Open-WebUI とは?
open-webuiはもともと、OllamaのWebインタフェイスとして開発されました。ollamaはCPUだけでも稼働するというのがウリのLLMツールです。
他にもRAG用エンベディングLLMやランカーLLMの指定、OpenAI API対応、LangChainなどのライブラリとの連携、LLMパラメータやコンテキスト指定、複数設定のLLM一括使用など、意欲的な機能追加が行われています。
さながら、LLMと様々なアプリケーションとユーザーをつなぐハブ的なソフト。
以下の記事は、2023年7月9日のVer.0.3.8を基に説明します。
できるだけ、最新のOpen-WebUIの内容で記事更新したいと思います。
Ollamaは、LLMがggufというコンパクトさを意識したフォーマットでできたデータで、gemmaやcommand-R,llama3など有名どころのLLMがggufに変換されライブラリからpullして使えます。
もちろん、自分でチューニングしたLLMも使えたり、Ollamaの代わりにOpenAIのAPIが使えたりします。
セットアップは、まずdockerをインストールしてから、ollamaとopen-webui をdocker runでコンテナ作成までを行います。
最新のdocker desktopは、ほぼインストールだけですむので、dockerのインストールは終わっているものとして紹介していきます。
ollama+Open-WebUI セットアップ
以下の2つのdocker runコマンドで、ollamaとOpen-WebUIをpull,runします。
ollamaのセットアップのdocker run ...GPU不使用の場合
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Open-webuiのdocker run
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
できあがりイメージ

基本的な設定
【ログインアカウントの設定】
Ollama、Open-WebUIのセットアップ後、ブラウザから、
http://[インストール先またはlocalhost]:3000
でアクセスできます。
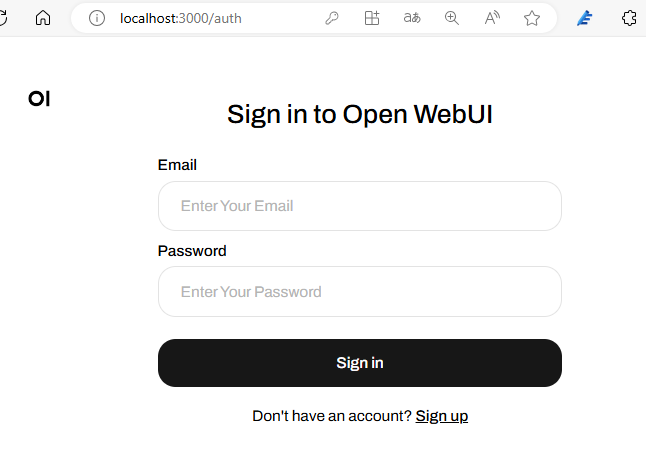
初回起動でログインアカウントの登録画面が表示されます。
ここで登録しても、どこかのサイトに登録されるとかいうことはありません。
はじめて登録されたアカウントは、管理者として登録されます。
このあと日本語表示に変えた後、必要に応じて「管理者パネル」メニュー中の「Dashboard」で別の管理者アカウントを作ったり、「役割」を「ユーザー」や「管理者」に変更したりしてアクセスユーザーの管理をしてください。

【表示の日本語化】
左下のアイコンにある「Setting」メニュー中の「General」にある「Language」の設定で「日本語」に設定します。

【LLMモデルのダウンロード】
左下のアイコンにある「管理者パネル」メニュー中の「設定」にある「モデル」の設定の「Ollama.comからモデルをプル」でLLMのタグ名前を指定します。ここでは「vicuna:7b」を設定します。
タグ名はここを参照して下さい。
右のダウンロードアイコンをクリックするとダウンロードが始まります。
「vicuna:7b」はそこそこ軽くて日本語も上手なLLMです。

【ちょっと使ってみる】
ここまで設定すれば、vicunaが答えてくれます。
右上の「新しいチャット」から始めます。
「モデルを選択」でvicuna:7bを選択してから、一番下の「メッセージを送信」でプロンプトを書いて送信します。
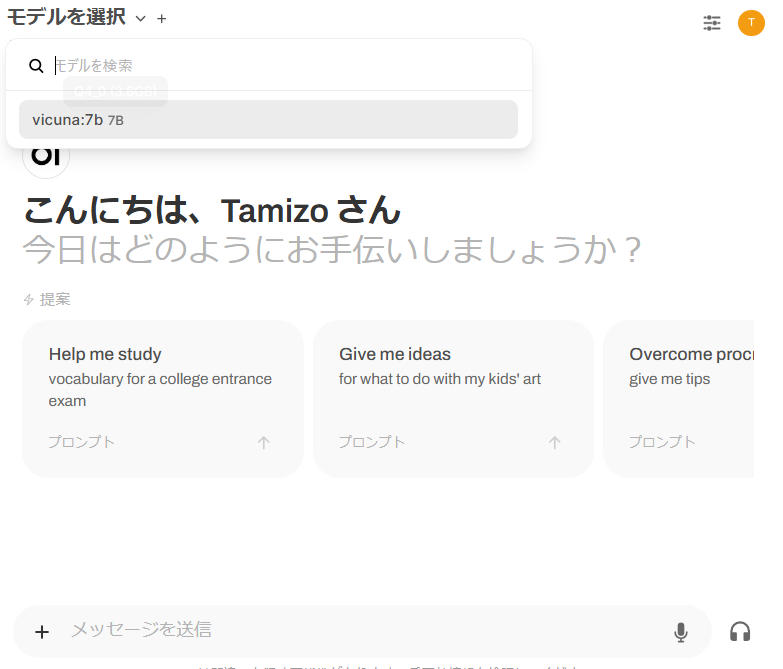
ためしに、LLM回答を見てみます。
普通の問いに当然答えられますが、ここではvicunaが知らなそうなことを聞いてみます。
私が庭で育てているナスの強敵”テントウムシだまし”のことを聞いてみました。
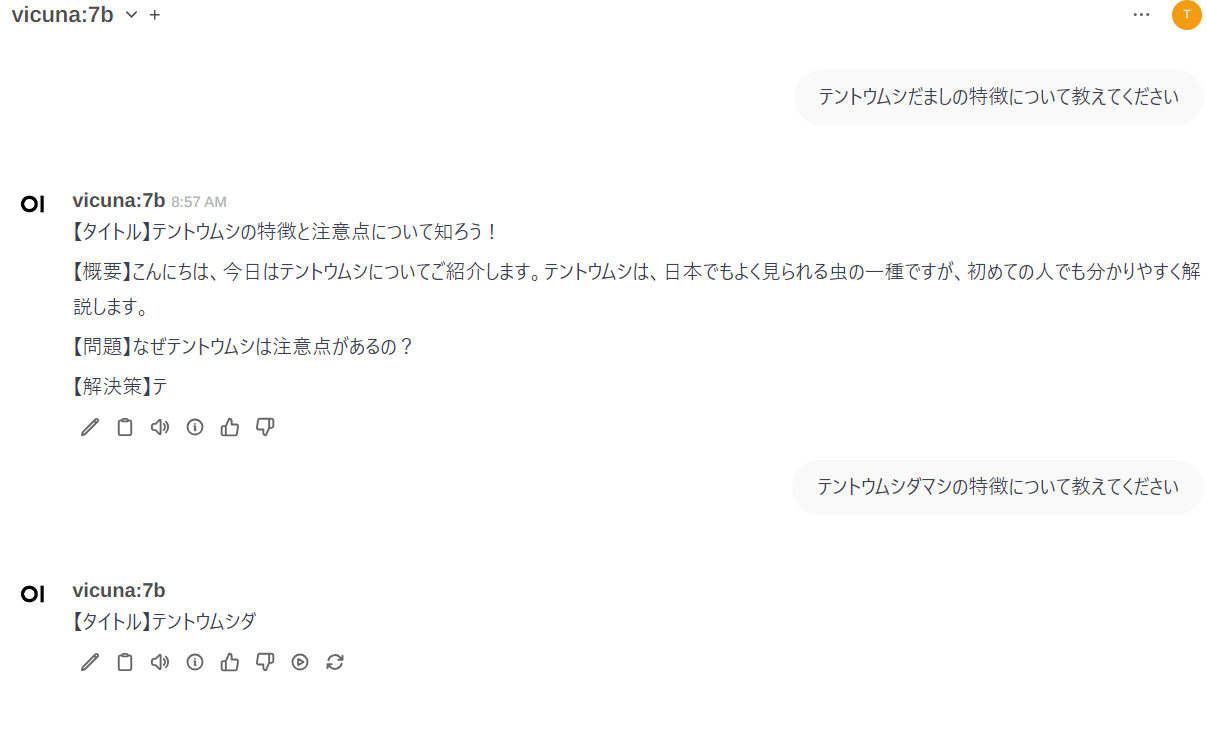
どこから引用されたのかが不明な、たどたどしい答えが返ってきました。
次で説明するRAGを使って、これをまともな答えにしていきます。
RAGを使ってみる
プロンプトにドキュメントを添付して、それを参考にした回答を得るRAGを試してみます。
以下の2つの方法があります。
- プロンプトを打つときに添付する
- あらかじめ複数の資料をアップロードし、資料群を一括で添付したり、LLMに紐付ける
まずは、添付した資料をプロンプトに埋め込むLLMの設定から行います。
【RAG用LLMの日本語対応】
左下のアイコンにある「管理者パネル」メニュー中の「設定」にある「ドキュメント」の設定で「埋め込みモデル」に日本語のembedingモデルを設定します。
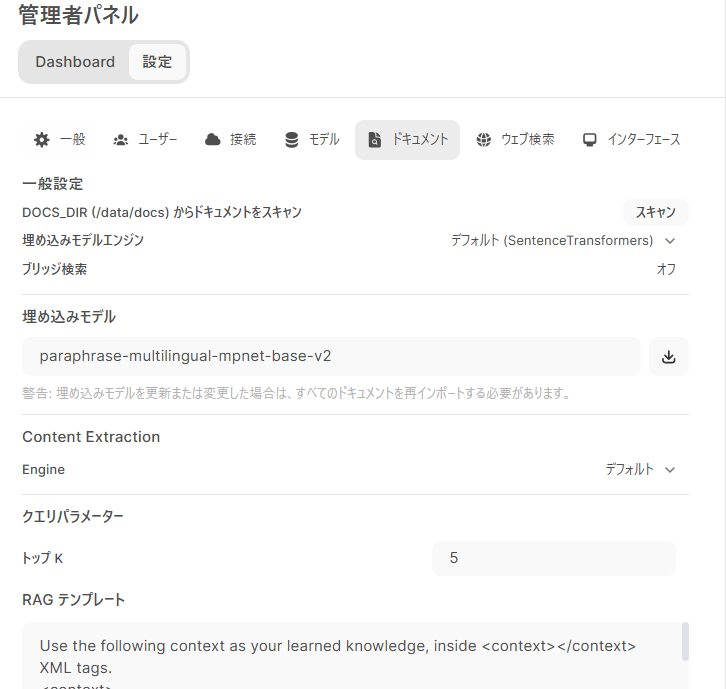
わたしは、以下の日本語対応のemmbedingモデルを使ってみています。
paraphrase-multilingual-mpnet-base-v2
paraphrase-multilingual-MiniLM-L12-v2
stsb-xlm-r-multilingual
【ドキュメントと一緒にプロンプトを投げる】
次に、プロンプトを投げるときに、pdfを添付して、その内容について聞いてみます。
テントウムシダマシについて書かれた資料”テントウムシだまし.pdf”をチャットの画面にドラグ&ドロップして添付し、質問してみます。
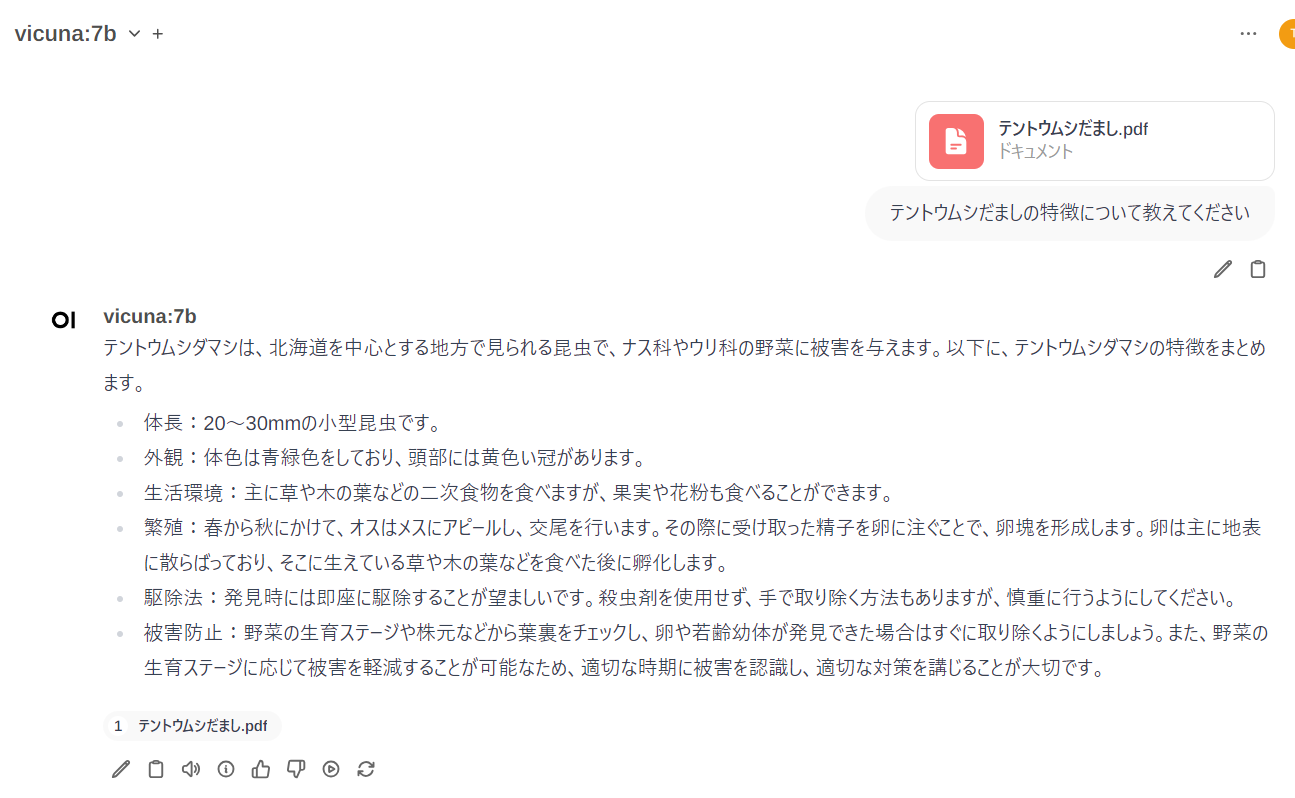
この内容を確認しましたがほぼほぼ資料には書かれていませんでした。
おそらく添付した資料をきっかけに、vicunaが知っている事柄に答えやすくなったものと考えられます。
次に、temparatureとTop-Pを、それぞれ0.4程度まで下げて改めて聞いてみます。

このレスポンスの下に”1 テントウムシだまし.pdf”と書かれた、添付資料のアイコンをクリックしてみます。
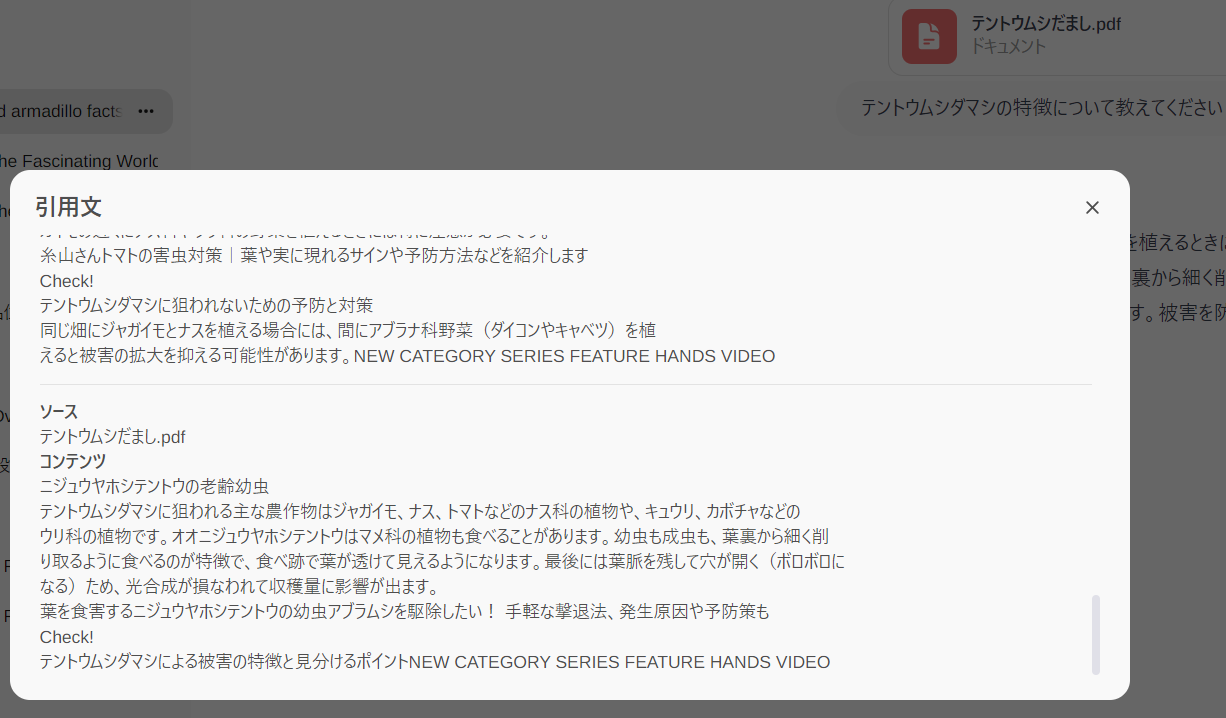
引用部分の内容が確認できて、ちゃんと読んでくれていることが分かります。
これで、裏付け確認やハルシネーション状況の確認ができて、信頼性が高いですね!
【あらかじめドキュメントアップロードしておく】
右上の「ワークスペース」から、「ドキュメント」メニューに行きます。

この画面にドラグ&ドロップすると資料がアップロードされます。
各資料の右のほうのペンアイコンをクリックすると、その資料に関するタグや資料名を編集できます。
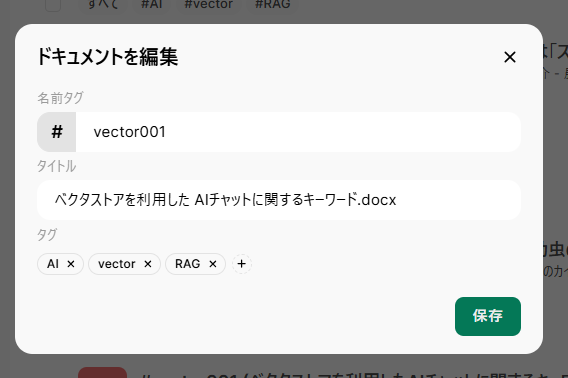
名前タグ:アルファベットでその資料を表す名前を付けて、プロンプトを書くとき簡単にアクセスできるよう設定します。
タイトル:資料のタイトルを変更したい場合にここで変えます。
タグ:同じテーマでのタグを複数の資料に付与すれば、そのタグを使って複数の資料をしてできます。
では、これらの資料をプロンプトのところで資料を指定してみましょう。
プロンプト文を書く前に、"#"キーを押すと、アップロードした資料やタグが表示されます。
さらに英数字を入れて絞っていって改行キーで決定したり、マウスで選択したりします。
タグを指定すると、複数の同じテーマのタグのドキュメントを一括添付してRAGします。
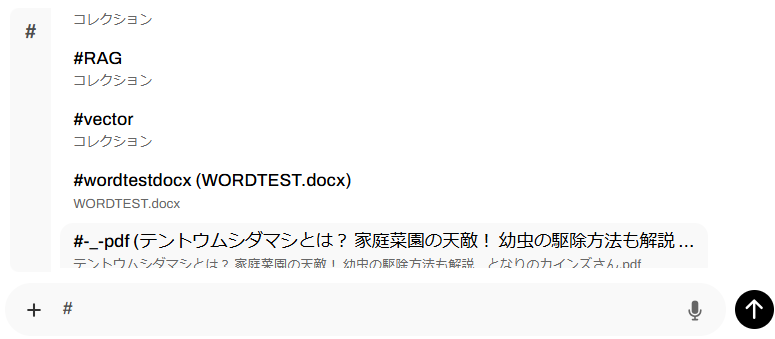
もちろん、RAGが参照した部分の一覧も表示されます。
このタグは、次のモデルのカスタマイズでも活用できます。
モデルのカスタマイズ
ダウンロードしたLLMをベースに、カスタム化したモデルを扱う機能について紹介します。
- システムプロンプトやtemparature,Top-Pなどカスタマイズした設定を含めて1つのモデルとして設定。振る舞いが異なるモデルを複数設定できる
- RAG用の資料が紐付けでき、添付操作不要で資料のテーマの回答が得られる
- チャット中、モデルはいつでも切り替え可能
- 複数のカスタムモデルを選択して、一斉にプロンプトを投げ、それぞれの回答が得られる
設定はつぎのとおり。
まずは右上の「ワークスペース」から、「モデル」メニューに行きます。

「+モデルファイルを作成する」ボタンで、モデルのカスタマイズ画面に行きます。
下記の例では、AIの最新技術に特化した回答をしてくれます。
モデル名は「ai-tech-assistant-vicuna」としました。
もちろん資料は管理者が設定してあげなければなりません。

この例では、モデルの名前やID、システムプロンプト、temparature、Top-Pをカスタマイズした例です。
さらに下の図では、提案プロンプトと、デフォルトでRAGする資料を指定します。

あとはチャットの画面で「ai-tech-assistant-vicuna」を指定してプロンプトを書けば、紐付けした資料を読んで回答してくれます。
機能は他にもたくさん
この記事で紹介したのは、一部の基本機能のみです。まだ開発中の機能、プラグインの様にプログラミングでの機能追加、などまだまだ機能がありますので、その内容どんどん紹介していきます。
他の機能
Open AI連携 OpenAIのAPIキーを設定すれば、OpenAIのLLMが使用できます。もちろん有償
パイプライン llamaindexやベクタデータベースなどの外部ライブラリと連携できます。
音声認識/音声回答
WebサーチでRAG
画像生成の統合