アラヤ社内の論文輪読会では、強化学習のアルゴリズムや実社会への応用を扱った論文を積極的に取り上げています。
この論文紹介は、社内輪読で私が紹介した上でQiita向けに書き直した記事です。
私が論文紹介を書くときはいつもarXivTimesのテンプレートを使っているうので、今回もその形式で。
論文へのポインタ
論文URL: https://advances.sciencemag.org/content/4/7/eaap7885
公式実装: https://github.com/isayev/ReLeaSE
Mariya Popova(1,2,3), Olexandr Isayev(1*), and Alexander Tropsha(1*)
(1)Laboratory for Molecular Modeling, Division of Chemical Biology and Medicinal Chemistry, UNC Eshelman School of Pharmacy, University of North Carolina, Chapel Hill, NC 27599, USA.
(2)Moscow Institute of Physics and Technology, Dolgoprudny, Moscow 141700, Russia.
(3)Skolkovo Institute of Science and Technology, Moscow 143026, Russia.
*Corresponding author.
いわゆる強化学習畑の人の論文ではない。
1st author: Ms. Mariya Popova
https://mariewelt.github.io/
履歴書 https://mariewelt.github.io/files/MariyaPopova_cv.pdf を見ると、修士をDouble Degreeで数理情報学/応用数理物理学で取られている。この論文は数理情報学のほうで取り組まれていた研究の成果をまとめたものと思われる。
コレスポはDouble degreeの両方のラボのボス?
一言でいうと
特定の性質を満たした化学物質の構造を生成する手法の新しい提案。
QSARとSMILES生成を深層学習で実装した上で、QSARを報酬獲得の一部として組み込み、SMILES生成のための入力を方策としてREINFORCEによる強化学習を実行。
概要
- SMILESを生成するネットワーク(Generative)とSMILESから直接QSARするネットワーク(Predictive)を実装。
- GenerativeとPredictiveを繋いで、REINFORCE(後述)でGenerative側を学習。Predictive側は追加学習しない前提
- JAK2阻害活性、LogP、Tmのほかいくつかの記述子を制御(最適化、最大化、最小化)する学習を行った結果を評価
- 制御には報酬関数を工夫して実装
新規性・差分
強化学習を用いたこと自体は厳密には新規性ではないが、結果について詳細な分析を加えており、先行研究よりも実用的な議論がなされている。
一方でGANやVAEを用いた手法に比べての優位性は記述されていない。GANやVAEではおそらく複雑な目的関数の設定が難しいように思われるが、計算所要時間は明らかに本手法の方が重いので、優位性はケースバイケースか。
手法
以下、パーツ単位で手法を説明する。
SMILES 生成ネットワーク
入力ベクトルからSMILESを生成する。SMILESは環構造やカッコのように前後の脈絡が必要となるため、生成ネットワークにはRNN系統の手法が有用。
本論文では一般的なGRUではなく、Stack GRUを使っている。内部メモリをスタックとして、POP/PUSHの処理ができるようにしているGRU素子。元の研究はstack RNNにある。
RNNを複数層重ねることをしばしば"Stacked RNN"などと呼ぶが、それとの混同に注意。
SMILESを生成した後、SMILES文法上の適格性、分子としての合成容易性(合成不可能なものはNGとする)を計算し、OKなもののみを次の段階に持ち込む。
適格なSMILESを生み出しやすい学習自体はできているが、それでも100%うまくいくわけではない。
QSAR ネットワーク
入力としてSMILESを使うQSAR。一般的には記述子やグラフを使うことが多いが、SMILESから直接QSARできるネットワーク構造を構築している。
DRAGON記述子を使ったQSARとほぼ遜色のない性能を達成しており、これ自体が興味深い。
QSARで得られた値はそのまま活用せず、報酬(強化学習の用語)に変換して用いる。
例えばQSARの値を一定範囲に収めたい場合(LogPをdrug-likeな範囲に収める)は、一定範囲に収まれば正の報酬が得られ、さもなければ報酬を0とする。最大化したい場合(LogIC50など)は、得られた値を単調増加する関数にかけて報酬値とする。
関数の選定は一般的に強化学習において重要で、おそらく試行錯誤を経ていると思われる。
複数の特性をバランスさせたい場合にも、報酬関数の設計を工夫することで実現できる。
REINFORCE
強化学習(reinforcement learning)と名前が似ていて区別に留意必要。
REINFORCEは「方策ベースの強化学習」として知られる手法の一つ。方策ベースの強化学習では、状態を入力すると最適な方策(手、行動など)を出力するモデル(エージェント)、つまり方策関数を構築する。強化学習はマルコフ決定過程(もしくは部分観測マルコフ決定過程)においてエージェントが現在の状態を観測し、取るべき行動を決定する問題設定に適した機械学習の手法であり、一般的には取るべき行動に一意の正解がないが、行動(もしくは行動の連鎖)に一定の評価が可能な場合に用いられる。例えばゲームAIでは得点、ロボット操作では目的達成などに「報酬」という評価を与えることが一般的である。
REINFORCEは価値関数(=方策がもたらす報酬、価値)に実際にアクセス可能な場合に用いられ、例えばAlphaGoでは自己対局を行い結果をもとに報酬を生成している。
今回はSMILES生成ネットワークが方策関数にあたる。SMILES出力を元にQSARを行い、得られた活性値を最適化する=活性値を元に算出する報酬を最大化するように方策関数を最適化する。
結果
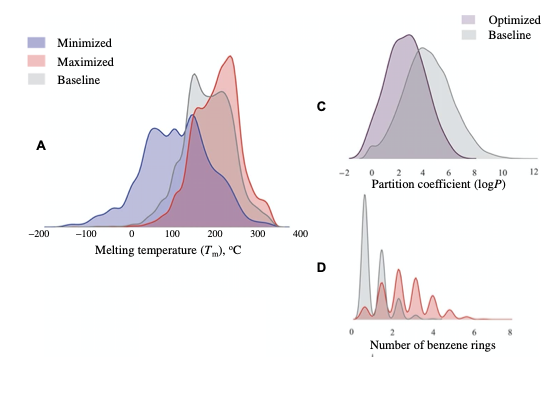
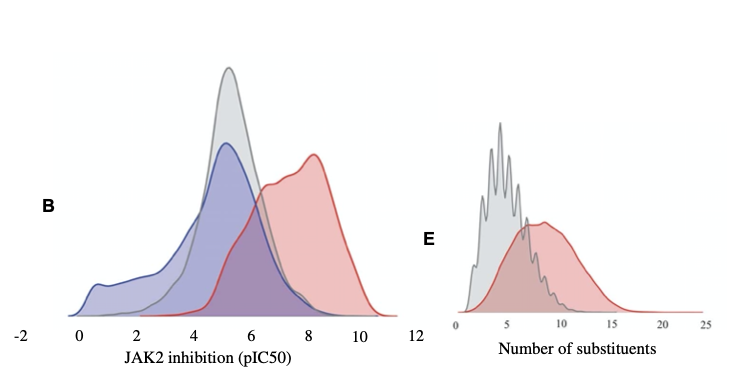
JAK2阻害活性、Tm、LogP、いくつかの記述子についてSMILES生成ネットワークの最適化を伴う強化学習を行い、強化学習前のプレーンなSMILES生成ネットワークの出力結果と比較した。
いずれの場合も、SMILES出力結果の分布が(プレーンなものに比べて)意図に寄っており、適切な最適化が行われていることが分かる。
以下の図は論文中から引用。
A: Tm(融点)の最大化と最小化した結果を示す
B: JAK2阻害効果の最大化と最小化した結果を示す
C: 0 < logP < 4 への最適化の結果を示す
D: ベンゼン環の数を最大化した結果を示す
E: 置換基(枝)の数を最大化した結果を示す
その他いくつかの定性的な評価を行っている。
コメント
AlphaGoで用いられたREINFORCEを創薬・ケモインフォ方面に活用したことは興味深い。全体としては本質的な新規性を見いだしたというより、さまざまなツールを組み合わせる方法と結果の分析に新規性がありそう。ただSMILESからのQSARをしれっと達成していたり、Stack RNNを持ち出していたり、ベースになる技術力は相当なものを持っているように思われる。創薬界隈から手軽に出てくる性質の論文ではないと思う。(実際著者は創薬畑の方ではないです)
一方で、サンプルの実装が甘く、マニュアル通りでは動かせない。GPU必須なことなど、利用に向けての負荷は高い。