はじめに
HANA Cloudのテーブルデータをファイルに出力したい場合、一番簡単な方法は、Database Explorerでクエリを実行して結果をダウンロードすることでしょう。
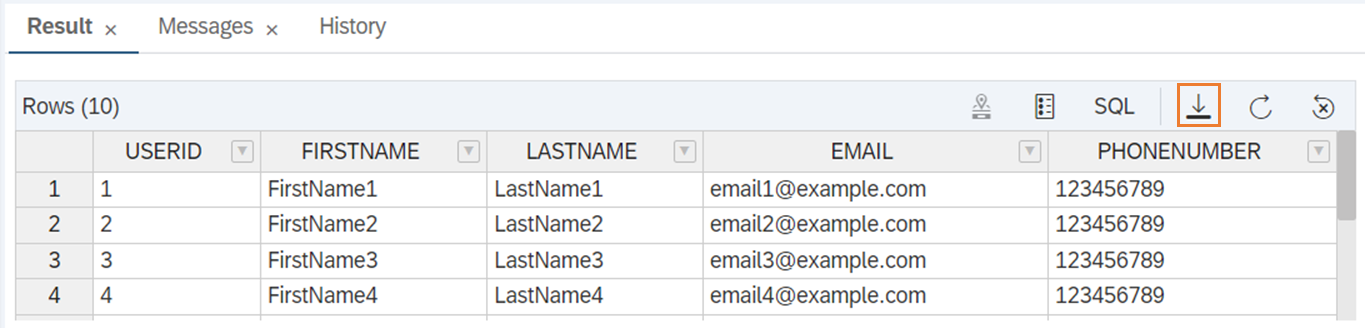
しかし、Database Explorerで抽出できるのはデフォルトで1000行までです。もっと大量のデータをダウンロードしたい場合はどうしたらよいでしょうか。この記事では、3つの方法を紹介します。
- Database Exlorerの設定で最大表示行数を変更する
- HANA Clientでローカルファイルに出力する
- Cloud Integrationで出力する
方法1:Database Exlorerの設定で最大表示行数を変更する
以下のKBAに記載の通り、Database Explorerの設定で最大表示行数を1000より大きくすることができます。
KBA 3131569 - How-To: Configure the maximum number of rows displayed in Result from HANA Database Explorer
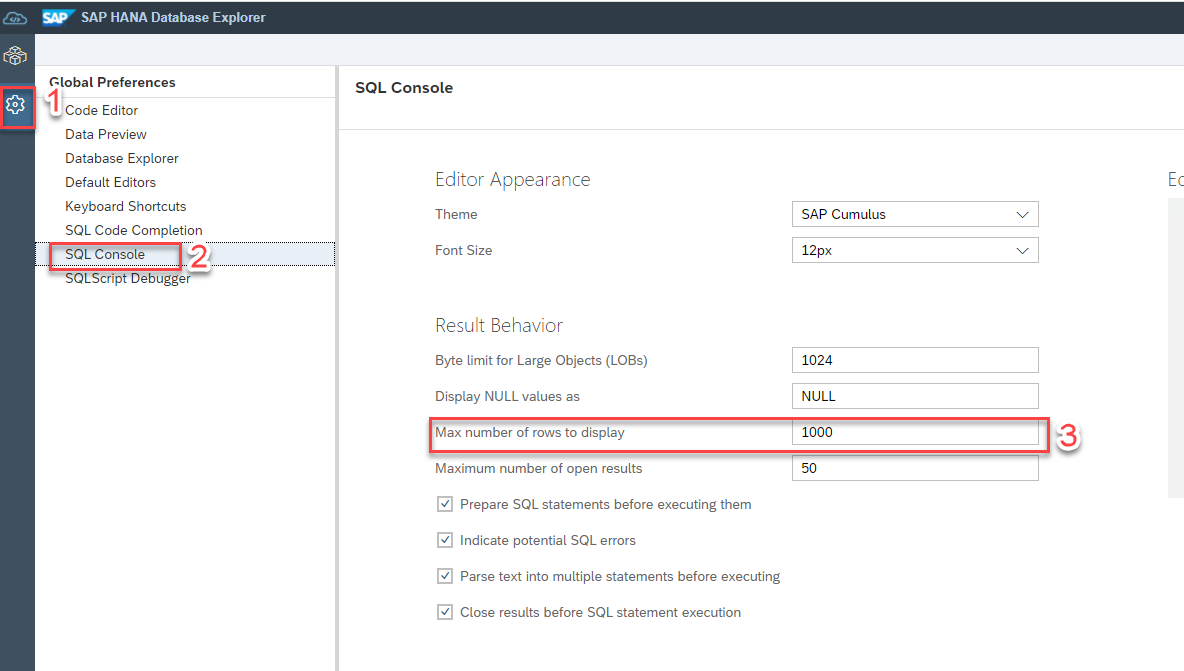
ただし、ここにも制限があります。上記KBAに「出力できる最大のサイズは16MB」とあります。
方法2:HANA Clientでローカルファイルに出力する
以下のKBAに、16MBを超えた場合の対応が記載されています。hdbsqlコマンドを使って出力する方法です。
2942727 - How-To: Export large select output to local file
hdbsql -n <DB host name>:<SQL port> -u <username> -p <password> -x "<your select query>" > /<path>/output_file.txt
hdbsqlコマンドを使用するにはHANA Clientをインストールする必要があります。インストール方法は以下のチュートリアルに記載されています。
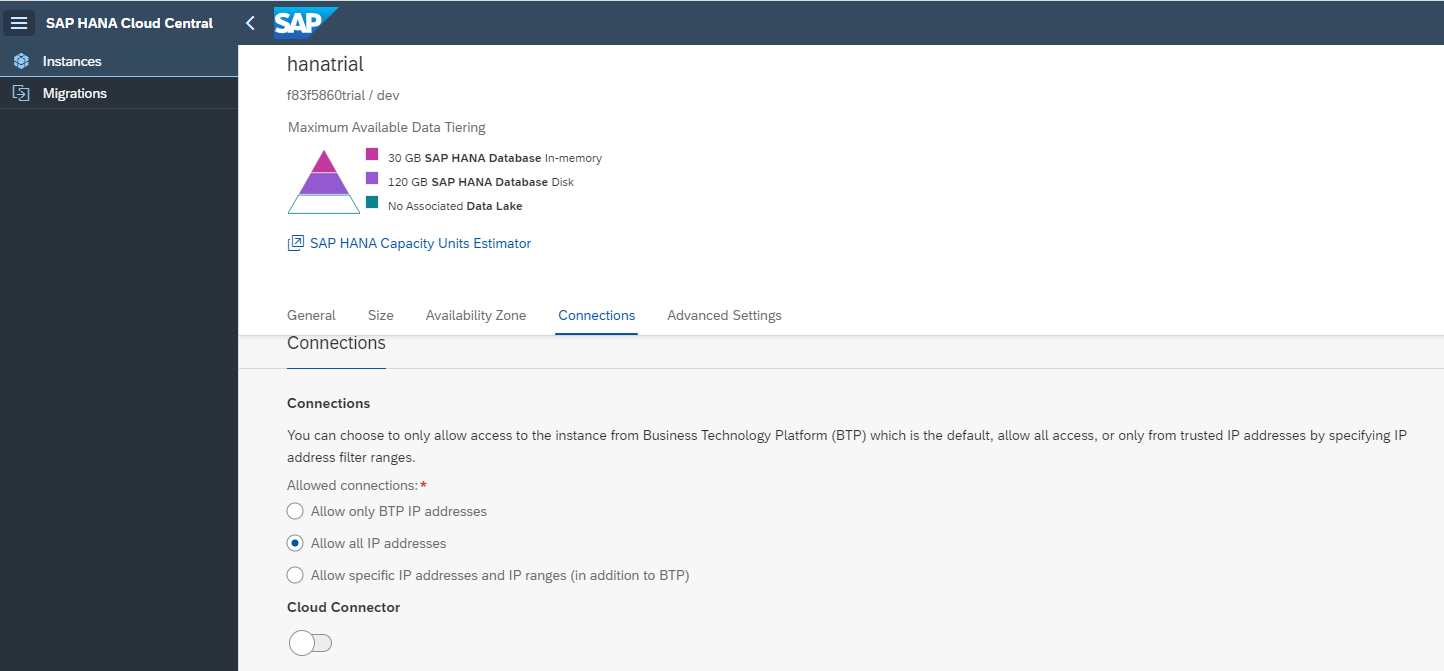
HANA Cloud側では、接続する端末のIPアドレスを許可しておく必要があります(今回はトライアル環境のため全てのIPアドレスを許可)。
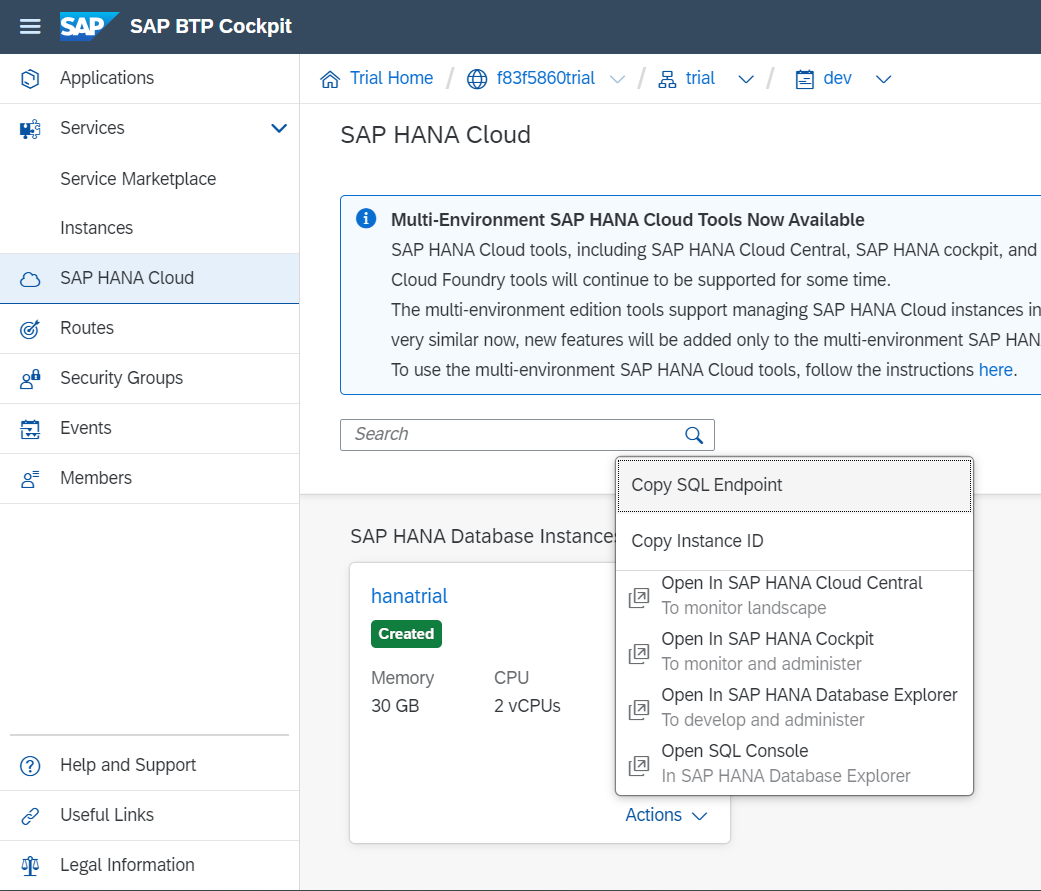
接続に必要な<DB host name>:<SQL port>の部分は、HANA Cloudのインスタンスのアクションから"Copy SQL Endpoint"でコピーできます。
コマンド例
hdbsql -n 118869d7-da16-4d93-b1e2-42bd39ed12da.hana.trial-us10.hanacloud.ondemand.com:443 -u user -p password -x "select * from ""MY_USERS"".""User""" > test\users.txt
約42万件のデータが30秒以内にダウンロードできました。

以下が取得したデータです。
USERID,FIRSTNAME,LASTNAME,EMAIL,PHONENUMBER
1,"FirstName1","LastName1","email1@example.com","123456789"
2,"FirstName2","LastName2","email2@example.com","123456789"
3,"FirstName3","LastName3","email3@example.com","123456789"
方法3: Cloud Integrationで出力する
SFTPサーバなどに定期的に出力したい場合は、Cloud Integrationを使うことができます。ただし、Cloud Integrationに大量データを持ち込むことになり、課金に影響しますのでご注意ください。
ステップ
- JDBC Materialを作成
- フローを作成
- 動作確認
3.1. JDBC Materialを作成
はじめにHANA Cloudへの接続を定義したJDBC Materialを作成しておきます。
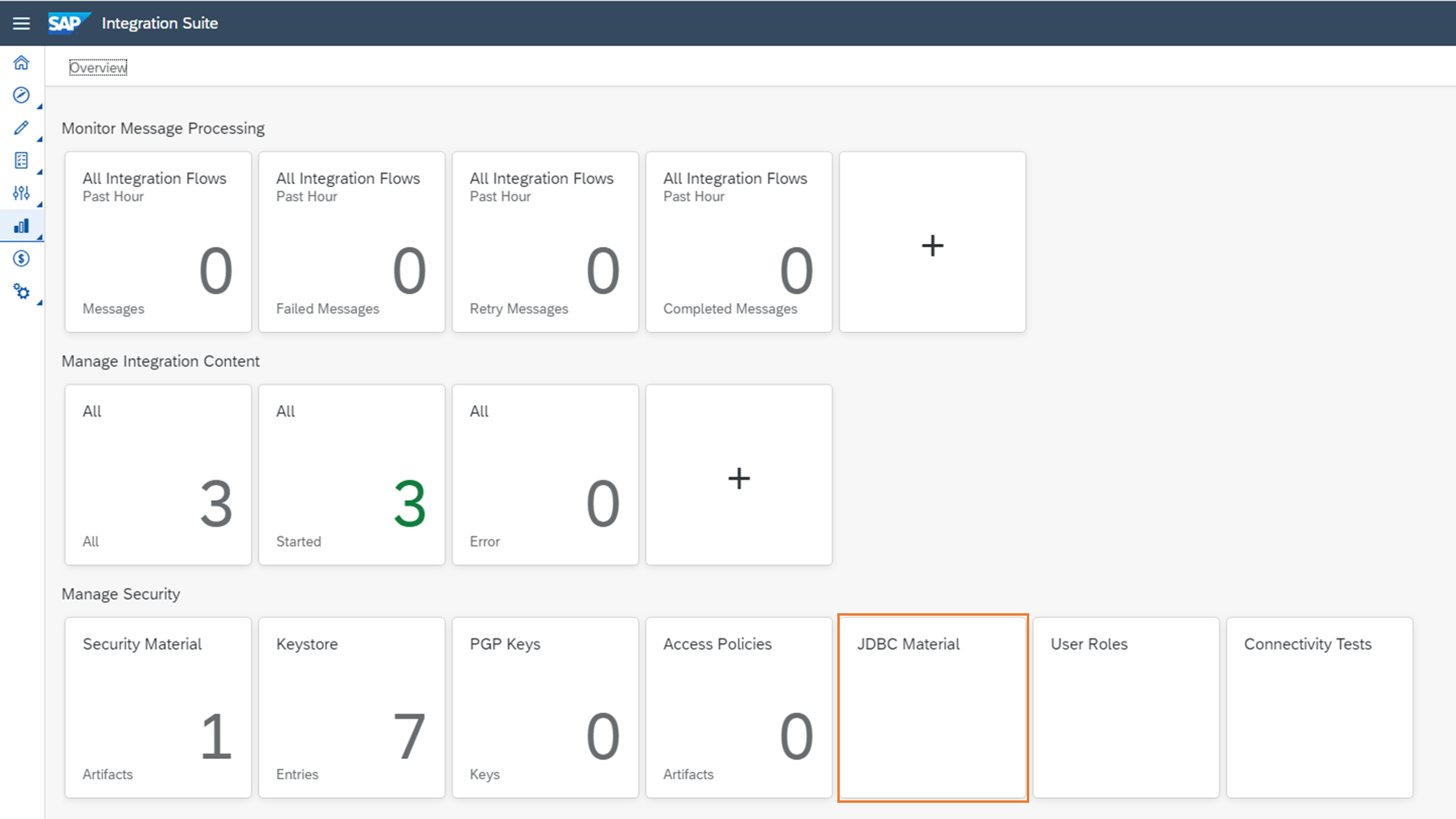
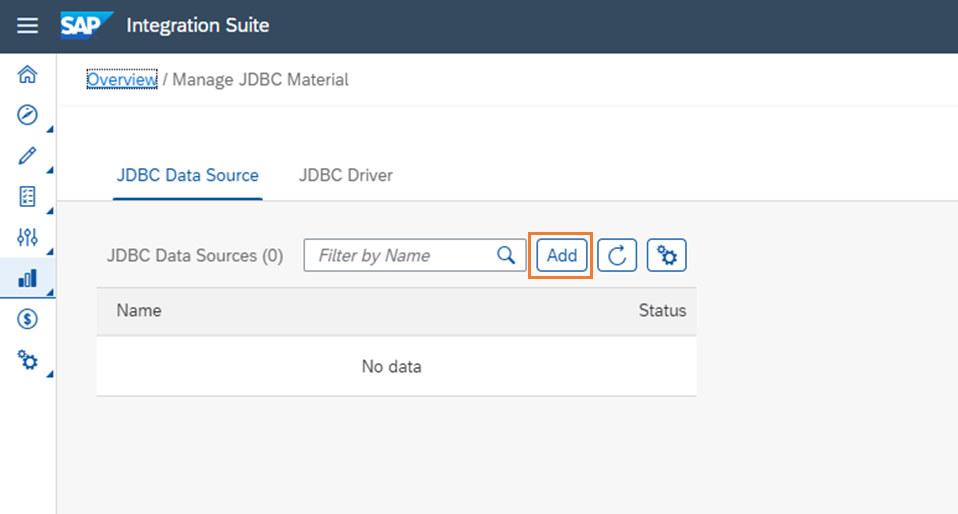
以下を設定します。
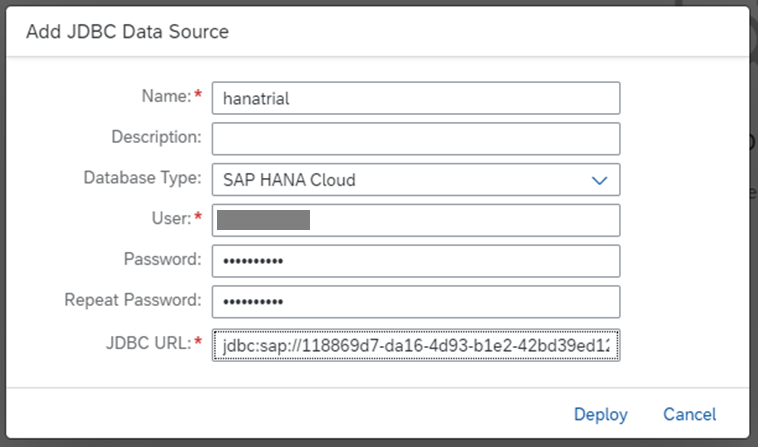
| 項目 | 設定値 |
|---|---|
| Name | 任意 |
| Database TYpe | SAP HANA Cloud |
| Database | データベースのユーザ |
| Password | 上記ユーザのパスワード |
| JDBC URL | jdbs:sap:// + <2.で確認したSQL Endpoint> |
JDBC URLの例:jdbc:sap://118869d7-da16-4d93-b1e2-42bd39ed12da.hana.trial-us10.hanacloud.ondemand.com:443
3.2. フローを作成
以下が作成したフローです。HANA Cloudに接続してテーブルデータ(約42万件)を全件取得し、ログに添付するという内容です。デプロイ時に一度だけ起動するようにタイマーを設定しています。
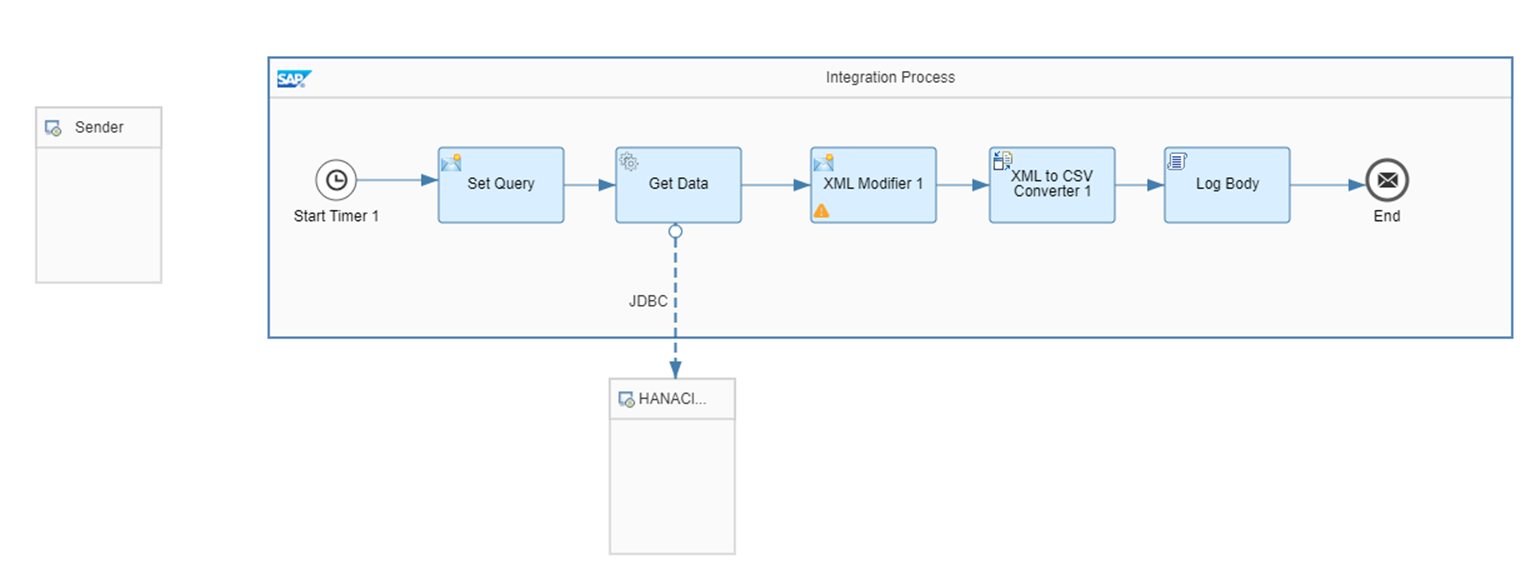
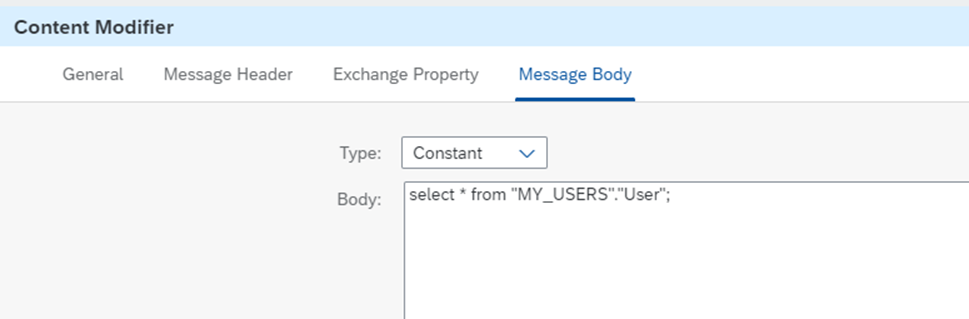
最初のステップでは、Content ModifierによりHANA Cloudに渡すクエリを設定します。SQLをそのまま書くことができます。(または、ヘルプにあるようにXMLで指定することも可能です)
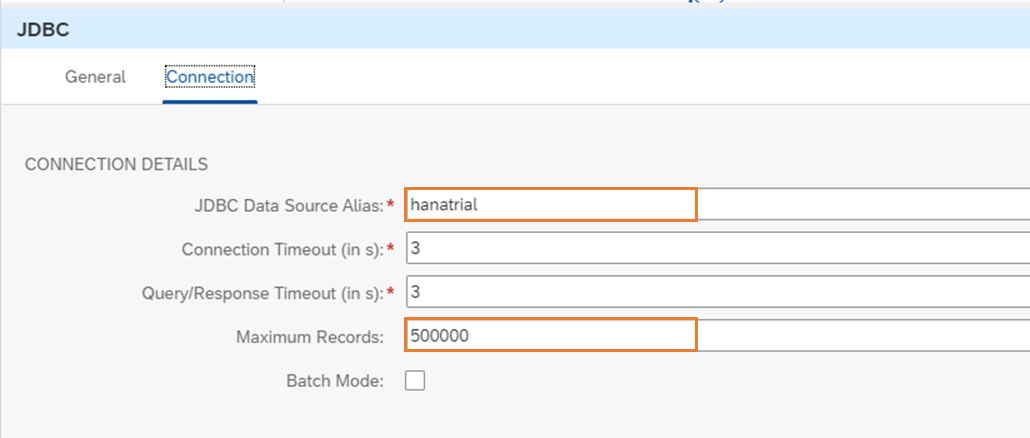
次のステップでは、JDBC Receiver AdapterによりHANA Cloudに接続してクエリを実行します。JDBC Data Source Aliasにあらかじめ作成しておいたJDBC Materialの名前を設定します。Maximum Recordsは想定される取得件数より大きくなるように設定します。
HANA Cloudからは以下のような形式でレスポンスが返ってきます。
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<ROOT>
<select_response>
<row>
<USERID>1</USERID>
<FIRSTNAME>FirstName1</FIRSTNAME>
<LASTNAME>LastName1</LASTNAME>
<EMAIL>email1@example.com</EMAIL>
<PHONENUMBER>123456789</PHONENUMBER>
</row>
<row>
<USERID>2</USERID>
<FIRSTNAME>FirstName2</FIRSTNAME>
<LASTNAME>LastName2</LASTNAME>
<EMAIL>email2@example.com</EMAIL>
<PHONENUMBER>123456789</PHONENUMBER>
</row>
</select_response>
</ROOT>
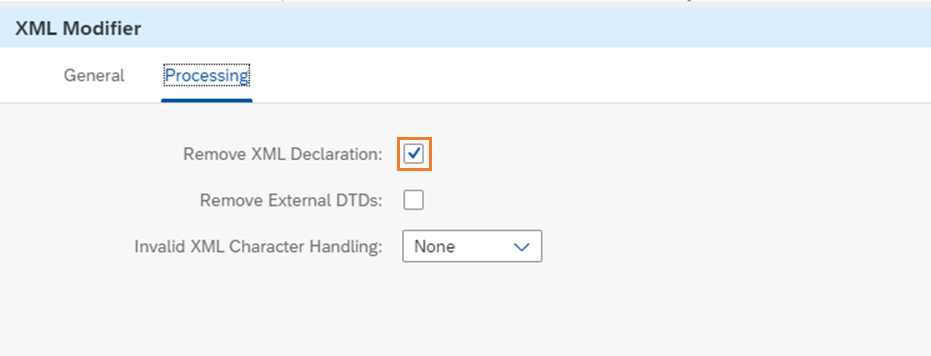
次のステップでは、XML Modifierでレスポンスの先頭のxmlタグを取り除きます。
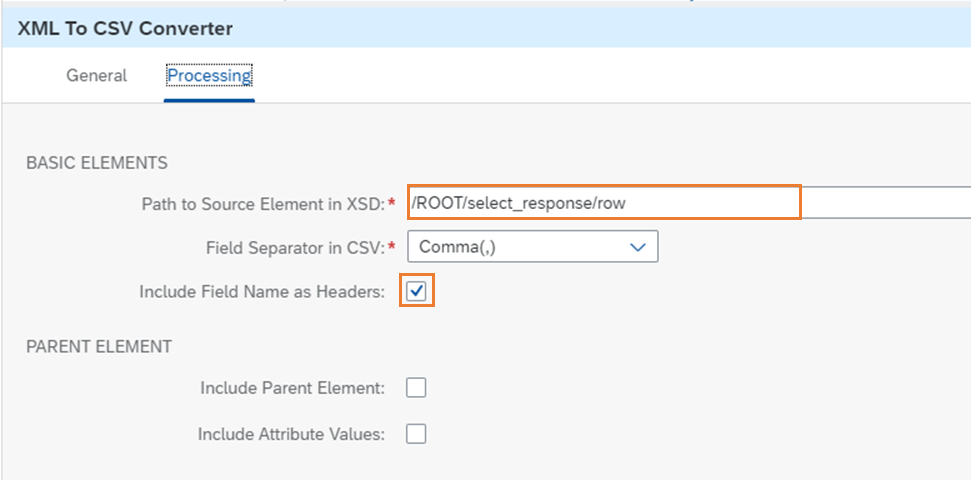
次のステップでは、XMLをCSVに変換します。Path to Source Element in XSDに/ROOT/select_response/rowを指定します。また、ヘッダ付きで出力したいのでInclude Field Name as Headersにチェックを付けます。
最後のステップで、Groovy ScriptによりCSVに変換したコンテンツをログに添付します。
import com.sap.gateway.ip.core.customdev.util.Message;
import java.util.HashMap;
def Message processData(Message message) {
def body = message.getBody(java.lang.String) as String;
def messageLog = messageLogFactory.getMessageLog(message);
if(messageLog != null){
messageLog.setStringProperty("Logging#1", "Printing Payload As Attachment")
messageLog.addAttachmentAsString("Retrieved Data:", body, "text/plain");
}
return message;
}
3.3. 動作確認
デプロイするとフローが動き、取得したデータが添付文書に保存されます。実行時間は11秒ほどでした。中で色々な処理を行っているにも関わらず、HANA Clientよりも高速でした。
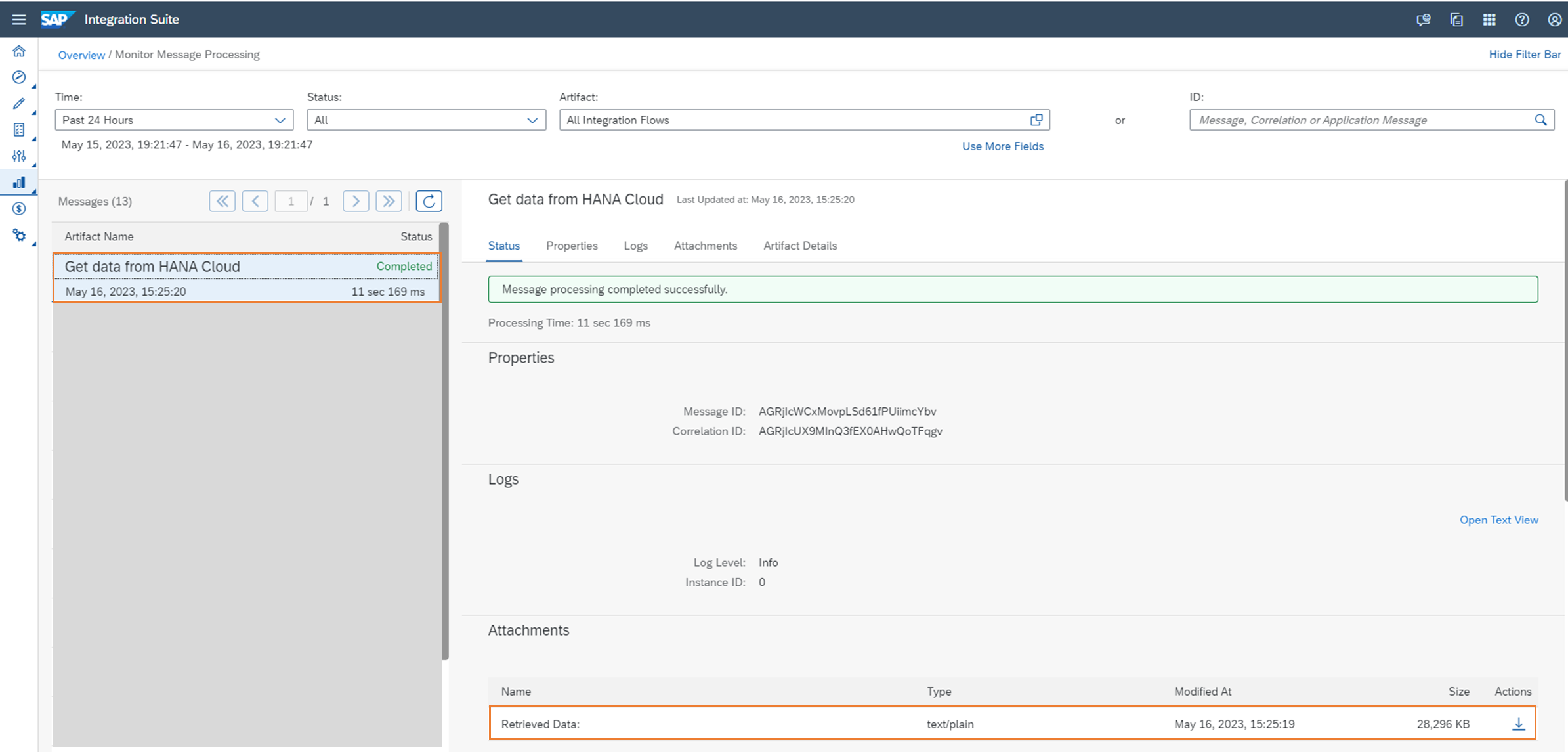
以下が取得したデータです。HANA Clientで取得したときは文字列がダブルクォートで囲まれていましたが、こちらは囲まれていません。
USERID,FIRSTNAME,LASTNAME,EMAIL,PHONENUMBER
1,FirstName1,LastName1,email1@example.com,123456789
2,FirstName2,LastName2,email2@example.com,123456789
3,FirstName3,LastName3,email3@example.com,123456789
4,FirstName4,LastName4,email4@example.com,123456789