DeepLearningが深い層でも学習に成功した一つの理由としてDropoutが有名です。それを改良し精度を向上させたDropBlockという手法の論文を紹介します。
- 論文
- DropBlock: A regularization method for convolutional networks1
- Conference
- NIPS2018
- Reference
この記事は、Wantedlyの勉強会で取り上げられた論文・技術をまとめたものです。
2018年に読んだ機械学習系論文・技術まとめ at Wantedly
どんなもの?
Google Brainチームが書いた論文で、NIPS2018に採択されました。
Deeplearningが深い層でも学習に成功した一つの理由としてDropoutが有名です。
Dropoutは、ランダムにユニットの値を使えなくすることで過学習を防ぎ、汎化性能を向上させる効果がありますが、全結合層で特に有効でConvolution層ではあまり有効ではないという報告があります。2
この論文ではその理由を、Convolution層では空間的に隣り合ったユニットは共通の情報を多く共有しており、情報の相関があるためと指摘しています。
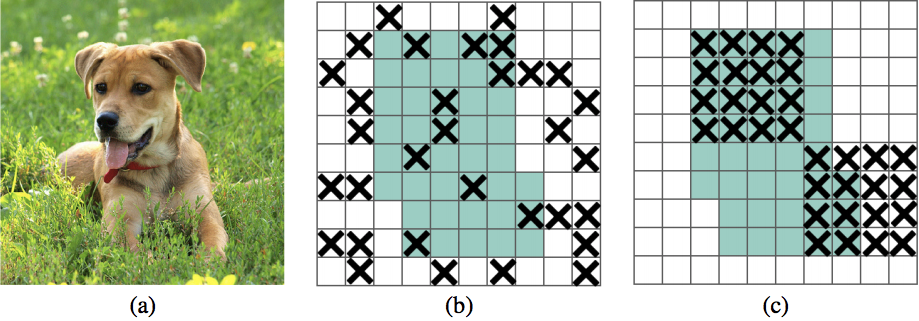
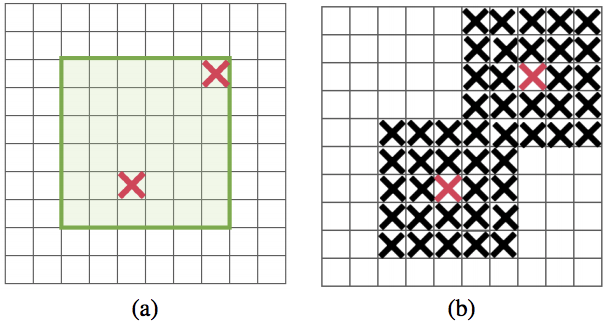
DropBlockではこれを防ぐための素朴な解決法として、Feature Mapで空間的に連続する$block\_size * block\_size$の領域をランダムに使えなくします。(下の例では5*5)
実験結果から、Classification、Object Detection、 Semantic Segmentationと言った複数の画像処理の問題に対して精度が向上しています。
先行研究と比べてどこがすごい?
発想が似た手法として、Cutout3という方法があります。画像の一部をマスクしてその領域の平均値で埋めるものでData Argumentationとして使われます。
この論文では、Cutoutと比べても精度が向上していると報告しています。
Cutoutは最初の入力画像で情報を隠し、Dropblocはネットワークの途中のFeature Mapで情報を隠すとすると、途中のFeatureMapでも隠すほうが効果があるようです(組み合わせたらどうなるんだろう?)
技術や手法のキモはどこ?
こう書くと単純で素朴な手法でうまく行ったように見えますが、実際はいくつかの工夫が必要だったように読み取れます。
- Scheduled DropBlock
- ランダムに消す割合が大きいと学習初期でうまくいかない。学習の初期では$keep\_prob$を1.0(ほとんど消さない)からスタートして徐々に下げていく(消す割合を増やす)というスケジューリングが有効。
- Dropoutよりもパラメータが必要
- Droblockを入れる場所はどこが最適でしょうか?自明ではないため実験によって決定しています。
- どのくらいの領域をZERO値にするか?これも潤沢な計算量があるため、実験を行いResnet-50に対しては$block\_size=7$が最適だとわかりました。
読んでみての感想
自分なりの解釈: 画像の中に犬がいるとき、その犬らしさは本来は頭でも胴体でも尻尾でもわかってほしい。ただ今の多くのネットワークは、一番当てやすい頭だけを見てそこの情報だけから犬と当てている。問題を解くにはそれが一番効率的だから。Dropblockはランダムに連続する領域をDropするので、Convolution層の中で犬の頭に強くActivateしている領域全体がDropされるかもしれない、そのときは胴体とか尻尾の部分からも当てなくてはならないという難しさを課している。
問題と解決方法が素朴なアイディアで、やってみて上手くチューニングしたらうまくいったという印象でした。同時にまだDeeplearningが上手く解決できていない部分があることを感じさせるものでした。上手く動かすためにはいくつかのパラメータを探索して最適値を探さないと行けない悩ましさがあると感じます。