はじめに
先日、OracleがJavaによる機械学習ライブラリーをオープンソースで公開したというニュースを目にしたので、軽く触ってみました。
- CodeZineニュース - Oracle、Javaによる機械学習ライブラリ「Tribuo」をオープンソースで公開
- マイナビニュース - Oracle、Java機械学習ライブラリ「Tribuo」を発表
これを見ると、機械学習の一般的なアルゴリズムに加えてXGBoostなども使えるようです。

特徴
公式サイトのトップページには以下の3つの特徴が挙げられています。
-
来歴(Provenance):Tribuoのモデル、データセット、評価には来歴があるため、それらを作成するために使用されたパラメーター、データの変換方法、ファイルなどが正確に追跡できる(※)。
-
型安全:Javaを使用しており、本番環境ではなくコンパイル時にミスを発見できる。
-
相互運用可能:XGBoostやTensorflowなどの一般的な機械学習ライブラリーへのインターフェイスを提供。ONNXモデル交換フォーマットをサポートしており、他のパッケージや言語(scikit-learnなど)で構築されたモデルをデプロイできる。
※:「Provenance」とは、モデルやデータセットがどのようにつくられたのかを示す情報のことです。訳が「来歴」で適切かどうかは分かりません。
とりあえず動かす
アヤメを分類するチュートリアルがあったので、まずはこれを試してみます。このチュートリアルでは、4つの特徴(がくと花弁の長さ・幅)を持つアヤメのデータを学習して、3種類(versicolor、virginica、setosa)に分類するモデルを作成して予測します。

以下のようにIntelliJでMavenプロジェクトを作成して、
pom.xmlに以下を追加します。
<dependencies>
<dependency>
<groupId>org.tribuo</groupId>
<artifactId>tribuo-all</artifactId>
<version>4.0.0</version>
<type>pom</type>
</dependency>
</dependencies>
分類するアイリスの花のデータをダウンロードして、
wget https://archive.ics.uci.edu/ml/machine-learning-databases/iris/bezdekIris.data
あとは、チュートリアルにある通り、クラスを作成すると、ディレクトリー構成は以下のようになります。
作成したサンプルプロジェクトは私のGitHubにアップロードしておくので、ソースコードの詳細を見たい方はこちらを参照下さい。
では、さっそく実行。ところが...チュートリアルの通りに実装したはずなのに、なぜかエラーが...
Exception in thread "main" java.lang.IllegalArgumentException: On row 151 headers has 5 elements, current line has 1 elements.
at org.tribuo.data.csv.CSVIterator.zip(CSVIterator.java:168)
at org.tribuo.data.csv.CSVIterator.getRow(CSVIterator.java:188)
at org.tribuo.data.columnar.ColumnarIterator.hasNext(ColumnarIterator.java:114)
at org.tribuo.data.csv.CSVLoader.innerLoadFromCSV(CSVLoader.java:249)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:238)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:209)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:161)
at ClassificationExample.main(ClassificationExample.java:21)
Process finished with exit code 1
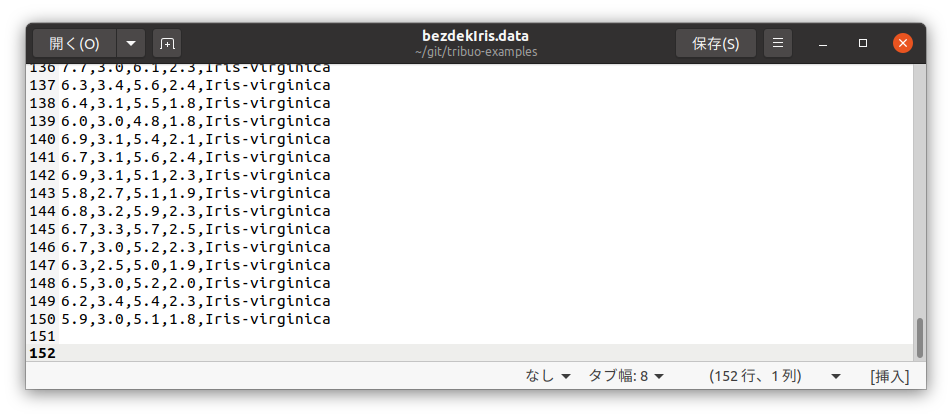
エラーメッセージに「On row 151 …」とあるので、データファイルの151行目を確認してみると、データファイルの最終行に改行のみの1行がありました...
「そんなことでこけるなよ」と思いつつ空行を削除して、再び実行。今度は成功で、結果は検証用データの45件中44件が正解。正解率は97.8%でした。
Class n tp fn fp recall prec f1
Iris-versicolor 16 16 0 1 1.000 0.941 0.970
Iris-virginica 15 14 1 0 0.933 1.000 0.966
Iris-setosa 14 14 0 0 1.000 1.000 1.000
Total 45 44 1 1
Accuracy 0.978
Micro Average 0.978 0.978 0.978
Macro Average 0.978 0.980 0.978
Balanced Error Rate 0.022
Iris-versicolor Iris-virginica Iris-setosa
Iris-versicolor 16 0 0
Iris-virginica 1 14 0
Iris-setosa 0 0 14
ソースコードの解説
チュートリアルを読めばわかりますが、簡単にソースコードも解説しておきます。
作成したクラスはmain()メソッドを持つ1クラスだけです。多クラス分類に必要なクラスなどをいくつかimportしています。
import org.tribuo.classification.Label;
import org.tribuo.classification.LabelFactory;
...(略)...
public class ClassificationExample {
public static void main(String[] args) throws IOException {
ダウンロードしたデータファイルをCSVLoaderで読み込んで、ListDataSourceというクラスでデータを保持します。
LabelFactory labelFactory = new LabelFactory();
CSVLoader csvLoader = new CSVLoader<>(labelFactory);
String[] irisHeaders = new String[]{"sepalLength", "sepalWidth", "petalLength", "petalWidth", "species"};
ListDataSource irisesSource = csvLoader.loadDataSource(Paths.get("bezdekIris.data"), "species", irisHeaders);
このデータを7:3で学習用のデータと検証用のデータに分けます。
TrainTestSplitter irisSplitter = new TrainTestSplitter<>(irisesSource, 0.7, 1L);
MutableDataset trainingDataset = new MutableDataset<>(irisSplitter.getTrain());
MutableDataset testingDataset = new MutableDataset<>(irisSplitter.getTest());
LogisticRegressionTrainerを使用すると、ロジスティック回帰で学習できます。
Trainer<Label> trainer = new LogisticRegressionTrainer();
Model<Label> irisModel = trainer.train(trainingDataset);
クラスのLogisticRegressionTrainer.toString()メソッドを呼び出すことで、以下のように使用しているハイパーパラメーターの値が分かります。
LinearSGDTrainer(objective=LogMulticlass,optimiser=AdaGrad(initialLearningRate=1.0,epsilon=0.1,initialValue=0.0),epochs=5,minibatchSize=1,seed=12345)
LabelEvaluator.evaluate()で検証用のデータがどの程度正しいか評価します。
LabelEvaluator evaluator = new LabelEvaluator();
LabelEvaluation evaluation = evaluator.evaluate(irisModel, testingDataset);
評価した結果はLabelEvaluationクラスのtoString()メソッドを呼び出すことで分かります。また、混同行列はgetConfusionMatrix()メソッドを呼び出すことで分かります。
System.out.println(evaluation);
System.out.println(evaluation.getConfusionMatrix());
以上でモデルの学習と評価は終わりですが、チュートリアルには前述した「来歴(Provenance)」の取得方法も記載されています。
ModelProvenance provenance = irisModel.getProvenance();
System.out.println(ProvenanceUtil.formattedProvenanceString(provenance.getDatasetProvenance().getSourceProvenance()));
このコードの出力は以下のようになります。
TrainTestSplitter(
class-name = org.tribuo.evaluation.TrainTestSplitter
source = CSVLoader(
class-name = org.tribuo.data.csv.CSVLoader
outputFactory = LabelFactory(
class-name = org.tribuo.classification.LabelFactory
)
response-name = species
separator = ,
quote = "
path = file:/home/tamura/git/tribuo-examples/bezdekIris.data
file-modified-time = 2020-09-24T09:05:30+09:00
resource-hash = 36F668D1CBC29A8C2C1128C5D2F0D400FA04ED4DC62D12246F44CE9360360CC0
)
train-proportion = 0.7
seed = 1
size = 150
is-train = true
)
どのファイルを読み込んで、どのように学習用データと検証用データに分割したか、などが分かるようです。
応用
少しだけソースコードを追加・修正して、動作確認してみたいと思います。
通常、精度の高いモデルができたら、そのモデルを使って未知のデータの予測を行います。TribuoではModel.predict()で予測ができ、その結果Predictionオブジェクトが返されます。このオブジェクトには、次のようにどの種類のアヤメであるかを示す確率が含まれています。
- Iris-versicolor: 90.1%
- Iris-virginica: 9.5%
- Iris-setosa: 0.4%
「では予測してみましょう」と言いたいところですが、未知のデータが無いので、検証用のデータをこのメソッドに与えてみます。以下のような実装をすることで、検証用データの予測が誤った行を特定できます。
List<Example> data = testingDataset.getData(); // 検証用のデータ
for (Example<Label> testingData : data) {
Prediction<Label> predict = irisModel.predict(testingData); // 検証用のデータを1件ずつ予測
String expectedResult = testingData.getOutput().getLabel(); // 正答
String predictResult = predict.getOutput().getLabel(); // 予測した結果
if (!predictResult.equals(expectedResult)) {
System.out.println("Expected result : " + expectedResult);
System.out.println("Predicted result: " + predictResult);
System.out.println(predict.getOutputScores());
}
}
この出力結果は、以下のようになります。
Expected result : Iris-virginica
Predicted result: Iris-versicolor
{Iris-versicolor=(Iris-versicolor,0.5732799760841581), Iris-virginica=(Iris-virginica,0.42629863727592165), Iris-setosa=(Iris-setosa,4.213866399202189E-4)}
誤った答えである「virginica」を57.3%、正しい答えである「versicolor」を42.6%と判定しているので、予測失敗した1件も惜しかったと言えます。
次に、前述のXGBoostを使用してみます。これは、TrainerをLogisticRegressionTrainerからXGBoostClassificationTrainerに変更するだけで良さそうです(もちろんimportも必要ですが)。
// Trainer<Label> trainer = new LogisticRegressionTrainer();
Trainer<Label> trainer = new XGBoostClassificationTrainer(2);
コンストラクターに与えた2は決定木の本数で、ここでは最小値の2を与えました。
結果は変わらず、正解率は97.8%でした。
ビルドする
ただ、使うだけでなく、バグを修正したり機能追加したい方のためにビルドも方法も書いておきます。
Tribuoのビルドには、Java 8以降かつMaven 3.5以降が必要なので、まずはそれを確認しておきます。
$ mvn -version
Apache Maven 3.6.3
Maven home: /usr/share/maven
Java version: 1.8.0_265, vendor: Private Build, runtime: /usr/lib/jvm/java-8-openjdk-amd64/jre
Default locale: ja_JP, platform encoding: UTF-8
OS name: "linux", version: "5.4.0-47-generic", arch: "amd64", family: "unix"
ちなみにこの記事ではOSにUbuntu 20.04を使用しています。ビルドは、mvn clean packageを実行するだけです。
$ mvn clean package
・・・(略)・・・
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 03:54 min
[INFO] Finished at: 2020-09-23T16:17:34+09:00
[INFO] ------------------------------------------------------------------------
ビルドは4分弱で終了し、350MBほどのディスク容量が追加されました。以前、Deeplearning4jを試したことがありますが、それと比較するとはるかに軽量です(Deeplearning4jは数時間のビルド完了後に数十GB空き容量が無くなっていました)。
感想
軽く触ってみたり、ソースコードを眺めた感想は、「Javaとしては手軽だけど、機能不足」な印象を受けました。正直、「Pythonであれば、もっと簡単にいろいろなことができるのに」と思ってしまいますね。
まだまだこれからなのかもしれませんが、この分野は淘汰のスピードが速いのでこの先も生き残れるのかは少し疑問です。Tribuoを使用する明確な理由があればいいのですが...(Pythonのライブラリーで学習されたモデルをTribuoを使ってJavaプログラムから使用できるようなので、そういった用途はあるかもしれません)。今後の展開に期待したいです。