はじめに
CAP-LLMプラグインは、SAP AI CoreやSAP HANA CloudのVector Engineとのやりとりを簡単にするためのライブラリです。
以下のブログにCAP-LLMプラグインを使用してHANA CloudのVector EngineにEmbeddingを登録したり、Retrieval Augmented Generation (RAG)を実行したりする方法が紹介されています。CAP-LLMプラグインを使用すると、RAGを実行するときにEmbeddingの作成とVectorからの取得が一度に行え、コードが少なくて済みます。
サンプルリポジトリ
本記事の目的
SAP AI Coreはトライアルアカウントでは使用できないため、本記事ではCAP-LLMプラグインを使わない方法で上記のリポジトリと同じことを実施します。LLMについては、OpenAIを使用します。
作成したコードは以下のリポジトリにあります。
プロジェクト構成
プロジェクト構成は以下のとおりです。
.
├── db
│ ├── data
│ │ └── codejam_roadshow_itinerary.txt
│ ├── schema.cds
│ ├── src
│ └── undeploy.json
├── srv
│ ├── embedding-storage.cds
│ ├── embedding-storage.js
│ ├── roadshow-service.cds
│ ├── roadshow-service.js
│ └── utils
│ └── OpenAIUtil.js
└── package.json
サービスは2つあります。
-
EmbeddingStorageService:
db/data/codejam_roadshow_itinerary.txtに格納された"SAP CodeJam Roadshow 2024"の予定をEmbeddingに変換し、SAP HANA CloudのVectorストアに格納する - RoadshowService: Vectorストアに格納したデータを利用してRAGおよびSimilarity Searchを行う
データモデル
db/schema.cdsで、Vectorデータを格納するためのテーブルを定義します。
namespace cap.vector;
entity DocumentChunk {
text_chunk: LargeString;
metadata_column: LargeString;
embedding: Vector(1536);
}
Vectorの型を使うためには、@sap/cds-hanaをインストールする必要があります。
EmbeddingStorageService
サービス定義
storeEmbeddingsとdeleteEmbeddingsという2つのファンクションを定義しています。これらは変更を伴うため本来はアクションとして定義すべきですが、ブラウザから実行したいためファンクションとしています。
using { cap.vector as db } from '../db/schema';
service EmbeddingStorageService {
entity DocumentChunk as projection on db.DocumentChunk excluding { embedding };
function storeEmbeddings() returns String;
function deleteEmbeddings() returns String;
}
サービス実装
以下ではstoreEmbeddingsファンクションの実装について解説します。deleteEmbeddingsはオリジナルのソースと変えていません。
const cds = require('@sap/cds')
const { TextLoader } = require('langchain/document_loaders/fs/text')
const { RecursiveCharacterTextSplitter } = require('langchain/text_splitter')
const path = require('path')
const { OpenAIUtil } = require('./utils/OpenAIUtil')
// Helper method to convert embeddings to buffer for insertion
let array2VectorBuffer = (data) => {
...
}
module.exports = class EmbeddingStorage extends cds.ApplicationService {
init () {
this.on('storeEmbeddings', async(req) => {
const { DocumentChunk } = this.entities
let textChunkEntries = []
console.log(__dirname)
//1. get document
const loader = new TextLoader(path.resolve('db/data/codejam_roadshow_itinerary.txt'))
const document = await loader.load()
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 0,
addStartIndex: true
})
const textChunks = await splitter.splitDocuments(document)
console.log(`Documents split into ${textChunks.length} chunks.`)
//2. generate embeddings
console.log("Generating the vector embeddings for the next chunks.")
const openai = new OpenAIUtil()
for (const chunk of textChunks) {
console.log(chunk.pageContent)
const embedding = await openai.getEmbedding(chunk.pageContent)
const entry = {
"text_chunk": chunk.pageContent,
"metadata_column": loader.filePath,
"embedding": array2VectorBuffer(embedding)
}
console.log(entry)
textChunkEntries.push(entry)
}
//3. store embeddings into db
console.log("Inserting text chunks with embeddings into db.")
const insertStatus = await INSERT.into(DocumentChunk).entries(textChunkEntries)
if (!insertStatus) {
throw new Error("Insertion of text chunks into db failed!")
}
return `Embeddings stored successfully to db.`
})
this.on('deleteEmbeddings', async(req) => {
const { DocumentChunk } = this.entities
await DELETE.from(DocumentChunk)
return "Success!"
})
return super.init();
}
}
オリジナルのソースと変えた部分は、Embeddingを取得する箇所です。オリジナルのソースでは、CAP-LLMプラグインを使って取得しています。
const embedding = await vectorPlugin.getEmbedding(chunk.pageContent)
今回は、OpenAI Node API Libraryを使用してEmbeddingを取得します。
const { OpenAIUtil } = require('./utils/OpenAIUtil')
const openai = new OpenAIUtil()
...
const embedding = await openai.getEmbedding(chunk.pageContent)
OpenAIとやりとりするためのOpenAIUtilクラスを以下のように定義しています。
const OpenAI = require('openai')
class OpenAIUtil {
constructor() {
this.openai = new OpenAI()
}
async getEmbedding(input) {
const response = await this.openai.embeddings.create({
model: "text-embedding-ada-002",
input: input,
encoding_format: "float"
})
return response.data[0].embedding
}
async chat(messages) {
const response = await this.openai.chat.completions.create({
messages: messages,
model: "gpt-3.5-turbo"
})
return response.choices[0].message.content
}
}
module.exports.OpenAIUtil = OpenAIUtil
RoadshowService
サービス定義
getRagResponseとexecuteSimilaritySearchという2つのファンクションを定義しています。RAGへのインプットはハードコーディングしているため、これらのファンクションにはインプットがありません。
service RoadshowService {
function getRagResponse() returns String;
function executeSimilaritySearch() returns array of {
text_chunk: String;
cosine_similarity: Decimal;
l2Distance: Decimal;
};
}
サービス実装
getRagResponseファンクション
const cds = require('@sap/cds')
const { OpenAIUtil } = require('./utils/OpenAIUtil')
const userQuery = 'In which city are Thomas Jung and Rich Heilman on April, 19th 2024?'
const instructions = 'Return the result in json format. Display the keys, the topic and the city in a table form.'
module.exports = class RoadshowService extends cds.ApplicationService {
init() {
this.on('getRagResponse', async () => {
//1. get embedding for input
const openai = new OpenAIUtil()
const embedding = await openai.getEmbedding(userQuery)
//2. retrieve relevant contents
const db = await cds.connect.to('db')
const { DocumentChunk } = db.entities;
const contents = await SELECT.from(DocumentChunk)
.limit(3)
.where`cosine_similarity(embedding, to_real_vector(${JSON.stringify(embedding)})) > 0.7`
console.log(contents)
let context;
contents.forEach(content => {
context = context + '\n' + content.text_chunk
})
console.log(context)
//3. get response
const messages = [
{ role: 'system', content: context },
{ role: 'user', content: userQuery }
]
const response = await openai.chat(messages)
return response
})
...
return super.init()
}
}
オリジナルのソースではCAP-LLMプラグインを使い、1ステップでレスポンスを取得しています。
const vectorplugin = await cds.connect.to('cap-llm-plugin')
const ragResponse = await vectorplugin.getRagResponse(
userQuery,
tableName,
embeddingColumn,
contentColumn
)
今回は以下の3ステップで行っています。
- Embeddingの取得
const openai = new OpenAIUtil()
const embedding = await openai.getEmbedding(userQuery)
- Vectorストアから関連するコンテンツの取得
const db = await cds.connect.to('db')
const { DocumentChunk } = db.entities;
const contents = await SELECT.from(DocumentChunk)
.limit(3)
.where`cosine_similarity(embedding, to_real_vector(${JSON.stringify(embedding)})) > 0.7`
...
let context;
contents.forEach(content => {
context = context + '\n' + content.text_chunk
})
CAPでは、Vector同士の近さや類似性をcosineSimilarityおよびl2Distanceというファンクションで計算することができます。
https://cap.cloud.sap/docs/guides/databases-hana#vector-embeddings
- OpenAIからチャットのレスポンスを取得
const messages = [
{ role: 'system', content: context },
{ role: 'user', content: userQuery }
]
const response = await openai.chat(messages)
executeSimilaritySearchファンクション
this.on('executeSimilaritySearch', async () => {
//1. get embedding for input
const openai = new OpenAIUtil()
const embedding = await openai.getEmbedding(userQuery)
//2. retrieve relevant contents
const db = await cds.connect.to('db')
const { DocumentChunk } = db.entities;
const contents = await SELECT.from(DocumentChunk)
.columns `text_chunk,
cosine_similarity(embedding, to_real_vector(${JSON.stringify(embedding)})) as cosine_similarity,
l2Distance(embedding, to_real_vector(${JSON.stringify(embedding)})) as l2Distance`
.limit(4)
// .where`cosine_similarity(embedding, to_real_vector(${JSON.stringify(embedding)})) > 0.7`
.orderBy `cosine_similarity(embedding, to_real_vector(${JSON.stringify(embedding)})) desc`
return contents
})
オリジナルのソースではCAP-LLMプラグインを使い、1. Embeddingの取得、2. Similarity Searchの実行という2ステップで実行しています。
const vectorplugin = await cds.connect.to('cap-llm-plugin')
const embeddings = await vectorplugin.getEmbedding(userQuery)
const similaritySearchResults = await vectorplugin.similaritySearch(
tableName,
embeddingColumn,
contentColumn,
embeddings,
'L2DISTANCE',
3
)
return similaritySearchResults
今回は、同じステップを以下のように実装しています。
- Embeddingの取得
const openai = new OpenAIUtil()
const embedding = await openai.getEmbedding(userQuery)
- Similarity Searchの実行
const db = await cds.connect.to('db')
const { DocumentChunk } = db.entities;
const contents = await SELECT.from(DocumentChunk)
.columns `text_chunk,
cosine_similarity(embedding, to_real_vector(${JSON.stringify(embedding)})) as cosine_similarity,
l2Distance(embedding, to_real_vector(${JSON.stringify(embedding)})) as l2Distance`
.limit(4)
// .where`cosine_similarity(embedding, to_real_vector(${JSON.stringify(embedding)})) > 0.7`
.orderBy `cosine_similarity(embedding, to_real_vector(${JSON.stringify(embedding)})) desc`
サービスの実行
ハイブリッドモードで実行
ローカルで実行する場合、HANA Cloudに接続する必要があるためハイブリッドモードで実行します。
cf create-service-key cap-vector-db cap-vector-db-key
cds bind -2 cap-vector-db
cds watch --profile hybrid
※先にアプリケーションをCloud FoundryにデプロイしてHDIコンテナを作成しておくこと
getRagResponseのレスポンス(例)

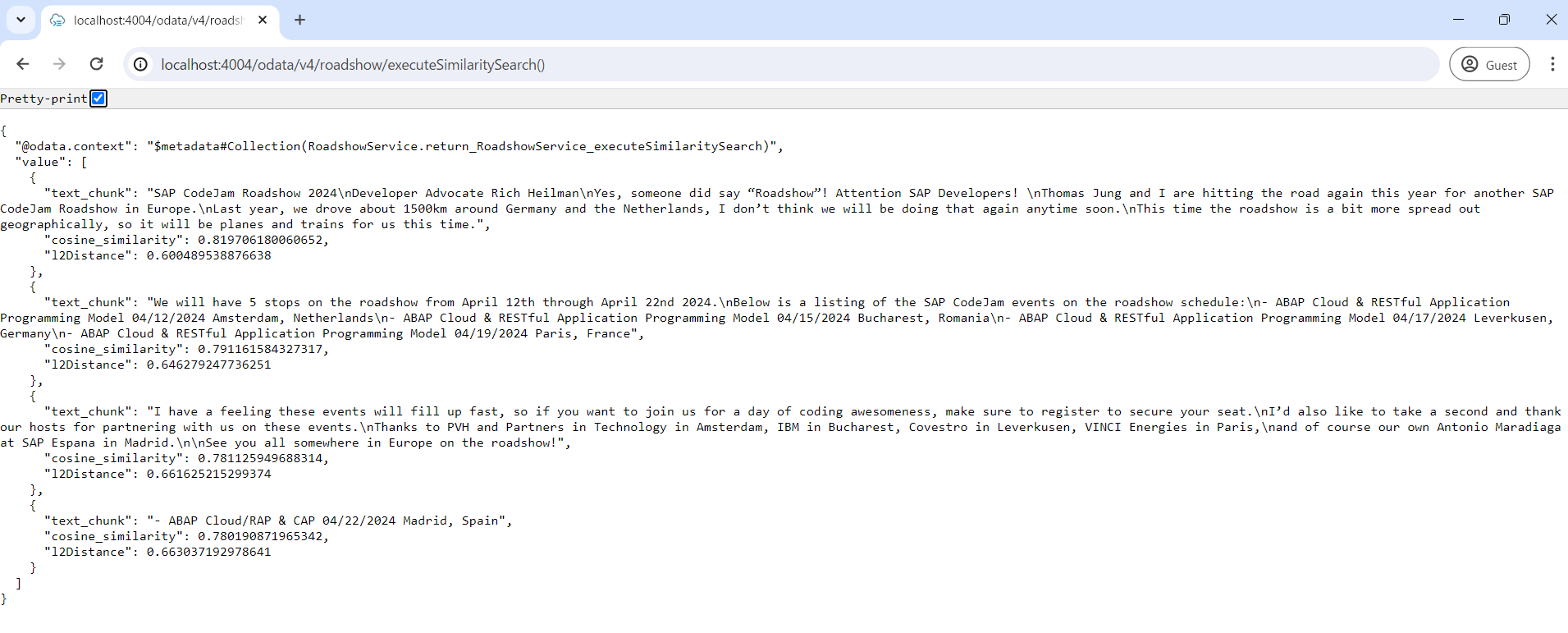
executeSimilaritySearchのレスポンス
まとめ
CAP-LLMプラグインを使わない場合、Embeddingの作成やVectorストアの検索を自前で実装する必要がありますが、さほどコード量が増えるわけではないことがわかりました。これは、CAP自体がVectorストアとやり取りするためのファンクションを備えていることや、OpenAIのライブラリにより短いコードでOpenAIとのやりとりが行えるためです。よって、SAP AI CoreやCAP-LLMプラグインを使わなくても、CAPでRAGの実装は簡単にできるといえます。