はじめに
私はつい最近Qiitaを始めました。自分の記事がどのくらい人の目に触れたか、気になるものです。なので毎日のように記事のビュー数を確認していました。

しかし、記事が10本くらいになると、それぞれの記事を開いてビューを確認して…という作業が面倒になってきました。
そこで、seleniumを使ってQiitaのview数をカウントし、CSVファイルに出力するプログラムを作りました。
参考にしたもの
準備
※環境はwindows10
- seleniumのインストール :
pip install selenium - webdriver(Chrome)のインストール:[こちら](pip install selenium)
- webdriverを格納したパスを環境変数に登録
ソース
まずは、ライブラリのインポート
from selenium import webdriver
import time
import datetime
import csv
続いて、Qiitaのマイページを開きます。
browser = webdriver.Chrome()
browser.get('https://qiita.com/<マイページ>')
マイページにはこんな感じで記事が並んでいます。
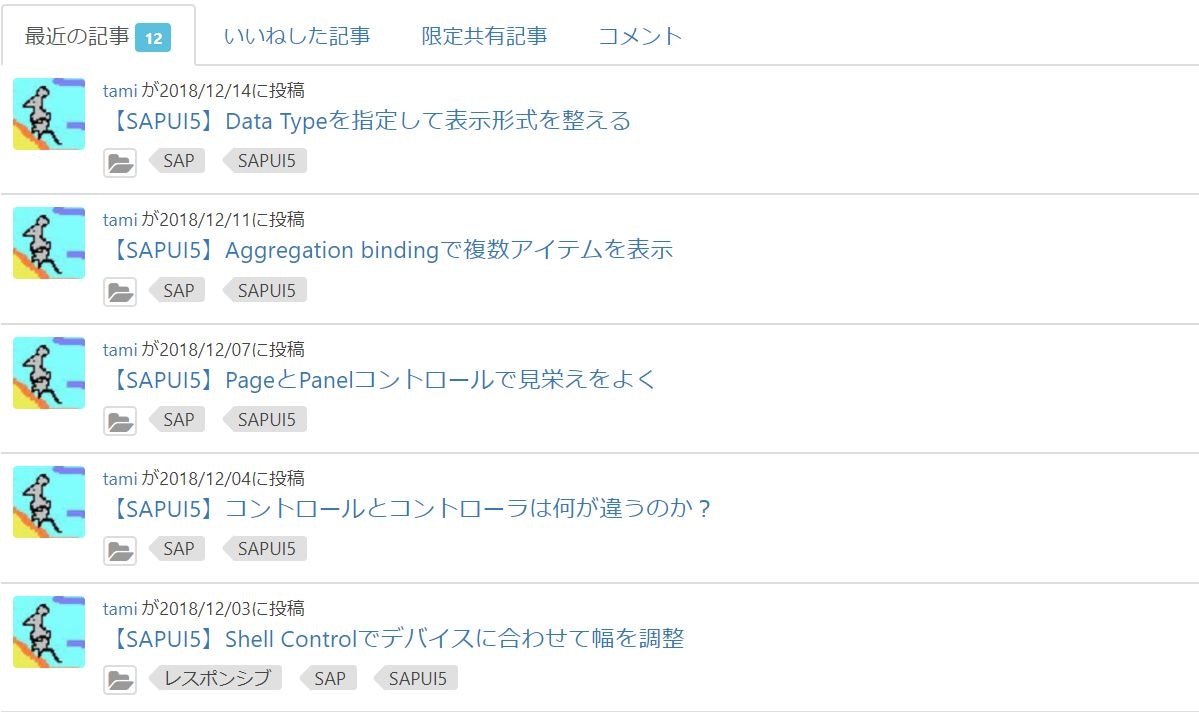
このリストは'tableList'というクラス名がついているので、まずはクラス名でリストを指定し、その中のリンクの要素('u-link-no-underline')をすべて取得します。
続いて、もう一つブラウザを開きます。このあとで記事のリンクを一つずつ開いていくのですが、マイページを開いた状態でキープしておかないとうまく動かなかったので、記事は別ブラウザで開くことにしました。
# 記事のリストを取得
articles = browser.find_element_by_class_name('tableList').find_elements_by_class_name('u-link-no-underline')
subBrowser = webdriver.Chrome()
以下はCSVファイルを出力するための準備です。日々の記録をつけていくので、ファイルは追記モード'a'で開きます。実行日付をファイルに書き込むために、変数dateを定義します。
# 出力用ファイルをオープン
f = open('QiitaLog.csv', 'a')
writer = csv.writer(f, lineterminator='\n')
datetime = datetime.date.today() # 日付
date = datetime.strftime("%Y/%m/%d")
ここからは、記事のリストをループしながら記事を一つずつ開き、ビュー数を取得し、CSVファイルに書き込む処理です。loginという関数はこの後で定義します。
for article in articles:
count = []
# リンク、テキストを取得
url = article.get_attribute('href')
text = article.text
# 新しいブラウザで開く
subBrowser.get(url)
# まだログインしていない場合はログイン
try:
subBrowser.find_element_by_class_name('st-Header_loginLink')
login(subBrowser)
except:
pass
# ビュー数をカウント
time.sleep(2)
views = subBrowser.find_element_by_class_name('it-Header_pv')
views_count = int(views.text.replace(' views', ''))
# 日付、テキスト、リンク、ビュー数を配列に格納
count.append(date)
count.append(text)
count.append(url)
count.append(views_count)
# CSVファイルに書き込み
writer.writerow(count)
ループが終わったらファイルをクローズし、ブラウザも閉じます。
# ファイルクローズ
f.close()
# ブラウザを閉じる
subBrowser.close()
browser.close()
最後にlogin関数の定義です。新しいブラウザで開いたときはログインしないとview数が見られないので、ログインの処理を作成します。ページ右上のログインボタンを押し、googleのアカウントを使ってログインします。xxxxには自分のメールアドレス、パスワードを設定します。

def login(browser):
# ログイン
browser.find_element_by_class_name('st-Header_loginLink').click()
# googleアカウント
browser.find_element_by_class_name('btn-google-inverse').click()
time.sleep(2)
browser.find_element_by_id('identifierId').send_keys('xxxx@gmail.com')
browser.find_element_by_class_name('CwaK9').click()
time.sleep(2)
browser.find_element_by_name('password').send_keys('xxxx')
browser.find_element_by_class_name('CwaK9').click()
実行結果
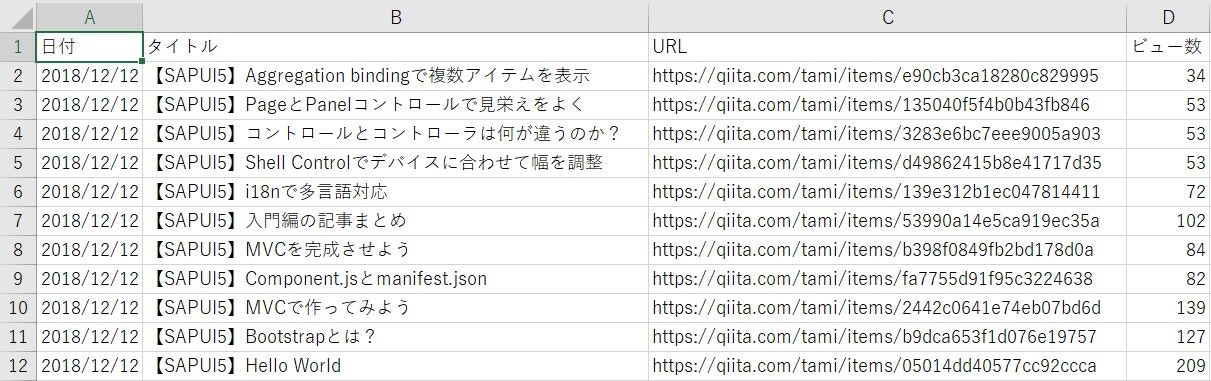
以下のフォーマットでCSVファイルに出力されます。なお、あらかじめヘッダだけのファイルを作成しておく必要があります。1日1回実行すると、その日のデータが追加されます。
感想
実行速度は人が操作するのとあまり変わりません。(ブラウザを実際にポチポチしているのですから…)まずは、素データを落とせるツールが簡単に作れたのでよかったです。記事ごとのビュー数の増え方など、観察できたら面白いと思います。