TL;DR
- AWS StepFunctionsを使うと、外部連携が安心してできていい感じ。
- AWS StepFunctionsは動的並列処理というものができ、入力された配列を並列で処理できる。
- ただし、入力が32KBを超えると落ちるので大きいデータはS3を経由して処理することが推奨されている
- そうすると並列処理したいはずの配列が入力に渡されなくなるので、やりたかった並列処理ができない。
- なので、32KBごとにS3にJSONを突っ込んで、JSONファイルのARNの配列を並列処理に渡し、さらにそのARNからデータの配列を作り、ネストした並列処理で1行ずつ実行すればOK!
ユースケース
Google Calendar連携のInitial full syncを例にする。
やりたいことは、予定の全取得と、次回以降に利用するsync_token(Etagみたいなもの)を取得・永続化すること。
手順
- [1] 引数で受け取ったアカウントの認証情報、対象のカレンダーIDから、本日以降の全予定とsync_tokenを取得する。
- [2] 取得した予定を自分のアプリのDBに永続化する。
- [3] 全ての予定が永続化されたら、最初に取得したsync_tokenを永続化する。
- [4] sync_tokenが永続化されたら、channelを作成して以降の変更をリッスンする。
懸念点
- [1] で取得したデータが多く、時間がかかる
- [2]が失敗したのにも関わらず[3]に進んでしまうと、予定の取りこぼしが発生する
- [3]が失敗すると次回も大量データ処理を行う必要が生じて非効率
AWS StepFunctions
AWS StepFunctionsを使うと、上記のような手順をLambdaベースで簡単に作ることができるうえ、
エラーの捕捉やリトライが簡単なのでこういうユースケースにはハマると思う。
素直にやった場合の構成
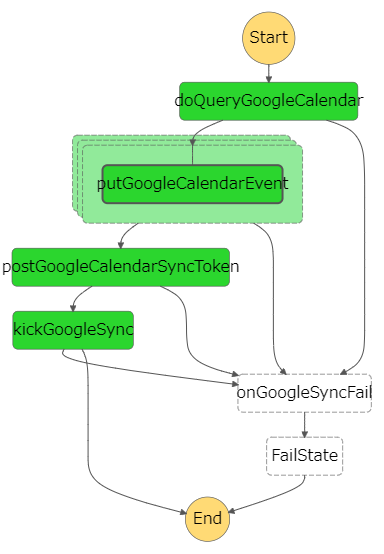
こういう感じになる。
定義JSON(参考)
{
"StartAt": "doQueryGoogleCalendar",
"States": {
"doQueryGoogleCalendar": {
"Type": "Task",
"Resource": ***,
"Next": "putGoogleCalendarEventParallel",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "onGoogleSyncFail",
"ResultPath": "$.error"
}
]
},
"putGoogleCalendarEventParallel": {
"Type": "Map",
"ItemsPath": "$.events",
"ResultPath": "$.events",
"Next": "postGoogleCalendarSyncToken",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "onGoogleSyncFail",
"ResultPath": "$.error"
}
],
"Iterator": {
"StartAt": "putGoogleCalendarEvent",
"States": {
"putGoogleCalendarEvent": {
"Type": "Task",
"Resource": ***,
"End": true
}
}
}
},
"postGoogleCalendarSyncToken": {
"Type": "Task",
"Resource": ***,
"Next": "kickGoogleSync",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "onGoogleSyncFail",
"ResultPath": "$.error"
}
]
},
"kickGoogleSync": {
"Type": "Task",
"Resource": ***,
"End": true,
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "onGoogleSyncFail",
"ResultPath": "$.error"
}
]
},
"onGoogleSyncFail": {
"Type": "Task",
"Resource": ***,
"Next": "FailState"
},
"FailState": {
"Type": "Fail"
}
}
}
ポイントとしては、
"Type": "Map"のステートを使って、doQueryGoogleCalendarの返り値のevents配列の要素ごとに動的並列処理を行う
というところ。
疑似的に書くとこんな感じ。
doQueryGoogleCalendar(input).then(({events})=>Promise.all(events.map(event=>putGoogleCalendarEvent(event))))
課題:32KB制限
StepFunctionで受け渡しする入力・出力は32KBを超すことができない。
ここで、doQueryGoogleCalendarの返り値が32KB以上あった場合、並列処理に入る際に落ちてしまう。
公式では、S3に一度データを格納し、データそのものの代わりにS3のARNを入力に渡すことが推奨されている。
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/avoid-exec-failures.html
ただし、"Type":"Map"はStepFunctionsの入力を対象に並列処理を行うため、
S3にデータを格納してしまった時点で並列処理の恩恵が受けられない。
ネストする
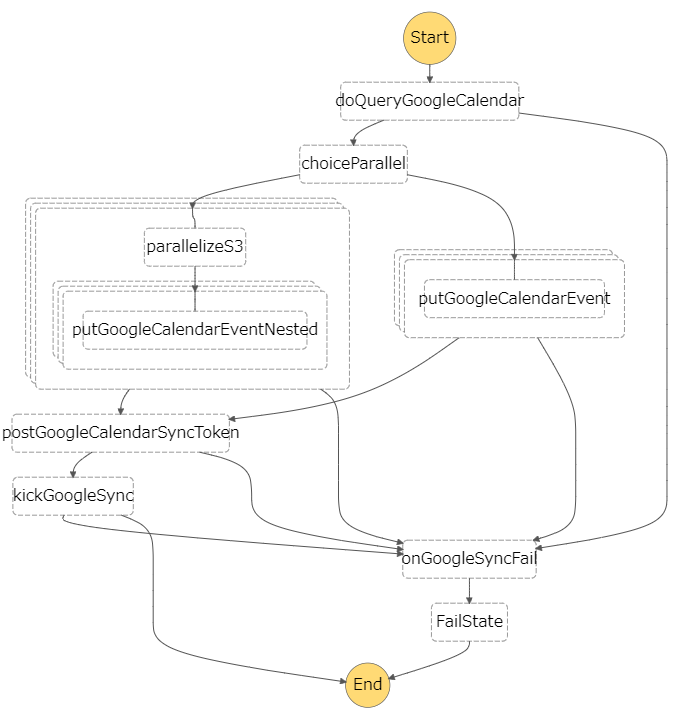
ということで、こんな感じにしてみた。
右側のルートが従来のケースで、左側のルートが32KBを超えた場合のルート。
定義JSON(参考)
{
"StartAt": "doQueryGoogleCalendar",
"States": {
"doQueryGoogleCalendar": {
"Type": "Task",
"Resource": ***,
"Next": "choiceParallel",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "onGoogleSyncFail",
"ResultPath": "$.error"
}
]
},
"choiceParallel": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.parallel",
"StringEquals": "s3",
"Next": "parallelizeS3Parallel"
}
],
"Default": "putGoogleCalendarEventParallel"
},
"parallelizeS3Parallel": {
"Type": "Map",
"ItemsPath": "$.events",
"ResultPath": null,
"Next": "postGoogleCalendarSyncToken",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "onGoogleSyncFail",
"ResultPath": "$.error"
}
],
"Iterator": {
"StartAt": "parallelizeS3",
"States": {
"parallelizeS3": {
"Type": "Task",
"Resource": ***,
"Next": "putGoogleCalendarEventParallelNested"
},
"putGoogleCalendarEventParallelNested": {
"Type": "Map",
"ItemsPath": "$.events",
"ResultPath": null,
"End": true,
"Iterator": {
"StartAt": "putGoogleCalendarEventNested",
"States": {
"putGoogleCalendarEventNested": {
"Type": "Task",
"Resource": ***,
"End": true
}
}
}
}
}
}
},
"putGoogleCalendarEventParallel": {
"Type": "Map",
"ItemsPath": "$.events",
"ResultPath": null,
"Next": "postGoogleCalendarSyncToken",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "onGoogleSyncFail",
"ResultPath": "$.error"
}
],
"Iterator": {
"StartAt": "putGoogleCalendarEvent",
"States": {
"putGoogleCalendarEvent": {
"Type": "Task",
"Resource": ***,
"End": true
}
}
}
},
"postGoogleCalendarSyncToken": {
"Type": "Task",
"Resource": ***,
"Next": "kickGoogleSync",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "onGoogleSyncFail",
"ResultPath": "$.error"
}
]
},
"kickGoogleSync": {
"Type": "Task",
"Resource": ***,
"End": true,
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "onGoogleSyncFail",
"ResultPath": "$.error"
}
]
},
"onGoogleSyncFail": {
"Type": "Task",
"Resource": ***,
"Next": "FailState"
},
"FailState": {
"Type": "Fail"
}
}
}
やっていることを解説すると以下のようになる。
-
doQueryGoogleCalendarは、取得したデータが32KB以上だったなら、32KBごとにデータを分割してJSON化してS3にアップし、S3のARNを配列にして次のステートに渡す。
その際、parallelModeみたいな属性を次のステートに渡しておき、inputモードとS3モードを後続が区別できるようにする。 -
choiceParallelステートは、受け取ったparallelModeがinputかS3かで後続を決定する。 -
inputだった場合は従来通り、入力を直接並列処理に渡して処理する。 -
S3だった場合、まずARNの配列を並列処理に回し、ARNからJSONを取得、取得したデータの配列をさらに子の並列処理に渡して、最終的にはデータ配列要素分の処理を実行する。(2重ネスト) - 並列処理の結果は後続処理には不要なので、
ResultPath: nullを指定する。これをやらないと、並列処理完了後に32KB制限にかかってしまう。 - 予定データの並列処理完了後の動きは
input/S3で共通。
S3のパターンを疑似的に表現するとこんな感じになる。
doQueryGoogleCalendar(input).then(({jsonArns})=>Promise.all(jsonArns.map(jsonArn)=>(paralellizeS3(jsonArn).then(events=>events.map(event=>Promise.all(putGoogleCalendarEvent(event))))
構成のメリット
-
putGoogleCalendarEventやpostGoogleCalendarSyncTokenなど、コアな部分の処理は同じものを使いまわせる。 - 並列なので処理時間が短くなる。
まとめ
- AWS StepFunctionsを使うと、外部連携が安心してできていい感じ。
- AWS StepFunctionsは動的並列処理というものができ、入力された配列を並列で処理できる。
- ただし、入力が32KBを超えると落ちるので大きいデータはS3を経由して処理することが推奨されている
- そうすると並列処理したいはずの配列が入力に渡されなくなるので、やりたかった並列処理ができない。
- なので、32KBごとにS3にJSONを突っ込んで、JSONファイルのARNの配列を並列処理に渡し、さらにそのARNからデータの配列を作り、ネストした並列処理で1行ずつ実行すればOK!