はじめに
Cloud Integrationの機能に、ローカルのプロセスの中でODataサービスをページに分けて呼び、全レコードが終わるまで処理を繰り返すというものがあることを最近知りました。
ちょうど「ソースシステムからターゲットシステムへ、全レコードを連携したい」(ただし、レコードが大量なため分割して取得するなどの工夫が必要)という場面があったので、この機能を使えるか検証してみることにしました。
仕組み
上記の機能はLooping Process Callというコンポーネントによって提供されます。Looping Process Callは、指定した条件が満たされている間、ローカルプロセスを繰り返し実行します。
ODataサービスはGetリクエストが来たときに、そのサービスで決められた最大の件数だけを返すようになっているものがあります。たとえばCAPの場合、デフォルトの最大取得件数は1000件です。
試しにCAPのODataサービスに件数を指定せずにリクエストすると、レスポンスの最後に@odata.nextLinkというプロパティが返ってきます。これは「続きのデータをリクエストしたい場合はクエリにこれを指定してください」という意味です。
"@odata.nextLink": "Stock?$skiptoken=1000"
Cloud Integrationでは、ODataリクエストの後にプロパティの有無によって後続データがあるかどうかを判断し、後続がある場合はExchange Propertyの<Recieverチャネル名>.OData.hasMoreRecordsにtrueを自動的に設定します。以下はフローをトレースした結果で、Exchange PropertyにOData.hasMoreRecordsが設定されています。
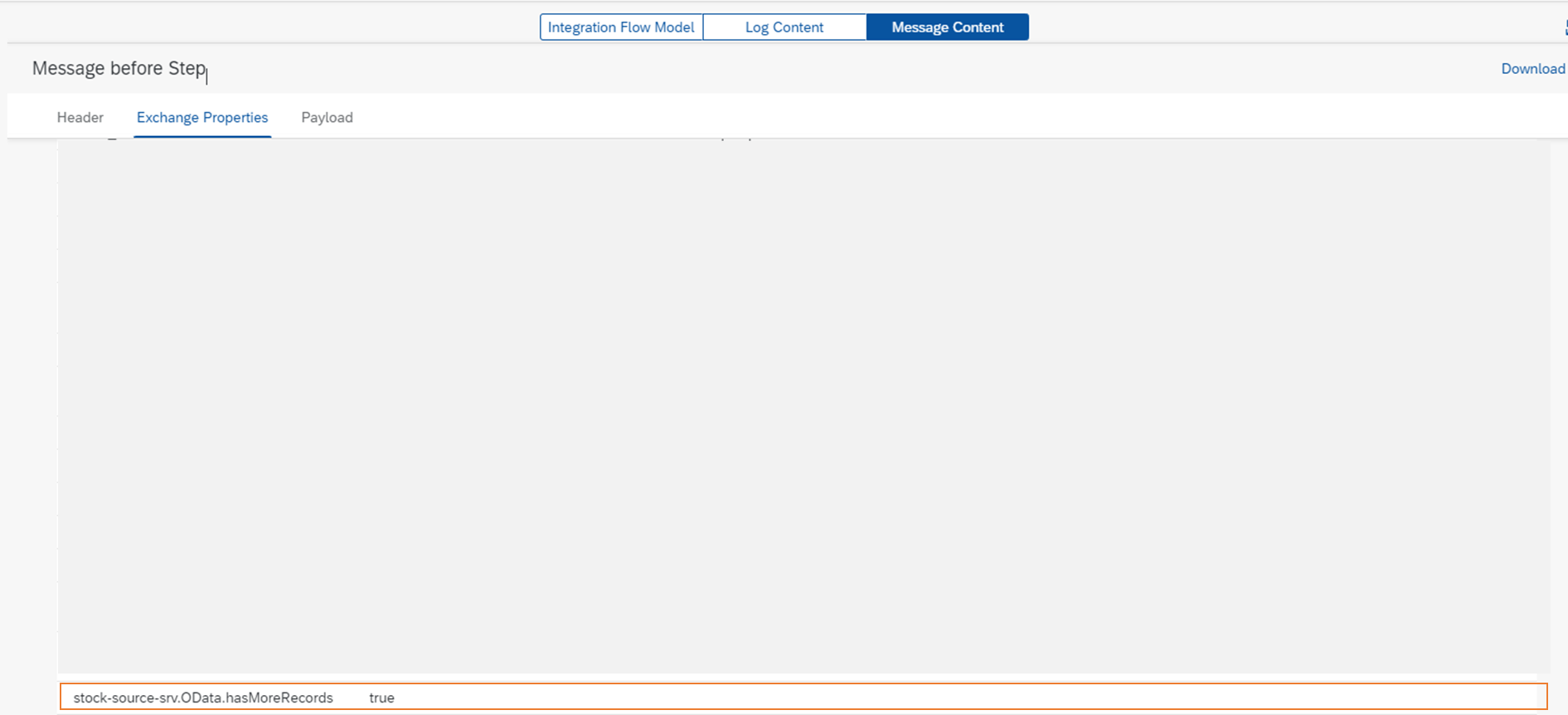
つまり、ローカルプロセスを繰り返し実行するかどうかの判定はCloud Integrationが自動的に行ってくれるので開発者が意識しなくてよいということです。
シナリオ
在庫データをソースシステムからターゲットシステムへ、全件同期する仕組みを作ります。ソース、ターゲットそれぞれにODataサービスがあり、取得と登録を行うことができます。
※SDIなどを使ってテーブル連携ができればよいのですが、それができない制約があります。

在庫データは1万件あり、ODataで一度に取得したり、一度のバッチリクエストで登録することはできません。そこでCloud Integrationにより、①ソースからデータを分割して取得し、②ターゲットが受け取ることができるサイズに分割して登録を行います。
今回ソースのODataサービスはCAP (Cloud Foundry)、ターゲットはRAP (BTP ABAP Environment)で作成しています。サービスの作成についての説明は省略しますが、ソースはGitリポジトリに格納しています。
ソース:https://github.com/miyasuta/stock-source
ターゲット:https://github.com/miyasuta/stock-target
作成したフロー
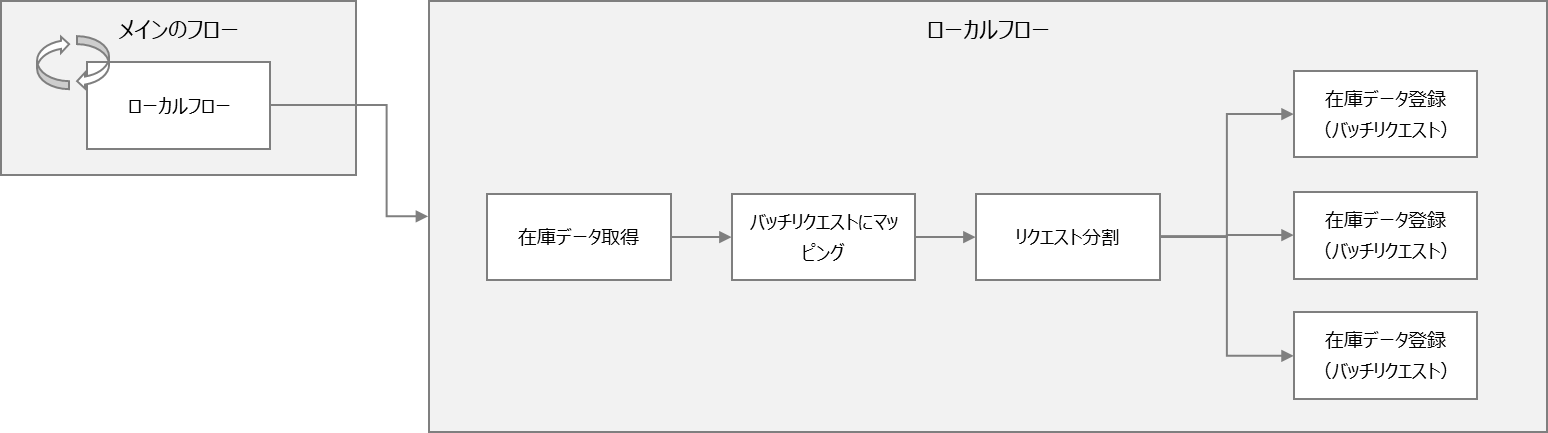
作成したフローはメインのフローと2つのローカルプロセスから構成されます。
メインのフロー
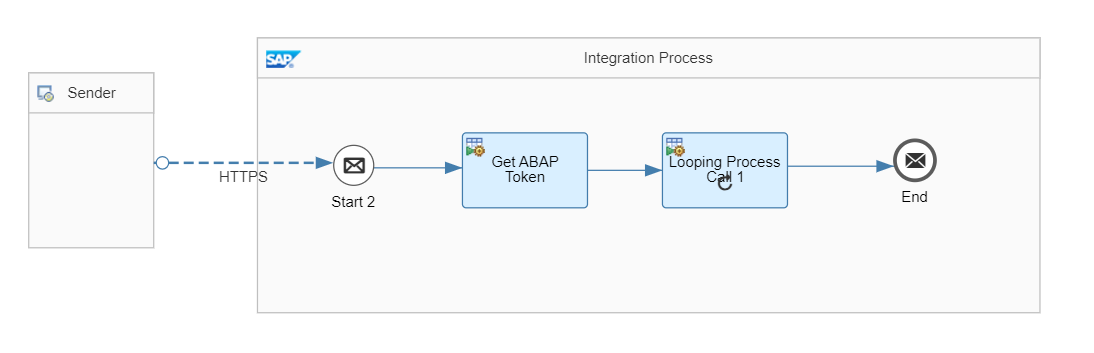
ローカルプロセス1
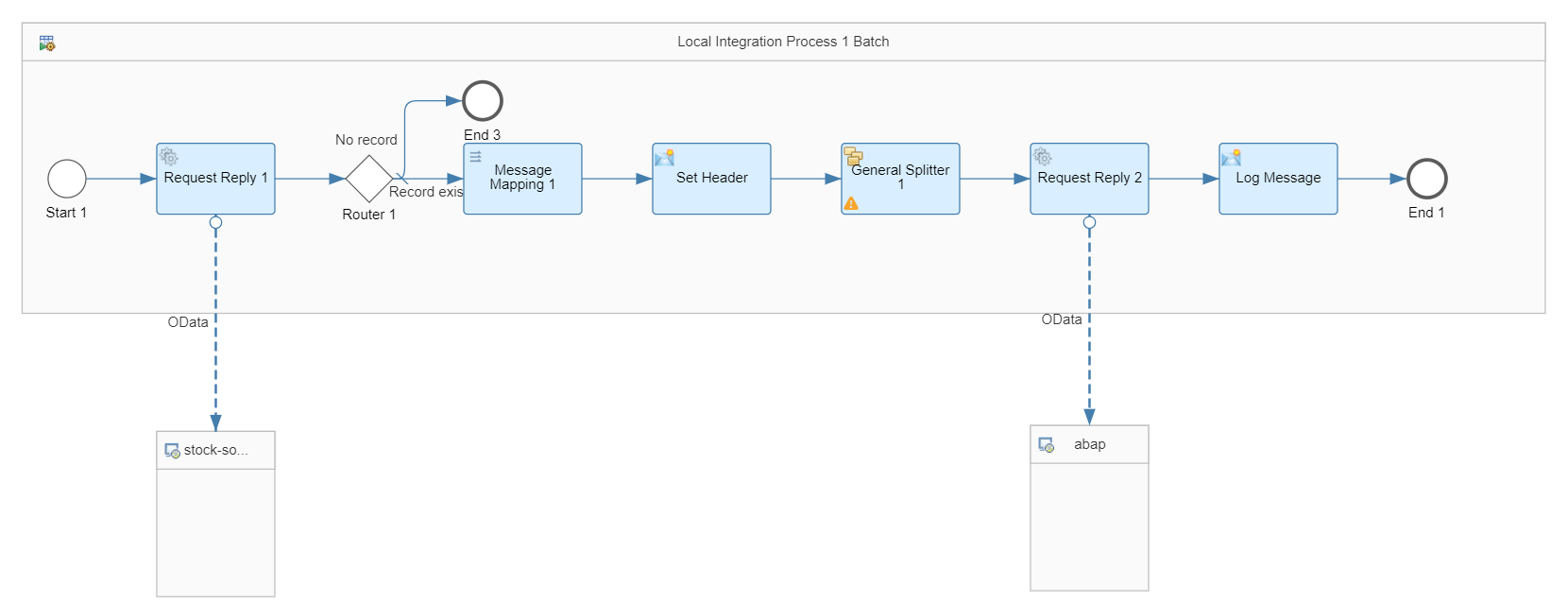
ローカルプロセス2
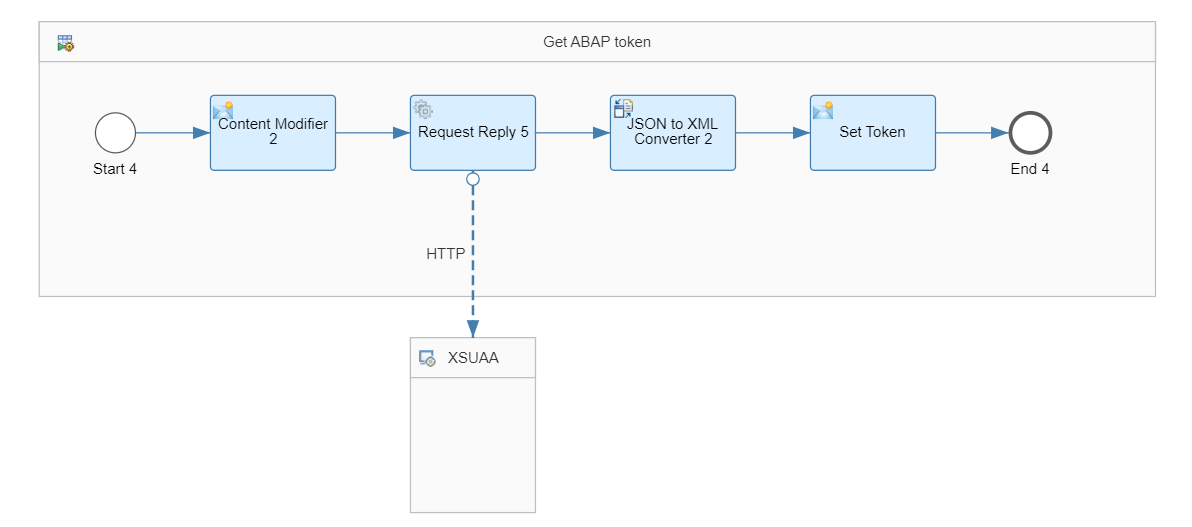
このうちローカルプロセス1はBTP ABAP Environmentの認証用のトークンを取得する処理で、処理内容については以下のブログで説明しています。
以下では、メインのフローとローカルプロセス2について見ていきます。
メインのフロー
メインのフローはHTTPSで起動し、はじめにローカルプロセス1を呼び出してBTP ABAP Environmentのトークンを取得します。取得したトークンはExchange Propertyに設定されます。次に、ローカルプロセス2を繰り返し呼び出します。
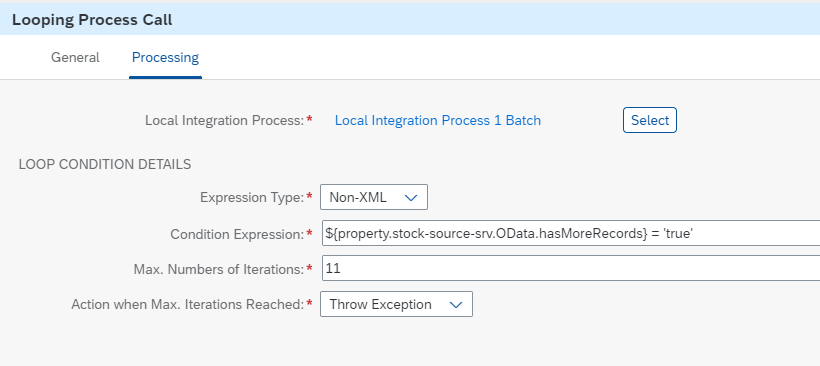
Looping Process Callの設定は以下のようになっています。
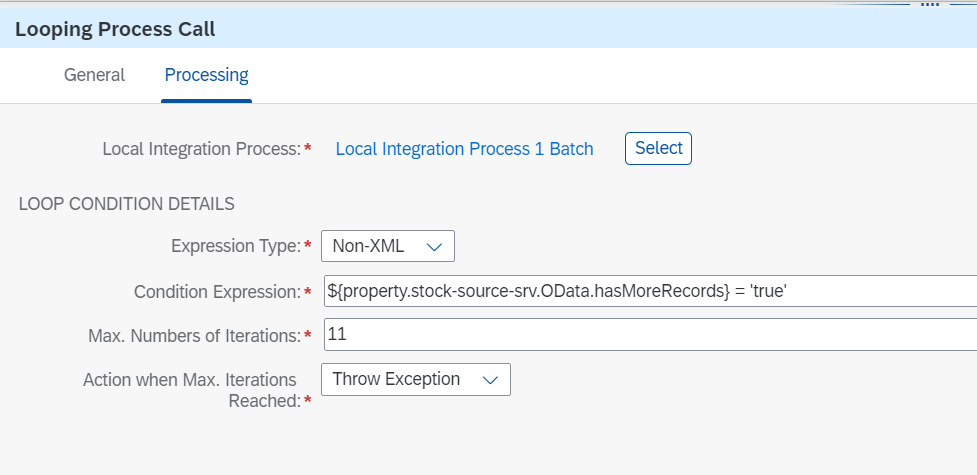
| 項目 | 設定値 |
|---|---|
| Local Integration Process | 呼び出すローカルプロセスを指定 |
| Expression Type | Non-XML |
| Condition Expression | ${property.<ODataのレシーバチャネル名>.OData.hasMoreRecords} = 'true' |
| Max. Numbers of Iterations | 想定される最大の繰り返し数を指定 |
ODataのレシーバチャネル名は、Request Replyの先にあるRecieverの名前(ここではstock-source-srv)です。
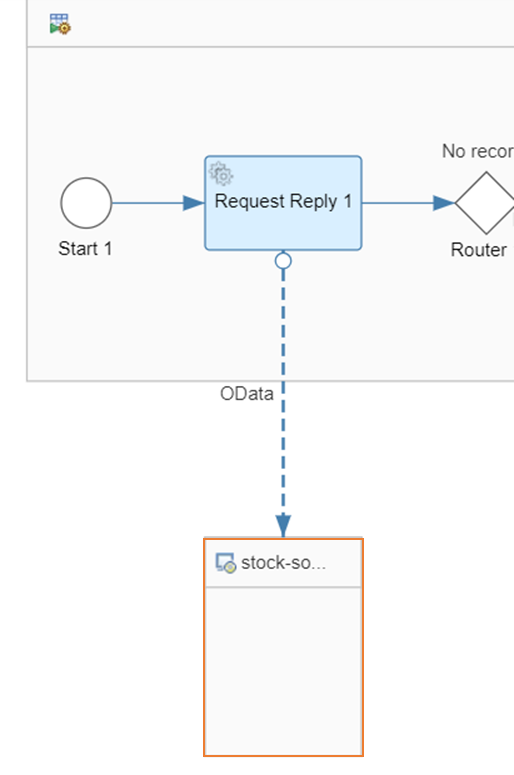
ローカルプロセス2
ローカルプロセス2はメインのフローから繰り返し呼ばれる処理です。このプロセスでは、ソースシステムから在庫データを取得し、ターゲットシステムに登録します。
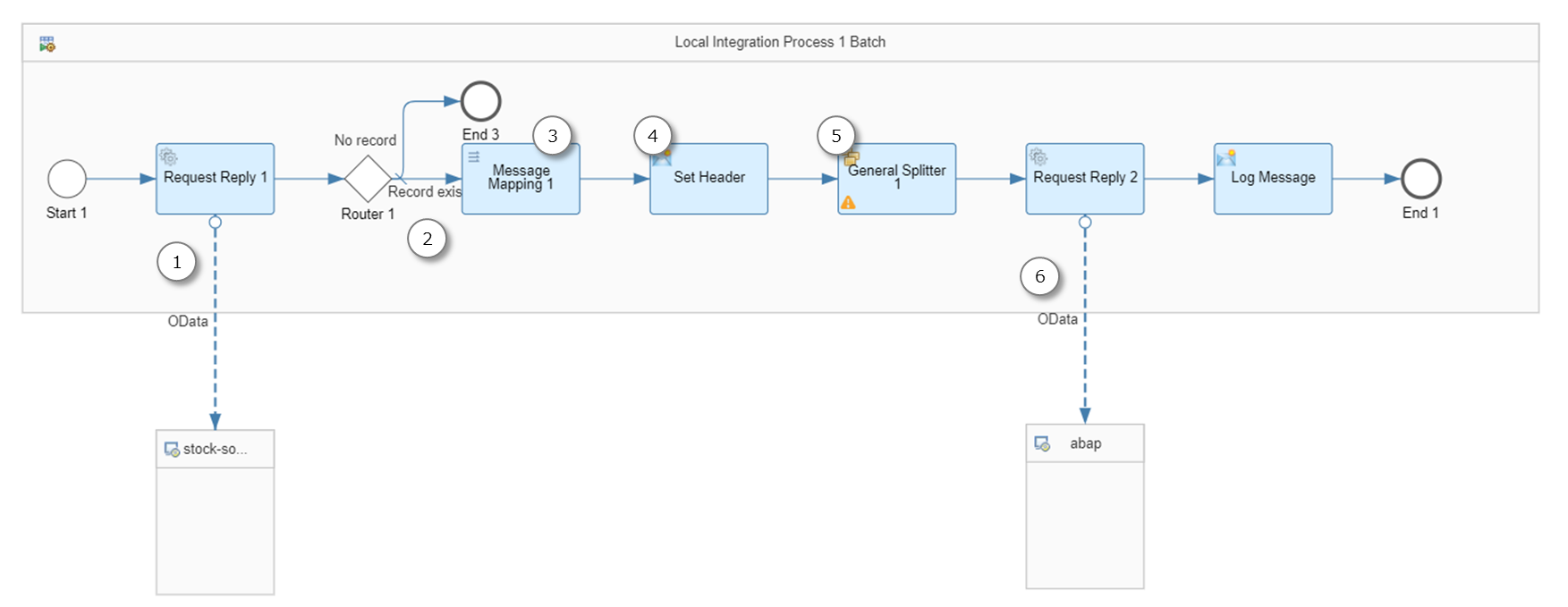
①OData V4 Receiver Adapter
ソースシステムに接続して在庫データを取得します。
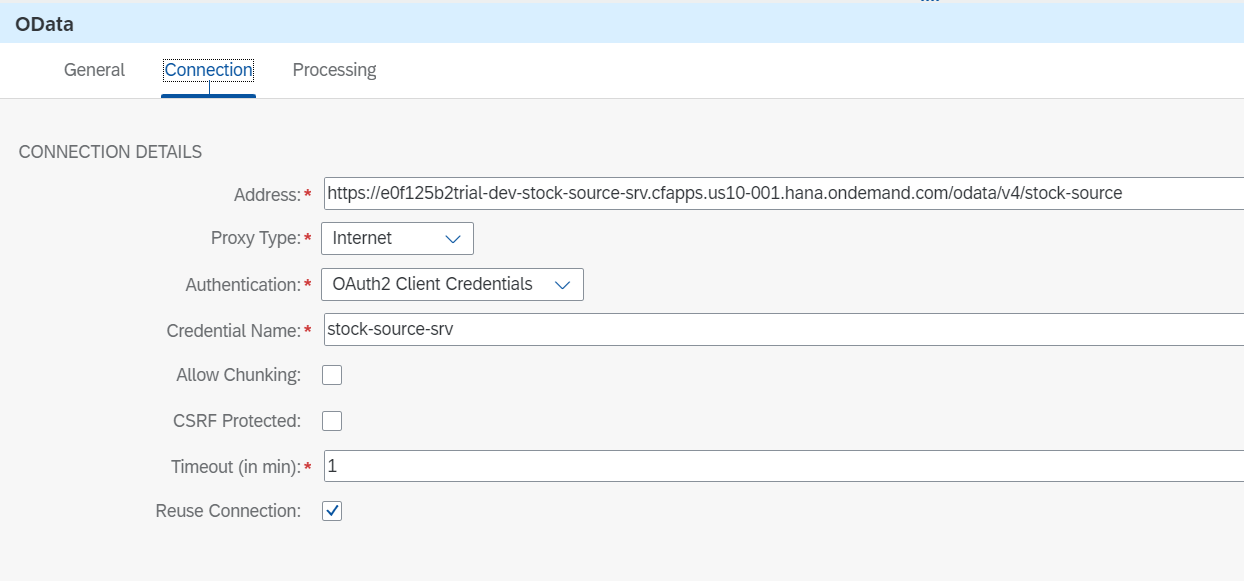
Looping Process Callと連携して繰り返し処理を行うため、Process in Pagesにチェックをつけるのがポイントです。
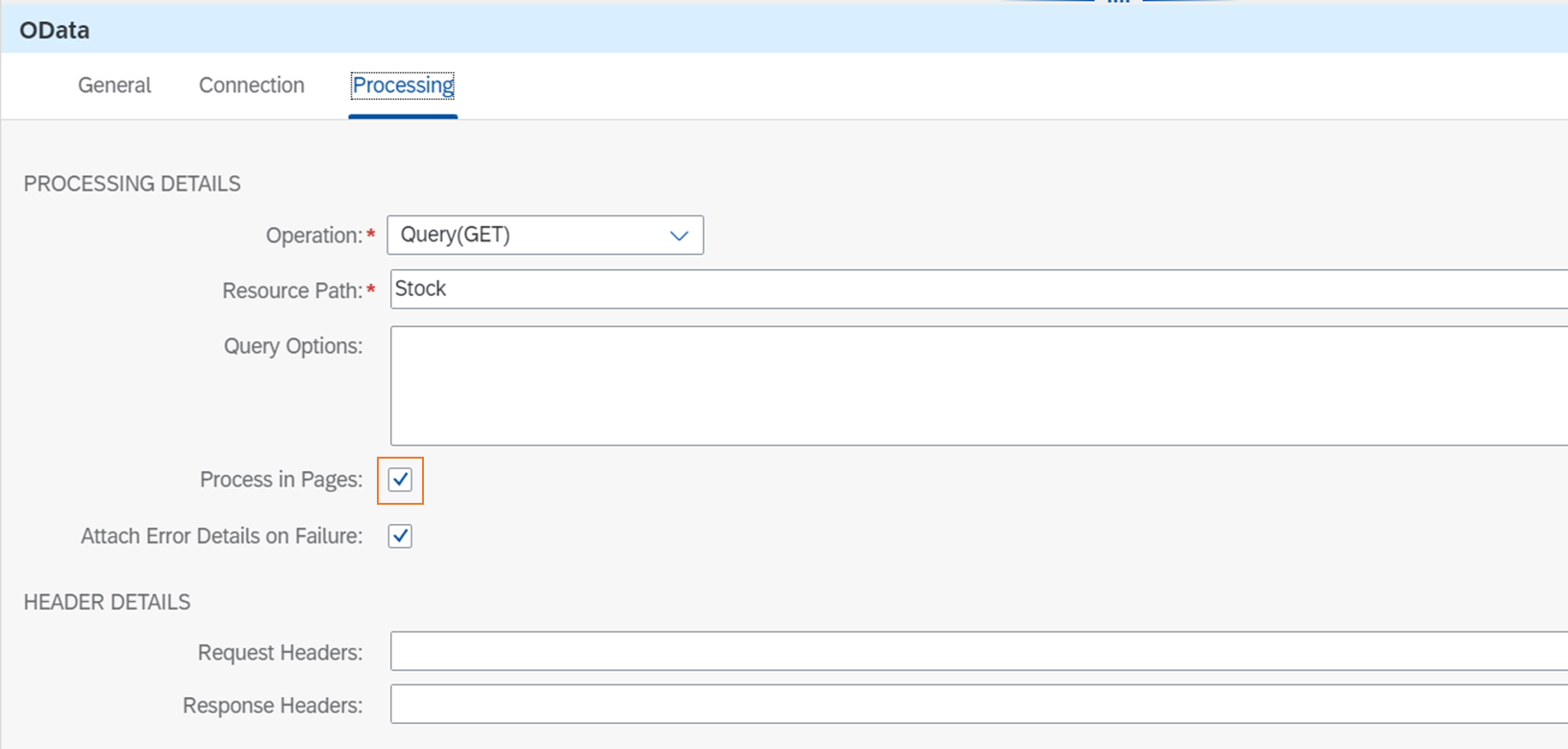
参考:Configure the OData V4 Receiver Adapter | Help Portal
By selecting Process in Pages, you enable the adapter to process messages in pages, the page size of which is defined in the server-side system. To use Process in Pages, you must use the adapter in a Local Integration Process that is invoked by a Looping Process Call step.
②Router
ページごとにデータを取得していると、最後のリクエストの結果が0件になることがあります。これをそのまま後続のマッピング処理に流すとエラーになるので、結果が0件の場合は処理を終了させます。このため、Routerでは"/Stock/Stock"というプロパティが存在するかどうかをチェックしています。
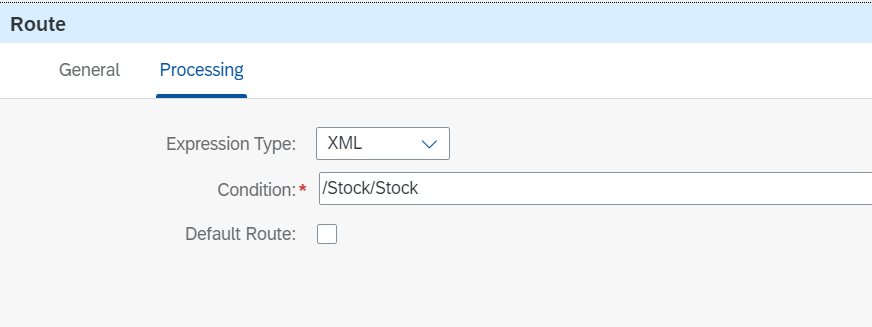
0件のときのペイロード:/Stock/Stockが存在しない
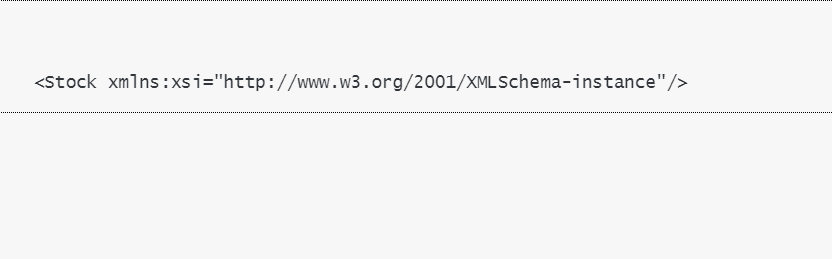
0件でないときのペイロード:/Stock/Stockが存在する
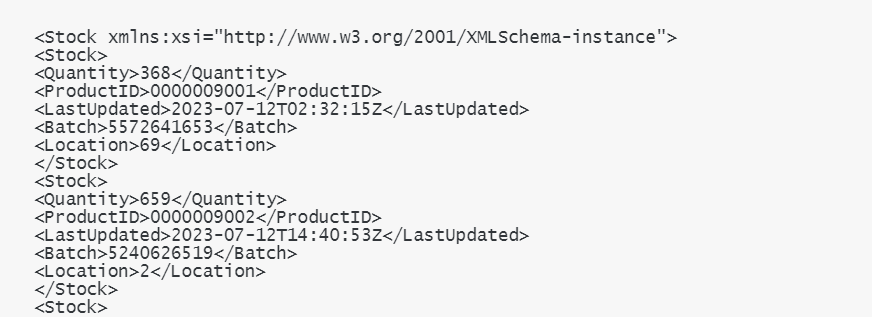
③Message Mapping
ここでは、取得したデータをOData V2のバッチリクエストの構造にマッピングします。
※マッピング先のXMLスキーマの取得方法は以下のブログに記載しています。
④Content Modifier
ここでは、BTP ABAP EnvironmentのODataサービスを呼ぶためのAuthorizationヘッダを設定します。トークンはメインのフローで取得しExchange Propertyに持っていたものを設定します。

⑤General Splitter
①では1000件単位にデータが取得されます(※)が、1000件を同時にターゲットシステムに登録しようとすると時間がかかります。そこでデータをさらに分割してバッチリクエストするために、General Splitterを使用します。
※登録する単位はサービスにより変わります
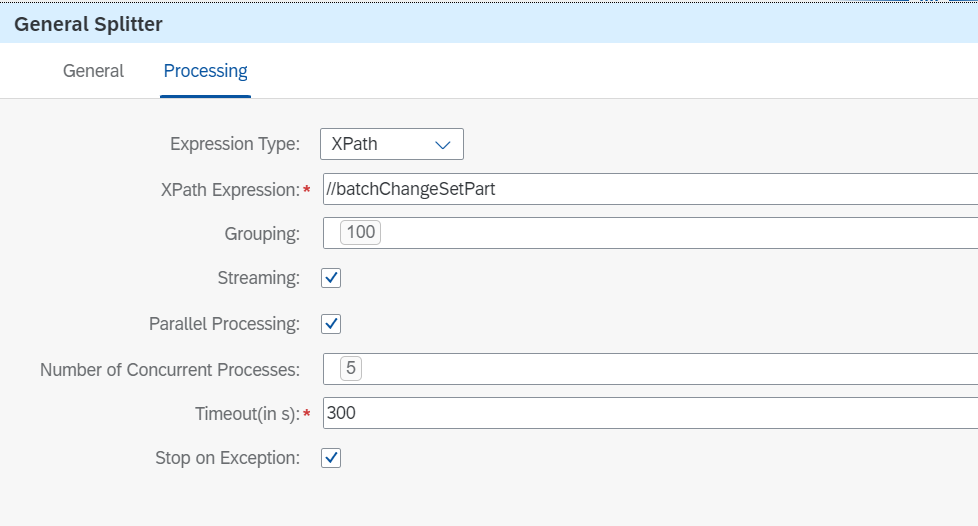
General Splitterでは、インプットデータがXPath Expressionで指定したノードで分割され、複数のパートに分かれます。イメージとしては以下のようなインプットを、
<?xml version="1.0" encoding="UTF-8"?>
<batchParts>
<batchChangeSet>
<batchChangeSetPart>
<method>POST</method>
<Stock>
<StockType>
<Productid>0000009001</Productid>
<Batch>5572641653</Batch>
<Location>69</Location>
<Quantity>368</Quantity>
<SourceLastChanged>2023-07-12T02:32:15Z</SourceLastChanged>
</StockType>
</Stock>
</batchChangeSetPart>
</batchChangeSet>
<batchChangeSet>
<batchChangeSetPart>
<method>POST</method>
<Stock>
<StockType>
<Productid>0000009002</Productid>
<Batch>5240626519</Batch>
<Location>2</Location>
<Quantity>659</Quantity>
<SourceLastChanged>2023-07-12T14:40:53Z</SourceLastChanged>
</StockType>
</Stock>
</batchChangeSetPart>
</batchChangeSet>
</batchParts>
以下のようにbatchChangeSetで切り出して複数のパートに分けます。
<?xml version="1.0" encoding="UTF-8"?>
<batchParts>
<batchChangeSet>
<batchChangeSetPart>
<method>POST</method>
<Stock>
<StockType>
<Productid>0000009001</Productid>
<Batch>5572641653</Batch>
<Location>69</Location>
<Quantity>368</Quantity>
<SourceLastChanged>2023-07-12T02:32:15Z</SourceLastChanged>
</StockType>
</Stock>
</batchChangeSetPart>
</batchChangeSet>
</batchParts>
<?xml version="1.0" encoding="UTF-8"?>
<batchParts>
<batchChangeSet>
<batchChangeSetPart>
<method>POST</method>
<Stock>
<StockType>
<Productid>0000009002</Productid>
<Batch>5240626519</Batch>
<Location>2</Location>
<Quantity>659</Quantity>
<SourceLastChanged>2023-07-12T14:40:53Z</SourceLastChanged>
</StockType>
</Stock>
</batchChangeSetPart>
</batchChangeSet>
</batchParts>
この際、Groupingによって1つのパートに含まれるレコードの数を、Number of Concurrent Processesによって、General Splitterの後の処理を何並列で実行するかを指定できます。
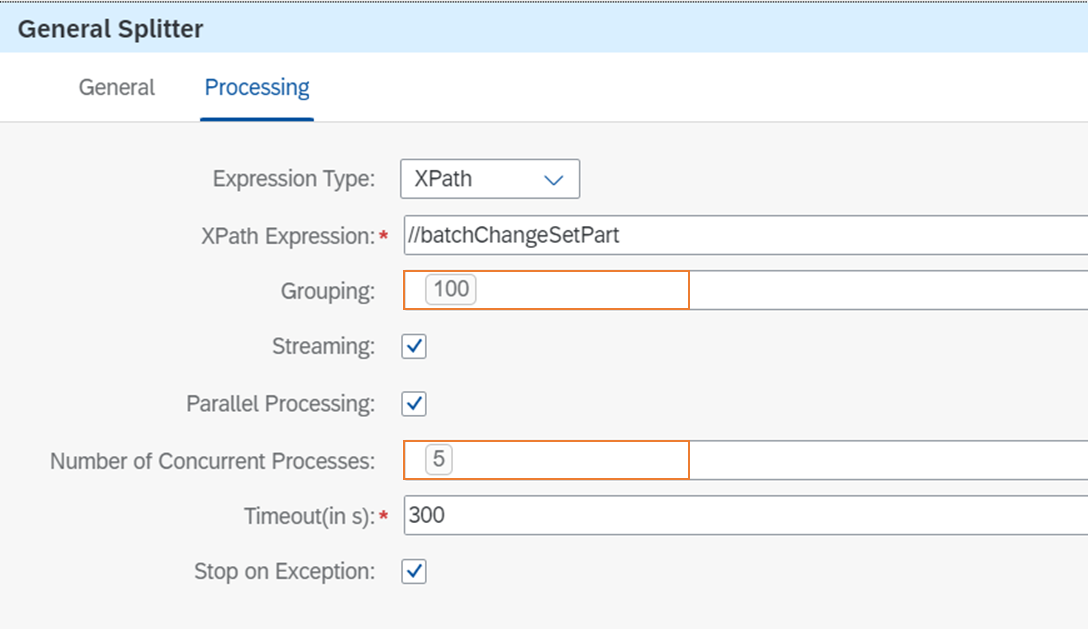
上記の例では1000個のデータを100個ずつに分け、5並列でバッチリクエストを投げます。
⑥OData V2 Receiver Adapter
BTP ABAP EnvironmentのODataサービスを呼んで在庫データを登録します。この環境ではCSRFトークンチェックが行われるので、CSRF Protectedにtrueを設定します。
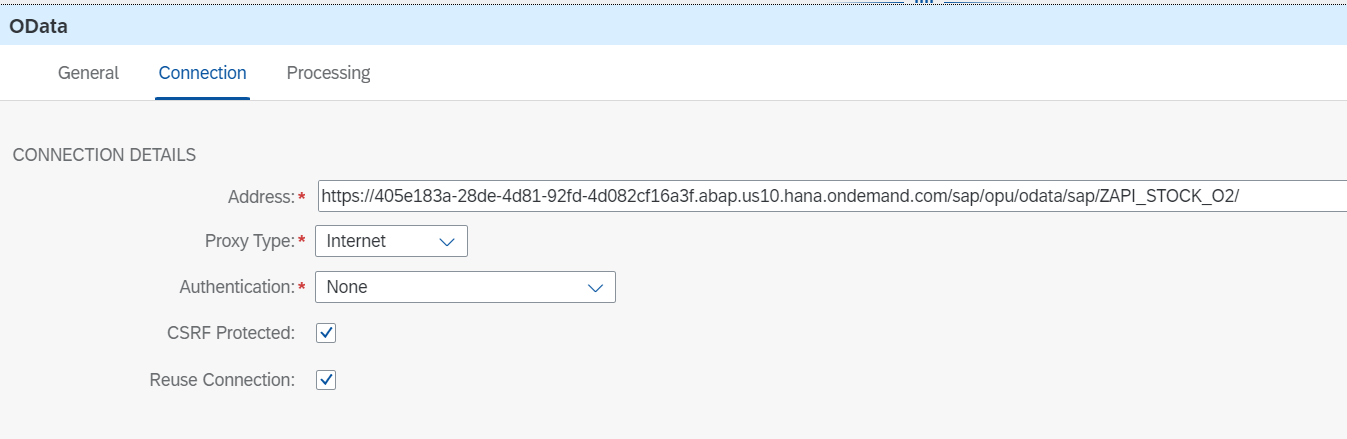
Processingタブでは、Enable Bath Processingにチェックを入れます。
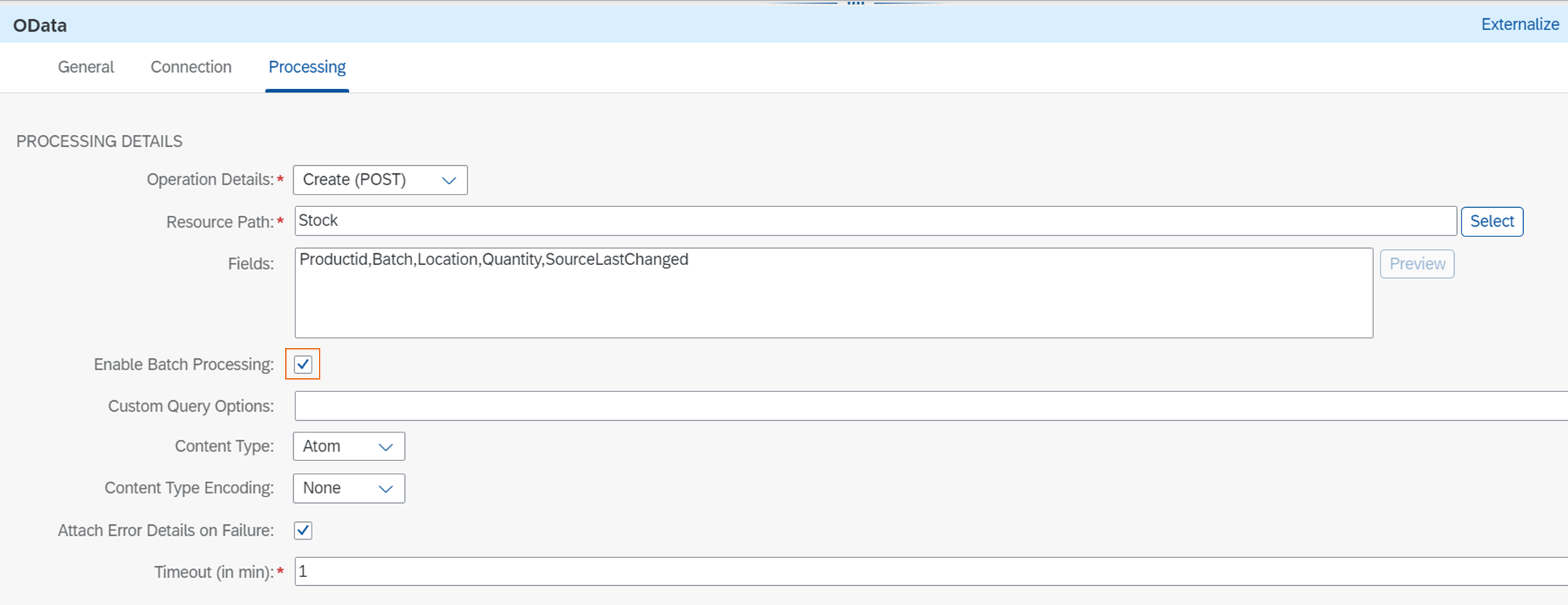
ヘッダには、ステップ④で設定したAuthorizationを設定します。

※OData V2のAdapterを使っているのは、V4では任意の数のバッチリクエストに任意の数のリクエストを入れることができないためです。詳しくは以下のブログに書いています。
動作確認
Postmanからフローを起動すると、以下のように結果が返ってきます。レスポンスボディには、最後のローカルプロセスのペイロードの内容が設定されています。本来はメインのフローで呼び出し元に返したい内容を設定する必要があります。
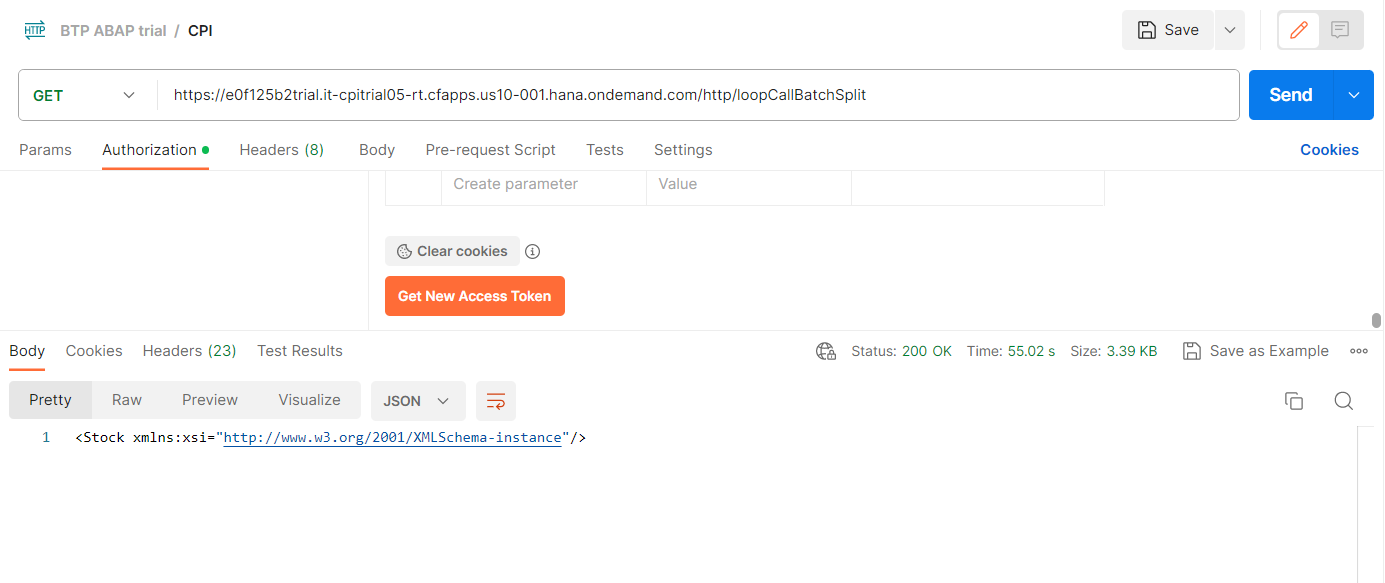
1万件を連携するのにかかった時間は1分弱でした。なお、General Splitterを使わずに1000件を同時に登録した場合は1回の登録に30秒ほどかかりました(10000件では単純計算で5分)。100件ずつ5パラにした場合は1000の登録が7秒ほどで終了しました。
バッチリクエストのエラーハンドリングについて
今回作成したフローではバッチリクエストのエラーハンドリングは行っていませんが、本来はやるべきです。バッチリクエストの場合、個別のリクエストがエラーになっても呼び出し自体は正常終了するので、フロー全体は正常終了になります。エラーハンドリングをする場合、バッチレスポンスの中のステータスコードを見てエラーの有無を判断する必要があります。
<batchPartResponse>
<batchChangeSetResponse>
<batchChangeSetPartResponse>
<headers>
<Accept></Accept>
<Accept-Language></Accept-Language>
<Content-Length>1364</Content-Length>
<dataserviceversion>1.0</dataserviceversion>
<Content-Type>application/xml;charset=utf-8</Content-Type>
</headers>
<statusInfo>Bad Request</statusInfo>
<contentId/>
<body><?xml version="1.0" encoding="utf-8"?><error xmlns="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata"><code>MC_CSP_USR_RUNTIME/006</code><message xml:lang="en">The key value is already in use. Please enter a different one.</message><innererror><application><component_id>BC-ESI-ESF-GW</component_id><service_namespace>/SAP/</service_namespace><service_id>ZAPI_STOCK_O2</service_id><service_version>0001</service_version></application><transactionid>de8c151fb1874ba1903f446cda69fcf6</transactionid><timestamp>20230712211001.3201380</timestamp><Error_Resolution><SAP_Transaction>For backend administrators: use ADT feed reader "SAP Gateway Error Log" or run transaction /IWFND/ERROR_LOG on SAP Gateway hub system and search for entries with the timestamp above for more details</SAP_Transaction><SAP_Note>See SAP Note 1797736 for error analysis (https://service.sap.com/sap/support/notes/1797736)</SAP_Note><Batch_SAP_Note>See SAP Note 1869434 for details about working with $batch (https://service.sap.com/sap/support/notes/1869434)</Batch_SAP_Note></Error_Resolution><errordetails><errordetail><ContentID/><code>MC_CSP_USR_RUNTIME/006</code><message>The key value is already in use. Please enter a different one.</message><propertyref/><severity>error</severity><target/><transition>true</transition></errordetail></errordetails></innererror></error></body>
<statusCode>400</statusCode>
</batchChangeSetPartResponse>
</batchChangeSetResponse>
注意点
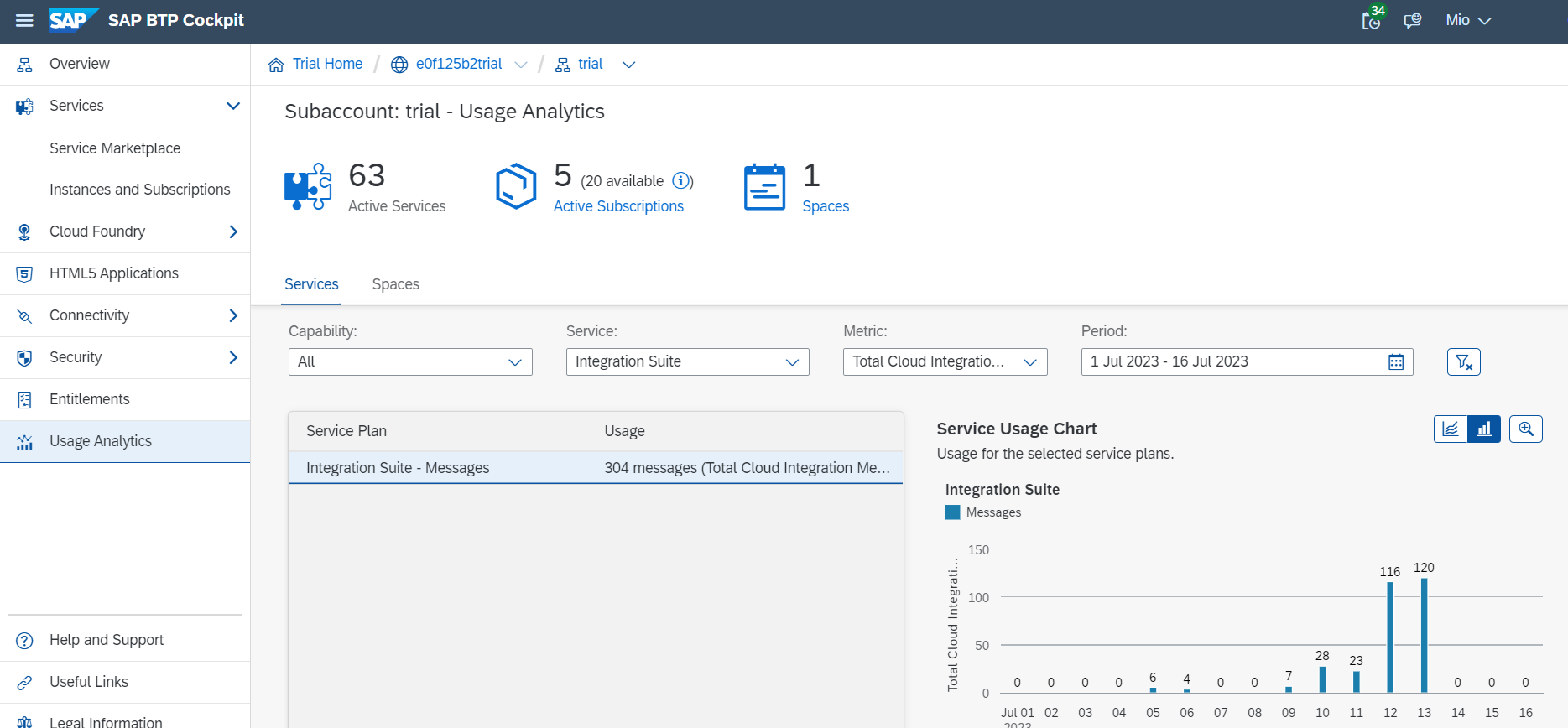
大量データを連携することでIntegration Suiteで処理されるメッセージサイズが大きくなり、課金額が膨らむ可能性があります。Cloud Integrationでは250KBごとに1メッセージとカウントされ、メッセージの数によって課金額が決まります(参考:Discovery Center)
実際にこの方法を採用するかどうかは、メッセージサイズや連携頻度を確認し、許容範囲かどうかを見極めて決定する必要があります。
※1つのフローで処理されたメッセージサイズを確認する方法がわからなかったのですが、Usage AnalyticsからはIntegration Suite全体で処理された1日あたりのメッセージ数を見ることができました。