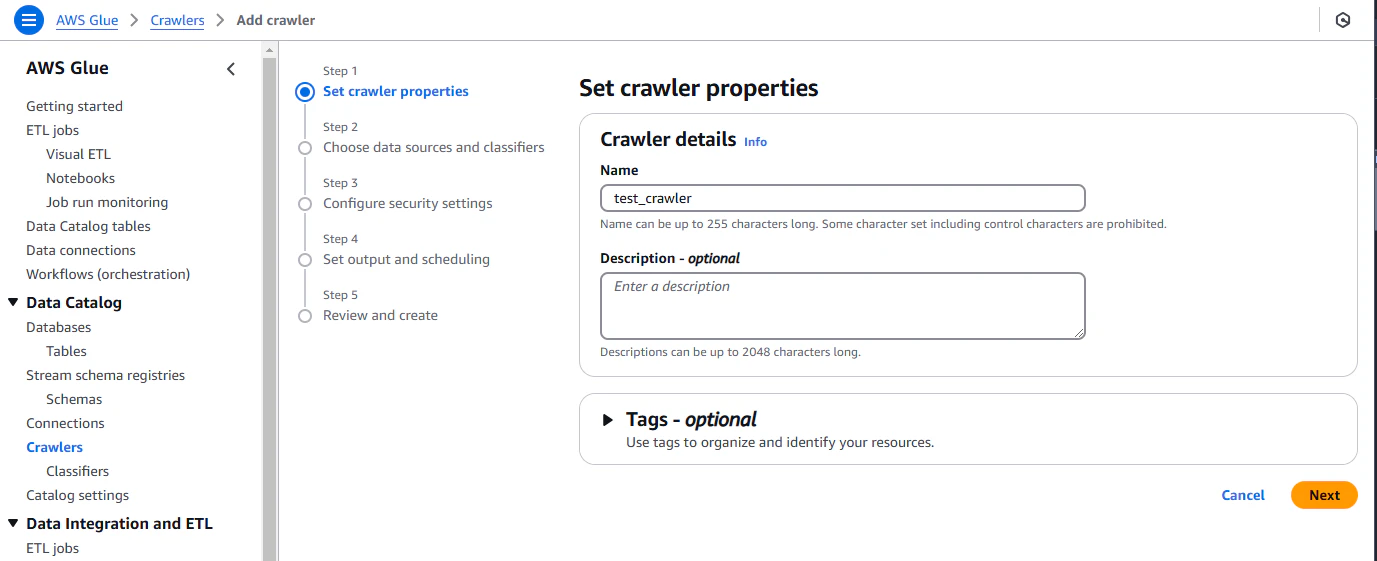
Step1
Crawlerの名前を設定します。
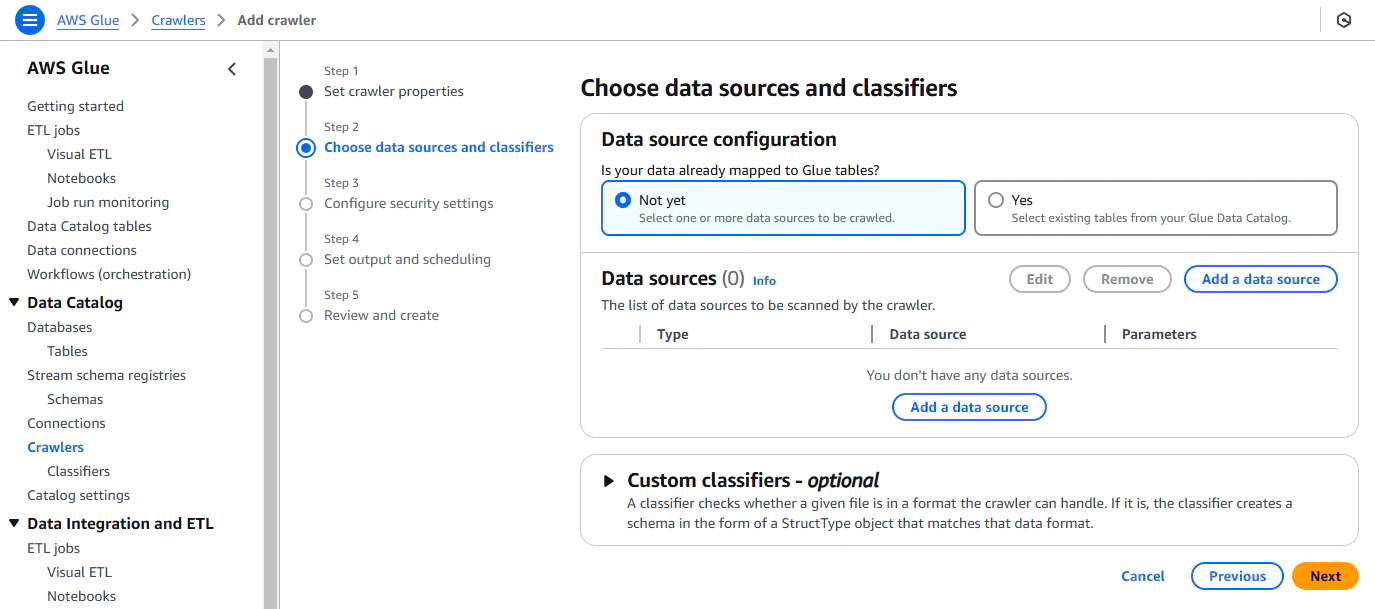
Step2
Data source configuration
データカタログの元となるデータソースを選択します。
既に既存のテーブルがデータカタログに登録されている場合はYesを選択しますが、今回はs3のデータから新規でテーブルを作成するのでNot yetを選択します。
Custom classifiers
非標準フォーマットのデータや複雑なスキーマの場合にはclassifiersを作成し設定することが出来ます。
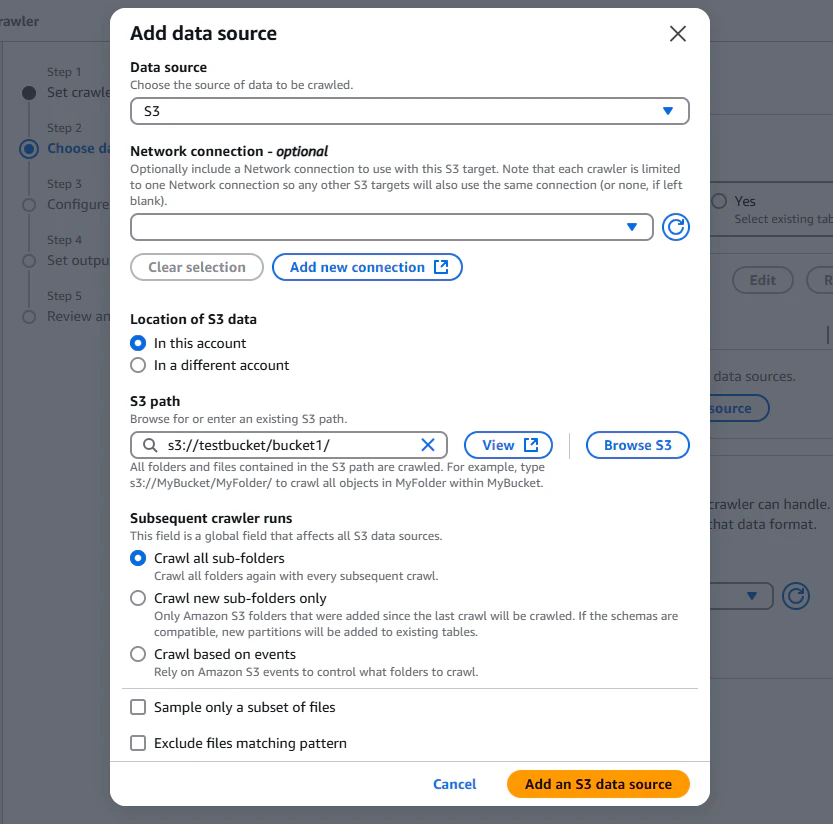
Data source
S3を選択します。S3以外にJDBCやDynamoDBなどを指定することも可能です。
S3 path
S3のpathを入力します。
Subsequent crawler runs
Crawl all sub-folders
すべてのサブフォルダを毎回クロールする方法で、データ変更の頻度が高い場合や、全体的な確認を行いたい場合に適しています。
Crawl new sub-folders only
新たに追加されたサブフォルダのみをクロールする方法で、効率的でリソースの節約になります。
Crawl based on events
S3のイベントを使ってクロールをトリガーする方法で、リアルタイムでのデータ更新に対応し、処理の無駄を省きます。
Crawl new sub-folders onlyの場合、カラムの更新やパーティションの追加がされないので今回はCrawl all sub-foldersを選択します。
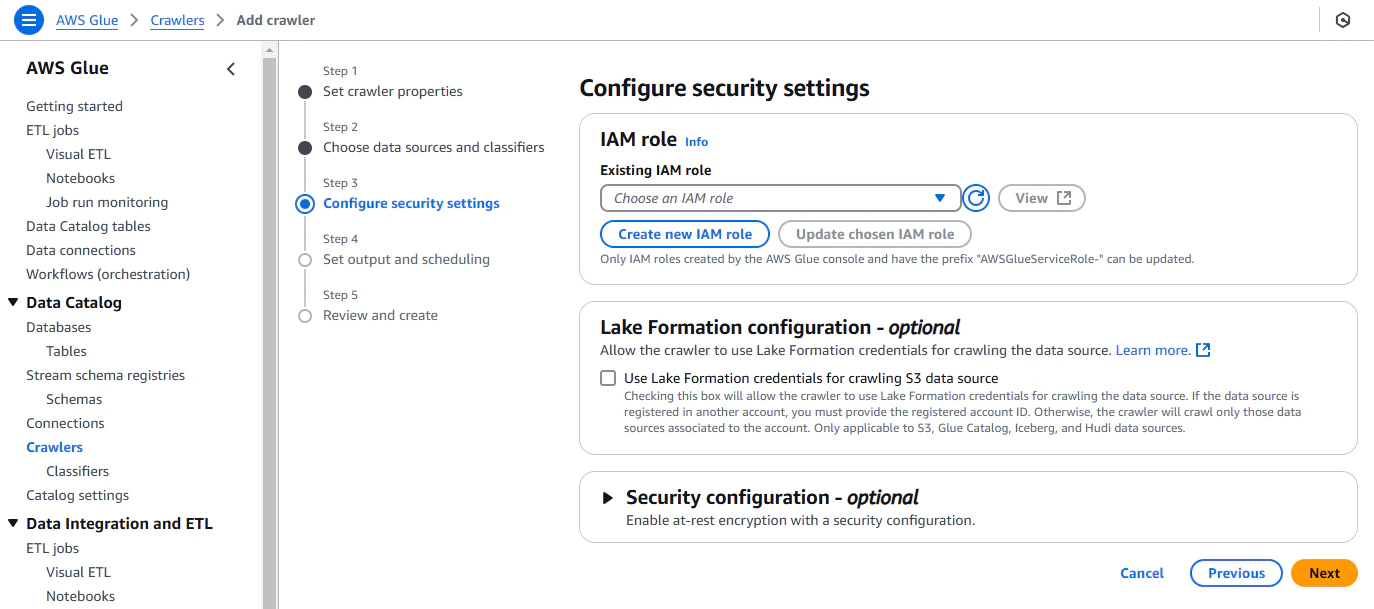
Step3
crawlerを実行するIAM roleを設定する。
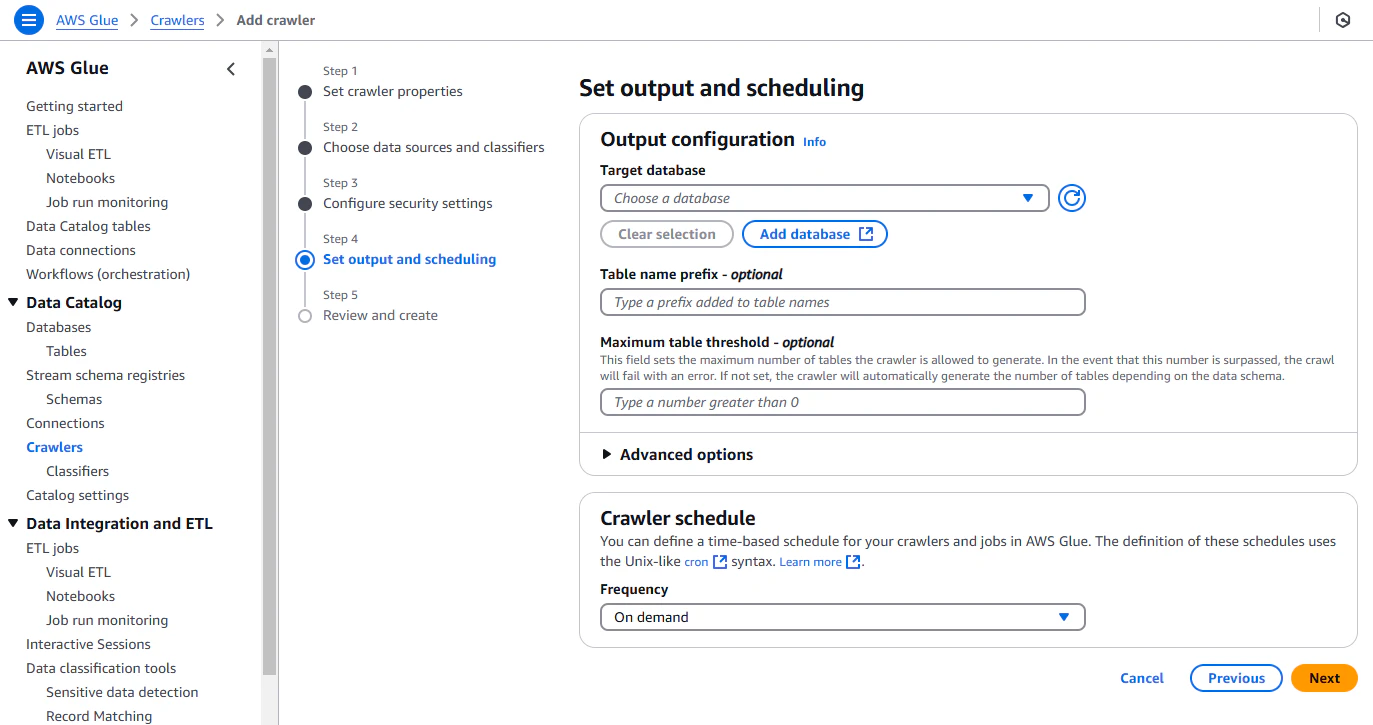
Step4
Target database
事前準備として作成したデータベースを選択する。
Table name prefix
クローラーで作成されるテーブル名はS3の親ディレクトリ名の名前になりますが、テーブル名にプレフィックスを追加することが可能です。
Maximum Table Threshold
クローラーが生成できる最大テーブル数を指定することが出来ます。
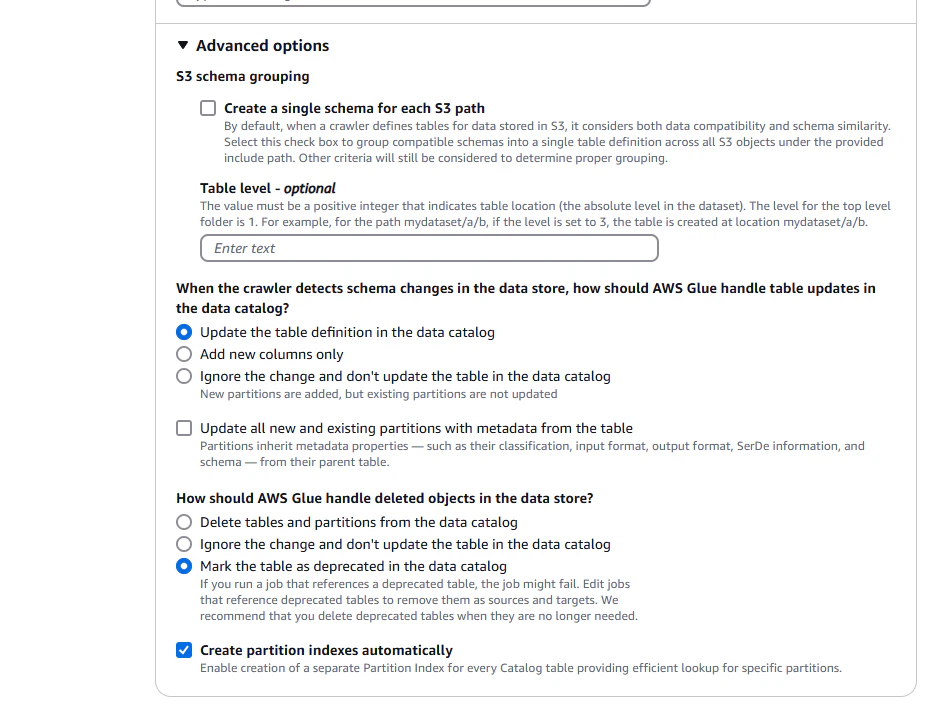
S3 schema groupingAdvanced options
指定されたS3パス以下のすべてのオブジェクトに対して、互換性のあるスキーマを1つのテーブル定義にまとめる設定。
Table Level
データの階層構造に基づいてテーブルの作成位置を決定する設定。
When the crawler detects schema changes in the data store, how should AWS Glue handle table updates in the data catalog?
スキーマの変更を検出したときに、データカタログ内のテーブルの更新をどのように処理するかを決定する設定。
Update all new and existing partitions with metadata from the table
クローラーが新しいパーティションや既存のパーティションのメタデータをテーブルから更新する際の設定。
How should AWS Glue handle deleted objects in the data store?
データストアからオブジェクトが削除された場合の設定。
Create partition indexes automatically
自動パーティションインデックス作成の設定。
Crawler schedule
手動実行でのOn demand以外にcron形式で設定することが可能です。
最後に
Glue Crawlerの具体的な設定手順と項目の説明を記述しました。
作成したCrawlerを実行するとAthenaで対象のcsvデータが確認できるようになります。
ぜひ試してみてください。