はじめに
この記事は、特徴量エンジニアリングについてわかりやすく説明することを目的として書きました。特徴量エンジニアリングについては、多くの記事で取り上げられていますが、最初に読む入門的な内容を目指しています。
分かりやすさを優先するため、言葉の定義の正確さなどは多少犠牲にしている点はご了承ください。
「特徴量エンジニアリング」とは、大雑把に言えば「機械学習モデルの予測精度を上げるための入力データの加工」のことですが、実はこの言葉の定義には曖昧さがあります。様々な記事を読むと、この言葉は使う人により若干意味が異なっていることが分かります。
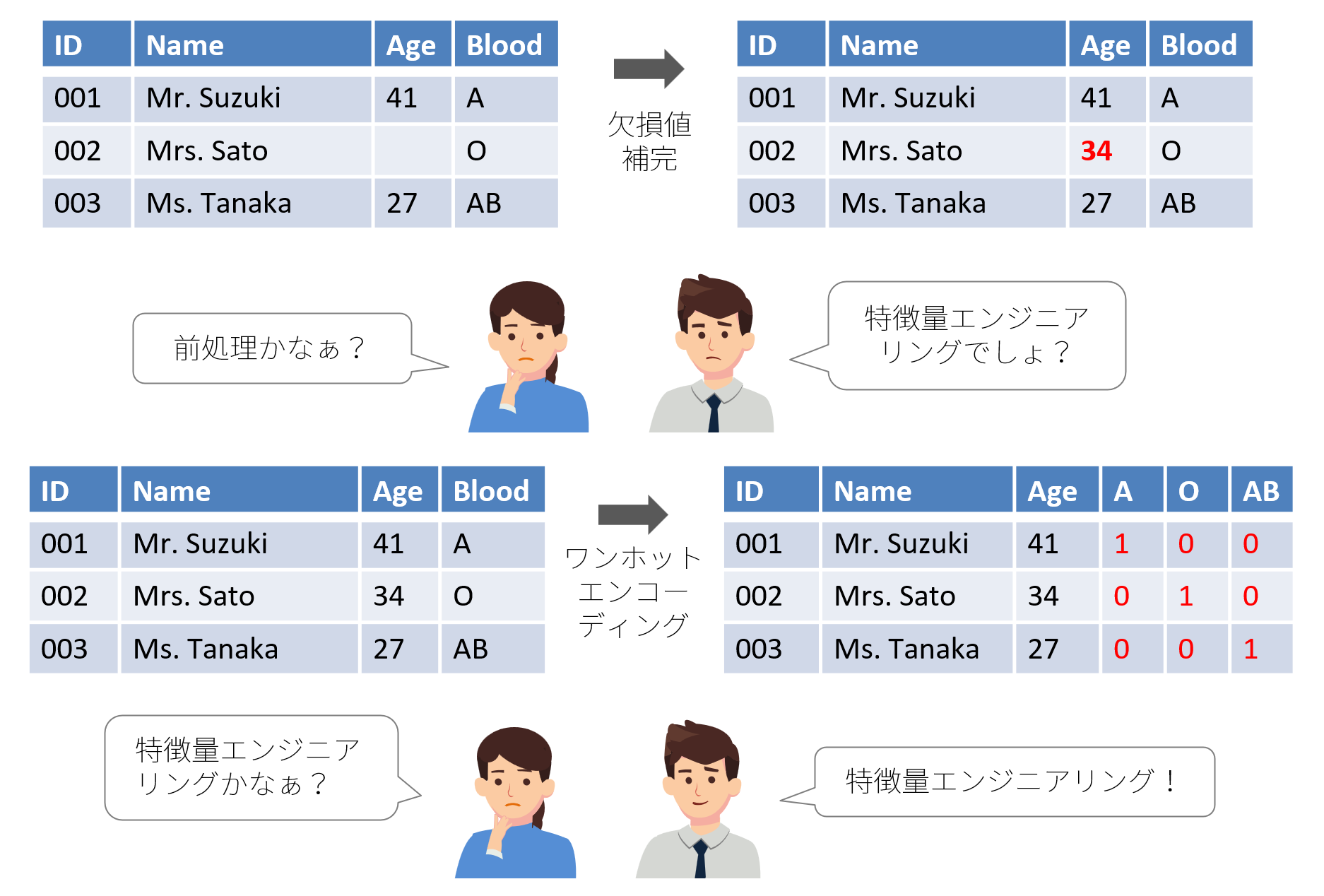
例えば、ある記事では、欠損値の補完は「前処理」で、カテゴリカルデータのワンホットエンコーディングが「特徴量エンジニアリング」と解説されています。一方、別の記事では両者とも「特徴量エンジニアリング」と解説されています。したがって、この言葉でイメージするものは人によって異なっていると言えます。
データサイエンティストの中でも自然言語処理をメインに扱う人にとっては、ストップワード1の除去や用語の出現頻度の算出などをイメージするかもしれません。

そこで、この記事では2023年12月26日発売の以下の書籍の内容をもとにできるだけ簡単に、特徴量エンジニアリングを説明したいと思います。

特徴量とは何か?
特徴量エンジニアリングを理解するには、まず「特徴量」が何であるかを理解しなければなりません。この書籍の中では以下のように表現されています。
本書では、モデルにとって意味のあるデータの属性(列)を特徴量と定義します。
つまり、以下のように考えることができます。
特徴量 ≒ 説明変数 ≒ 列(表形式のデータであれば)
※ただし、モデルの性能に良い影響を与えるものに限る
したがって、以下のような顧客の情報から、ビールの購入を予測するようなモデルにおいて、「Birthday」(生年月日)から特定される「Age」(年齢)は特徴量と言えますが、「ID」は特徴量とは言えません。
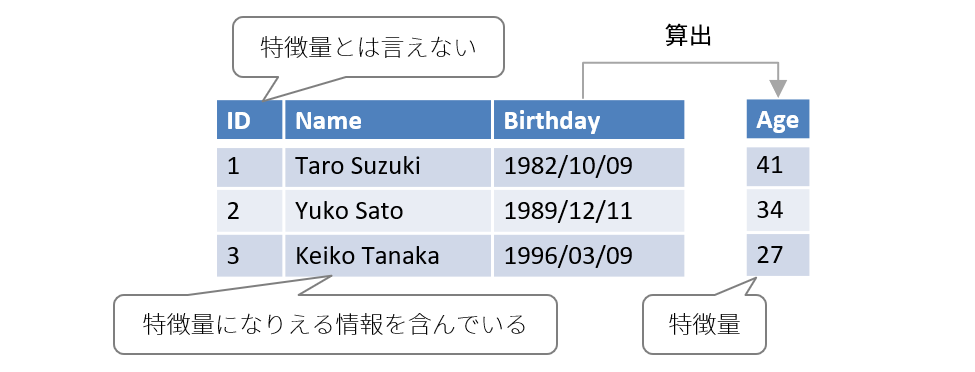
なぜなら、「若者のビール離れ」という言葉があるように年齢はビールの購入に大きく影響するのに対して、ユーザーを一意に識別する目的しかないIDは全く影響を与えないためです。また、「Name」(名前)はうまく扱えば、特徴量になりえます。ビールの購入に大きな影響を与える「性別」が、名前から特定できる可能性があるためです。
特徴量エンジニアリングとは何か?
前述した「特徴量」の「エンジニアリング」(工学)ということなので、つまり、モデルの性能に良い影響を与える説明変数を作り出すことと考えていいと思います。上の例で言えば、「Birthday」(生年月日)列をもとに「Age」(年齢)列をつくったり、「Name」(名前)列をもとに「Sex」(性別)列をつくったりすることが特徴量エンジニアリングと言えます。なお、書籍の中では以下のように記述されています。
本書において、特徴量エンジニアリングとは、データの複雑性や偏りを補正し、機械学習アルゴリズムがモデル化する問題に適した表現形式へ変換する操作手法を意味します。
特徴量エンジニアリングはなぜ必要か?
いくら高性能なモデルの構築に努力しても、データ自体がよくなければ、モデルは複雑なものになり、予測の精度は上がらない上に学習時間が大幅に増加してしまいます。データからモデルにとって有益な情報を抽出したり、無益な情報を削除することは、モデルが進化したとしても、良い結果を生み出す要因になります。
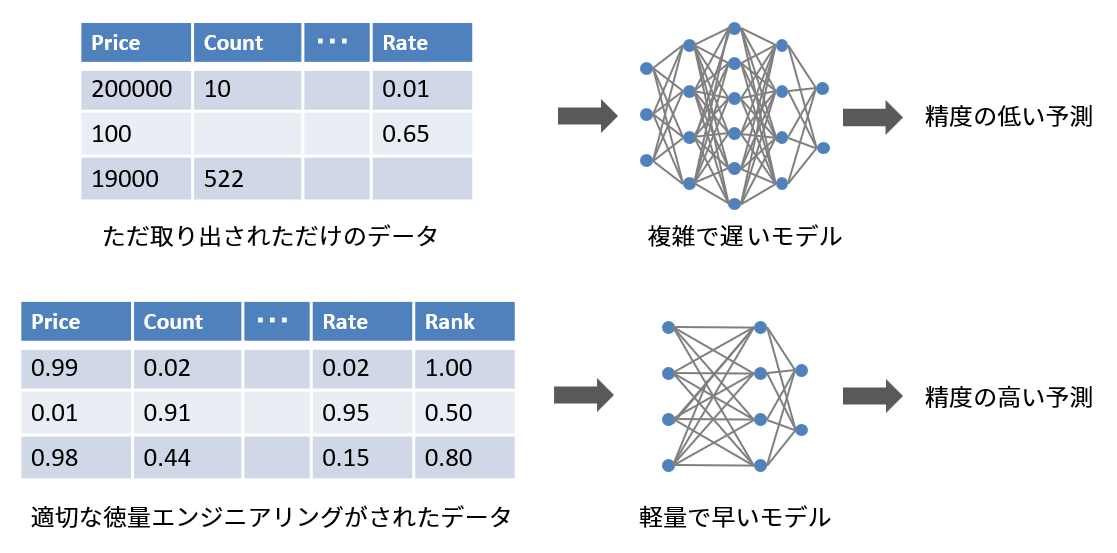
とはいえ、画像や音声の処理では、畳み込みニューラルネットワークのようなディープラーニングネットワークが自ら学習できるようになったため、それらの分野に特化した特徴量エンジニアリングの重要性は薄れてきているのは事実です。
しかし、完全に特徴量エンジニアリングが不要になったわけではありません。依然として特定のタスクや特定のデータセットにおいて、手動で特徴量を作成、改良、選択することが有用な場合は多々あります。また、データ品質の向上や特定のドメイン知識の適用によって、特徴量エンジニアリングがモデルの性能向上に寄与することがあります。Kaggleなどのコンペにおいても、最終的な順位を左右する要因になっているのは特徴量エンジニアリングであることは多いです。
特徴量エンジニアリングの種類
特徴量エンジニアリングの手法は無限に存在するため、それらを網羅することはできません。しかし、手法の種類を大まかに分類することはできます。「事例で学ぶ特徴量エンジニアリング」では、以下の5つに分類しています。
- 特徴量作成(Feature Construction)
- 特徴量改善(Feature Improvement)
- 特徴量選択(Feature Selection)
- 特徴量抽出(Feature Extraction)
- 特徴量学習(Feature Learning)
それぞれについて簡単に説明します。
特徴量作成
特徴量作成とは、既存の特徴量などから新しい特徴量を作成することです。例として以下のようなことが挙げられます。
- 結合

この例では、ユーザー情報に外部から取得したユーザーの「Rank」(ランク)列を結合しています。有益な情報が増えれば、それだけ予測の精度は高くなります。
- ワンホットエンコーディング

文字列型の「Blood」(血液型)列を「A」、「O」、「AB」の3つの列に分解して0と1だけで表現します。Aが0、Oが1、ABが2、Bが3を意味する1列で表現することもできますが、血液型には順序性がないので、このようにするのが一般的です(「ワンホットエンコーディング」と言います。)。なお、B型用の列「B」がありませんが、これは「A」、「O」、「AB」の3つの列をすべて0にすれば表現できるため不要です。
- ドメイン知識の利用

「Name」列に含まれる「Mr.」などの文字列から性別を特定し、「Sex」(性別)列を作成することができます(同時に不要になった「Name」列は削除)。このようにその分野の知識(=ドメイン知識。この場合は一般常識ですが...)から新しい特徴量を導き出せることがあります。
特徴量改善
特徴量改善とは、数学的な変換などにより既存の特徴量をより使いやすくすることです。例えば、以下のようなことが挙げられます。
- 欠損値の補完

多くの機械学習モデルでは、欠損値があると正常に動作しないため、一般的に欠損値は何らかの値で補完します。この例では欠損値を平均値で補完しています。
- 正規化

上のように、すべての値を0~1の範囲に収めること(正規化)で、学習の際に桁の大きな列が小さい列よりも大きな影響を与えてしまうことを回避できます。
特徴量選択
特徴量選択とは、既存の特徴量から最適な特徴量のみを残すことです。例えば、以下のように血液型に関する情報を削除することもその1つです。

「情報量が多い方が予測精度が上がるのでは?」と思ったかもしれませんが、そうとは限りません。例えば、購入予測モデルに対して血液型は特徴量になりえないでしょう。なぜなら、「血液型」と「購入」の間に論理的な因果関係が無いためです。血液型で性格を判断することは日常で良くありますが、それが正しいことを示す科学的根拠はありません。したがって、「血液型」は特徴量ではないと考えるのが妥当です。このような列は、学習においてノイズにしかならないため、列を削除してしまった方が予測の精度も上がります(そのような意味では、医療などの分野を除くと、そもそも血液型は特徴量とは言えないのかもしれませんが...)。
上の例では、一般的な知識により判断して列を削除しましたが、ランダムフォレストなどで各説明変数の重要度で算出して、重要度の低いものを削除するようなこともできます。
特徴量抽出
特徴量抽出とは、数学的な変換を用いて、元のデータを最適な新しい特徴量にマッピングする手法を指します。例えば、線形代数の手法を応用した主成分分析(PCA)や特異値分解(SVD)なども特徴量抽出と言えます。
自然言語処理の一般的な特徴量抽出の手法の1つに、単語の語彙を学習し、生のテキストを単語の出現回数のベクトルに変換する手法があります。この手法は、古典的ではありますが、実装が容易で、解釈可能な特徴量を生成できるなど、多くの利点があります。

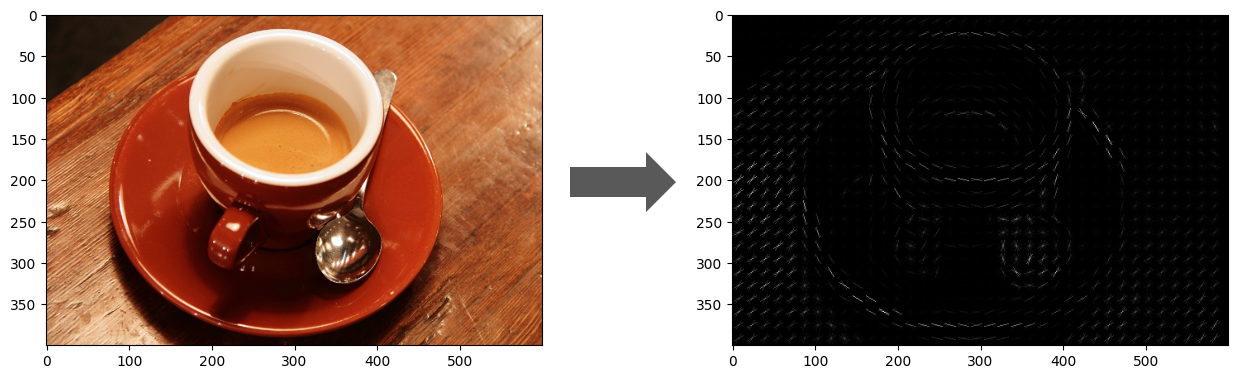
画像処理の古典的な特徴量抽出の手法の1つにHOG(勾配方向ヒストグラム)があります。HOGは、画像の局所的な領域における各画素値の変化(勾配)の大きさと方向を計算し、その情報を利用してヒストグラムを計算し、最終的な特徴量を決定します。
特徴量学習
特徴量学習(表現学習とも呼ばれる)は、テキストや画像、動画などの非構造化データから特徴量を自動的に生成する点で、特徴量抽出と似ています。しかし、ディープラーニングのモデルを利用し、元のデータの潜在的な「表現」を自動的に発見しようとする点で異なります。特徴量学習は特徴量エンジニアリング中でも高度な手法です。

具体的な例として、オートエンコーダー(自己符号化器)を使用して、画像の特徴量を学習することなどが挙げられます。オートエンコーダーは、入力をエンコード(符号化=圧縮)してから、もとに戻して出力する手法です。この手法の特徴は、入力と出力が同じになるように学習させる点です。一見、意味がないように思われますが、下の図を見てわかるように、入力層と出力層に対して中間層の数が少なくなっていることに意味があります。
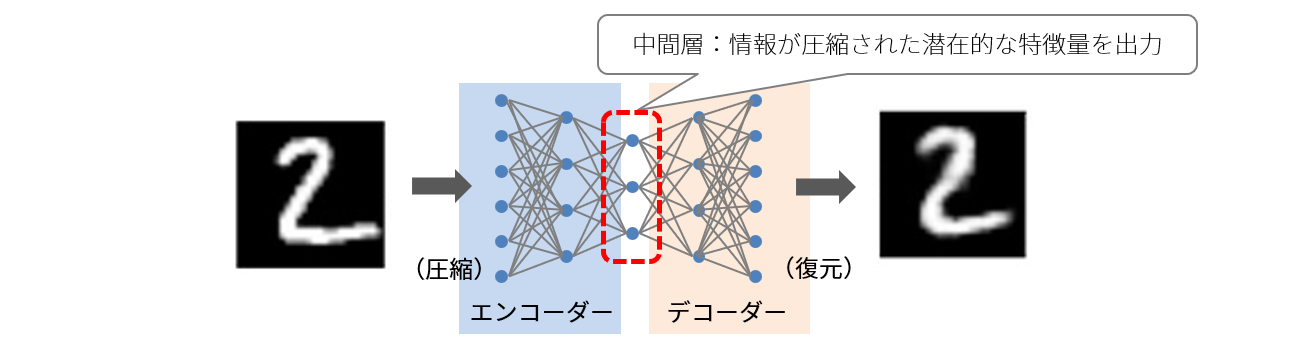
中間層で情報を圧縮させても同じ答えを出せるように不要な情報を落とし、必要な情報である特徴量を学習しているためです。
最後に
この記事では特徴量エンジニアリングについて非常に簡単にまとめました。主に表形式のデータを例に挙げて説明しましたが、それ以外の形式のデータでも特徴量エンジニアリングはでき、その手法は多数あります。また、5つの特徴量エンジニアリングの手法の種類を挙げましたが、これらを分ける境界は明確ではなく、分けなければいけないというものでもありません。あくまでも「事例で学ぶ 特徴量エンジニアリング」の著者による分類であり、別の分類もあり得ることはご理解ください。
特徴量をどのように作成し、その有効性をどのように評価するかについては、この書籍の中で解説されています。実践的なユースケースを題材にしたノートブックとともに、実際にコードを動かしながら学習できる内容になっていますので、さらに勉強したい方は参考になると思います。
-
ストップワード(Stop Word)とは、テキストデータ内の単語や複合語のうち、通常、文脈やタスクに対してあまりにも一般的であり、重要な情報を提供しないと考えられる単語やトークンのことを指します。英語のストップワードには、「a」、「in」、「and」などが含まれます。 ↩