ImageNetなどの一般的な画像分類からの転移学習で、特定の小さいドメインの問題が解けるのが関心があったので読んでみました。
Reference
- Document Image Classification with Intra-Domain Transfer Learning and Stacked Generalization of Deep Convolutional Neural Networks
- Presented on ICPR 2018
文中の図表は論文より引用しています。
この記事は、Wantedlyの勉強会で取り上げられた論文・技術をまとめたものです。
2018年に読んだ機械学習系論文・技術まとめ at Wantedly Advent Calendar 2018 - Qiita
モチベーション
デジタル化以前の過去の大量の文章をデジタル化して、有効活用したいという関心がある。
そのためにOCRをしてドキュメントにするが、色々な種類のドキュメントを一律に扱うのは難しい。
例えばテーブルとか手書きとかは何らかの前処理をするかも知れないし、請求書とかは項目名と数値部分にだけ関心があるかも。
そのため画像をまずは表・請求書・メモなどに分類して扱いたいというストーリー。
この論文は、文章画像はそんなに大量にない点と、224*224くらいのネットワークでは文字レベルの解像度を見るのが難しいという問題にチャレンジしている。
手法
メインのコントリビューションは2点。
- 2種類の転移学習, inter-domain, intra-domainを行って精度を上げた。
- 部分領域の分類からスタッキングする手法で精度を上げた。
転移学習部分
2種類の転移学習を行った。
- L1: ImageNetで学習したVGG16モデルをベースに、この問題の16種類の分類問題を学習する。
- L2: L1で学習したモデルをベースに、「ドキュメントの小さい領域」を見て16種類の分類問題を学習する。図を参照↓
L1は普通の転移学習。L2がなぜ必要なのか?
モデルはVGG16で、インプットは224 × 224にリサイズされる。このサイズだと文字認識はかなり難しそう。実際に下の画像全体を224*224にリサイズすると恐らく文字は読めない。→部分に分けて認識するというアイディア
この論文では、入力画像を小さな部分領域(Header, Footer, Right, Left)に分割してそれを入力として分類するモデルを作った。論文だったらヘッダ部分に特定のレイアウトが見れるし、請求書だったらフッタ部分に定形の文章が来るかも知れない。こういった人間の知識を素直に入れた形。
その後、部分領域と全体の認識結果をConcatしたものを特徴量として、さらにメタ分類器を入れて最終的な16種類の分類を行うというもの。
Kaggleとかで使われるStacking手法と同じ。ただ計算コストは5倍に増えるはず。(ちなみにメタ分類機は、Multi−layer Neural Networkが良かったらしい)
どうやって有効だと検証した?
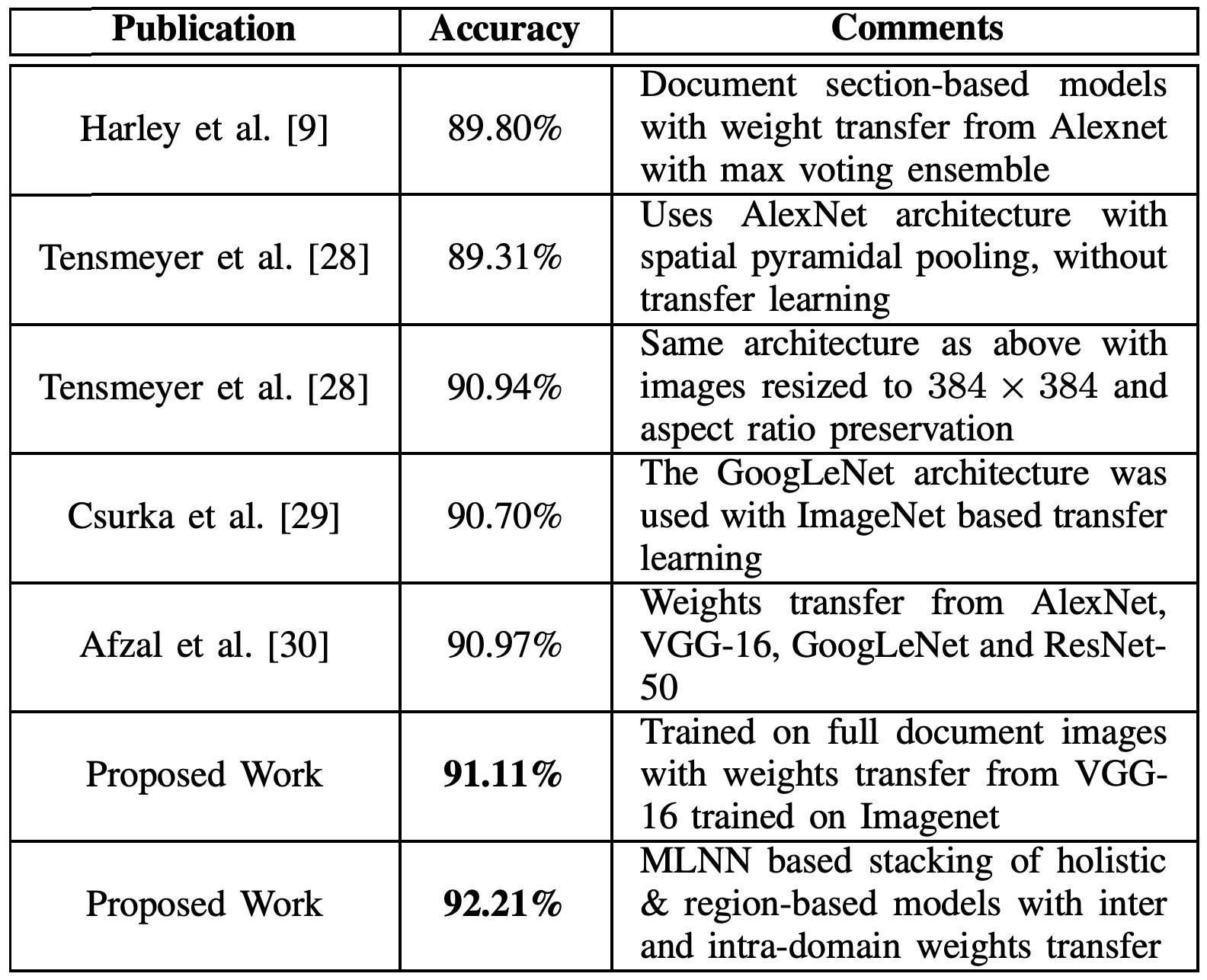
16種類の画像データ・セット http://www.cs.cmu.edu/~aharley/rvl-cdip の分類精度でSOTを達成したと報告されている(16クラスならもっと行く気がするけど16種類にアノテートされたデータを見ると人間でも判断が悩むところがありそう)。
議論・感想
ドメインが違っても転移学習が有効だったのは知見として面白かったけど、アンサンブルしても1.1%プラスにしかならない。単純に比較して5倍の計算量がかかってもそれに価値があるかは疑問。
ヘッダ・フッタみたいに分ける部分は、実はランダムにパッチで見てアンサンブルという方法でも同じくらいの精度が出るのではとか色々疑問がありそう。
あとドキュメントの分類は2018年時点でもそこまでフォーカスしてやられていないという感想だった。ImageNetなどの分類問題が高精度で解かれているから、本質的には解かれている問題のドメインが違うだけという認識が強いのかも知れない。